什么是 PGO?
Profile-Guided Optimization (PGO) 是一种 "以真实运行数据为依据" 的编译优化方式:
先用插桩或采样收集程序在代表性输入下的执行画像(热点路径、分支概率、调用频次等);
再用该画像指导编译器做更贴近实际负载的优化决策(代码布局、内联、分支预测、循环向量化与调度、寄存器分配等)。
PGO 原理
PGO 是基于当前运行的程序生成的 Profile,基于 Profile 再通过编译器调整代码,原理如下:
- 分析阶段:程序首先在启用分析工具的情况下进行编译和执行,在此阶段,编译器会收集不同代码路径、函数调用和其他程序行为的频率和分布数据;
- 分析数据:分析阶段会生成一个分析数据文件,其中包含有关代码热点(经常执行的部分)的信息以及有关程序运行时行为的其他相关详细信息;
- 重新编译:编译器随后会使用此配置文件数据来指导优化过程,它可以做出明智的决策,确定哪些代码路径最为关键,以及哪些优化可能产生最大的影响;
- 优化:基于分析信息,编译器可以应用各种优化措施,例如内联函数、重新排序代码以改进分支预测以及优化循环结构。这些优化旨在提高程序的整体性能;
- 重建:重新编译应用了优化的代码,从而生成一个新的可执行文件,该文件应根据从分析数据中获得的见解更高效地运行;
分析代码
比如有一段如下 C++ 代码,对其进行 PGO 优化:
csharp
bool some_top_secret_checker(int var)
{
if (var == 42) return true;
if (var == 322) return true;
if (var == 1337) return true;
return false;
}
...
// 多处高频执行如下代码:
bool ret = some_top_secret_checker(322);
...(1)直接编译
如上 c++ 编译以后的汇编代码如下:
ini
mov al, 1 ; 将立即数1存入AL寄存器(EAX的低8位),设置默认返回值为1
cmp edi, 42 ; 比较EDI寄存器的值与42
je .LBB0_4 ; 如果相等(ZF=1),跳转到标签.LBB0_4
cmp edi, 1337 ; 比较EDI寄存器的值与1337
je .LBB0_4 ; 如果相等(ZF=1),跳转到标签.LBB0_4
cmp edi, 322 ; 比较EDI寄存器的值与322
je .LBB0_4 ; 如果相等(ZF=1),跳转到标签.LBB0_4
xor eax, eax ; 将EAX寄存器清零(异或自身=0),设置返回值为0
.LBB0_4: ; 函数返回标签
ret ; 返回调用者,返回值在EAX中(2)使用 PGO 编译
ini
mov al, 1 ; 将立即数1存入AL寄存器(EAX的低8位),设置默认返回值为1
cmp edi, 322 ; 比较EDI寄存器的值与322
jne .LBB0_1 ; 如果不相等(ZF=0),跳转到标签.LBB0_1继续检查其他值
; 如果edi == 322,则直接执行下面的返回(返回值为1)
.LBB0_4: ; 函数返回标签
ret ; 返回调用者,返回值在EAX中
.LBB0_1: ; 继续检查其他值的标签
cmp edi, 42 ; 比较EDI寄存器的值与42
je .LBB0_4 ; 如果相等(ZF=1),跳转到返回标签(返回值为1)
cmp edi, 1337 ; 比较EDI寄存器的值与1337
je .LBB0_4 ; 如果相等(ZF=1),跳转到返回标签(返回值为1)
xor eax, eax ; 将EAX寄存器清零(异或自身=0),设置返回值为0
jmp .LBB0_4 ; 无条件跳转到返回标签发现有什么不一样么?
if (var == 322) return true; 这段被高频执行代码被优化到前面了;
cmp edi, 322 这段逻辑被提前到代码的最前面的位置。
(3)值得注意
在 PGO 之后,ret 返回语句不再放在函数末尾,而是移到了函数开头。
这样做是为了提高 CPU 指令缓存的命中率,因为分支之后 322 很有可能直接返回,所以将接下来很有可能执行的代码放到一起能提升性能。
如何对 C++ 代码 PGO
为了验证性能,实现如下代码:
ini
...
bool some_top_secret_checker(int var) {
if (var == 42 && calculateSum(10000) > 100) {
returntrue;
}
if (var == 322) {
returntrue;
}
if (var == 1337 && calculateSum(10000) > 1000) {
returntrue;
}
returnfalse;
}
...文件名为 main.cpp,按照如下步骤进行编译:
Mac/Clang编译
ini
# 1) 普通构建
clang++ -std=c++17 -O3 -march=native -o main main.cpp
# 2) 插桩构建
clang++ -std=c++17 -O3 -march=native -fprofile-instr-generate -o main_pgo_gen main.cpp
# 3) 运行收集 raw profile(可用通配符生成多文件)
LLVM_PROFILE_FILE="default_%p.profraw" ./main_pgo_gen >/dev/null
# 4) 合并画像
llvm-profdata merge default_*.profraw -o default.profdata
# 5) 应用构建(使用画像)
clang++ -std=c++17 -O3 -march=native -fprofile-instr-use=default.profdata -o main_pgo main.cpp
# 6) 性能对比
time -p ./main >/dev/null
time -p ./main_pgo >/dev/nullLinux/GCC 编译
ini
# 生成阶段:带 profile 插桩
g++ -std=c++17 -O3 -march=native -fprofile-generate -o main_gen main.cpp
./main_gen >/dev/null # 运行后生成 *.gcda 数据
# 应用阶段:使用 profile 做优化
g++ -std=c++17 -O3 -march=native -fprofile-use -fprofile-correction -o main_pgo main.cpp测试结果
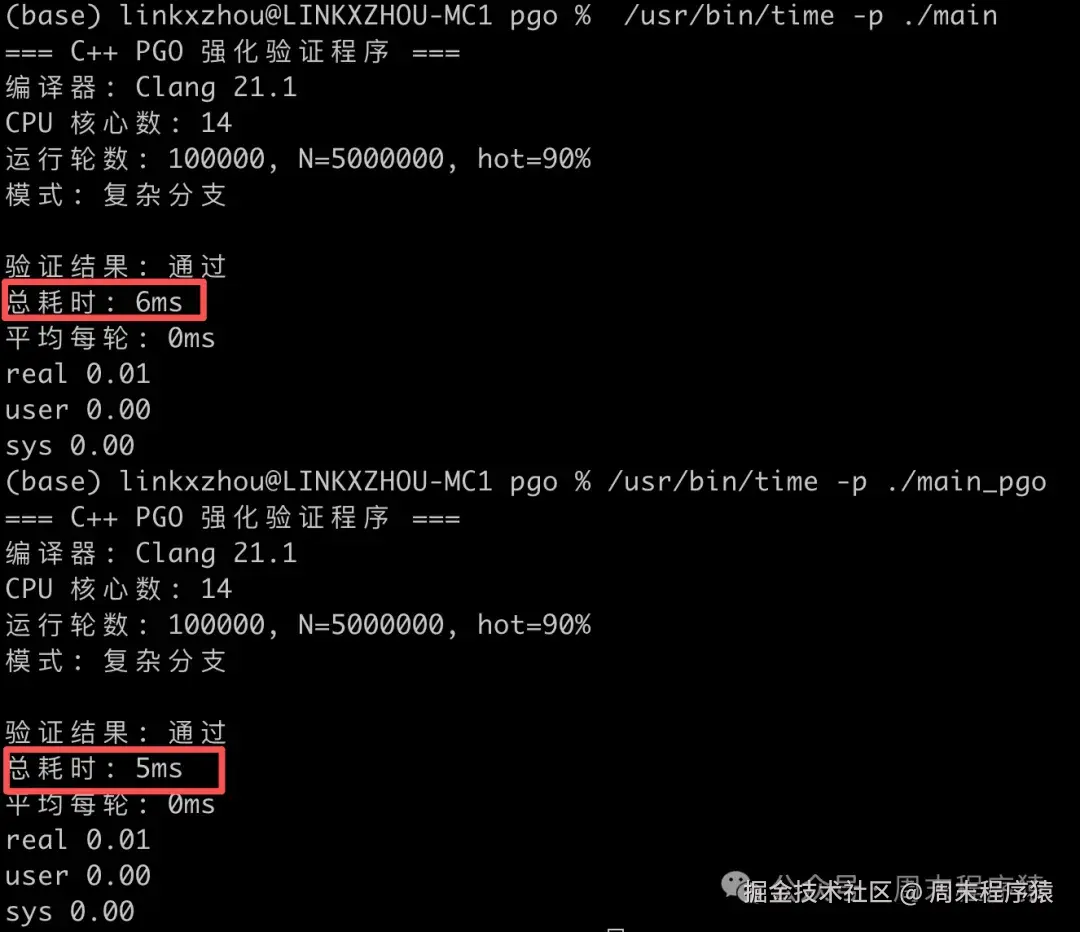
上面是没有 PGO 优化的执行时间,下面是 PGO 优化的执行时间,对比性能提升 10~20% 之间。
PGO 实现类型
PGO 实现类型主要有两种:
- 基于插桩(Instrumentation-based):
-
- 原理:插桩实现即在编译或者运行时收集统计信息,比如执行频率,哪些会执行,哪些不执行,这些文件被保存为
PGO profiles,重新编译代码的时候,会将这些收集的信息集合,重新调整代码执行的顺序; - 问题:插桩会导致插装的运行时的程序性能下降,而且二进制的编译文件体积会增加;
- 原理:插桩实现即在编译或者运行时收集统计信息,比如执行频率,哪些会执行,哪些不执行,这些文件被保存为
- 基于采样(Sampling-based):
-
- 原理:为降低插桩的开销,采样
PGO通过硬件性能计数器(如 Linux perf)收集运行数据,再转换为编译器可读的配置文件,主流工具包括 Google AutoFDO(支持 GCC/LLVM)和 LLVM 内置的 llvm-profgen; - 问题:由于依赖硬件性能计数器等工具,所以需要依赖工具链建设;
- 原理:为降低插桩的开销,采样