目录
[LLaMA 实现全部代码](#LLaMA 实现全部代码)
Introduction
作为背景,讨论了是否更大的模型训练更大的参数就会有更好的训练效果。
这里引入了缩放定律scaling laws,作者认为缩放定律忽略了推理的成本,相比于训练更快的模型,作者认为应该选择推理更快的模型,因此提出小的 LLM 配大数据训练更好,因为小 LLM 推理更友好。
Approach
预训练数据
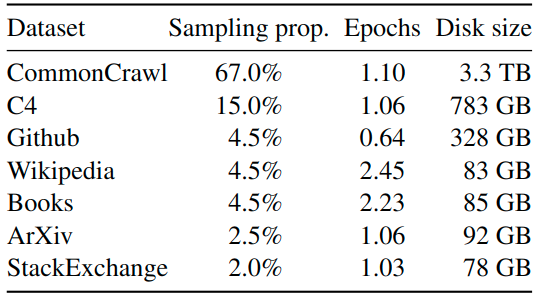
LLaMa 预训练数据大约包含 1.4T tokens,对于绝大部分的训练数据,训练期间只使用一次。
下图展示了 LLaMa 预训练数据的占比:
结构
LLaMA 为 decoder-only 结构,和之前其他模型相比最大的3个改进:
- 对每个Transformer子层的输入使用 RMSNorm 归一化函数进行归一化,而不是对输出进行归一化。
- 用 SwiGLU 激活函数替换 ReLU 非线性,以提高性能。
- 删除了绝对位置嵌入,使用 RoPE 旋转位置嵌入。
RMSNorm
可以增强训练稳定性。
代码实现:
python
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weightSwiGLU
可以提高模型性能。
LLaMa 使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能,SwiGLU 激活函数结合了 Swish 激活函数和 GLU(Gated Linear Unit)的机制。
RoPE
可以更好地建模长序列数据。
来源于苏剑林大神,不直接将位置信息作为向量与词向量相加,而是在注意力机制的 Query(查询)和 Key(键)计算时,将输入向量视为复数,在复数平面上进行旋转,通过旋转操作将位置信息融入输入嵌入中。
优点:
旋转操作可以通过复数操作简化,计算复杂度低
可以捕捉相对位置关系
对长序列友好
LLaMA中 RoPE 的实现代码:
python
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # type: ignore
freqs = torch.outer(t, freqs).float() # type: ignore
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)Optimizer
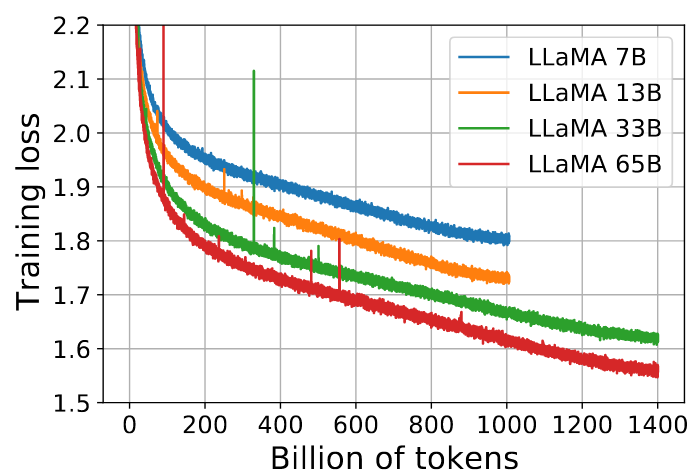
使用 AdamW 优化器,超参数如下:β1 = 0.9,β2 = 0.95,最终学习率等于最大学习率的10 %。
如图为7B、13B、33B 和 65B tokens 的模型训练损失:
高效训练的方法
- 内存与速度优化:用 xformers 库实现高效因果多头注意力,手动实现 Transformer 层反向传播,选择性保存高计算成本激活值以减少重计算。
- 分布式策略:模型并行 + 序列并行减少内存占用;重叠激活计算与 GPU 间通信。
- 训练效率:65B 模型用 2048 张 A100(80GB)GPU,1.4T tokens 训练耗时约 21 天。
主要结果
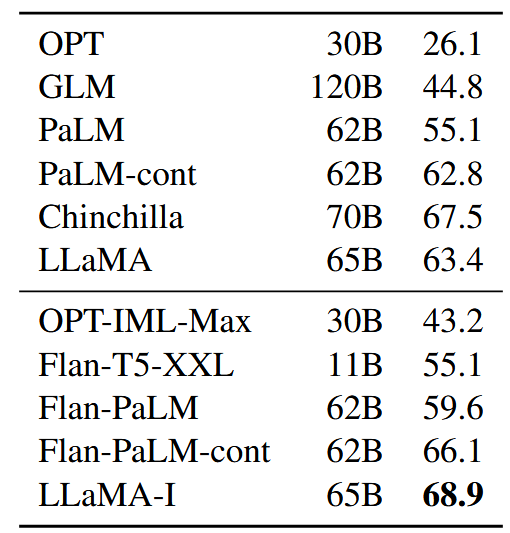
该模块给出 LLaMA 在常识推理、闭卷问答、阅读理解6项具体任务中,其表现优于或匹敌主流模型。
指令微调
该部分指出小样本微调可以进一步提高了模型对指令的follow能力。下图比较了大小适中的模型在MMLU上有指令微调和无指令微调的情况:
模型风险评估
该部分分为Bias, Toxicity and Misinformation,即毒性、偏见、真实性三方面展开,核心结论如下:
- 毒性:用 RealToxicityPrompts 评估,模型规模越大毒性越强,如 65B 模型 "基础提示""尊重提示" 毒性得分(0.128、0.141)高于 7B 模型(0.106、0.081),与 OPT 等开源模型趋势一致;
- 偏见:通过 CrowS-Pairs 和 WinoGender 评估,65B 模型平均偏见得分(66.6%)略低于 GPT-3、OPT-175B,但宗教领域偏见突出(79.0%,超 OPT 10%);且对 "their/them" 代词共指分辨率高于 "her/she""his/he","gotcha" 案例错误率高,存在性别偏见;
- 真实性:用 TruthfulQA 评估,65B 模型 "真实回答""真实且有用" 占比(57%、53%)高于 GPT-3(28%、25%),但仍有幻觉风险。
Conclusion
强调仅用公开可用数据训练大模型就能达到最先进性能,无需依赖专有数据集,这也是本文的标题所在:开源高效的大语言模型。
LLaMA 实现全部代码
python
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the GNU General Public License version 3.
from typing import Optional, Tuple
from dataclasses import dataclass
import math
import torch
from torch import nn
import torch.nn.functional as F
import fairscale.nn.model_parallel.initialize as fs_init
from fairscale.nn.model_parallel.layers import (
ParallelEmbedding,
RowParallelLinear,
ColumnParallelLinear,
)
@dataclass
class ModelArgs:
dim: int = 512
n_layers: int = 8
n_heads: int = 8
vocab_size: int = -1 # defined later by tokenizer
multiple_of: int = 256 # make SwiGLU hidden layer size multiple of large power of 2
norm_eps: float = 1e-5
max_batch_size: int = 32
max_seq_len: int = 2048
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # type: ignore
freqs = torch.outer(t, freqs).float() # type: ignore
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim)
output = output.transpose(
1, 2
).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()