在大数据时代,处理 GB 级别的 CSV 文件是数据工作者的日常挑战。当文件大小超出内存限制时,传统的一次性加载方法会导致内存溢出,让分析工作陷入困境。本文将全面解析如何高效处理 GB 级 CSV 文件,重点介绍按行追加、按列合并和关键字段关联三种拼接方式,并详细讲解如何在本地 Python 环境中将这些庞大数据文件转换为更高效的 Parquet 格式。
一、GB 级 CSV 文件处理的挑战与解决方案
1.1 内存溢出:数据处理的首要障碍
当处理 GB 级别的 CSV 文件时,直接使用pd.read_csv()会导致内存溢出问题。这是因为 Pandas 默认会将整个文件加载到内存中,形成一个 DataFrame 对象。如果文件大小超过计算机内存容量,程序就会崩溃,提示 "MemoryError"。
造成内存溢出的主要原因包括:
- CSV 文件中的数据类型通常是字符串,Pandas 在读取时需要推断每列的数据类型,这一过程会消耗大量内存
- 如果某些列包含混合类型数据,Pandas 可能会默认使用占用内存更大的object类型(通常是字符串)
- 文件越大,需要存储的数据单元就越多,对内存的需求也就越高
1.2 分块处理:应对大数据的核心策略
分块处理是解决 GB 级 CSV 文件内存溢出问题的核心策略。通过将大文件拆分成多个小块,每次只加载一块到内存中进行处理,处理完成后再加载下一块,这样可以有效降低内存占用。
Pandas 提供了chunksize参数来实现分块读取:
python
chunk_size = 100000 # 设置合适的块大小
chunks = pd.read_csv('large_data.csv', chunksize=chunk_size)
for chunk in chunks:
process(chunk) # 处理每个数据块(这里的处理可以是print)返回的chunks是一个TextFileReader对象,它类似于一个迭代器,可以逐个提供数据块。
1.3 优化策略:提升处理效率的关键
除了分块处理外,还有多种优化策略可以提升 GB 级 CSV 文件的处理效率:
指定数据类型:通过dtype参数预先定义每列的数据类型,可以避免 Pandas 自动类型推断的开销,并减少内存占用:
python
dtype_mapping = {
'column_id': 'int32',
'timestamp': 'datetime64[ns]',
'value': 'float32',
'category': 'category' # 使用category类型可以大幅节省内存
}
df = pd.read_csv('large_file.csv', dtype=dtype_mapping)column_id和value当中默认的设置分别是int64和float64,描述的都是二进制存储格式的位数,实际上现实场景很少会用64位二进制去存储一个数值
timestamp就是大家所熟知的时间戳,平常存储在csv文件当中的时间都是直接以字符串的形式存储的,这样实际上是相当消耗我们的存储空间的,因此我们可以使用时间戳,这是一种相比字符串更加地节约空间的存储办法
category 类型:会将唯一值映射为整数编码,例如:"北京", "上海", "广州", "北京", "上海"----> 0, 1, 2, 0, 1
二、数据拼接的三种核心方式
2.1 按行追加:纵向合并数据
按行追加是将多个 CSV 文件或同一文件的不同部分按行合并,形成一个更大的数据集。这通常用于将同一数据源的不同时间段数据合并,或整合多个相似结构的文件。
实现方法:
使用 Pandas 的pd.concat()函数可以轻松实现按行追加。当处理 GB 级文件时,需要分块读取并追加:
python
import pandas as pd
# 定义块大小
chunk_size = 100000
# 读取第一个文件的所有块
chunks = []
for chunk in pd.read_csv('file1.csv', chunksize=chunk_size):
chunks.append(chunk)
# 读取第二个文件的所有块并追加
for chunk in pd.read_csv('file2.csv', chunksize=chunk_size):
chunks.append(chunk)
# 合并所有块
merged_df = pd.concat(chunks)
# 保存结果
merged_df.to_csv('merged.csv', index=False)注意事项:
- 确保所有要合并的 CSV 文件具有相同的列名和列顺序
- 当处理非常大的文件时,不要尝试将所有块都保存在内存中再合并,而应该处理一个块就写入一个块到结果文件
- 可以使用ignore_index=True参数重置合并后的索引
python
df1=pd.read_csv('file1.csv')
print(df1)
df2=pd.read_csv('file2.csv')
print(df2)
print(merged_df)
python
student_id hours_studied previous_scores exam_score
0 S001 8.0 45 30.2
1 S002 1.3 55 25.0
2 S003 4.0 86 35.8
3 S004 3.5 66 34.0
4 S005 9.1 71 40.3
.. ... ... ... ...
195 S196 10.5 87 42.7
196 S197 7.1 92 40.4
197 S198 1.6 76 28.2
198 S199 12.0 58 42.0
199 S200 10.2 68 37.8
[200 rows x 4 columns]
student_id hours_studied sleep_hours attendance_percent \
0 S001 8.0 8.8 72.1
1 S002 1.3 8.6 60.7
2 S003 4.0 8.2 73.7
3 S004 3.5 4.8 95.1
4 S005 9.1 6.4 89.8
.. ... ... ... ...
195 S196 10.5 5.4 94.0
196 S197 7.1 6.1 85.1
197 S198 1.6 6.9 63.8
198 S199 12.0 7.3 50.5
199 S200 10.2 6.3 97.4
previous_scores
0 45
1 55
2 86
3 66
4 71
.. ...
195 87
196 92
197 76
198 58
199 68
[200 rows x 5 columns]
student_id hours_studied previous_scores exam_score sleep_hours \
0 S001 8.0 45 30.2 NaN
1 S002 1.3 55 25.0 NaN
2 S003 4.0 86 35.8 NaN
3 S004 3.5 66 34.0 NaN
4 S005 9.1 71 40.3 NaN
.. ... ... ... ... ...
195 S196 10.5 87 NaN 5.4
196 S197 7.1 92 NaN 6.1
197 S198 1.6 76 NaN 6.9
198 S199 12.0 58 NaN 7.3
199 S200 10.2 68 NaN 6.3
attendance_percent
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
.. ...
195 94.0
196 85.1
197 63.8
198 50.5
199 97.4
[400 rows x 6 columns]2.2 按列合并:横向扩展数据维度
按列合并是将两个或多个 CSV 文件基于相同的行索引进行横向合并,增加数据的维度。这种方式通常用于将同一实体的不同属性数据合并在一起。
实现方法:
使用 Pandas 的pd.concat()函数并设置axis=1参数,可以实现按列合并:
python
import pandas as pd
# 读取两个CSV文件
df1 = pd.read_csv('file1.csv')
df2 = pd.read_csv('file2.csv')
# 按列合并
merged_df = pd.concat([df1, df2], axis=1)
# 保存结果
merged_df.to_csv('merged.csv', index=False)分块处理方法:
对于 GB 级文件,同样需要分块处理。可以分别读取两个文件的块,然后逐个合并并写入结果文件:
python
import pandas as pd
chunk_size = 100000
# 读取第一个文件的块迭代器
chunk_iter1 = pd.read_csv('file1.csv', chunksize=chunk_size)
# 读取第二个文件的块迭代器
chunk_iter2 = pd.read_csv('file2.csv', chunksize=chunk_size)
# 初始化输出文件
output_file = 'merged.csv'
# 遍历两个块迭代器,同时读取并合并
for chunk1, chunk2 in zip(chunk_iter1, chunk_iter2):
merged_chunk = pd.concat([chunk1, chunk2], axis=1)
merged_chunk.to_csv(output_file, mode='a', header=not os.path.exists(output_file), index=False)注意事项:
- 按列合并要求两个文件的行数相同,并且行顺序对应
- 如果两个文件的行数不同,合并后会出现 NaN 值填补的情况
- 可以使用join参数控制如何处理不匹配的索引
2.3 关键字段关联:基于公共列的智能拼接
关键字段关联是将两个或多个 CSV 文件基于某个或某几个公共列进行连接,类似于 SQL 中的 JOIN 操作。这种方式在数据处理中非常常见,可以将不同来源的数据整合在一起。
实现方法:
使用 Pandas 的pd.merge()函数可以轻松实现基于公共列的关联:
python
import pandas as pd
# 读取两个CSV文件
df1 = pd.read_csv('file1.csv')
df2 = pd.read_csv('file2.csv')
# 基于公共列'key'进行内连接
merged_df = pd.merge(df1, df2, on='key', how='inner')
# 保存结果
merged_df.to_csv('merged.csv', index=False)pd.merge() 是 pandas 中用于合并数据的函数,on='key' 表示以两表中名为 'key' 的列作为公共键(连接依据),只有当 'key' 列的值相同时,两行数据才会被合并------how='inner' 表示采用内连接方式,即只保留两个表中 'key' 列值存在交集的行(仅合并两边都有的 key 对应的数据)。
分块处理方法:
对于 GB 级文件,可以采用分块处理并关联的方法。这里需要注意的是,由于分块处理,无法直接进行全局关联,需要更复杂的处理逻辑:
python
import pandas as pd
chunk_size = 100000
# 读取第一个文件的所有块并存储在列表中
chunks1 = []
for chunk in pd.read_csv('file1.csv', chunksize=chunk_size):
chunks1.append(chunk)
# 分块读取第二个文件并逐个关联
output_file = 'merged.csv'
first_chunk = True
for chunk2 in pd.read_csv('file2.csv', chunksize=chunk_size):
# 逐个与chunks1中的块进行关联
merged_chunks = []
for chunk1 in chunks1:
merged = pd.merge(chunk1, chunk2, on='key', how='inner')
merged_chunks.append(merged)
# 合并所有关联后的块
merged_df = pd.concat(merged_chunks)
# 写入结果文件
merged_df.to_csv(output_file, mode='a', header=first_chunk, index=False)
first_chunk = False关联类型:
- how='inner':内连接,只保留两个数据集中都存在的键值
- how='left':左连接,保留左数据集的所有行,右数据集匹配的行
- how='right':右连接,保留右数据集的所有行,左数据集匹配的行
- how='outer':外连接,保留两个数据集的所有行,缺失值用 NaN 填充
注意事项:
- 确保关联列的数据类型在两个数据集中一致,否则关联结果可能不准确
- 对于非常大的文件,内存可能仍然是一个问题,可以考虑使用 Dask 等库进行分布式处理
- 可以通过suffixes参数指定重叠列的后缀,避免列名冲突
pickle
python当中有一个名为pickle的模块可以依靠对于二进制存储结构的序列化和反序列化来实现数据的高效存储,但值得注意的是,这种存储的优势仅存在于csv数据结构相对复杂,多用引号等文件存储较大的情况下------而在数据类型单一且样本较小时,往往pickle文件的优势并不显著,此外,官方pickle文档中明确提及pickle模块并非安全,因此只能对于信任的文件使用,加之其所具备的人工不可读性,使我们在使用此法时需要慎重考虑

模块接口
pickle模块有如下四个使用方式:
python
pickle.dump(obj, file, protocol=None, *, fix_imports=True, buffer_callback=None)
#将对象 obj 封存以后的对象写入已打开的 file object file。它等同于 Pickler(file, protocol).dump(obj)。
pickle.dumps(obj, protocol=None, *, fix_imports=True, buffer_callback=None)
#将 obj 封存以后的对象作为 bytes 类型直接返回,而不是将其写入到文件。
pickle.load(file, *, fix_imports=True, encoding='ASCII', errors='strict', buffers=None)
#从已打开的 file object 文件 中读取封存后的对象,重建其中特定对象的层次结构并返回。它相当于 Unpickler(file).load()。
pickle.loads(data, /, *, fix_imports=True, encoding='ASCII', errors='strict', buffers=None)
#重建并返回一个对象的封存表示形式 data 的对象层级结构。 data 必须为 bytes-like object。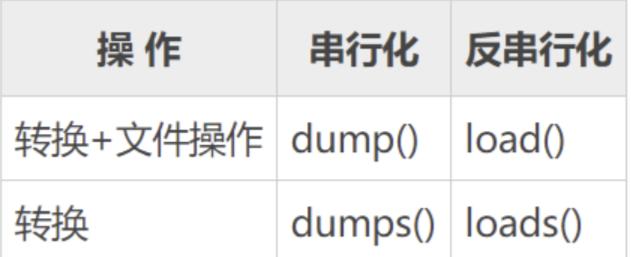
应用实例
那么我们该如何调用pickle模块以期实现数据的低存储?
把一个csv文件转录成pickle文件方案如下:
python
import pickle
import pandas as pd
df = pd.read_csv('TRD_Dalyr.csv')
print(df)
with open('TRD_Dalyr.pickle', 'wb') as f:
pickle.dump(df, f) dump在这里同时实现了两个操作,一个是对于df的转换,二是将其写入pickle文件当中
同理,load方法在这里也能同时实现对于文件的打开和转换:
python
import pickle
with open('TRD_Dalyr.pickle', 'rb') as f:
x = pickle.load(f)
print(x)(这里的r和w对应读写模式,b对应二进制编码)