引言:万物互联时代的"数据洪流"与"选型之痛"
我们正处在一个前所未有的时代。从智慧工厂的机械臂、纵横交错的智能电网,到城市中川流不息的车联网车队,再到每个人手腕上的智能穿戴设备,数以百亿计的传感器正在以前所未有的速度生成着海量数据。这些数据最典型的特征,就是它们都携带着一个"时间戳",记录着特定时刻的状态,这便是"时序数据"。
据 IDC 预测,到 2025 年,全球物联网(IoT)连接设备将超过 400 亿台,产生的数据量将逼近 80 ZB。这股汹涌而来的"数据洪流",为企业带来了巨大的机遇,也带来了严峻的挑战。如何高效地存储、管理、查询和分析这些数据,从中挖掘出商业价值,成为企业数字化转型的关键。

传统的通用数据库(如 MySQL)在面对每秒百万点甚至千万点的高并发写入、PB 级的存储需求以及复杂的时序分析时,早已力不从心。这催生了一个专门的领域------时序数据库(Time Series Database, TSDB)。然而,市场上的 TSDB 产品百花齐放,技术路线各异,这让许多企业在技术选型时陷入了"选择的困境":
-
性能陷阱:一些数据库在小规模测试时表现尚可,但随着数据量和设备数的增长,性能会断崖式下跌。
-
成本黑洞:海量数据意味着高昂的存储成本,如果数据库的压缩能力不足,数年的数据就可能变成一个吞噬预算的无底洞。
-
生态孤岛:最致命的问题是,新的数据库是否能与企业现有的技术栈(特别是大数据平台)顺畅集成?如果为了引入一个新的数据库而导致数据无法自由流动,形成新的"数据孤岛",那么其价值将大打折扣。
本文将从现代大数据架构的视角出发,探讨一个理想的时序数据库应该具备哪些核心能力,并重点剖析 Apache 基金会的顶级项目------IoTDB,是如何凭借其原生的"大数据基因"和"端-边-云"一体化架构,成为破解上述难题、与大数据生态无缝融合的理想之选。  @toc
@toc
现代数据架构对时序数据库的核心诉求
在评估一个时序数据库时,我们不能再孤立地看待它本身,而应将其置于整个数据架构中,考察其综合能力。一个现代化的、面向未来的 TSDB,至少应满足以下五个维度的核心诉求: 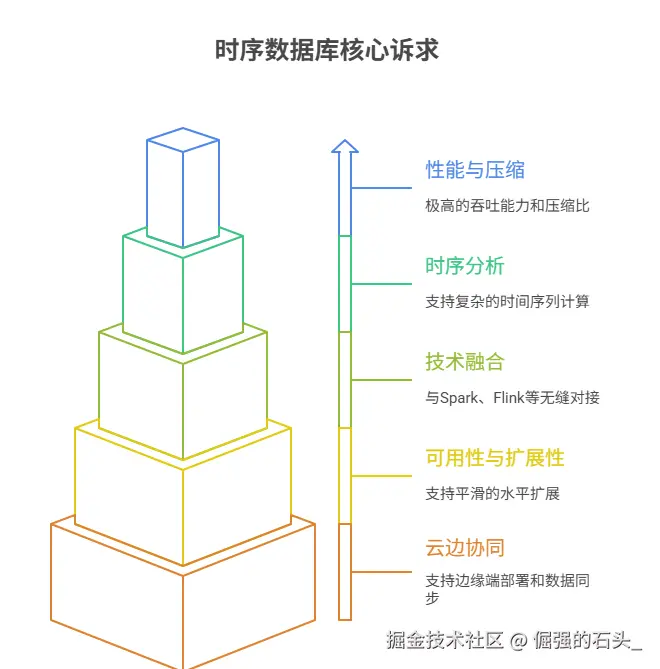
-
极致的读写性能与压缩比:这是 TSDB 的立身之本。面对海量测点的高并发写入,数据库必须具备极高的吞吐能力和极低的写入延迟。同时,为了应对动辄数年的数据存储周期,必须拥有超高的压缩比,以数量级的方式降低存储成本。
-
强大的时序分析能力:数据存进来只是第一步,更重要的是能被快速、灵活地分析。除了基础的点查询、范围查询,数据库还必须原生支持降采样、窗口查询、数据对齐、周期性分析等复杂的时间序列计算,将分析能力下推到离数据最近的地方。
-
与现有技术栈的融合度:现代企业的数据处理早已不是单点作战,而是形成了以 Spark、Flink、Hadoop 等为核心的复杂数据处理链路。TSDB 必须能够作为数据源或数据湖的一部分,与这些计算引擎和存储系统无缝对接,让数据能够自由、高效地在体系内流动,支撑 ETL、机器学习、AI 训练等上层应用。
-
高可用与可扩展性:业务总是在不断发展。数据库必须具备高可用特性,避免单点故障。同时,它必须支持平滑的水平扩展,当数据量和请求量增长时,只需简单地增加节点即可线性提升整个集群的服务能力。
-
云边协同的全场景覆盖:在工业互联网等典型场景中,数据产生于边缘端(如车间、设备侧),但大量的复杂分析和长期存储发生在云端。一个优秀的 TSDB 应该具备"端-边-云"一体化的能力,支持在资源受限的边缘端进行轻量化部署和数据预处理,并能高效地将数据同步到云中心。
这五大诉求,如同一张"选型罗盘",为我们指明了方向。接下来,我们将以此为标准,审视 Apache IoTDB 的设计哲学。
破局之道:Apache IoTDB 的原生大数据基因
Apache IoTDB 并非一个简单的数据库,它从诞生之初就将自己定位为大数据生态中的关键一环。它的架构设计和核心特性,无一不体现着与大数据生态无缝融合的"原生基因"。
1. 架构解析:为高并发、高可用而生
IoTDB 采用了清晰且可扩展的分布式架构,主要由 ConfigNode 和 DataNode 组成。
-
ConfigNode:负责整个集群的元数据管理(如时间序列的结构信息)和集群状态管理。它们通过 Raft 一致性协议保证元数据的高可用,是集群的"大脑"。
-
DataNode:负责时序数据的存储和查询。数据通过分区策略(按时间和序列)分布在不同的 DataNode 上,读写请求可以并行地发往多个 DataNode,从而实现极高的并发处理能力。
这种"Master-Slave"的存算分离架构,使得集群可以独立地扩展计算和存储节点,具备极强的水平扩展能力。
2. 天作之合:与大数据生态的无缝集成
这是 IoTDB 最具魅力的特性之一。它不是通过笨重的、低效的数据导入导出方式来"兼容"大数据生态,而是通过原生的连接器和底层文件格式的开放性,实现了真正的"无缝集成"。
数据流示意图:
-
计算层集成 (Spark & Flink) :IoTDB 提供了
iotdb-spark和iotdb-flink两个原生连接器。这意味着,数据分析师和工程师可以直接在 Spark 或 Flink 程序中,像读写普通数据表一样,将 IoTDB 作为数据源进行读取,或者将计算结果写回 IoTDB。整个过程无需繁琐的数据格式转换和中间落地,数据在内存中直接流动,效率极高。-
Spark 伪代码示例:
scala// Read data from IoTDB val df = spark.read.format("org.apache.iotdb.spark.IoTDB") .option("path", "root.factory.workshop_1.device_1.temperature") .load() // Perform complex analysis val result = df.filter("value > 100").groupBy("time").avg("value") // Write result back to IoTDB result.write.format("org.apache.iotdb.spark.IoTDB") .option("path", "root.analysis.workshop_1.avg_temp") .save()
这种原生的集成方式,相比其他 TSDB 需要通过 JDBC 或者导出 CSV 文件再让 Spark 读取的方式,性能和易用性都得到了质的飞跃。
-
-
存储层集成 (Hadoop & HDFS) :IoTDB 的底层核心是其自研的列式存储文件格式------TsFile。TsFile 的设计完全开放,并且可以独立于 IoTDB 数据库存在。企业可以将生成的 TsFile 文件直接存放在 HDFS 或对象存储(如 S3)上,形成数据湖的一部分。这意味着,Hadoop 生态中的其他计算引擎(如 Hive, MapReduce)可以直接处理这些 TsFile 文件,实现了存储层的彻底打通。
这种设计使得 IoTDB 不仅是一个"数据库",更是一个"数据湖连接器",完美融入了企业现有的数据湖架构。
3. IoTDB 的其他核心优势
除了与大数据生态的紧密结合,IoTDB 自身也具备一系列强大特性。
-
卓越的性能与极致的压缩:IoTDB 的高性能不仅来自其架构。其核心 TsFile 格式采用了"列式存储 + 预聚合 + 专有编码"的技术。它会根据不同数据类型(整型、浮点型、文本等)自动选择最高效的编码方式(如 RLE, ZIGZAG, GORILLA)和压缩算法(SNAPPY),通常可以实现高达 10:1 甚至更高的压缩比,极大地节约了宝贵的存储资源。
-
"端-边-云"一体化架构:这是 IoTDB 针对现代物联网场景的独特设计。
-
云端:部署功能完整的分布式集群,提供强大的存储和分析能力。
-
边缘端:可以部署轻量级的单机版 IoTDB,在靠近数据源的地方进行数据汇聚、清洗和预聚合。
-
数据同步:IoTDB 提供了专门的数据同步工具,可以高效地将边缘端的数据增量或全量同步到云中心,形成统一的数据视图。这种能力对于网络不稳定、带宽受限的工业场景至关重要。
-
-
灵活强大的查询语言 (IoT-SQL):IoTDB 提供了类 SQL 的查询语言,学习成本低。同时,它针对时序场景做了大量增强,如设备对齐查询(一次性查询同一设备下所有测点在同一时间戳的值)、降采样、值域过滤、时间窗口聚合等,让复杂的时序分析变得简单直观。
场景实践:以"智慧工厂"为例的选型之路
理论的魅力最终需要通过实践来检验。让我们构建一个虚拟但真实的案例,看一家大型制造企业------"未来重工",是如何在数字化转型中,最终选择 IoTDB 构建其设备监控与预测性维护平台的。
初始阶段:Excel 与关系型数据库的挣扎
"未来重工"最初尝试使用 Excel 手动记录关键设备的运行参数,很快就因数据量和维护问题而放弃。随后,他们转向使用 MySQL 数据库,将每个测点的数据存成一张表。但随着产线上设备和传感器数量的增加,问题接踵而至:
-
数据库表数量爆炸式增长,难以管理。
-
写入并发量达到每秒数万点时,MySQL 出现严重瓶颈,大量数据被丢弃。
-
对设备进行跨时间、跨指标的分析查询,需要复杂的
JOIN操作,查询耗时以分钟计。
演进之路:拥抱大数据,选择 IoTDB
在意识到传统方案的局限后,"未来重工"决定构建一个现代化的数据平台。他们的目标很明确:新平台必须能够支撑海量数据,并且能与公司正在建设的基于 Spark 的数据分析平台无缝集成。在评估了多个 TSDB 方案后,他们最终选择了 Apache IoTDB。
最终的数据架构图:
数据流转过程:
-
数据采集与边缘处理:在每个车间的边缘服务器上部署轻量级的 IoTDB Edge。产线上的设备数据通过 MQTT 协议高并发地写入 EdgeIoTDB。EdgeIoTDB 利用其本地存储和计算能力,进行数据清洗和1分钟级别的预聚合。
-
云端同步与存储:EdgeIoTDB 定期(例如每分钟)将聚合后的数据和部分原始明细数据,通过数据同步工具高效、可靠地传输到云端的 IoTDB 集群中。云端集群负责数据的长期归档和统一存储。
-
深度分析与机器学习 :公司的算法团队使用 Spark,通过
iotdb-spark连接器直接读取云端 IoTDB 中的设备历史数据。他们无需进行数据导出,即可在 Spark 上运行复杂的设备健康度评估模型和故障预测算法,并将预测结果写回 IoTDB。 -
实时监控与告警 :运维团队使用 Flink,通过
iotdb-flink连接器实时消费 IoTDB 的新数据流。当检测到设备震动、温度等指标超过预设阈值时,Flink 作业会立即触发告警系统,通知相关人员。 -
可视化展现:管理层和现场工程师通过 Grafana 仪表盘,实时监控整个工厂的设备运行状态。Grafana 直接连接到云端 IoTDB,提供了从宏观概览到微观细节的下钻分析能力。
通过这套架构,"未来重工"不仅解决了数据存储和查询的性能瓶颈,更重要的是,他们将时序数据无缝地融入了企业的大数据战略中,打通了从数据采集到智能应用的全链路,真正实现了"数据驱动制造"。
总结与行动指南
在今天,选择一个时序数据库,早已不是选择一个孤立的软件,而是选择一个能够与您现有技术体系共生共荣的"生态伙伴"。当企业的数据战略已经或即将拥抱大数据和人工智能时,TSDB 与大数据生态的融合度就成为了选型中最关键的考量因素。
Apache IoTDB 凭借其原生的分布式架构、与 Spark/Flink/Hadoop 的无缝集成能力、开放的 TsFile 存储格式以及独特的"端-边-云"协同设计,为大数据和 AIoT 时代提供了一个近乎完美的答案。它不仅是一个高性能的时序数据存储引擎,更是一个连接物理世界和数字智能的强大桥梁。
如果您的企业也正面临海量时序数据的挑战,如果您希望将这些数据转化为驱动业务增长的燃料,那么,现在就是开始了解和使用 Apache IoTDB 的最佳时机。
立即开始你的 IoTDB 之旅:
-
下载 Apache IoTDB 开源版 :iotdb.apache.org/zh/Download...
-
寻求企业级支持与更强性能?了解 Timecho 企业版 :timecho.com