一、YARN 与 MapReduce 基础关系
(一)依赖关系:从 "运行载体" 到 "生态绑定" 的深度关联
- 底层运行依赖 :MapReduce 作为 Hadoop 早期的核心计算框架,本身不具备资源管理能力 ------ 它无法主动申请服务器的 CPU、内存,也不能协调多任务间的资源冲突。而 YARN(Yet Another Resource Negotiator)作为 Hadoop 2.x 后新增的资源调度平台,恰好填补了这一空白:MapReduce 程序的每一个计算任务(Map Task、Reduce Task),都必须通过 YARN 申请资源容器(Container),在容器分配的资源范围内运行,没有 YARN 的资源调度支持,MapReduce 程序会因 "无资源可用" 而无法启动。
- 学习与部署的同步性:在实际企业部署中,YARN 与 MapReduce 的配置、启动、运维高度绑定。例如,若仅部署 MapReduce 而不配置 YARN,MapReduce 程序会处于 "待机状态";若仅启动 YARN 而未正确关联 MapReduce,YARN 会成为 "空转的资源调度器"。因此,二者的学习需同步进行,理解 MapReduce 的计算逻辑必须结合 YARN 的资源分配逻辑,反之亦然。
(二)资源调度核心逻辑:从 "资源定义" 到 "调度价值" 的全维度解析
- 资源定义:分布式场景下的硬件资源范畴
-
- 核心资源:CPU(计算能力,以 "虚拟核" 为单位,1 个虚拟核约对应物理 CPU 的 1 个线程)、内存(存储计算过程中的临时数据,以 MB/GB 为单位)------ 这两类资源是 YARN 调度的核心,直接决定任务能否运行及运行效率。
-
- 辅助资源:硬盘(存储 MapReduce 的中间结果、日志文件,需具备高 IO 性能)、网络(节点间数据传输的通道,如 Map 任务向 Reduce 任务传输数据的 "Shuffle" 过程,依赖稳定的网络带宽)。
- 资源调度的核心作用:解决 "无序竞争" 与 "资源浪费"
-
- 管控无序竞争:在分布式集群中,若多个 MapReduce 程序同时运行,会出现 "资源争抢"------ 例如程序 A 占用过多内存,导致程序 B 因内存不足被 "杀死"。YARN 通过 "统一资源池" 机制,将集群所有节点的 CPU、内存整合为 "全局资源池",按任务优先级、资源需求统一分配,避免无序竞争。
-
- 提升资源利用率:单机环境下,单个程序可能仅使用服务器 10% 的 CPU;而 YARN 通过 "多任务并发",在同一节点上为多个程序分配独立容器,使 CPU、内存利用率提升至 70%-80%(企业级集群常见水平)。
- 生活类比:更贴近技术逻辑的场景映射
-
- 类比场景 1:商场停车场管理
无 YARN 调度的集群类似 "无人管理的停车场":车主(程序)随意占用多个车位(资源),新到车主(新程序)找不到车位;而 YARN 类似 "停车场管理员":先登记车主需求(程序资源申请),按车型(任务类型)分配固定车位(容器),同时统计空车位(剩余资源),确保每辆车(任务)有车位,且车位不浪费。
-
- 类比场景 2:餐厅后厨出餐
MapReduce 程序类似 "点餐顾客",需要厨师(CPU)、厨具(内存)完成菜品(计算任务);YARN 类似 "后厨经理":统一分配厨师、厨具给不同订单(任务),避免某一订单占用所有厨师(资源浪费),同时确保订单按优先级出餐(任务调度)。
-
- 关键差异:程序无 "资源节省意识"
人类在使用公共资源时会主动节省(如停车仅占 1 个车位),但程序会 "最大化占用资源"------ 例如 MapReduce 程序若不限制内存,会持续申请内存直到服务器内存耗尽。因此 YARN 必须通过 "强制资源限制"(如为容器设置最大内存),避免程序过度占用资源。
二、YARN 核心架构与组件
(一)核心角色:主从架构的 "分工与协作" 逻辑
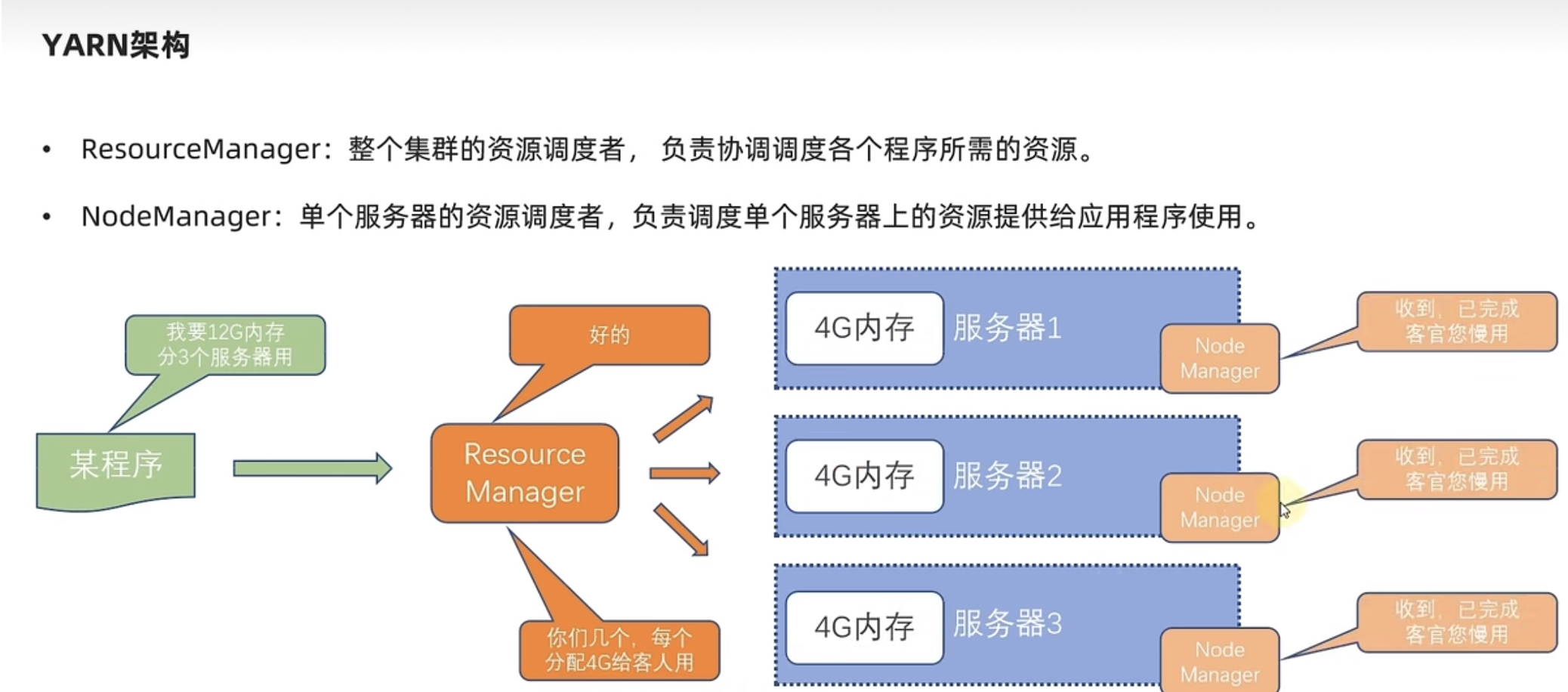
1. ResourceManager(RM):集群资源的 "总指挥官"
- 角色定位:YARN 集群的 "主节点进程",仅在集群中 1 个节点(通常是配置最高的节点)运行,负责全局资源调度与任务管理。
- 核心功能细化:
-
- 资源池管理:实时收集所有 NodeManager 上报的节点资源(CPU 总核数、内存总大小、已用资源、剩余资源),维护 "全局资源视图"------ 例如集群共 10 个节点,每个节点 8 核 CPU、32GB 内存,RM 会实时统计 "总资源:80 核 CPU、320GB 内存;已用资源:40 核 CPU、160GB 内存;剩余资源:40 核 CPU、160GB 内存"。
-
- 任务调度决策:当 MapReduce 程序提交任务时,RM 会先审核任务的资源申请(如需要 2 核 CPU、4GB 内存),再从 "剩余资源池" 中匹配合适的 NodeManager 节点,向该节点发送 "资源分配指令"。
-
- 任务生命周期监控:跟踪所有运行中任务的状态(初始化、运行中、成功、失败),若某任务因资源不足失败,RM 会重新调度该任务(如重新分配资源、选择其他节点运行)。
- 关键特性:RM 是 YARN 的 "单点核心",若 RM 故障会导致整个 YARN 集群无法调度任务,因此企业级集群通常会配置 RM 高可用(HA)------ 通过 2 个 RM 节点(Active 主节点、Standby 备用节点),当 Active 节点故障时,Standby 节点自动接管,避免集群中断。
2. NodeManager(NM):单机资源的 "执行者"
- 角色定位:YARN 集群的 "从节点进程",在集群所有节点(如文档中的 node1、node2、node3)运行,负责单个节点的资源管理与容器维护。
- 核心功能细化:
-
- 资源上报:每隔 3 秒(默认配置)向 RM 上报当前节点的资源状态 ------ 例如 "node2 节点:CPU 总 8 核,已用 4 核,剩余 4 核;内存总 32GB,已用 16GB,剩余 16GB",确保 RM 的 "全局资源视图" 实时准确。
-
- 容器创建与管理:接收 RM 的 "资源分配指令" 后,在本地节点创建容器(Container)------ 具体操作包括:为容器分配指定的 CPU 核数(通过 Linux 的 cgroups 限制 CPU 使用率)、分配指定的内存大小(通过 cgroups 限制内存使用,避免内存溢出)、为容器设置独立的运行环境(如 JDK 路径、Hadoop 配置路径)。
-
- 任务运行监控:实时监控容器内运行的 MapReduce 任务(如 Map Task、Reduce Task),若任务占用资源超过容器限制(如内存使用超 4GB),NM 会强制 "杀死" 该容器,避免影响节点其他任务;同时将任务状态(如 "容器被杀死")上报给 RM。
- 关键特性:NM 仅管理本地节点资源,不参与全局调度,这种 "主从分工" 确保 YARN 集群可横向扩展 ------ 即使新增 100 个节点,只需在新节点部署 NM 并接入 RM,即可纳入集群资源池。
(二)辅助角色:保障集群 "安全" 与 "可追溯" 的关键组件
1. ProxyServer(Web 应用代理):YARN WEB UI 的 "安全守门人"
- 核心价值:解决 YARN WEB UI 的访问安全问题。若直接暴露 ResourceManager 的 WEB 端口(如 8088),外部攻击者可能通过 WEB UI 获取集群敏感信息(如任务运行日志、节点 IP),甚至尝试注入恶意请求攻击 RM;而 ProxyServer 作为 "中间代理层",可过滤不安全请求,保护 RM 安全。
- 功能细化:
-
- 访问过滤:拦截来自 "未授权 IP" 的访问请求(可通过配置白名单实现),仅允许企业内部 IP 访问 WEB UI;同时过滤包含恶意代码(如 SQL 注入、XSS 脚本)的请求,避免 RM 被攻击。
-
- Cookie 与会话管理:剥离访问请求中的无关 Cookie(如用户浏览器的第三方 Cookie),仅保留 YARN 认证所需的会话 Cookie,防止 Cookie 劫持攻击;同时限制单个 IP 的并发会话数,避免恶意用户占用过多连接资源。
-
- 请求转发与日志记录:将过滤后的合法请求转发给 RM,再将 RM 的响应结果返回给用户;同时记录所有访问日志(如访问 IP、访问时间、请求路径、响应状态),便于后续安全审计(如排查 "异常 IP 频繁访问" 问题)。
- 部署与配置细节:
-
- 默认集成与分离部署:ProxyServer 默认集成在 RM 进程中,无需单独启动;若集群对安全要求较高(如金融、政务场景),可通过配置yarn.web-proxy.address=node1:8089将其分离部署 ------ 此时 ProxyServer 会作为独立进程运行,即使 RM 故障,ProxyServer 仍可拦截请求,避免直接暴露 RM。
-
- 启动与验证 :分离部署时,通过命令$HADOOP_YARN_HOME/sbin/yarn-daemon.sh start proxyserver启动进程,启动后可通过jps命令查看 "WebAppProxyServer" 进程;访问http://node1:8089,若能正常跳转至 YARN WEB UI(8088 端口),说明 ProxyServer 配置生效。
2. JobHistoryServer(历史服务器):任务日志的 "存储与查询中心"
- 核心价值:解决 MapReduce 任务 "日志丢失" 与 "运行追溯" 问题。MapReduce 任务运行在 YARN 容器中,任务结束后容器会被 NM 销毁,容器内的运行日志(如任务报错信息、数据处理量统计)也会随之删除;而 JobHistoryServer 可提前抓取日志并集中存储,便于后续排查任务失败原因、分析任务运行性能。
- 功能细化:
-
- 日志聚合与存储:依赖 YARN 的 "日志聚合" 功能(需配置yarn.log-aggregation-enable=true),任务结束后,NM 会将容器内的日志(默认存储在节点本地$HADOOP_LOG_DIR/userlogs目录)压缩后上传至 HDFS 的指定路径(如/tmp/logs);JobHistoryServer 会实时监听 HDFS 的日志路径,将日志解析为结构化数据(如任务 ID、运行时间、Map/Reduce 数量、错误信息),存储在本地数据库(如 Derby)中。
-
- 历史任务查询:提供 WEB UI(默认端口 19888),用户可通过任务 ID、提交时间、用户名等条件查询历史任务 ------ 例如输入任务 ID "job_1620000000000_0001",可查看该任务的运行状态(成功 / 失败)、Map/Reduce 任务数量、每个任务的运行日志、数据输入 / 输出量等信息。
-
- 日志下载与分析:在 WEB UI 中,用户可下载完整的任务日志(压缩格式),用于本地分析(如用文本工具搜索 "ERROR" 关键词定位报错原因);同时支持查看 "任务运行统计图表"(如 Map 任务运行时间分布、Reduce 任务数据处理量趋势),帮助优化任务配置(如调整 Map 任务数量以提升效率)。
- 配置与启动细节:
-
- 关键配置:除开启日志聚合(yarn.log-aggregation-enable=true)外,还需配置 HDFS 日志存储路径(yarn.nodemanager.remote-app-log-dir=/tmp/logs)、日志保留时间(如yarn.log-aggregation.retain-seconds=604800,表示保留 7 天日志)、JobHistoryServer 的 WEB 端口(mapreduce.jobhistory.webapp.address=node1:19888)。
-
- 启动验证:通过命令$HADOOP_HOME/bin/mapred --daemon start historyserver启动进程,启动后用jps查看 "JobHistoryServer" 进程;访问http://node1:19888,若能看到 "Job History" 页面且显示历史任务列表,说明配置生效。
(三)YARN 容器(Container):资源分配的 "最小单位"
- 本质定义:Container 不是物理容器,而是 YARN 通过 Linux cgroups(Control Groups)技术实现的 "资源隔离单元"------ 它为 MapReduce 任务划定了一块 "独立的资源区域",包含指定的 CPU、内存资源,且任务只能在该区域内运行,无法占用区域外的资源。
- 核心特性细化:
-
- 资源隔离性:通过 cgroups 限制容器的 CPU 使用率(如分配 2 核 CPU,容器最多只能使用 2 核的计算能力)、内存使用量(如分配 4GB 内存,容器使用内存超过 4GB 时会被 NM 强制杀死),确保多个容器在同一节点运行时互不干扰 ------ 例如容器 A 的任务内存溢出,仅会导致容器 A 被销毁,不会影响容器 B 的正常运行。
-
- 资源可定制性:Container 的资源配置(CPU 核数、内存大小)由 MapReduce 任务的需求决定,且可动态调整 ------ 例如处理小数据量的 Map 任务,可分配 1 核 CPU、2GB 内存;处理大数据量的 Reduce 任务,可分配 4 核 CPU、8GB 内存,实现 "按需分配"。
-
- 生命周期与任务绑定:Container 的生命周期与其中运行的 MapReduce 任务完全一致 ------ 任务启动时,NM 创建容器;任务运行中,容器持续提供资源;任务结束(成功 / 失败)后,NM 销毁容器,释放资源回节点资源池,供其他任务使用。
- 技术实现原理:以内存隔离为例,NM 在创建容器时,会通过 Linux 命令echo 4294967296 > /sys/fs/cgroup/memory/yarn/container_123/memory.limit_in_bytes(4294967296 字节 = 4GB),为容器设置内存上限;当容器内任务的内存使用超过 4GB 时,Linux 内核会触发 "Out Of Memory(OOM)" 机制,杀死该任务进程,NM 则会将 "容器内存溢出" 的状态上报给 RM。