有很多童鞋不知道怎么制作符合自己的视频,特别是孩子的作业或者比赛要求一个诗朗诵或者录制一段视频,要求有背景,融入自己的画像,再配上文字这种。应广大童鞋的要求上一个视频编辑说明,其实这东西很简单,与AI本身都不沾边,我是指使用者,顶多是抠图过程需要AI图像算法结合一点AI的东西处理下视频。废话不多说,直接上干货。
如果你手边只有一个手机,那就用类似剪映的工具就可以直接制作。下面已剪映app 为例,手把手教会大家怎么做这种视频。
1)导入背景视频。这部非常简单,我就不说了,直接导入视频即可。
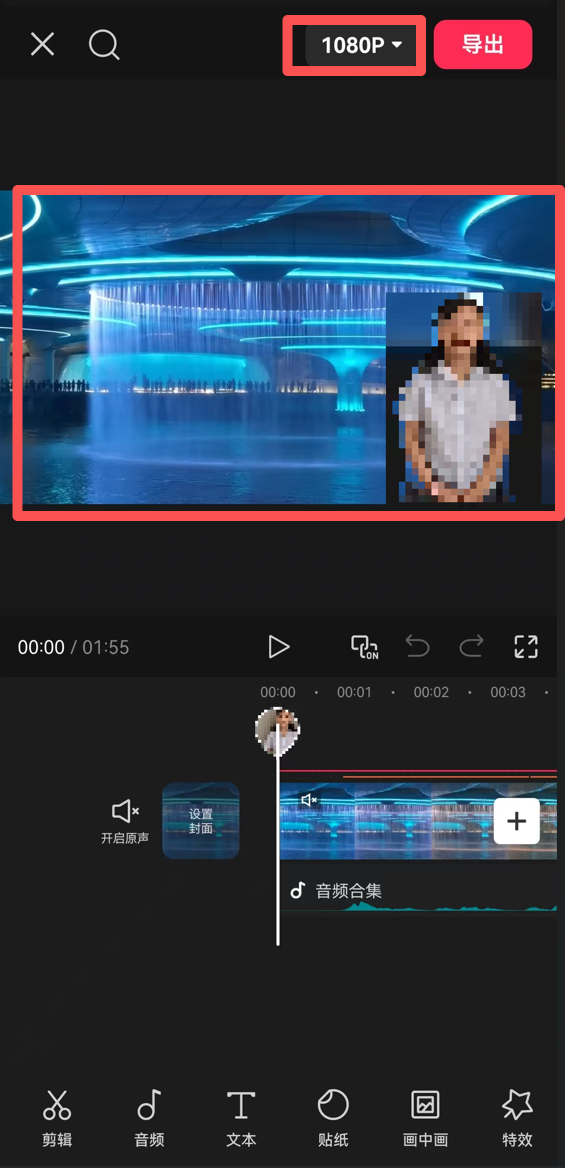
注意,如果你的手机处理性能不行,可以把最上面的分辨率调低一些,比如720p,480p。
开始导入的时候,只有背景,其他的人物,声音,还没有。因为我随便找了一个视频来做,所以里面展示的元素是最后完成的效果,可以先忽略。后面会讲。
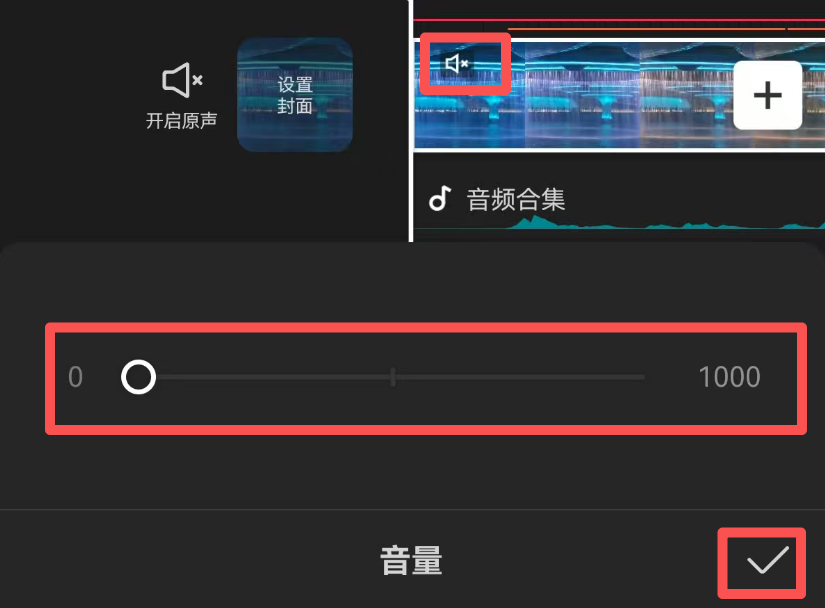
2)去掉背景的声音,如果需要。在这个视频中,我需要去掉背景的声音,怎么处理?直接单击声音,将 音量调为0即可。
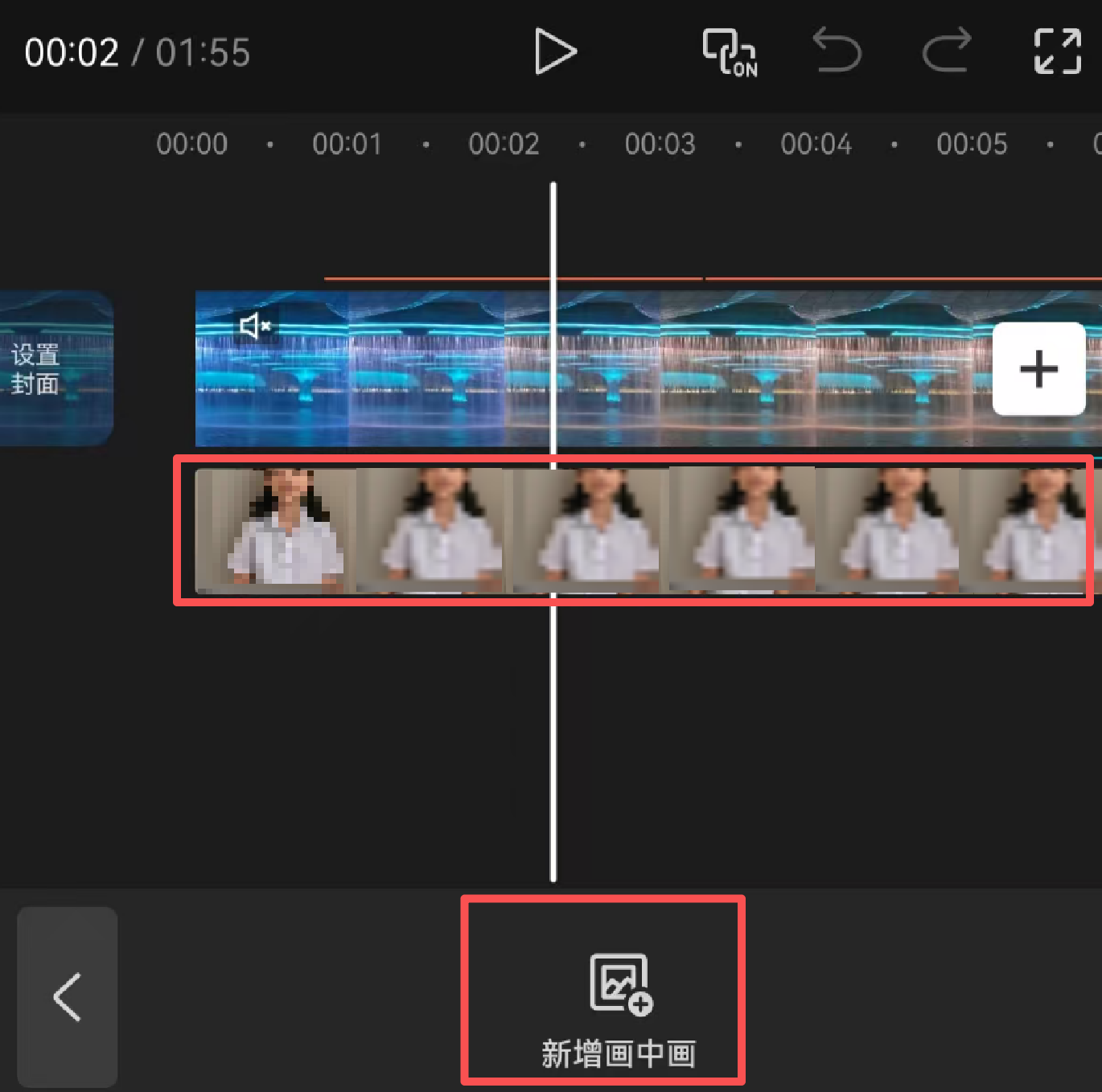
3)导入人物背景,在剪映中就是画中画功能。
需要说明的是,剪映 本身只只支持 两层 视频图层。也就是说,视频有且仅有一个画中画。朋友可能会问,我要多个画中画怎么办?没关系,先做好一个,再用这个作为基底往上添加。整体思路 就是 要使得最终结果为3画叠加。就是 1+1=2,然后 2+1=3。导入画中画。此时下方会多一个画中画的视频轨道。
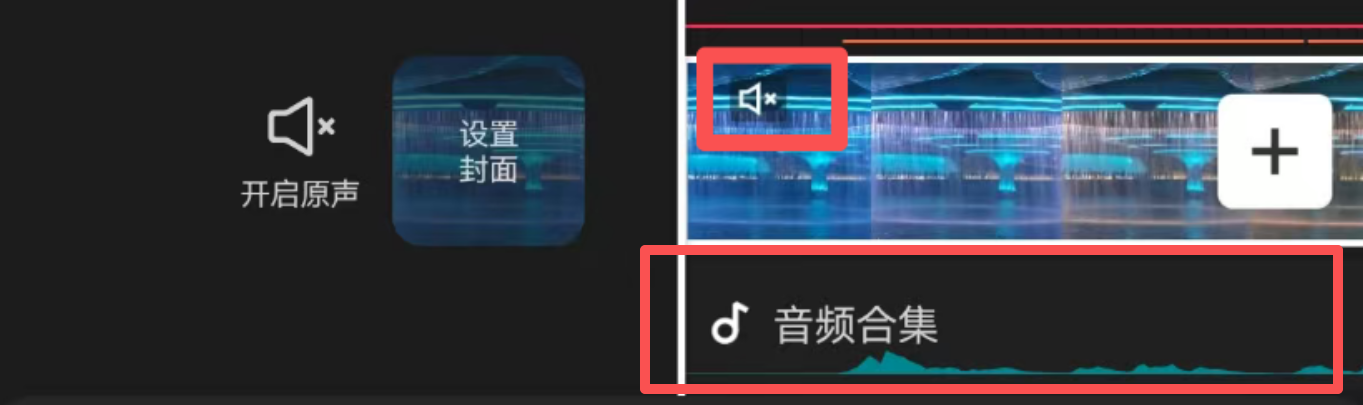
4)提取画中画的声音。因为剪映app只能将主轨声音识别成文字,所以,我们第一步需要提取出画中画的声音。方法如下:直接选中画中画,提取音频。此时,会多一个这样的音频轨道:
5)点击文字,识别文字,即可转成文字展示,需要的效果你自己选。
6)回到画中画,用抠图功能,将背景去掉,只留下人物。

7)整体完成,导出即可。
