目录
[1.5、JIT 的优化](#1.5、JIT 的优化)
[2.1. 方法内联(Inlining)](#2.1. 方法内联(Inlining))
[2.2. 循环展开(Loop Unrolling)](#2.2. 循环展开(Loop Unrolling))
[2.3. 公共子表达式消除](#2.3. 公共子表达式消除)
[2.4. 常量折叠](#2.4. 常量折叠)
[3、验证 JIT](#3、验证 JIT)
前言
Java 程序是怎么运行的?(背景知识),我们先回顾一下 Java 程序的执行流程:
bash
.java 源文件
↓ 编译(javac)
.class 字节码文件(平台无关)
↓ 运行(java 命令)
JVM 加载并执行如下所示:
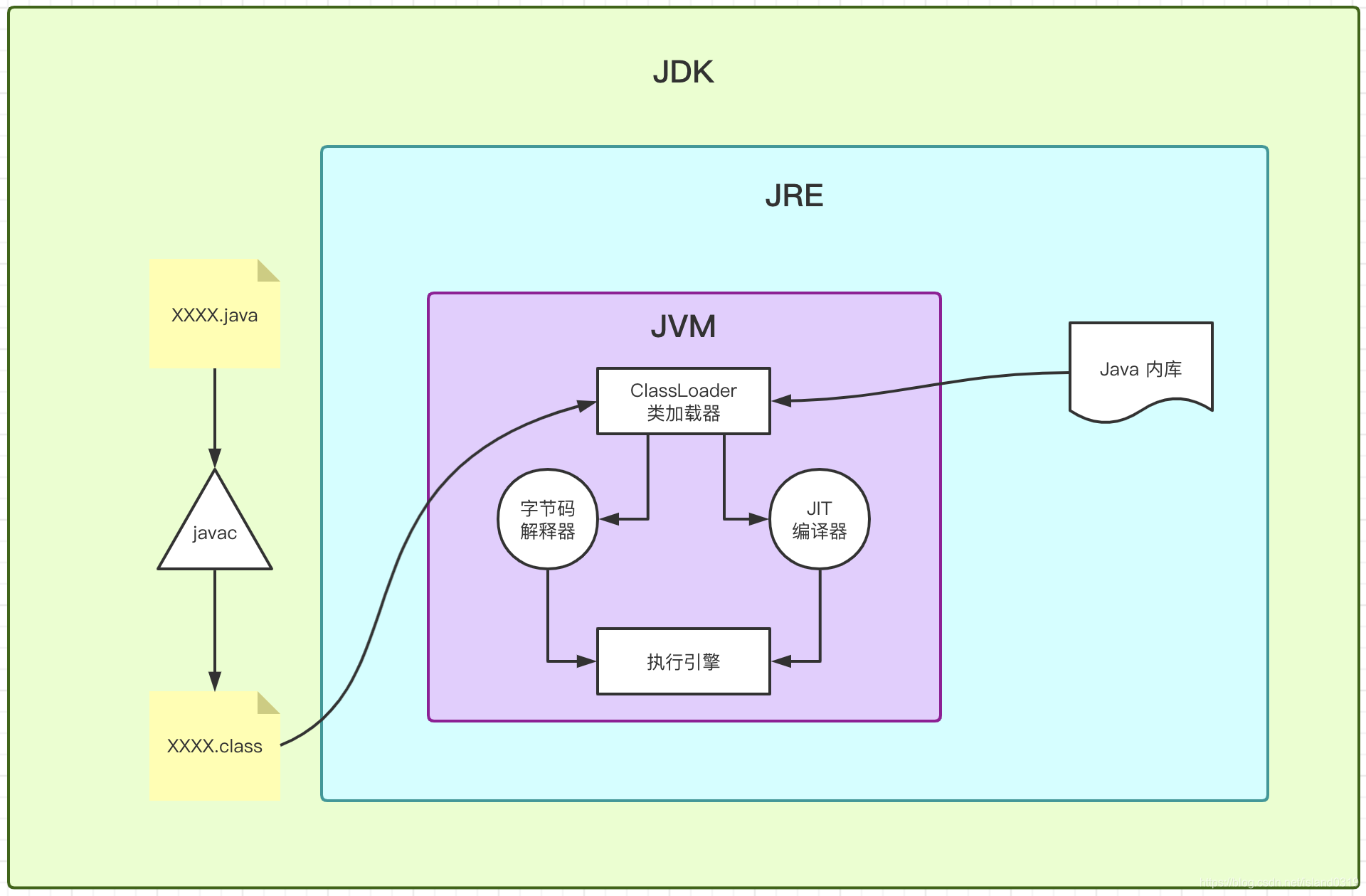
但 JVM 不能直接执行.class文件,它有两种方式来"跑"代码:
| 方式 | 说明 |
|---|---|
| 解释执行 | 一行行读字节码,边解释边执行(慢) |
| 即时编译(JIT) | 把热点代码编译成机器码,以后直接运行(快) |
👉 JVM 不是只用一种方式,而是 混合模式(Mixed Mode):解释 + 编译 结合使用。
如下所示:
1、JIT
1.1、定义
JIT 是 JVM 在程序运行时,把"慢的字节码"自动翻译成"快的机器码"的过程。
就像你听外语直播:
- 一开始是"同声传译"(解释执行,慢)
- 听多了发现某些句子反复出现 → 直接背下来,下次直接说中文(编译成本地代码,快)
这就是 JIT 的核心思想!
1.2、设计目的
如下所示:
| 项目 | 说明 |
|---|---|
| 全称 | Just-In-Time Compilation(即时编译) |
| 目的 | 提升 Java 程序运行速度 |
| 触发条件 | 方法被频繁调用(成为"热点代码") |
| 发生在哪 | 程序运行时(Runtime) |
| 输入 | Java 字节码(.class) |
| 输出 | 本地机器码(Native Code) |
| 是否影响语义 | 否,行为完全一致 |
| 依赖技术 | 方法计数器、逃逸分析、内联、标量替换等 |
举个生活例子:做饭 vs 外卖
假设你要吃饭:
❌ 方案1:每次饿了才开始做(解释执行)
- 每次都要洗菜、切菜、炒菜......很慢
- 适合"偶尔吃一次"
👉 类比:解释执行每条字节码,适合不常用的代码
✅ 方案2:发现某道菜天天吃 → 直接预制半成品(JIT 编译)
- 第一次还是现做
- 发现你连续吃一周红烧肉 → 下次提前做好冷冻
- 再点就直接加热上桌,超级快!
👉 类比:某个方法被频繁调用 → JIT 将其编译为本地机器码,后续直接执行
1.3、热点探测策略
JVM 主要通过以下两种策略之一来判断是否为"热点",这取决于你使用的虚拟机和配置:
| 策略 | 说明 | HotSpot 默认 |
|---|---|---|
| 基于计数器的热点探测 | 统计方法被调用的次数或循环回边次数 | ✅ 使用 |
| 基于采样的热点探测 | 定期采样调用栈,统计哪些方法出现最多 | 少见 |
1.4、热点计数器
1、"半衰期"机制:
为了避免"只看总次数"导致老程序一直不编译,HotSpot 引入了 热度衰减(Counter Decay) 机制。
2、工作原理:
- 每隔一段时间(方法调用计数器满一次),JVM 会:
- 把计数器值 减半
- 如果此时没有达到编译阈值 → 归零
🎯 目的:
只对 近期频繁执行 的方法做 JIT,而不是"曾经火过"的方法。
📌 类比:抖音不是看你历史总播放量,而是看你最近是不是爆款。
你可以通过 JVM 参数查看和调整热点探测的行为。
| 参数 | 说明 | 默认值(64位Server VM) |
|---|---|---|
-XX:CompileThreshold=10000 |
方法调用次数阈值 | 10000(C1) / 15000(C2) |
-XX:OSRCompileThreshold=14000 |
循环回边次数阈值 | 14000 |
-XX:+UseCounterDecay |
是否启用计数器衰减 | 是 |
-XX:CounterHalfLifeTime=30 |
半衰期时间(秒) | 30 秒 |
-XX:+PrintCompilation |
打印编译日志 | 否(可开启) |
-XX:+UnlockDiagnosticVMOptions |
解锁诊断参数 | 必须加才能打印详细信息 |
1.5、JIT 的优化
代码如下所示:
java
public class JITDemo {
// 这个方法会被频繁调用 → 成为"热点代码"
public static long sum(int n) {
long result = 0;
for (int i = 0; i < n; i++) {
result += i;
}
return result;
}
public static void main(String[] args) {
// 调用很多次,触发 JIT 编译
for (int i = 0; i < 100_000; i++) {
sum(1000);
}
System.out.println("完成");
}
}执行过程发生了什么?
java
第1~几千次调用:解释执行(慢)
↓
JVM 发现 sum() 被调用了太多次 → 标记为"热点方法"
↓
JIT 编译器(C1 或 C2)介入:
- 把 sum() 的字节码 编译成 CPU 能直接运行的机器码
- 存入"代码缓存"(Code Cache)
↓
之后所有调用:直接跳转到机器码执行(飞快!)🎯 结果:越跑越快!
2、JIT的两个阶段
(C1 和 C2)HotSpot JVM 有两个 JIT 编译器:
| 编译器 | 名称 | 特点 |
|---|---|---|
| C1 | 客户端编译器(Client Compiler) | 快速编译,优化程度低,适合启动快的应用 |
| C2 | 服务器编译器(Server Compiler) | 慢一点,但优化狠,适合长期运行的服务 |
如下所示:
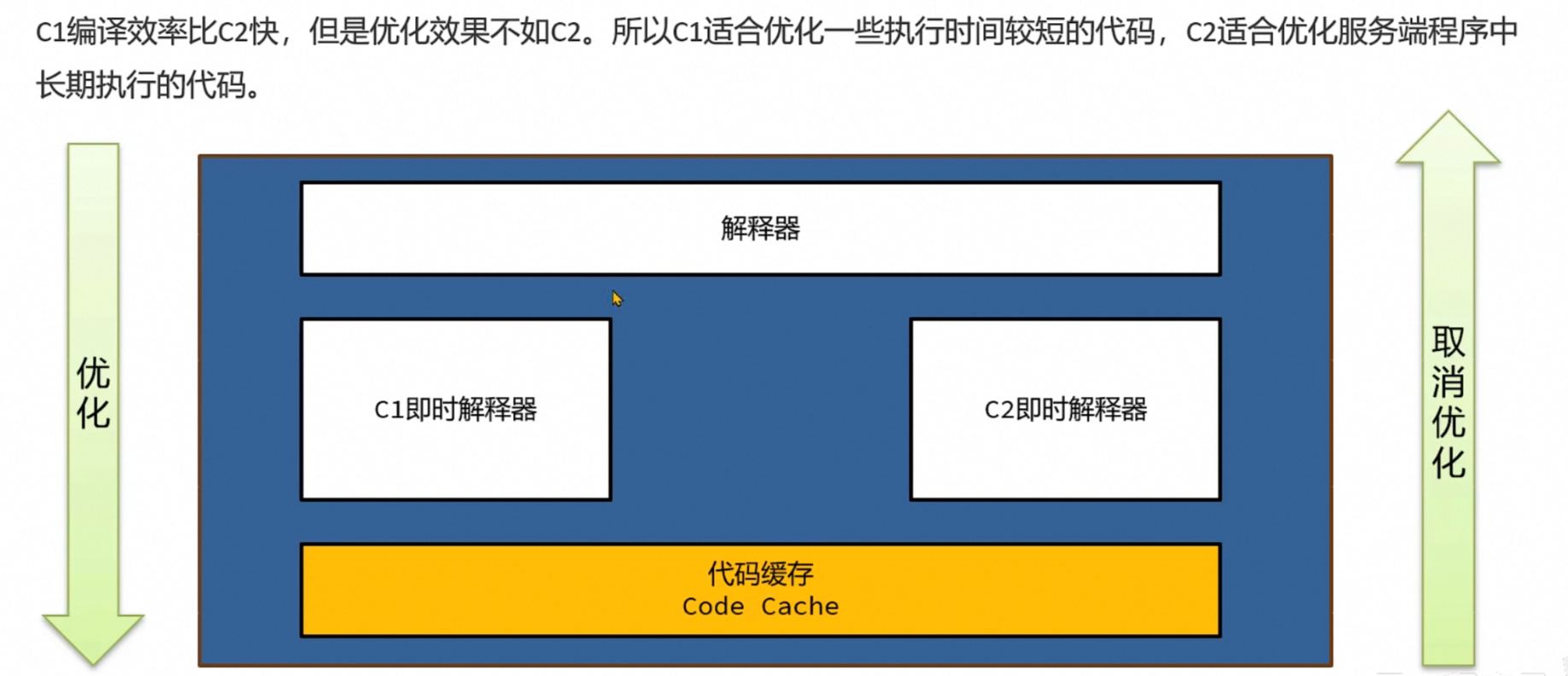
现代 JVM(如 Java 8+)默认使用 分层编译(Tiered Compilation):
- 先用 C1 编译(快速上手)
- 再用 C2 深度优化(越用越快)
继续看上面的 sum() 方法,JIT 可能会做这些事:
2.1. 方法内联(Inlining)
把小方法直接"塞进"调用处,减少函数调用开销
java
// 原始代码
result += i;
// JIT 优化后可能变成:
%rax = %rax + %rcx ← 直接生成汇编指令方法调用是有成本的!
当你写:
java
int result = calculator.add(5, 3);JVM 需要做很多事:
- 保存当前执行状态(栈帧)
- 分配新栈帧
- 参数传递
- 跳转到
add方法 - 执行完再返回
- 恢复原状态
这些操作虽然快,但频繁调用小方法时,累积起来就很浪费。
✅ 所以内联的目标是:
把短小精悍的方法"展开"到调用处,避免调用开销,还能为后续优化创造条件。
示例:
java
public class Calculator {
// 小方法,只是返回两数之和
public int add(int a, int b) {
return a + b;
}
}
public class Main {
public static void main(String[] args) {
Calculator calc = new Calculator();
int sum = 0;
for (int i = 0; i < 1000; i++) {
sum += calc.add(i, 1); // 调用 1000 次
}
System.out.println(sum);
}
}如果不内联:
- 每次循环都要调用
add()方法 - 创建栈帧、参数压栈、跳转、返回......重复 1000 次
- 效率低
✅ JIT 编译后(内联发生):
JVM 发现add()是个简单方法,且被频繁调用 → 决定内联。
最终执行的代码等价于:
java
for (int i = 0; i < 1000; i++) {
sum += (i + 1); // 直接把 add 的逻辑"塞进来"
}2.2. 循环展开(Loop Unrolling)
减少循环判断和跳转次数,提高指令流水线效率。把一个循环体复制多份,每次处理多个元素。
如下所示:
java
// 优化前
for(i=0; i<1000; i++) { ... }
// 优化后
for(i=0; i<1000; i+=4) {
result += i;
result += i+1;
result += i+2;
result += i+3;
}2.3. 公共子表达式消除
当同一个表达式被多次计算时,JIT 编译器会识别出来,只计算一次,并将结果复用。
java
public double compute(double a, double b) {
double x = (a + b) * 2;
double y = (a + b) * 3;
double z = (a + b) * 4;
return x + y + z;
}❌ 没有优化的情况:
- 计算
a + b三次
✅ 经过 CSE 优化后:
java
double temp = a + b; // 只算一次!
double x = temp * 2;
double y = temp * 3;
double z = temp * 4;2.4. 常量折叠
在编译期完成所有能提前计算的运算,避免运行时浪费 CPU。
代码如下所示:
java
public int calculate() {
return 3 + 5 * 2; // 编译时就能算出是 13
}JIT 优化过程:
- 发现
3、5、2都是常量 - 表达式无副作用
- → 直接替换成
return 13;
🎯 效果:省去运行时的乘法和加法指令。
常量折叠是"把能提前算的都算好",公共子表达式消除是"相同的活只干一次"。
3、验证 JIT
方法 1:加 JVM 参数打印编译日志
java
java -XX:+PrintCompilation \
-XX:+UnlockDiagnosticVMOptions \
-XX:+PrintInlining \
-XX:+PrintOptoAssembly \
-XX:CompileCommand=print,*YourClass.yourMethod \
YourApp输出示例:
java
100 1 java.lang.String::hashCode (65 bytes)
120 2 JITDemo::sum (17 bytes)
↳ 表示 sum 方法已被 JIT 编译方法 2:性能对比实验
java
// 关闭 JIT:纯解释执行(非常慢)
java -Xint JITDemo
// 开启 JIT:默认模式(越跑越快)
java JITDemo
// 强制只用 JIT(不解释)
java -Xcomp JITDemo你会发现 -Xint 模式下程序明显变慢!
总结
| 优化技术 | 目的 | 原理简述 | 是否改变语义 | 典型场景 |
|---|---|---|---|---|
| 方法内联 | 减少方法调用开销 | 把小方法的代码"复制"到调用处 | 否 | getter/setter、工具方法频繁调用 |
| 循环展开 | 减少循环控制开销 | 将多次迭代合并为一条语句执行 | 否 | 高频循环遍历数组或集合 |
| 常量折叠 | 提前计算常量表达式 | 在编译期算出 3 + 5 这类结果 |
否 | 数学公式、配置计算 |
| 公共子表达式消除 | 避免重复计算 | 相同表达式只算一次,结果复用 | 否 | (a + b) 多次出现 |
参考文章: