1.UDP报文格式
2.校验和
1.UDP报文格式
1).UDP是"尽力而为"的服务, 报文可能会丢失或送到应用进程的报文乱序, 它被用在对于丢失
不敏感但是速率敏感的应用; 在UDP上可靠传输需要在应用层增加可靠性
2).一个UDP报文包含两部分组成:
a.报头(Header): 固定8个字节, 包含了一些基础控制信息
b.数据(Data): 来自应用层的数据
c.如下是UDP报文的格式:
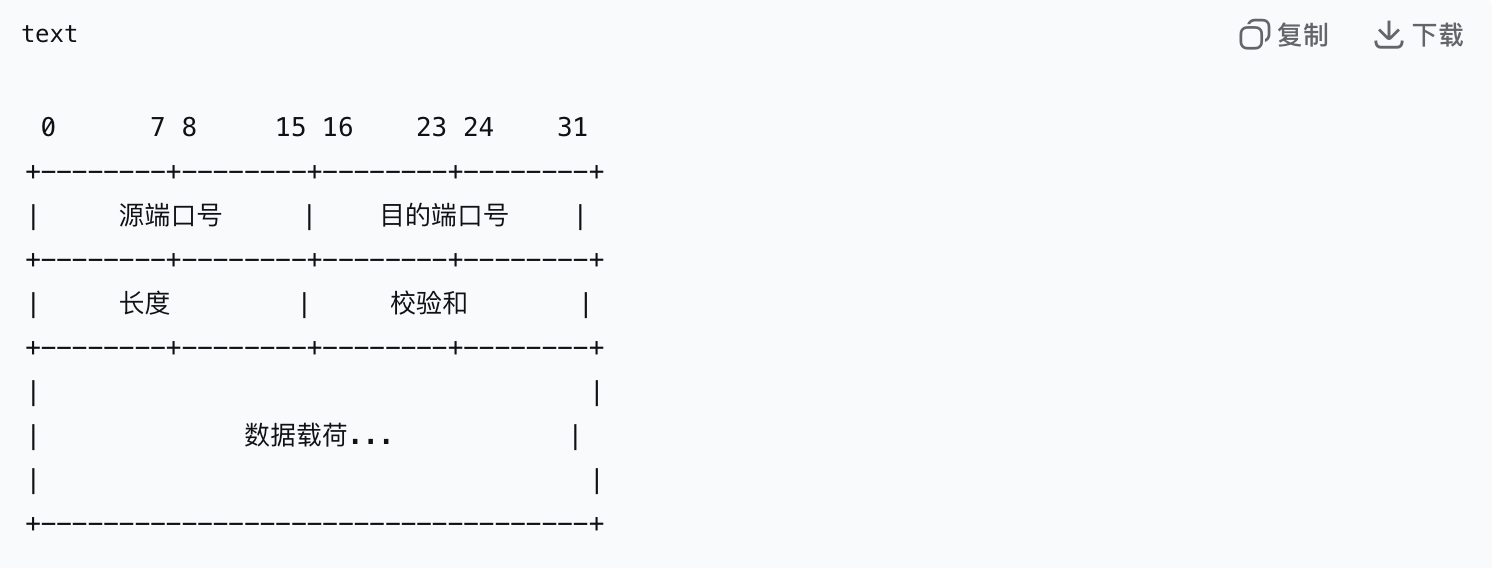
报头的四个字段都是16位(2字节)
1).源端口号
a.长度: 16位
b.作用: 标识发送方应用程序的端口号, 当接收方需要回复消息时, 就需要使用这个端口号作为
目标
c.范围: 0 - 65535, 注: 这个字段是可选的, 如果不需要回复, 可以用全0表示
2).目标端口号
a.长度: 16位
b.作用: 标识接收方应用程序的端口号, 这个字段是必须的, 它告诉应该将这个报文交给哪个应
用程序
3).长度
a.长度: 16位
b.作用: 整个UDP报文的总长度(以字节为单位)
c.计算范围: 包含8字节的报头和数据部分; 因此, UDP报文的最小长度是8(只有报头, 没有数
据), 最大长度理论上是65535字节; 但由于底层网络(如以太网)有最大传输单元的限制, 实际
数据长度会小得多
4).校验和
a.长度: 16位
b.作用: 用于差错检测, 检测UDP报文在传输过程中是否出现了错误(如比特翻转)
c.计算内容: 校验和的计算不仅包括UDP报文本身(报头和数据), 还引入了一个伪首部
d.特点: 这个字段在IPV4中是可选的, 如果发送方没有计算校验和, 则该字段填充为0; 但在
ipv6中是强制的
2.校验和
1).伪首部
a.为什么需要伪首部?
为了不仅校验数据, 还能验证这个udp报文是否被错误地送到了错误的主机
b.伪首部包含什么
伪首部是临时构造的, 只用于计算校验和, 不会被实际传输; 伪首部是12字节
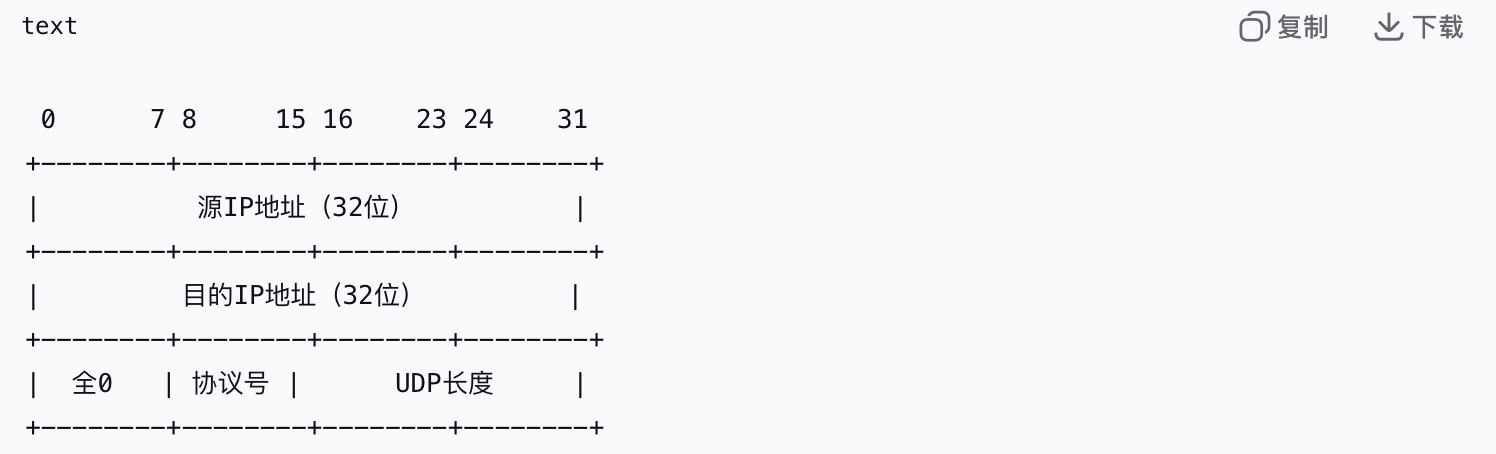
a.源/目的IP地址: 来自ip层的头部信息, 保证报文能够正确的送到对应的主机
b.协议号: udp的协议号是17
c.UDP长度: UDP头部中的长度字段
2).计算校验和:
a.拼接
将伪首部、UDP报头(注意,此时校验和字段先置为0)和数据部分全部拼接在一起
b.分组
将整个拼接后的数据流, 视为一系列16位(2字节)的数
c.求和
将所有这些16位的数进行二进制反码求和
简单理解二进制反码求和: 就是普通的二进制加法, 但当最高位有进位时, 不是丢弃, 而是把这
个进位"回卷"加到最低位上
例子: 计算1101和1001(这里我们用4位简化演示)
- 普通加法, 1101 + 1001 = 1 0110(结果溢出了)
- 反码求和, 取出溢出位1, 加到结果0110上: 0110 + 1 = 0111
d.取反得到最终结果
将对所有16位数进行二进制反码求和后得到的结果, 按位取反(0变1, 1变0)得到的这个值就是
校验和, 然后填入UDP报头的"校验和"字段