🍊作者:计算机编程-吉哥
🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
🍅 文末获取源码联系
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java毕业设计项目~热门选题推荐《1000套》

目录
[① 监督学习算法](#① 监督学习算法)
[② 无监督学习算法](#② 无监督学习算法)
[③ 高级算法](#③ 高级算法)
为什么要做真正的大数据和机器学习项目?
我们专注于提供真正基于大数据分析和机器学习算法的项目开发服务,致力于为客户解决实际业务痛点,提供可验证的技术解决方案。核心优势
- 真实技术应用:项目中真正运用大数据分析和机器学习算法
- 完整代码交付:提供完整的数据分析代码和机器学习模型训练过程
- 丰富可视化:多模块菜单分析 + 多图表展示 + 可视化大屏综合展示
- 专业技术指导:不懂的技术问题,提供售后答疑服务
1.技术选型
大数据技术介绍
| 技术领域 | 核心技术 | 应用场景 |
|---|---|---|
| 分布式计算 | Hadoop、Spark | 大规模数据处理与分析 |
| 数据查询 | Hive、Spark SQL | 海量数据查询与统计 |
| 数据处理 | Pandas、Numpy | 数据清洗与预处理 |
| 数据存储 | MySQL | 结构化数据存储管理 |
| 数据采集 | Scrapy、Selenium | 多源数据爬虫采集 |
| 数据可视化 | Echarts | 交互式可视化大屏 |
机器学习算法介绍【可扩展】
① 监督学习算法
-
线性回归 - 连续值预测与趋势分析
-
逻辑回归 - 分类问题与概率预测
-
决策树 - 规则挖掘与可解释性分析
-
随机森林 - 高精度集成学习
-
支持向量机 - 复杂分类与回归任务
-
K近邻算法 - 基于相似度的智能推荐
② 无监督学习算法
-
K均值聚类 - 客户分群与市场细分
-
层次聚类 - 数据结构挖掘
③ 高级算法
-
贝叶斯网络 - 概率推理与因果分析
-
梯度提升算法 - 高性能预测模型
后端开发框架介绍
| 语言 | 框架 | 特点 |
|---|---|---|
| Java | SpringBoot | 企业级应用开发,稳定性强 |
| Python【推荐】 | Django【推荐】/Flask | 快速开发,与数据科学无缝集成 |
2.开发工具
Pycharm、VSCode、Navicat
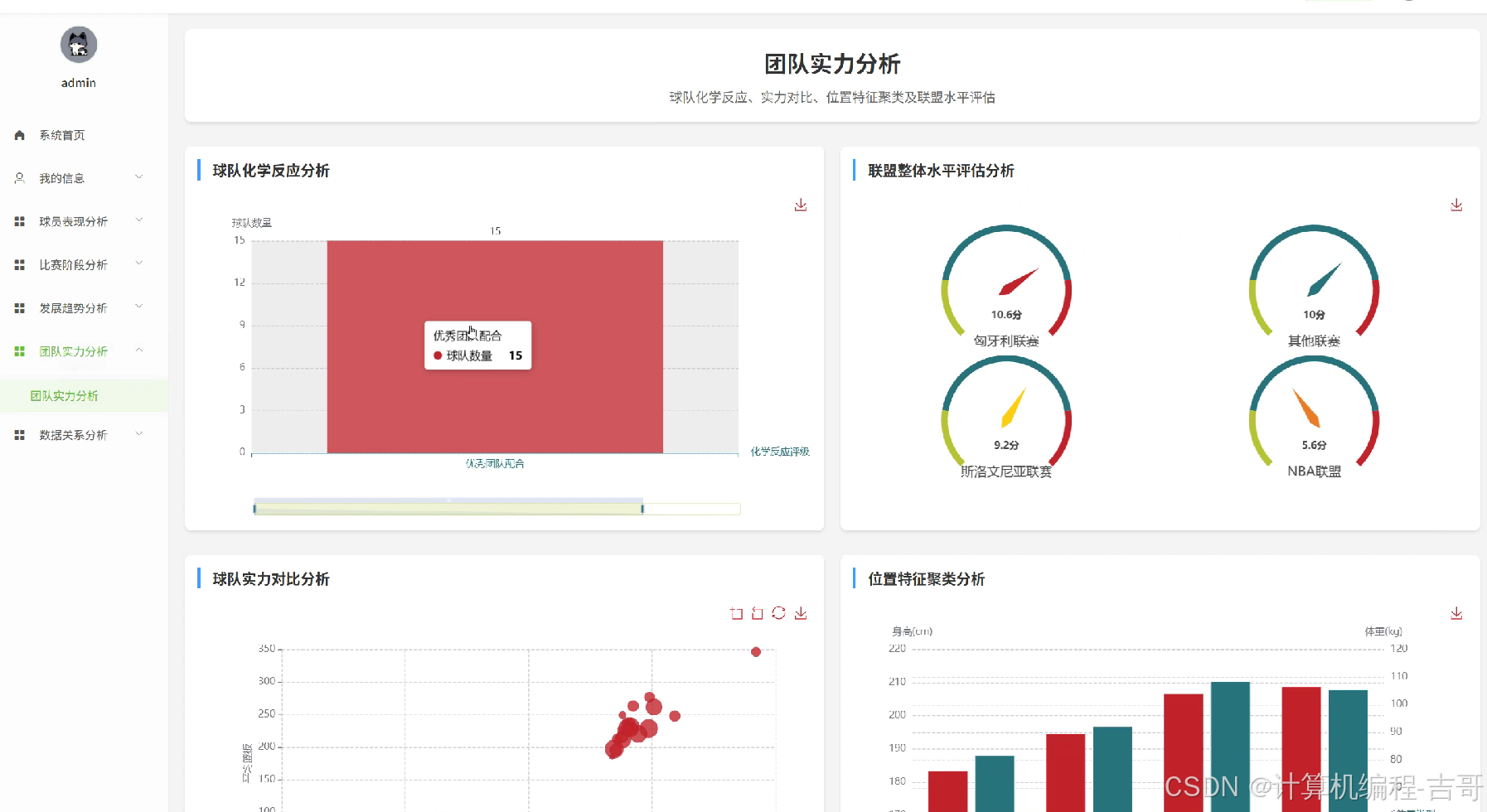
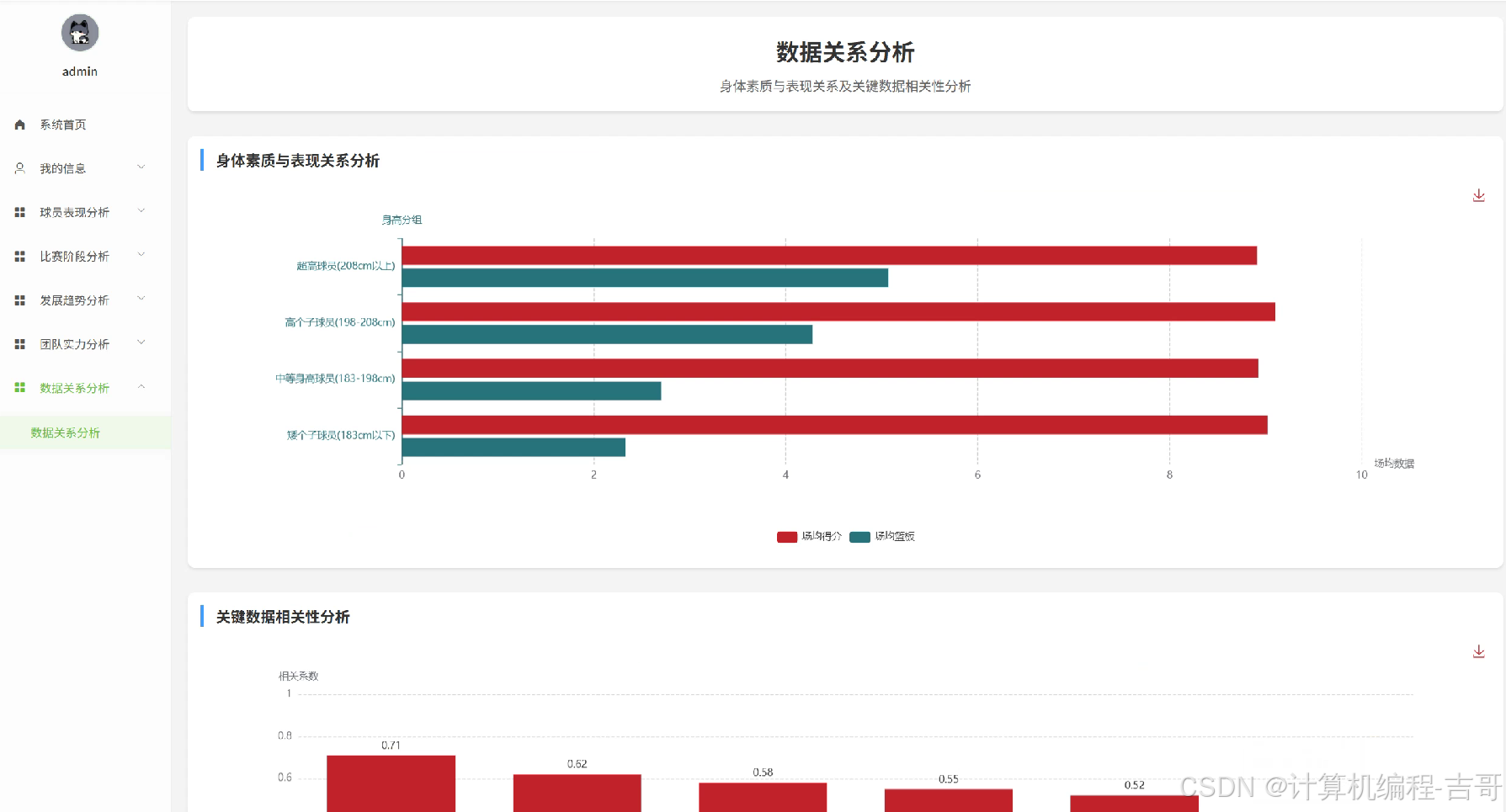
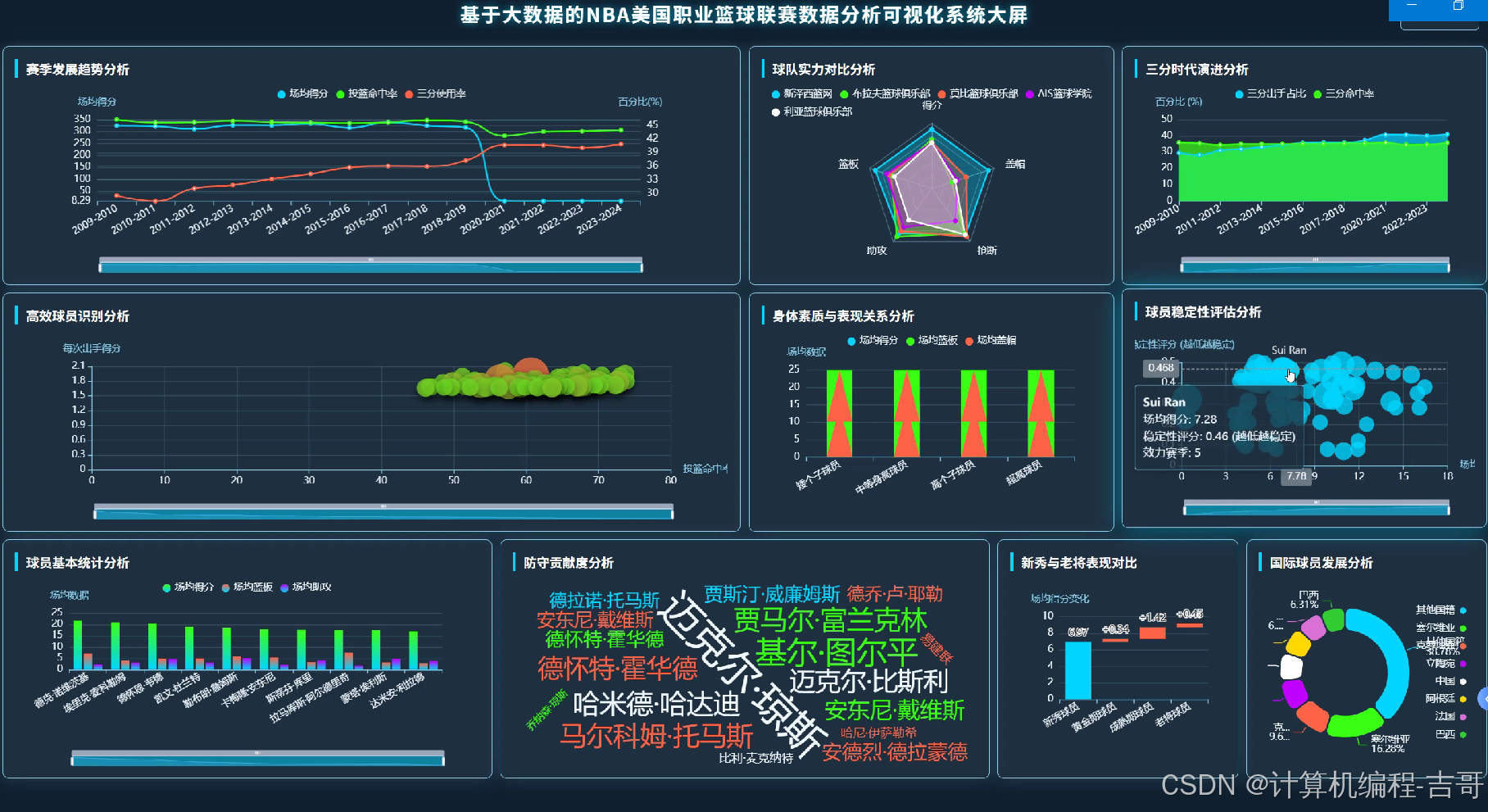
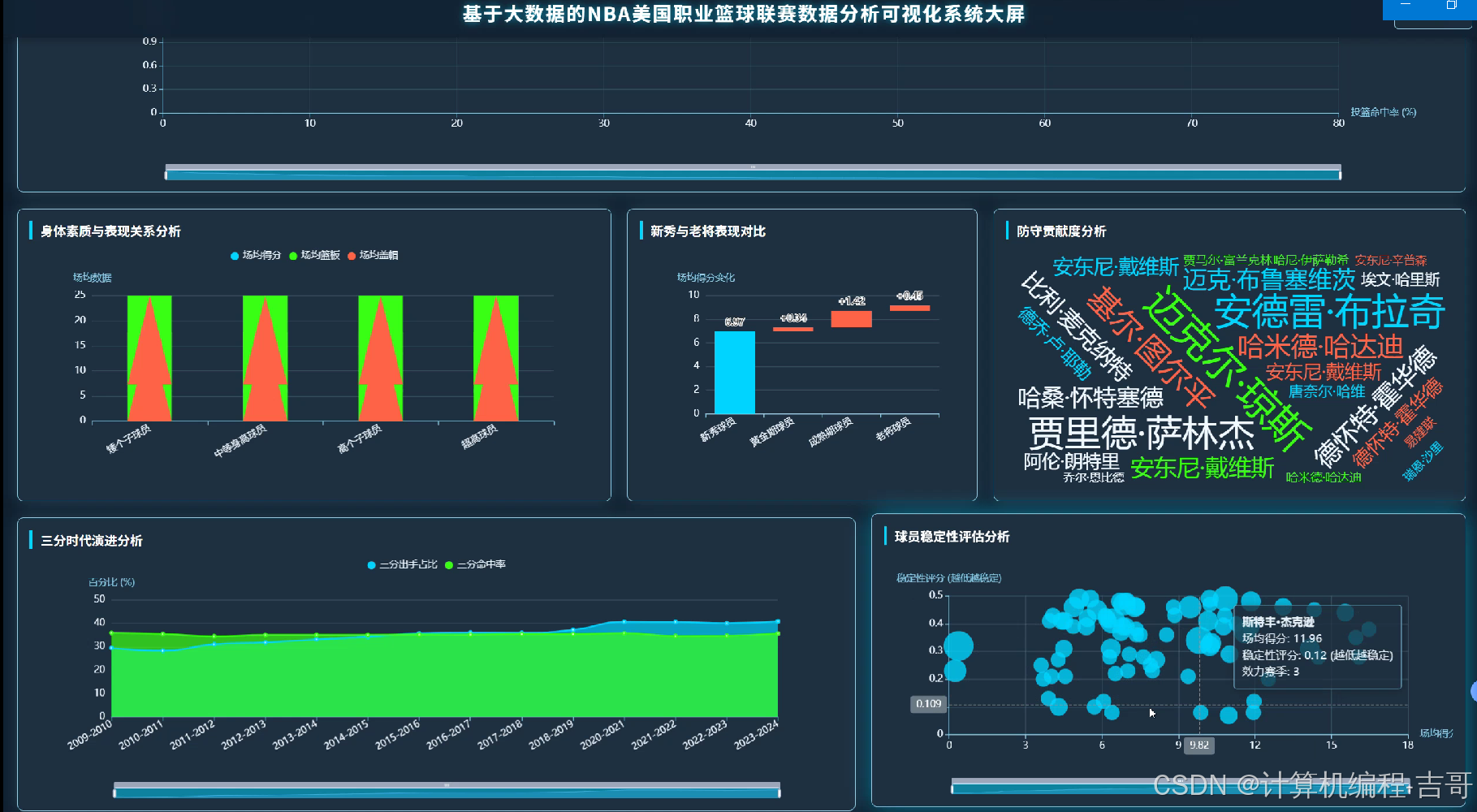
3.功能截图展示

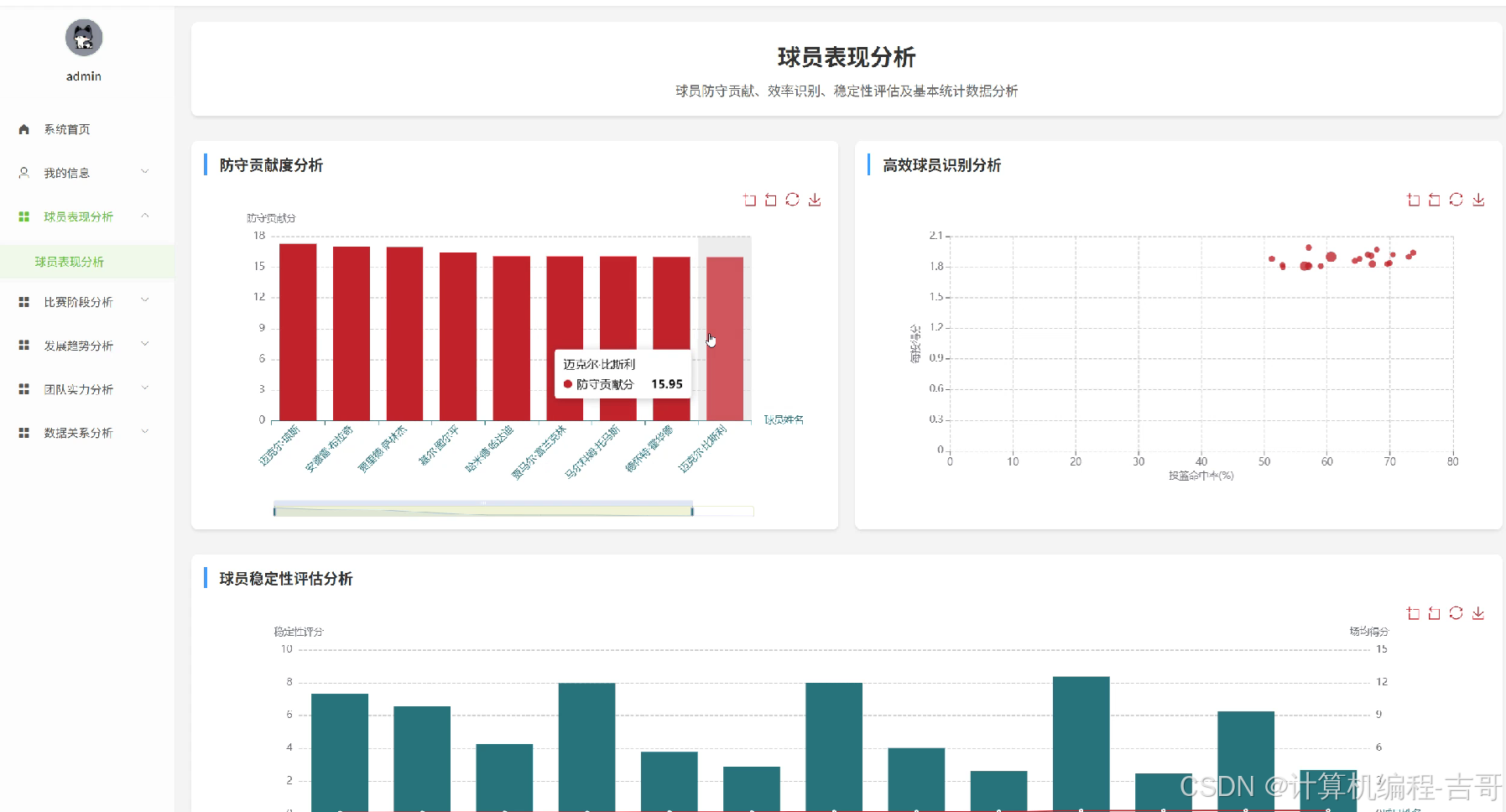
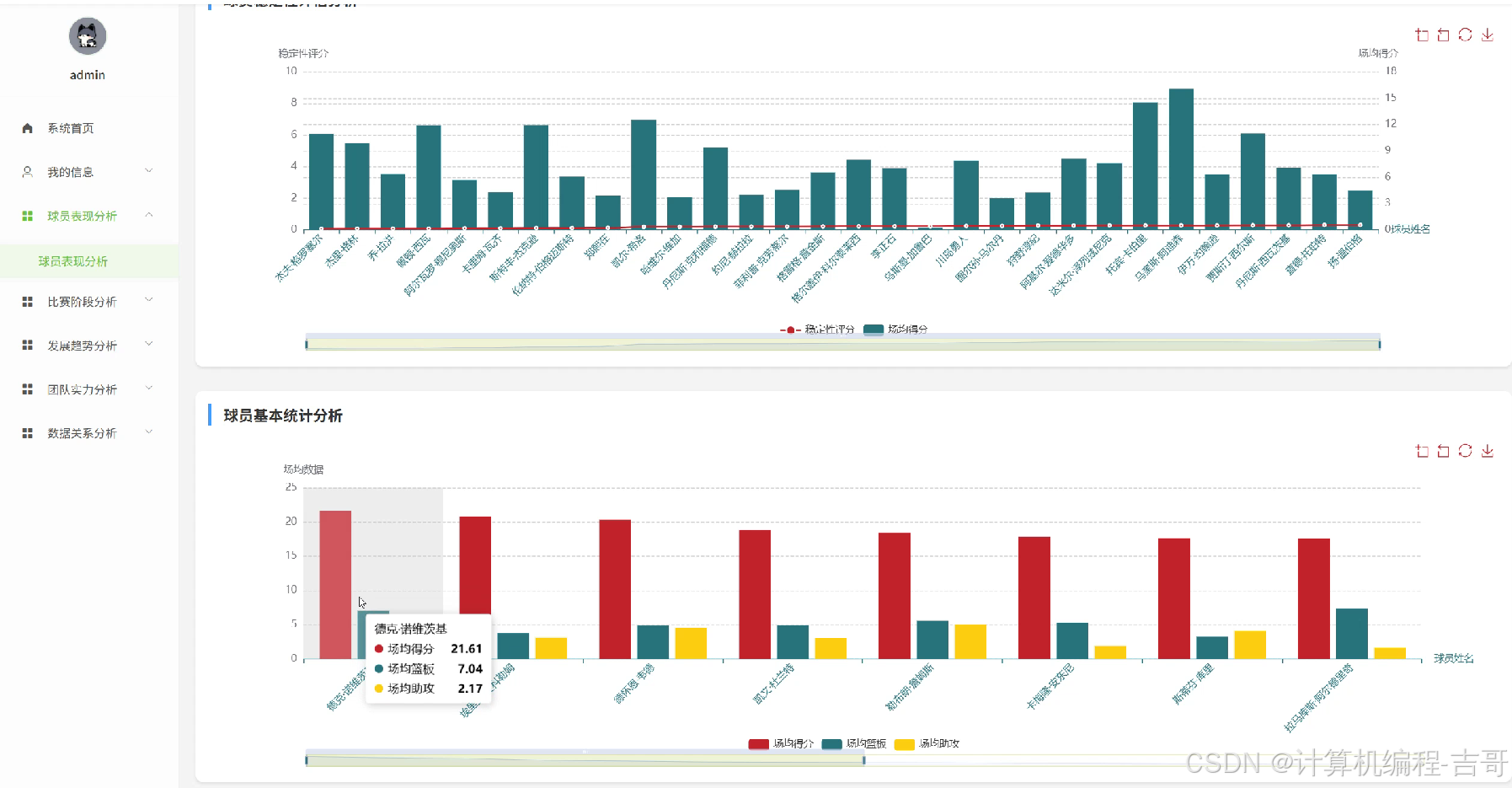
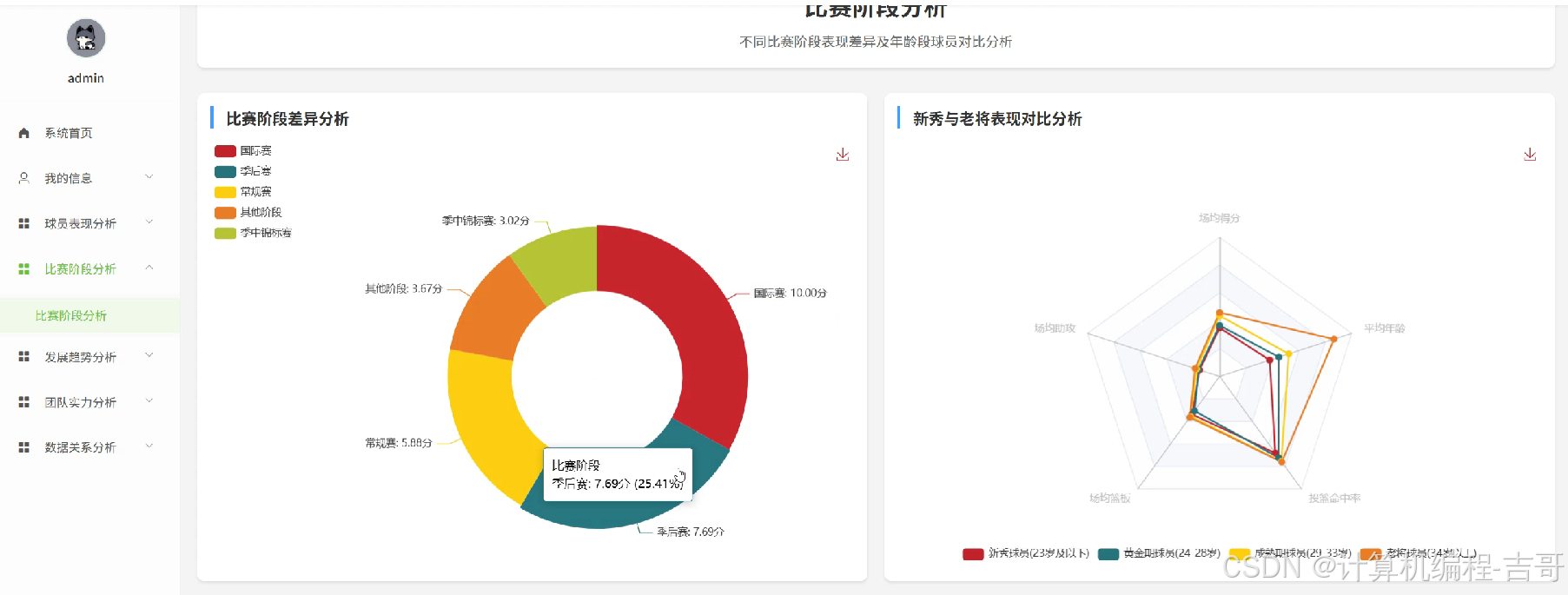
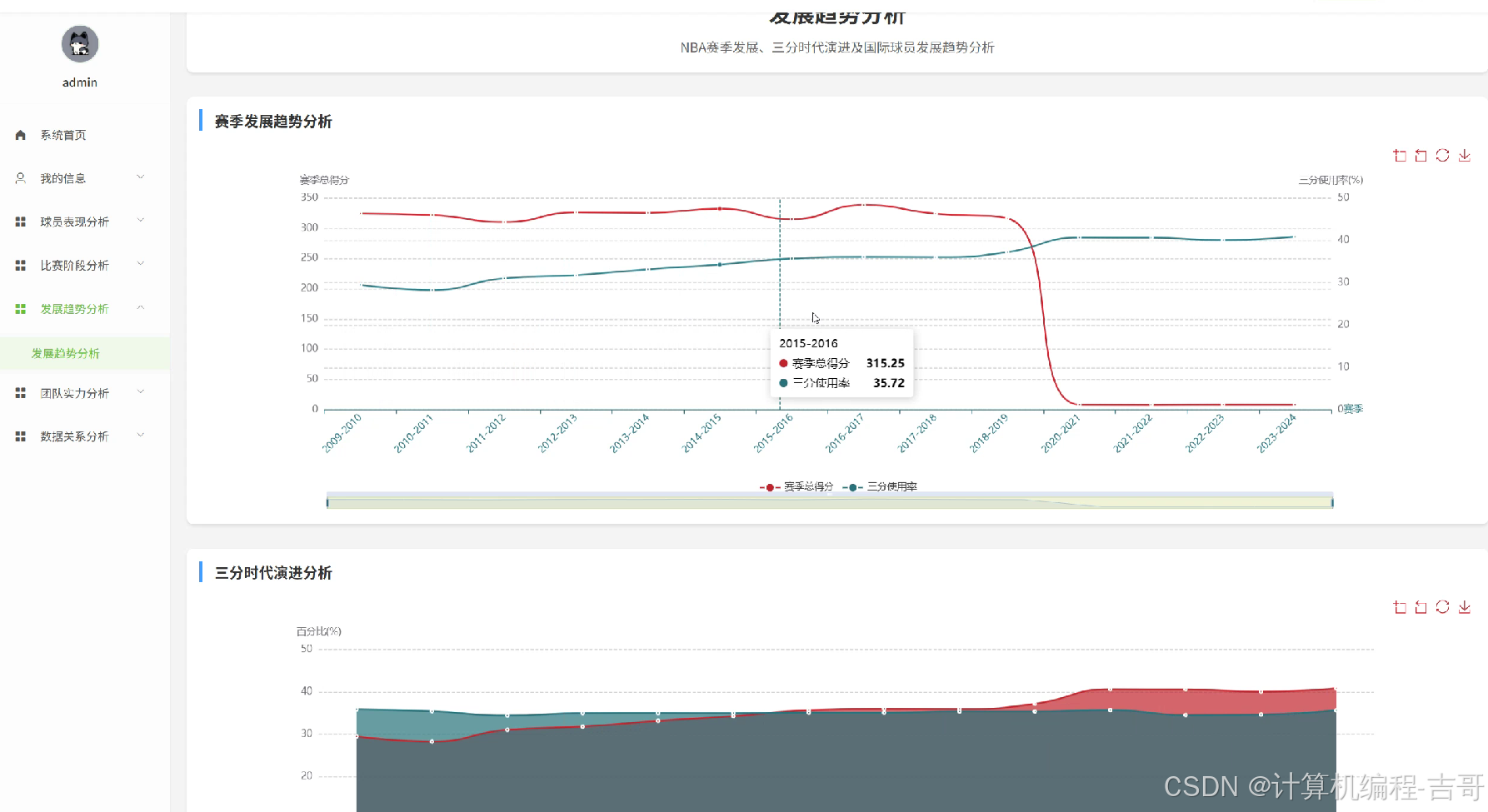
4.核心代码
python
def upload_to_hadoop():
"""
将本地数据集上传到HDFS
"""
print("\n" + "="*60)
print("步骤 1: 开始上传数据集到 HDFS")
print("="*60)
script_dir = os.path.dirname(os.path.abspath(__file__))
local_dataset_path = os.path.join(script_dir, 'dataset')
hdfs_target_path = '/movie_dataset'
try:
print(f"📂 检查本地数据集路径: {local_dataset_path}")
if not os.path.exists(local_dataset_path):
raise FileNotFoundError(f"本地数据集目录不存在: {local_dataset_path}")
# 列出本地数据集文件
local_files = os.listdir(local_dataset_path)
print(f"📋 发现本地文件: {local_files}")
print(f"🔍 检查HDFS目录 '{hdfs_target_path}'...")
check_cmd = f"hdfs dfs -test -d {hdfs_target_path}"
result = subprocess.run(check_cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if result.returncode == 0:
print(f"🗑️ HDFS目录已存在,正在删除...")
rm_cmd = f"hdfs dfs -rm -r {hdfs_target_path}"
subprocess.run(rm_cmd, shell=True, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print("✅ 旧目录删除成功")
print(f"📁 创建HDFS目录 '{hdfs_target_path}'...")
mkdir_cmd = f"hdfs dfs -mkdir -p {hdfs_target_path}"
subprocess.run(mkdir_cmd, shell=True, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print("✅ HDFS目录创建成功")
print(f"📤 上传数据集到HDFS...")
upload_cmd = f"hdfs dfs -put {local_dataset_path}/* {hdfs_target_path}/"
subprocess.run(upload_cmd, shell=True, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print("✅ 数据集上传成功")
# 验证上传结果
print(f"🔍 验证HDFS中的文件...")
ls_cmd = f"hdfs dfs -ls {hdfs_target_path}"
result = subprocess.run(ls_cmd, shell=True, capture_output=True, text=True)
print("📋 HDFS文件列表:")
print(result.stdout)
except subprocess.CalledProcessError as e:
print(f"\n❌ Hadoop命令执行失败!")
print(f"命令: {e.cmd}")
print(f"返回码: {e.returncode}")
if hasattr(e, 'stderr') and e.stderr:
print(f"错误信息: {e.stderr.decode()}")
raise
except Exception as e:
print(f"\n❌ 上传过程出错: {e}")
raise5.LW文档大纲参考【具体根据学习的来哦~】
具体仑文如何写法,可以咨询博主,耐心分享!
你可能还有感兴趣的项目👇🏻👇🏻👇🏻
更多项目推荐:计算机毕业设计项目****
如果大家有任何疑虑,请在下方咨询或评论