大家好,我是韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少"避坑"经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批"好上手且有亮点"的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

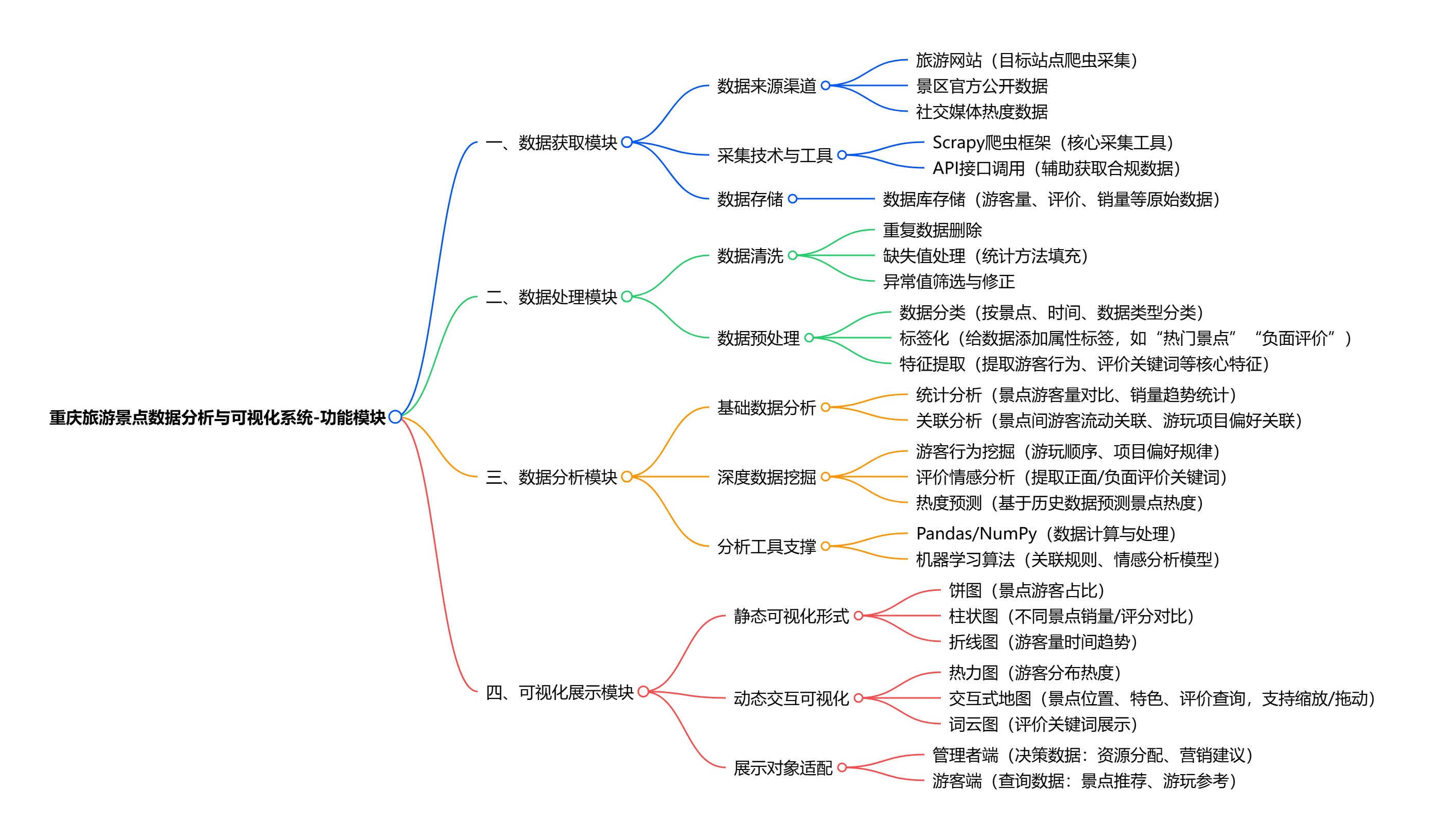
重庆旅游景点数据分析与可视化系统核心功能可概括为四部分:
一是数据获取,通过 Scrapy 爬虫框架等从目标网站抓取景点游客量、评价、门票销量等数据并存储;
二是数据处理,对获取数据进行清洗(删重复、处理缺失 / 异常值)与预处理(分类、特征提取),保障数据质量;
三是数据分析,运用 Pandas、NumPy 等工具,结合统计方法与机器学习技术,挖掘游客行为偏好、景点关联规律及评价关键词等信息;
四是可视化展示,借助 Matplotlib、ECharts 等工具,以饼图、柱状图、热力图、交互式地图等形式,直观呈现分析结果,供管理者决策与游客查询参考。
开题陈述
各位老师好,我的毕业设计题目是《重庆旅游景点数据分析与可视化》。这个系统主要通过Python爬虫技术从各大旅游平台采集重庆景点的游客数据、评价信息和社交媒体热度,经过数据清洗和预处理后,利用Pandas、NumPy进行数据分析,再通过Matplotlib、ECharts等可视化库将分析结果以交互式图表和热力图的形式展现。
核心功能包括数据采集模块、数据清洗与预处理模块、分析计算模块和可视化展示模块。
技术栈主要采用Python3.7+环境,配合Jupyter Notebook进行数据分析,使用Flask框架搭建Web展示平台,最终为游客提供景点推荐和路线规划,为景区管理者提供运营决策支持。
答辩环节
评委老师: H同学,你计划从哪些具体网站爬取数据?是否考虑过这些网站的反爬虫机制和数据使用协议问题?
答辩学生: 老师好,我初步计划从携程、去哪儿、马蜂窝这些主流旅游平台获取景点评分、评论和游客量数据。关于反爬虫问题,我确实考虑过,准备采用设置请求头模拟浏览器、控制访问频率、使用代理IP等基础反反爬策略。至于数据使用协议,这些公开评论数据属于用户生成内容,一般用于学术研究是可以的,但我会注意不爬取涉及个人隐私的信息,仅采集公开可见的景点评价和访问量数据,并做好数据脱敏处理。
评委老师: 报告中提到要对游客行为进行分析和预测,你具体会分析哪些行为维度?用什么算法模型?
答辩学生: 老师,我计划分析的行为维度包括:游客来源地分布、游览时间偏好(季节性和时段性)、景点热度趋势、用户评价情感倾向这几个方面。预测方面,主要是基于历史数据做景点热度趋势预测和游客量预测。算法上,时间序列预测会用ARIMA模型,情感分析可能用TextBlob或简单的朴素贝叶斯分类。不过这些方法都是基础模型,效果可能有限,我会先实现基于历史数据的统计预测,机器学习部分作为后续优化内容。
评委老师: 你的可视化展示打算做成交互式的还是静态图表?如果只是普通的柱状图、饼图,如何体现项目的创新性和实用价值?
答辩学生: 我计划做成交互式可视化,用户可以选择不同的时间范围、景点类型进行筛选查看。除了基础的柱状图、饼图,还会加入热力图展示景点热度地理分布,用折线图展示趋势变化,以及词云图展示用户评价关键词。但您说得对,如果仅仅是常规图表,创新性确实不足。我考虑增加一个"个性化推荐"功能模块,基于用户的历史浏览行为推荐相似景点,这样能让系统更具实用价值。不过这个功能实现难度较大,我会作为加分项尽力实现。
评委老师: 重庆有300多个A级景区,你的系统计划覆盖全部景点还是选取部分代表性景点?数据存储结构如何设计?
答辩学生: 考虑到开发周期和数据采集难度,我计划先选取重庆主城区的20-30个热门4A、5A级景区作为数据源,比如洪崖洞、磁器口、武隆天生三桥这些知名度高的景点。数据存储方面,我设计了三类核心表:景点基本信息表(名称、地址、等级、门票)、游客数据表(访问量、评分、评论)、时间维度表(日期、节假日标记)。如果后续时间允许,再逐步扩展景点数量。这种小规模数据集也更有利于我这种基础薄弱的学生快速做出可用原型。
评委老师: 你提到要处理数据质量问题,但爬虫获取的数据往往存在大量噪音,比如评论中的广告、无效评分等。你准备如何建立数据质量评估体系和清洗规则?
答辩学生: 初步的清洗规则包括:删除重复评论、过滤明显广告内容(含联系方式、外链的)、剔除评分与评论内容严重不符的数据。但建立完整的质量评估体系确实有难度。我计划采用简单的统计方法,比如计算评论长度的分布,过滤掉过短的水军评论;检查用户评分分布,过滤掉异常评分模式。更复杂的内容质量判断可能需要人工标注样本训练分类器,这个可能超出我的能力范围。我会在论文中说明数据质量的局限性,并尽量保证基础的数据准确性。
评委老师: 你的系统最终是部署在本地服务器供个人使用,还是计划部署到云服务器开放访问?如果是后者,如何应对高并发访问和实时数据更新问题?
答辩学生: 我目前的计划是先在本地Flask开发服务器上运行,作为毕业设计演示版本。如果要做成可公开访问的系统,确实需要考虑性能问题。对于高并发,Flask自带的开发服务器肯定不行,需要配合Nginx+Gunicorn部署,这对我有一定难度。数据更新方面,我打算采用定时任务(如每天凌晨)批量更新数据,而不是实时爬取,这样可以减轻服务器压力。但您提到的这些问题都属于系统优化层面,考虑到我的基础,我会优先保证核心功能实现,部署和性能优化作为后续工作,在论文中也会说明系统的局限性。
评委老师: 最后一个问题,如果景区管理者要使用你的系统做决策,你如何证明你的分析结果是可信的?比如你的景点热度预测准确率达到多少才有参考价值?有没有考虑模型的可解释性?
答辩学生: 老师,这个问题确实很关键。关于预测准确率,我计划用历史数据做回测验证,比如用过去6个月的数据训练模型,预测最近1个月的热度,再和实际数据对比计算MAE(平均绝对误差)。但对于"多少准确率才有参考价值",坦白说我没有明确标准,可能70%以上的准确率算基本可用?关于模型可解释性,简单的时序模型和统计分析方法本身就有较好的可解释性,比如我能告诉管理者"周末游客量比平时高30%""暑期是旺季"这些明确结论。但如果用复杂的机器学习模型,可解释性确实会下降。我会在论文中明确说明数据来源、分析方法的局限性,并提供验证指标,让用户了解结果的置信度。对于重大决策,我的系统只能作为辅助参考,不能完全依赖。
评委老师总结评价
H同学,你的开题报告整体结构完整,技术路线清晰,选题也贴合实际应用需求,具备可行性。从答辩情况看,你对项目整体有基本把握,但在几个关键方面还需加强:
-
技术深度不足:对高并发、实时性、模型评估等进阶问题考虑较少,停留在"做出来就行"的层面,缺乏系统性思维。
-
创新性挖掘不够:项目偏向常规的数据爬虫+可视化,特色不鲜明,需要思考如何做出差异化价值。
-
工程化思维欠缺:对数据质量、系统部署、性能优化等工程实践问题预估过于乐观,缺乏风险意识。
建议:聚焦核心功能,做实做细数据采集和清洗环节,确保分析结果基本准确;可视化方面不求花哨但要有洞察力;预测功能谨慎评估,避免过度承诺。适当降低广度,提升单点深度,比如专注做游客评论的情感分析和归因分析,做出特色。
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告可参考。