本教程主要提供DeepSeek-V3.1-Terminus/DeepSeek-V3.2-Exp在华为昇腾910B 安装部署指南,从系统固件安装→ 模型量化→ 服务环境安装启动全流程配置。
温馨提示:过程中有任何问题可以去华为昇腾提交工单或者社区发帖讨论奥!
一、物理机器环境
1.1 物理机配置
| 服务器(NPU) | CPU | NPU | 内存 | 存储 |
|---|---|---|---|---|
| 910B2 | 192核 | 8* 64G | 2048GB | 2*3T |
| 910B2 | 192核 | 8* 64G | 2048GB | 2*3T |
1.2 查看操作系统和内核版本
bash
# 查看内核版本
uname -r
# 查看 /etc/os-release 文件
cat /etc/os-release| 组件 | 版本/说明 |
|---|---|
| 操作系统 | 银河麒麟 V10 |
| 内核版本 | 4.19.90-52.22.v2207.ky10.aarch64 |
Tips:
DeepSeek-V3.1-Terminus-w8a8的量化版部署需要2台昇腾910B 物理机服务器,w4a8量化版需要1台昇腾910B 物理机服务器,DeepSeek-V3.2-Exp-w8a8的量化版同样需要2台昇腾910B物理机服务器。
二、环境准备
2.1 系统更新与依赖安装
bash
# 更新系统包管理器
yum update -y && yum makecache -y
# 安装内核开发工具(需与当前内核版本匹配)
yum install -y make dkms gcc kernel-headers-$(uname -r) kerneldevel-$(uname -r)2.2 检查现有驱动状态
bash
# 检测所有NPU设备的版本信息
for i in {0..7}; do
npu-smi info -t board -i $i | grep Version 2>/dev/null
done输出说明:
- 若显示
Software Version和Firmware Version,则已安装驱动,无需安装下面的NPU 驱动与固件安装 - 若无输出或报错,需继续安装流程
三、NPU 驱动与固件安装
3.1 获取安装包
官方渠道 :访问昇腾社区 → 然后根据自己的服务器系统 CPU 架构、昇腾芯片型号官网下载:
bash
https://support.huawei.com/enterprise/zh/ascend-computing/ascend-hdk-pid-252764743/software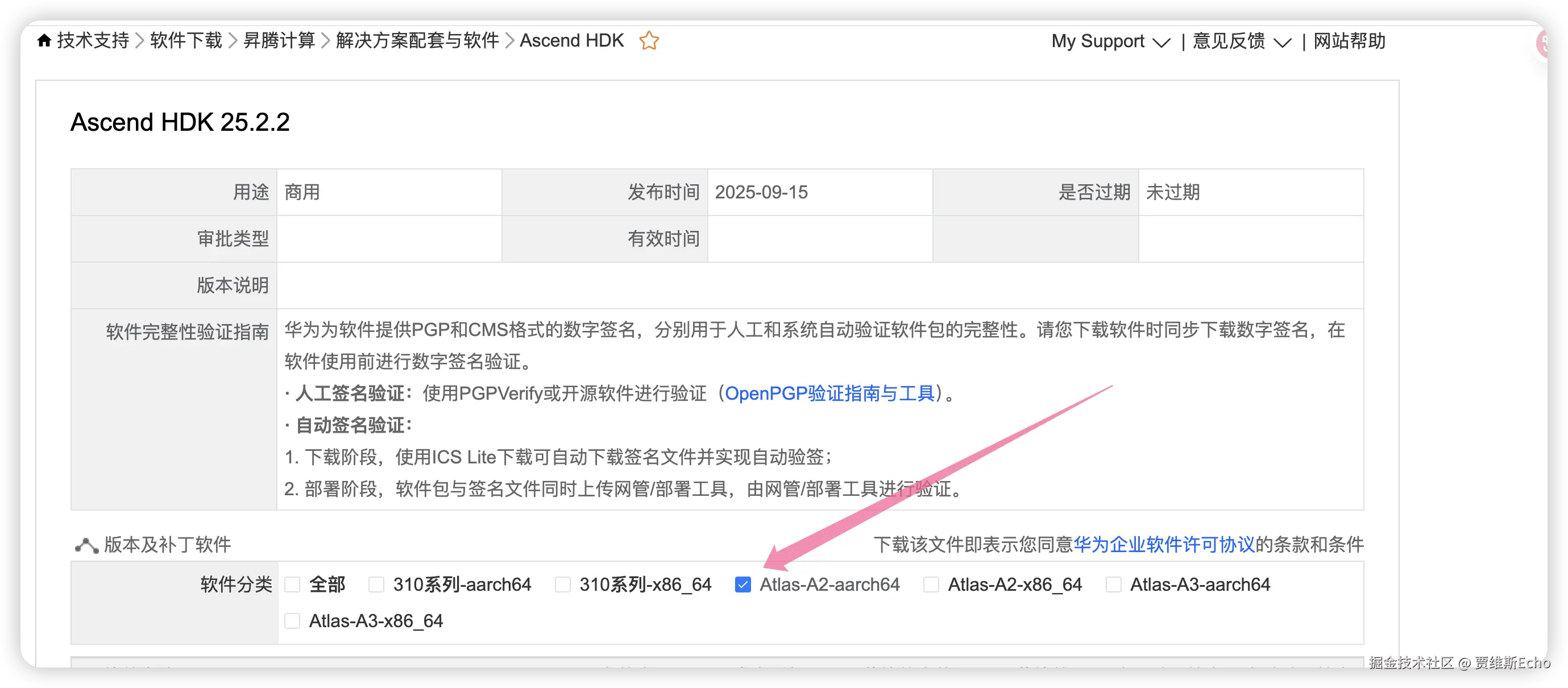
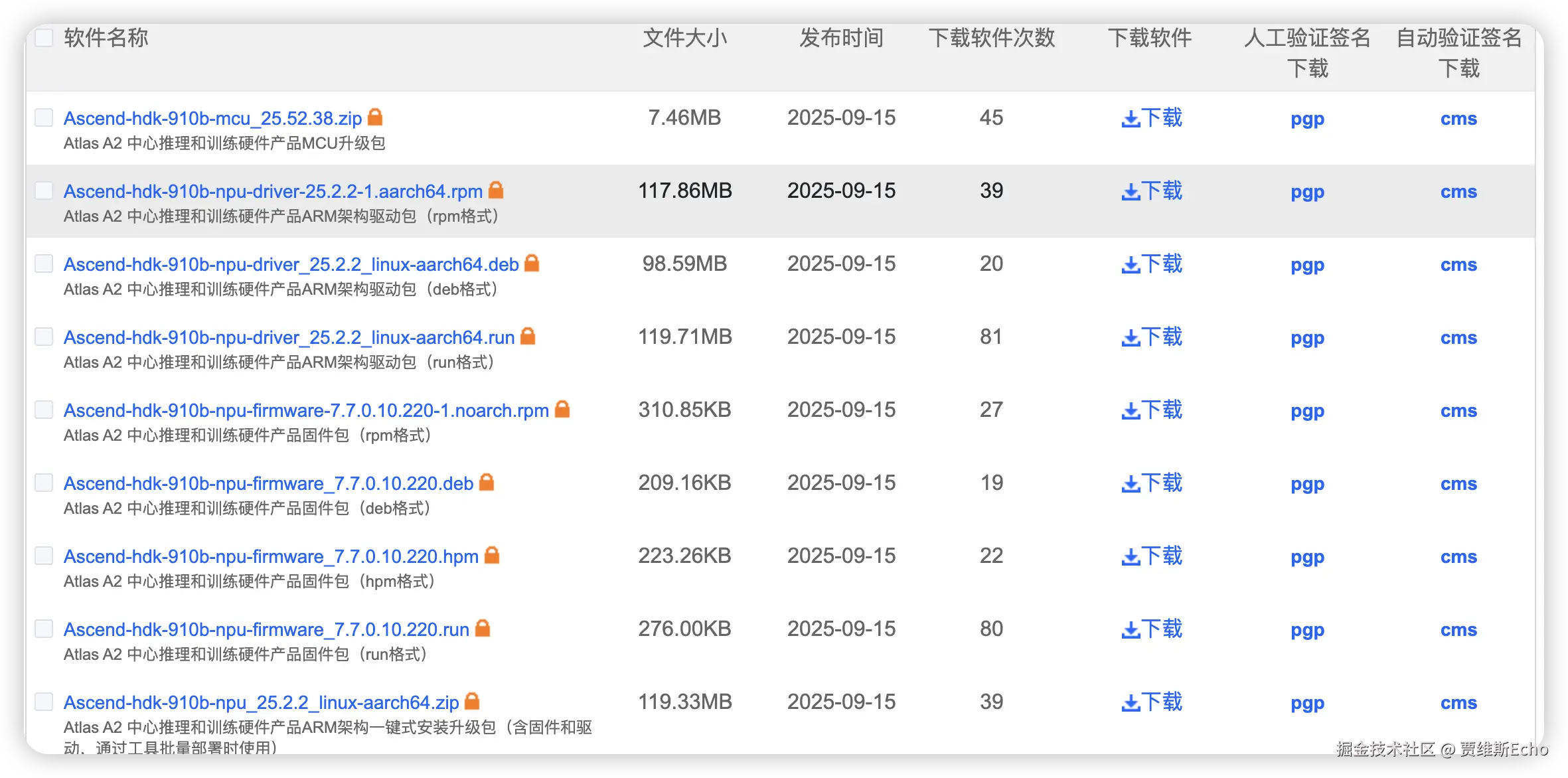
需要下载的驱动固件如下:
arduino
Ascend-hdk-910b-npu-driver_25.2.2_linux-aarch64.run
Ascend-hdk-910b-npu-firmware_7.7.0.10.220.run3.2 安装前准备
bash
# 授予执行权限
chmod +x Ascend-hdk-910b-npu-driver_25.2.2_linux-aarch64.run
chmod +x Ascend-hdk-910b-npu-firmware_7.7.0.10.220.run
# 确认权限(应以root用户执行)
[[ $(id -u) -eq 0 ]] || echo "请切换到root用户执行安装"3.3 安装驱动
css
# 完整安装(包含工具链)
./Ascend-hdk-910b-npu-driver_25.2.2_linux-aarch64.run \
--full --install-for-all成功标志 :终端显示 Driver package installed successfully!
3.4 安装固件
arduino
./Ascend-hdk-910b-npu-firmware_7.7.0.10.220.run --full成功标志 :显示 Firmware package installed successfully! 并提示重启生效
3.5 安装验证
bash
# 重启系统使驱动生效
reboot
# 检查设备状态
npu-smi info预期输出:应显示所有NPU设备的详细信息,包括:
- 固件版本号
- 内存与功耗状态
四、安装 CANN 核心组件
CANN 核心组件包括 Toolkit(开发套件)、Kernels(算子包)、NNAL(神经网络加速库)等,这里我们选择安装 Toolkit 套件,满足训练、推理及开发调试需求。
4.1 配置yum 源
bash
sudo curl https://repo.oepkgs.net/ascend/cann/ascend.repo -o /etc/yum.repos.d/ascend.repo && yum makecache
# 查询软件包列表
yum list Ascend-cann-* --showduplicates4.2 安装CANN
4.2.1 安装依赖
安装前需确保已具备Python环境及pip3,当前CANN支持Python3.7.x至3.11.4版本,若不满足可执行以下命令安装。
sudo yum install -y python3 python3-pip安装业务运行时依赖的Python第三方库。
ini
pip3 install attrs cython 'numpy>=1.19.2,<=1.24.0' decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20.0 scipy requests absl-py4.2.2 安装Toolkit开发套件包
sudo yum install -y Ascend-cann-toolkit-8.2.RC1PS : 默认
root用户安装路径如下:"/usr/local/Ascend",非root用户:"${HOME}/Ascend",${HOME}为当前用户目录。
配置Toolkit环境变量,当前以root用户默认路径为例,请用户根据set_env.sh的实际路径执行如下命令
bash
source /usr/local/Ascend/ascend-toolkit/set_env.sh上述环境变量配置只在当前窗口生效,用户可以按需将以上命令写入环境变量配置文件(如.bashrc文件)。
4.2.3 安装Kernels算子包
Kernels算子包安装之前,需已安装配套版本的Toolkit并配置环境变量。
yum install -y Ascend-cann-kernels-910b-8.2.RC14.2.4 安装NNAL神经网络加速库
NNAL神经网络加速库中提供了ATB(Ascend Transformer Boost)加速库和SiP(AscendSiPBoost)信号处理加速库。
加速库安装之前,需已安装同一版本的Toolkit并配置环境变量。
sudo yum install -y Ascend-cann-nnal-8.2.RC1五、安装 Miniconda
bash
# 1、下载安装文件:从Miniconda 官网下载 Linux aarch64 版本的安装包
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-aarch64.sh
# 2、安装Miniconda3
bash Miniconda3-latest-Linux-aarch64.sh
# 安装过程到最后会询问是否要加入对应的路径,安装程序会建议选no
# 如果选了no 则需要进行下列步骤手动激活环境
eval "$(/root/miniconda3/bin/conda shell.bash hook)"
echo 'eval "$(/root/miniconda3/bin/conda shell.bash hook)"' >>~/.bashrc
source ~/.bashrc
# 3、验证安装
conda --version六、量化模型
这里已经量化好了,可以使用我直接量化好的模型,或者可以跟着我一步一步实践一下量化模型。
- DeepSeek-V3.2-Exp-w8a8:modelscope.cn/models/taox...
- DeepSeek-V3.1-Terminus-w4a8:modelscope.cn/models/taox...
- DeepSeek-V3.1-Terminus-w8a8:modelscope.cn/models/taox...
- DeepSeek-V3.1-Terminus-w8a8c8:modelscope.cn/models/taox...
6.1 modelscope 下载模型
这里使用modelscope 下载模型,安装modelscope 依赖,Python 版本需要>=3.10
pip install modelscope下载DeepSeek-V3.2-Exp 模型或DeepSeek-V3.1-Terminus
bash
# 下载 DeepSeek-V3.2-Exp
nohup modelscope download --model deepseek-ai/DeepSeek-V3.2-Exp --local_dir ./model/DeepSeek-V3.2-Exp > ./dd.log 2>&1 &
# 下载 DeepSeek-V3.1-Terminus
nohup modelscope download --model deepseek-ai/DeepSeek-V3.1-Terminus --local_dir ./model/DeepSeek-V3.1-Terminus > ./dd.log 2>&1 &由于昇腾不支持flash_attn库,运行时需要注释掉权重文件夹 中modeling_deepseek.py中的如下代码。
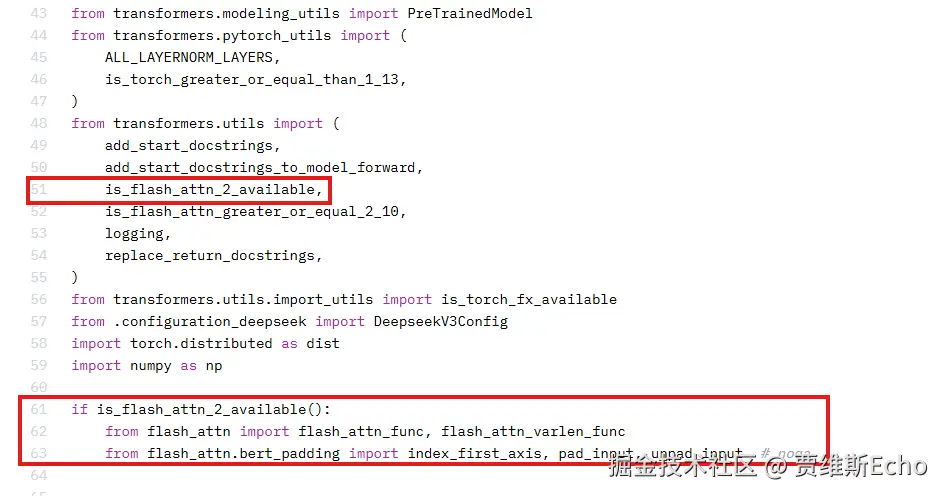
6.2 创建与安装量化环境
bash
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:False
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
# 创建虚拟环境
conda create -y -n msit_env python=3.10
conda activate msit_env
# 安装依赖包
pip3 install attrs cython 'numpy>=1.19.2,<=1.24.0' decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20.0 scipy requests absl-py
pip install torch==2.7.1 torch_npu==2.7.1rc1
pip install transformers==4.48.2
git clone https://gitcode.com/Ascend/msit.git
cd ./msit/msmodelslim
bash install.sh 6.3 DeepSeek-V3.1 W8A8C8 混合量化 + MTP 量化
bash
git clone https://gitcode.com/Ascend/msit.git
cd ./msit/msmodelslim/example/DeepSeek
# DeepSeek-V3.1 W8A8C8 混合量化 + MTP 量化
nohup python3 quant_deepseek_w8a8.py \
--model_path ./model/DeepSeek-V3.1-Terminus \
--save_path ./model/DeepSeek-V3.1-Terminus-w8a8c8 \
--batch_size 8 \
--anti_dataset ./anti_prompt_50_v3_1.json \
--calib_dataset ./calib_prompt_50_v3_1.json \
--anti_method m4 \
--quant_mtp mix \
--rot \
--fa_quant > ./quant_w8a8c8.log 2>&1 &
tail -f quant_w8a8.log6.4 DeepSeek-V3.1 W8A8 混合量化 + MTP 量化
lua
nohup python3 quant_deepseek_w8a8.py \
--model_path ./model/DeepSeek-V3.1-Terminus \
--save_path ./model/DeepSeek-V3.1-Terminus-w8a8 \
--batch_size 8 \
--anti_dataset ./anti_prompt_50_v3_1.json \
--calib_dataset ./calib_prompt_50_v3_1.json \
--anti_method m4 \
--quant_mtp mix \
--rot > quant_w8a8.log 2>&1 &
tail -f quant_w8a8.log6.5 DeepSeek-V3.1 W4A8 混合量化 + MTP 量化
bash
# 生成DeepSeek-V3.1 W4A8 混合量化 + MTP 量化
nohup python3 quant_deepseek_w4a8.py \
--model_path ./model/DeepSeek-V3.1-Terminus \
--save_path ./model/DeepSeek-V3.1-Terminus-w4a8 \
--anti_dataset ./anti_prompt_50_v3_1.json \
--calib_dataset ./calib_prompt_50_v3_1.json \
--quant_mtp mix \
--batch_size 8 > ./quant_w4a8.log 2>&1 &
tail -f quant_w4a8.log6.6 DeepSeek-V3.2-Exp(含MTP层) W8A8 混合量化
lua
nohup msmodelslim quant \
--model_path ./model/DeepSeek-V3.2-Exp \
--save_path ./model/DeepSeek-V3.2-Exp-w8a8 \
--model_type DeepSeek-V3.2-Exp \
--quant_type w8a8 \
--device npu \
--trust_remote_code True > quant_v3.2_exp_w8a8.log 2>&1 &
tail -f quant_v3.2_exp_w8a8.log七、 检查多节点通讯环境
7.1 显卡网络通信检查
链路检查 :在每台机器上分别执行下列命令,确保返回状态均为 success 且端口为 UP:
bash
# 检查远端交换机端口
for i in {0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done
# 查看网口链路状态(UP/DOWN)
for i in {0..7}; do hccn_tool -i $i -link -g; done
# 网络健康检查
for i in {0..7}; do hccn_tool -i $i -net_health -g; done
# 查看检测到的IP配置
for i in {0..7}; do hccn_tool -i $i -netdetect -g; done
# 查看网关配置
for i in {0..7}; do hccn_tool -i $i -gateway -g; done
# 查看 NPU 网络配置文件
cat /etc/hccn.conf7.2 获取 NPU IP
获取 NPU IP :用 hccn_tool -ip -g 获取各 NPU IP 地址:
bash
for i in {0..7}; do hccn_tool -i $i -ip -g | grep ipaddr; done7.3 跨节点NPU 网络测试
跨节点网络测试 :在任一节点上用 hccn_tool -ping 测试与另一节点的连通性:
css
hccn_tool -i 0 -ping -g address <对方NPU_IP>八、部署DeepSeek-V3.1-Terminus 模型
8.1 W4A8 量化版部署
为了降低部署门槛,我们先使用 GPUStack快速上手部署,通过少量 UI 配置快速高效。
1、在节点1启动 Server 与内置 Worker:
bash
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware:ro \
-v /etc/hccn.conf:/etc/hccn.conf:ro \
-v /etc/ascend_install.info:/etc/ascend_install.info:ro \
-v /mnt/data/app_data/gpustack/:/var/lib/gpustack \
-v /mnt/data/model:/data/models \
-v /etc/localtime:/etc/localtime:ro \
--shm-size=500g \
--network=host \
--ipc=host \
--env TZ="Asia/Shanghai" \
crpi-thyzhdzt86bexebt.cn-hangzhou.personal.cr.aliyuncs.com/gpustack_ai/gpustack:v0.7.1-npu-vllm-v0.9.1 \
--cache-dir /data/models \
--port 8888启动命令假设提前下载好的模型的存储路径,包括后续通过 GPUStack 联网搜索 Hugging Face/ModelScope 下载的模型存储路径均为
/data/models,可按实际修改,多节点需要统一路径
查看容器日志确认 GPUStack 是否已正常运行:
docker logs -f gpustack若容器日志显示服务启动正常,使用以下命令获取 GPUStack 控制台的初始登录密码和用于其它节点加入 GPUStack 的认证 Token:
bash
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
docker exec gpustack cat /var/lib/gpustack/token2、在其它节点启动 Worker 并注册到节点1的 GPUStack,按实际修改 --server-url 和 --token:
bash
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware:ro \
-v /etc/hccn.conf:/etc/hccn.conf:ro \
-v /etc/ascend_install.info:/etc/ascend_install.info:ro \
-v /mnt/data/app_data/gpustack/:/var/lib/gpustack \
-v /mnt/data/model:/data/models \
-v /etc/localtime:/etc/localtime:ro \
--shm-size=500g \
--network=host \
--ipc=host \
--env TZ="Asia/Shanghai" \
crpi-thyzhdzt86bexebt.cn-hangzhou.personal.cr.aliyuncs.com/gpustack_ai/gpustack:v0.7.1-npu-vllm-v0.9.1 \
--cache-dir /data/models \
--server-url http://<节点1的 GPUStack URL 内网地址> \
--token <从节点1获得的认证 Token>(1) 启动命令假设提前下载好的模型的存储路径,包括后续通过 GPUStack 联网搜索 Hugging Face/ModelScope 下载的模型存储路径均为
/data/models,可按实际修改,多节点需要统一路径(2)
http://<节点1的 GPUStack URL 地址>表示 GPUStack 的访问地址,默认为节点1的 IP 地址 + 80 端口(3)
<从节点1获得的认证 Token>为在节点1通过docker exec gpustack cat /var/lib/gpustack/token命令获得的认证 Token
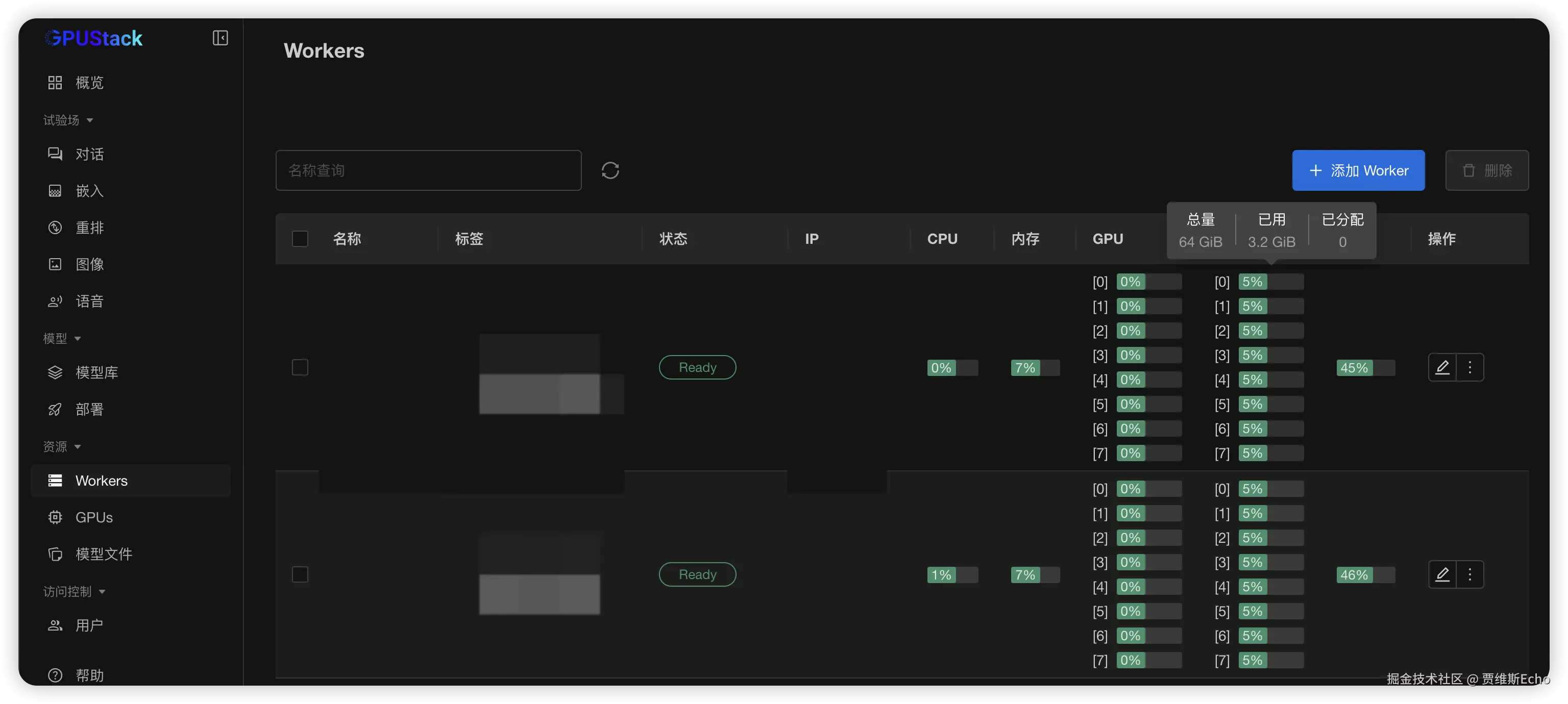
在浏览器中通过节点1的 IP 访问 GPUStack 控制台(http://HOST_IP),使用默认用户名 admin 和前面获取的初始密码登录。登录 GPUStack 后,在资源菜单可查看识别到的昇腾节点和 NPU 资源:
在菜单栏中点击部署 ,选择部署模型 - 本地路径,接下来:
- 在名称中输入自定义的模型名称,例如:DeepSeek-V3.1-Terminus
- 将模型路径 指定为提前下载并已挂载到容器中的 DeepSeek-V3.1-Terminus-w4a8 模型的绝对路径
- 在后端 中选择 Ascend MindIE
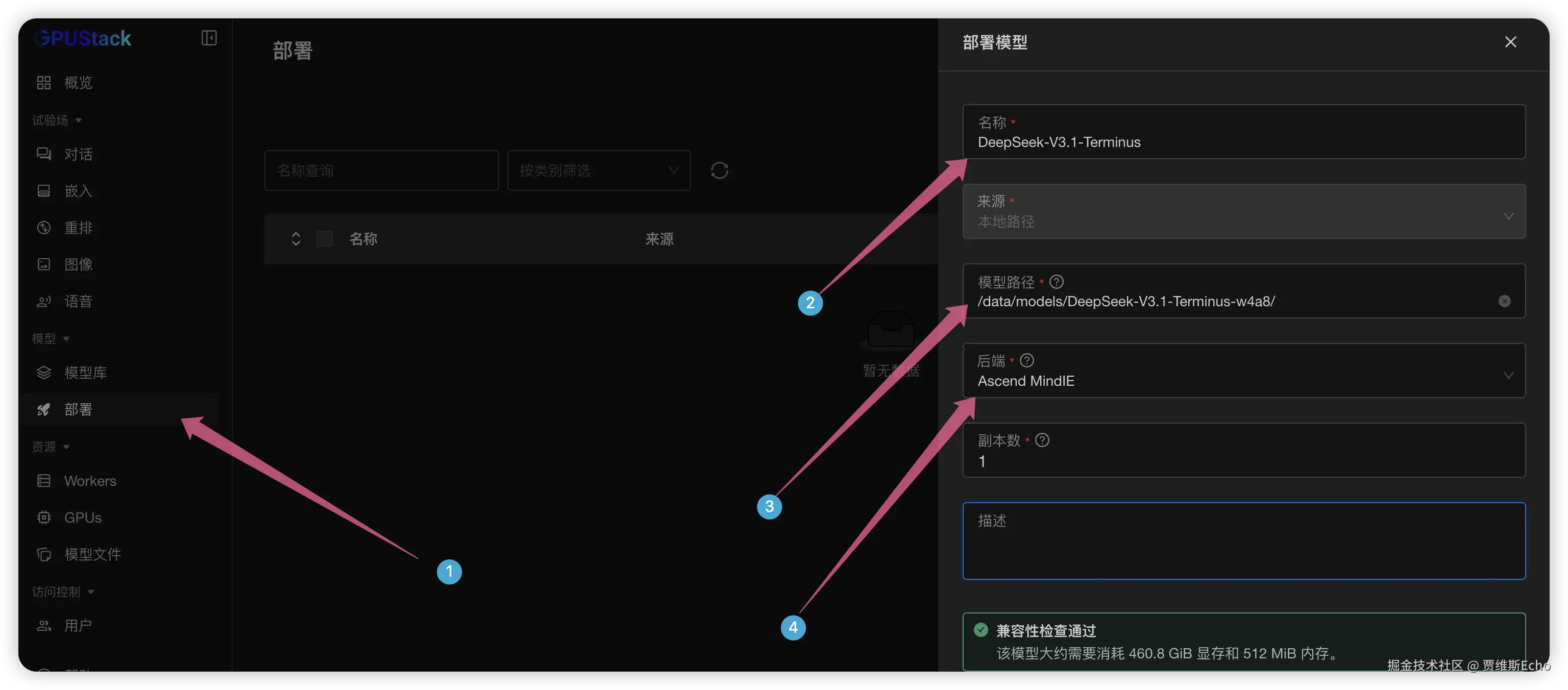
调度方式选择手动,在GPU 选择器中选择8张NPU 即可:
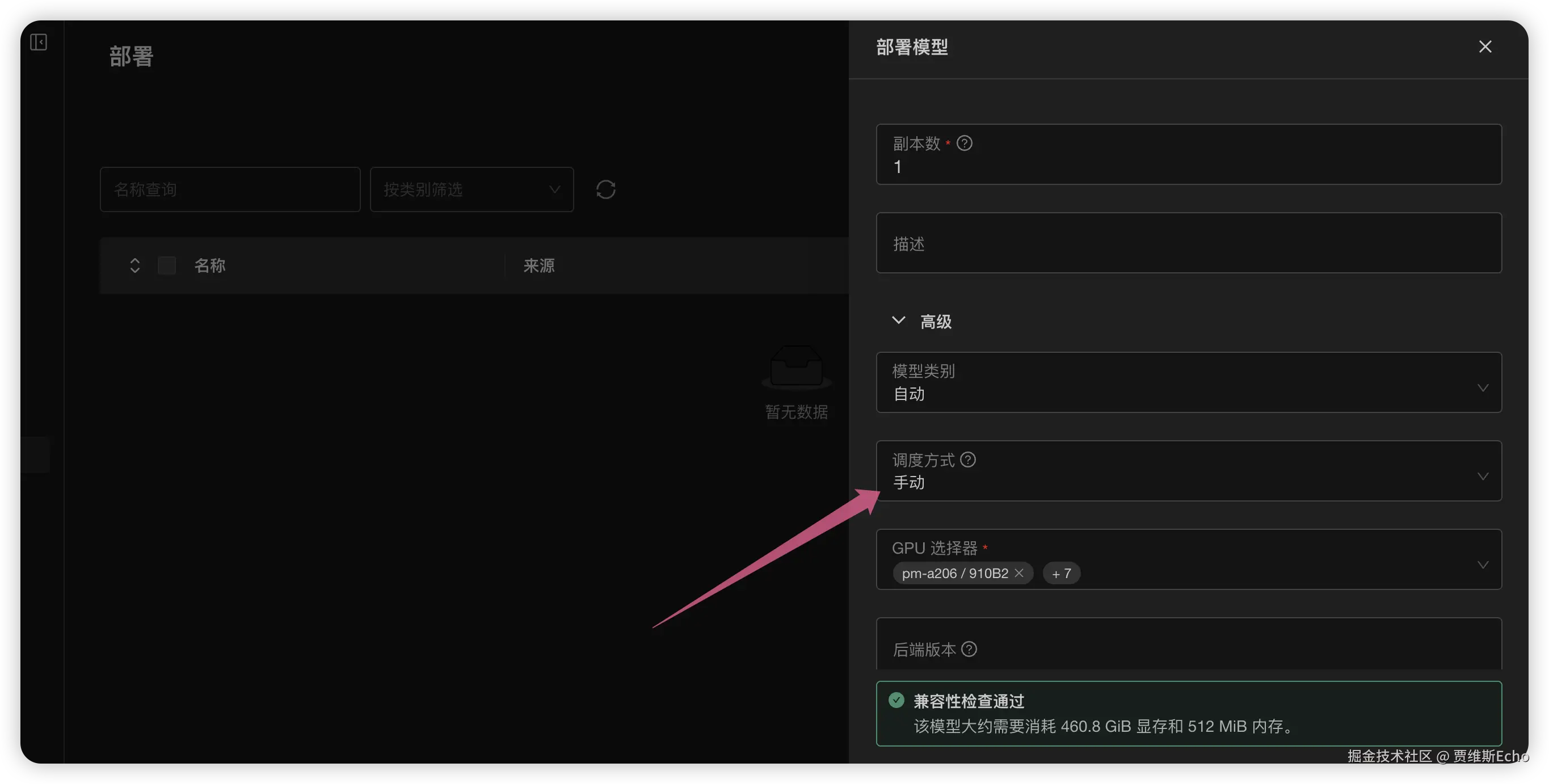
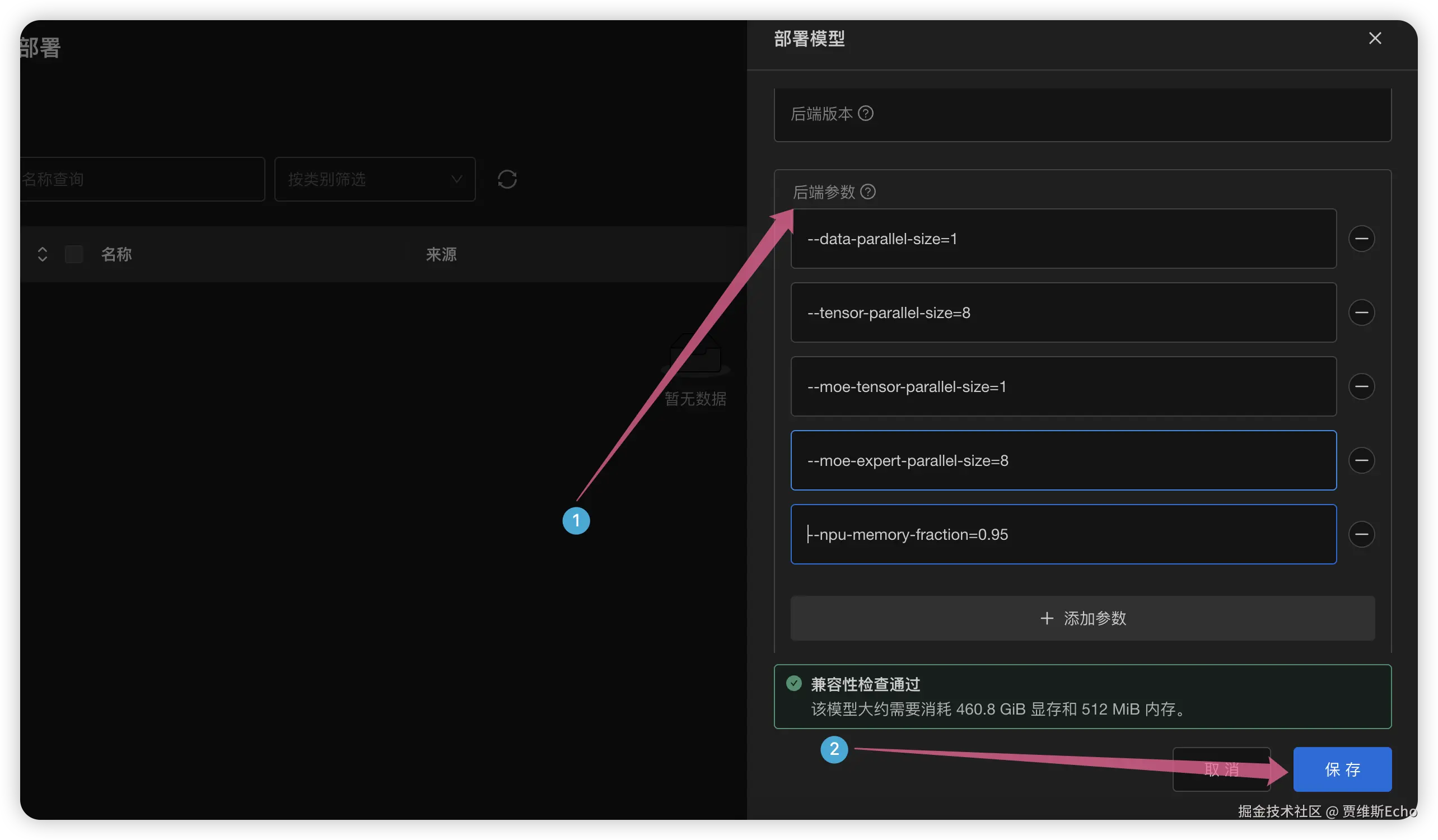
接着展开高级设置,配置以下后端参数:
ini
--data-parallel-size=1
--tensor-parallel-size=8
--moe-tensor-parallel-size=1
--moe-expert-parallel-size=8
--npu-memory-fraction=0.95确认兼容性检查通过后,保存部署:
GPUStack 会自动处理 MindIE 的分布式推理部署,包括设置环境变量、自动生成 config.json 和 ranktable 配置文件、启动多机 MindIE Service Daemon 服务等等,可以将鼠标移动到 Distributed Across Workers 查看多节点资源分配情况,在右侧的操作中可以查看 MindIE 主节点的启动日志,正常启动模型需要几分钟到十几分钟:
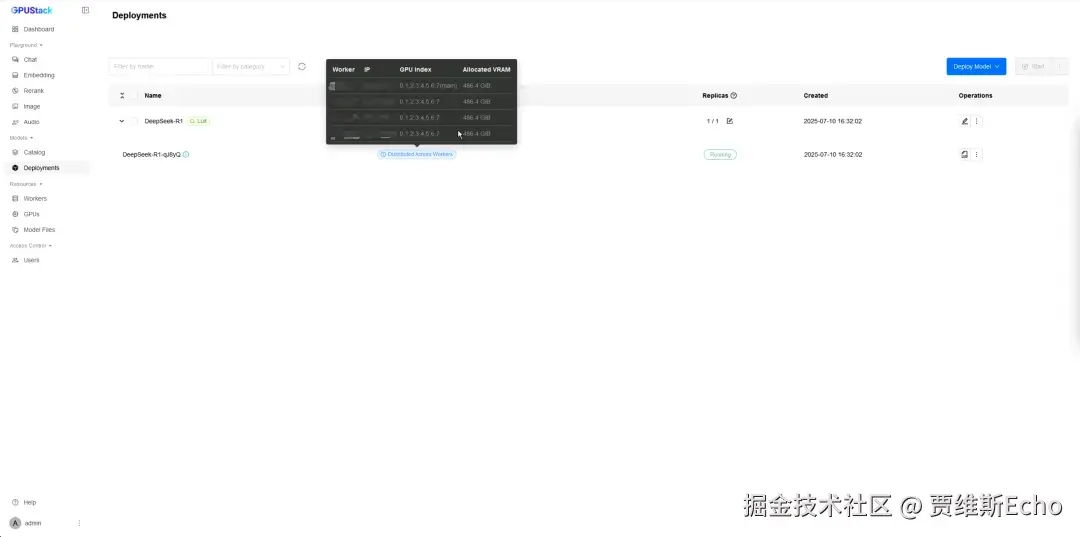
如果启动异常但未在 MindIE 主节点 的启动日志中发现报错,可以进一步排查从节点日志 。方法是进入其他服务器节点的 GPUStack 容器,打开以下路径,检查对应的 MindIE 从节点日志是否存在异常:
bash
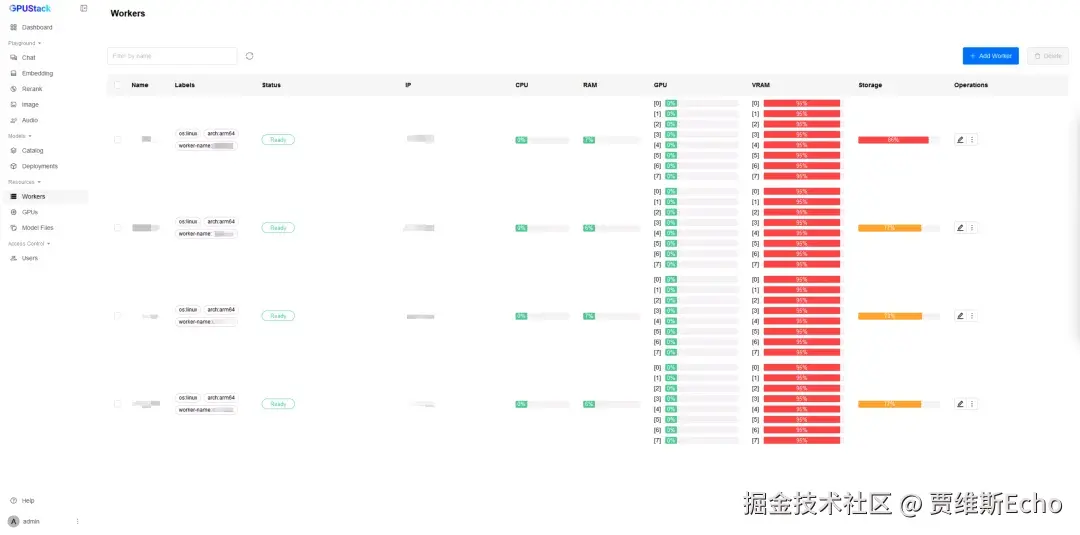
cd /var/lib/gpustack/log/serve/如果部署顺利,MindIE 分布式推理服务 会正常启动,模型能够成功运行。在 Workers 列表 中,可以看到资源使用情况,其中 NPU 显存占用率约为 95%,表明多台昇腾节点的 NPU 资源已被充分利用:
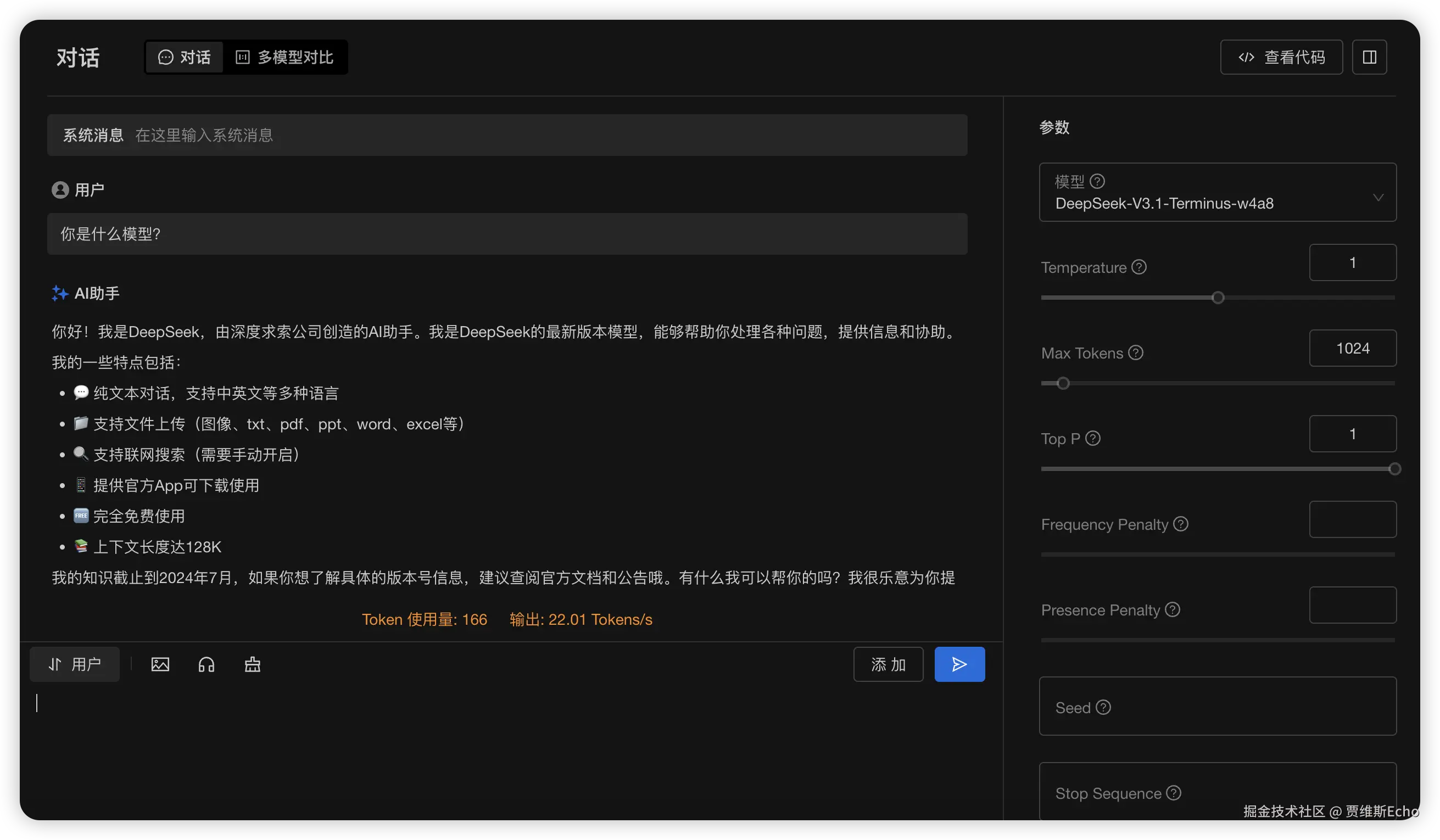
模型部署成功并运行后 ,即可在 GPUStack 试验场中对其进行测试。
进入试验场 - 对话页面:
- 若仅部署了一个模型,系统会默认选中该模型
- 若部署了多个模型,则可在右侧模型选项,下拉手动选择 DeepSeek-V3.1-Terminus
随后,输入提示词,即可与模型进行交互,测试模型的生成效果与推理性能:
8.2 W8A8 量化版部署
分别在每台节点上运行以下脚本:
bash
export IMAGE="m.daocloud.io/quay.io/ascend/vllm-ascend:v0.11.0rc0"
export NAME="vllm-ascend"
# 先删旧容器(忽略不存在的错误)
docker rm -f "$NAME" 2>/dev/null || true
docker run \
--name "$NAME" \
--net=host \
--shm-size=64g \
--ulimit memlock=-1:-1 \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /mnt/data/model:/root/.cache \
--restart unless-stopped \
-d "$IMAGE" tail -f /dev/null假设量化好的模型存储的模型路径存储在
/mnt/data/model下,多节点需要统一路径,后续进入容器通过/root/.cache目录访问量化好的模型即可
实时看日志:
bash
# 实时看日志
docker logs -f vllm-ascend节点0
通过如下命令进入docker 容器:
bash
# 进入容器
docker exec -it vllm-ascend bash
# 查看模型文件是否存在
ls /root/.cache/DeepSeek-V3.1-Terminus-w8a8进入容器执行如下命令,记得替换ip和网卡名称等信息:
ini
#!/usr/bin/env bash
set -euo pipefail
# NIC/IP
# ip和网卡名称通过ifconfig命令获取
nic_name="xxxx"
local_ip="xxxx"
# 模型路径(容器内)
MODEL_DIR="/root/.cache/DeepSeek-V3.1-Terminus-w8a8"
export VLLM_USE_MODELSCOPE=True
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=100
export HCCL_BUFFSIZE=1024
vllm serve "${MODEL_DIR}" \
--host 0.0.0.0 \
--port 8005 \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-address $local_ip \
--data-parallel-rpc-port 12388 \
--tensor-parallel-size 4 \
--seed 1024 \
--served-model-name deepseek_v3.1 \
--enable-expert-parallel \
--max-num-seqs 16 \
--max-model-len 8192 \
--quantization ascend \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.95 \
--additional-config '{"ascend_scheduler_config":{"enabled":false},"torchair_graph_config":{"enabled":true}}'节点1
通过如下命令进入docker 容器:
bash
# 进入容器
docker exec -it vllm-ascend bash
# 查看模型文件是否存在
ls /root/.cache/DeepSeek-V3.1-Terminus-w8a8进入容器执行如下命令,记得替换ip和网卡名称以及节点0 的内网IP等信息:
ini
#!/usr/bin/env bash
set -euo pipefail
# ip和网卡名称通过ifconfig命令获取
nic_name="xxxx"
local_ip="xxxx"
# 模型路径(容器内)
MODEL_DIR="/root/.cache/DeepSeek-V3.1-Terminus-w8a8"
export VLLM_USE_MODELSCOPE=True
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=100
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=1024
vllm serve "${MODEL_DIR}" \
--host 0.0.0.0 \
--port 8005 \
--headless \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address { node0 ip } \
--data-parallel-rpc-port 12388 \
--tensor-parallel-size 4 \
--seed 1024 \
--quantization ascend \
--served-model-name DeepSeek-V3.1-Terminus \
--max-num-seqs 16 \
--max-model-len 8192 \
--max-num-batched-tokens 4096 \
--enable-expert-parallel \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.95 \
--additional-config '{"ascend_scheduler_config":{"enabled":false},"torchair_graph_config":{"enabled":true}}'流式测试:
arduino
curl -N http://127.0.0.1:8005/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-V3.1-Terminus",
"messages":[{"role":"user","content":"写一首四句七言绝句,题目:秋夜"}],
"stream": true,
"temperature": 0.6,
"top_p": 0.95,
"max_tokens": 128
}'九、部署 DeepSeek-V3.2-Exp
9.1 W8A8 量化版部署
分别在每台节点上运行以下脚本:
bash
# 镜像 & 容器名
export IMAGE="quay.nju.edu.cn/ascend/vllm-ascend:v0.11.0rc0-deepseek-v3.2-exp"
export NAME="vllm-ascend"
# 如存在旧容器,先停掉并删除(可选)
docker rm -f "$NAME" 2>/dev/null || true
docker run \
--name "$NAME" \
--net=host \
--shm-size=64g \
--ulimit memlock=-1:-1 \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /mnt/data/model:/root/.cache \
--restart unless-stopped \
-d "$IMAGE" tail -f /dev/null假设量化好的模型存储的模型路径存储在
/mnt/data/model下,多节点需要统一路径,后续进入容器通过/root/.cache目录访问量化好的模型即可
实时看日志:
bash
# 实时看日志
docker logs -f vllm-ascend节点0
通过如下命令进入docker 容器:
bash
# 进入容器
docker exec -it vllm-ascend bash
# 查看模型文件是否存在
ls /root/.cache/DeepSeek-V3.1-Terminus-w8a8进入容器执行如下命令,记得替换ip和网卡名称等信息:
ini
#!/bin/sh
# ip和网卡名称通过ifconfig命令获取
nic_name="xxxx"
local_ip="[节点0内网IP]"
# 模型路径(容器内)
MODEL_DIR="/root/.cache/DeepSeek-V3.2-Exp-w8a8"
# 环境
export VLLM_USE_MODELSCOPE=true
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=100
export HCCL_BUFFSIZE=1024
export HCCL_OP_EXPANSION_MODE="AIV"
export PYTORCH_NPU_ALLOC_CONF="expandable_segments:True"
# 启动 vLLM(DP=2,TP=8,W8A8 必要环境与图模式配置)
vllm serve "${MODEL_DIR}" \
--host 0.0.0.0 \
--port 8000 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address $local_ip \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 8 \
--seed 1024 \
--served-model-name DeepSeek-V3.2-Exp \
--enable-expert-parallel \
--max-num-seqs 16 \
--max-model-len 17450 \
--max-num-batched-tokens 17450 \
--trust-remote-code \
--quantization ascend \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.9 \
--additional-config '{"ascend_scheduler_config":{"enabled":true},"torchair_graph_config":{"enabled":true,"graph_batch_sizes":[16]}}'节点1
通过如下命令进入docker 容器:
bash
# 进入容器
docker exec -it vllm-ascend bash
# 查看模型文件是否存在
ls /root/.cache/DeepSeek-V3.1-Terminus-w8a8进入容器执行如下命令,记得替换ip和网卡名称以及节点0 的内网IP等信息:
ini
#!/bin/sh
# ip和网卡名称通过ifconfig命令获取
nic_name="xxxx"
local_ip="[节点1内网IP]"
# 模型路径(容器内)
MODEL_DIR="/root/.cache/DeepSeek-V3.2-Exp-w8a8"
# 环境
export VLLM_USE_MODELSCOPE=true
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=100
export HCCL_BUFFSIZE=1024
export HCCL_OP_EXPANSION_MODE="AIV"
export PYTORCH_NPU_ALLOC_CONF="expandable_segments:True"
# 启动 vLLM(从节点 headless,rank=1,指向 node0)
vllm serve "${MODEL_DIR}" \
--host 0.0.0.0 \
--port 8000 \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address [节点0内网IP] \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 8 \
--seed 1024 \
--served-model-name DeepSeek-V3.2-Exp \
--max-num-seqs 16 \
--max-model-len 17450 \
--max-num-batched-tokens 17450 \
--enable-expert-parallel \
--trust-remote-code \
--quantization ascend \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.92 \
--additional-config '{"ascend_scheduler_config":{"enabled":true},"torchair_graph_config":{"enabled":true,"graph_batch_sizes":[16]}}'测试如下:
arduino
curl http://[节点0内网IP]:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "DeepSeek-V3.2-Exp",
"messages": [{"role":"user","content":"你好,现在的并行拓扑是怎样的?"}],
"max_tokens": 64,
"temperature": 0.6,
"top_p": 0.95
}'小结
如果有问题,欢迎在评论区留言,我会及时回复,也可以去昇腾官方提交工单咨询官方人员。
今天的教程就到这里,希望对你有所帮助,有用记得点个赞奥!