1.前言
国产显卡是指由中国本土企业研发、设计、生产并在国内市场销售的图形处理器(GPU)或专用加速卡。与国外品牌(如 NVIDIA、AMD)不同,国产显卡的核心芯片、封装、驱动软件以及整机系统均由中国公司或其合作伙伴完成。
典型的国产显卡厂商包括华为(昇腾系列 NPU/AI 加速卡)、景嘉微、寒武纪、海光信息、壁仞科技、摩尔线程等,它们的产品覆盖从低功耗嵌入式 GPU、面向信创的工业显卡,到用于 AI 大模型训练的高性能加速卡,构成了中国显卡产业的多层次格局。
下面是国产化显卡(GPU)厂商列表
以下列出在国内GPU/显卡领域具有代表性的企业,华为昇腾(Ascend)系列为核心示例。
- 华为昇腾(Huawei Ascend)------华为自研的AI加速卡/显卡,涵盖Ascend 310、910、910B等型号
- 景嘉微(Jingjia Micro)------国内较早进入GPU研发的企业,提供面向高可靠性场景的图形处理芯片
- 沐曦(Muxi)------专注GPGPU研发,产品包括耀龙S8000等高性能显卡
- 摩尔线程(Moore Threads)------国内GPU第一梯队代表,推出KUAE系列GPU并适配多种大模型
- 天数智芯(Tianshu ZhiXin)------提供AI算力卡和GPU解决方案,已对接DeepSeek等模型
- 海光(HaiGuang)------推出K100、Z100L等GPU产品,布局AI算力生态
- 燧原(SuiYuan)------研发高性能GPU芯片,已在行业展会上展示竞争力
- 壁仞科技(Birren Technology)------在国产GPU设计上取得突破,已进入市场竞争行列
- 寒武纪(Cambricon)------虽以NPU为主,但其思元系列也涉及GPU加速功能
- 华丰科技(Huafeng Technology)------华为昇腾生态链合作伙伴,提供显卡相关硬件与服务
- 泰嘉股份(Taijia Co.)------在显卡及算力平台领域提供配套产品
之前也有小伙伴问过我国产化显卡模型部署和推理怎么弄的今天就带大家在魔乐社区提供的国产化算力卡华为昇腾(Ascend)NPU显卡来实现模型推理。给大家看一下模型推理效果
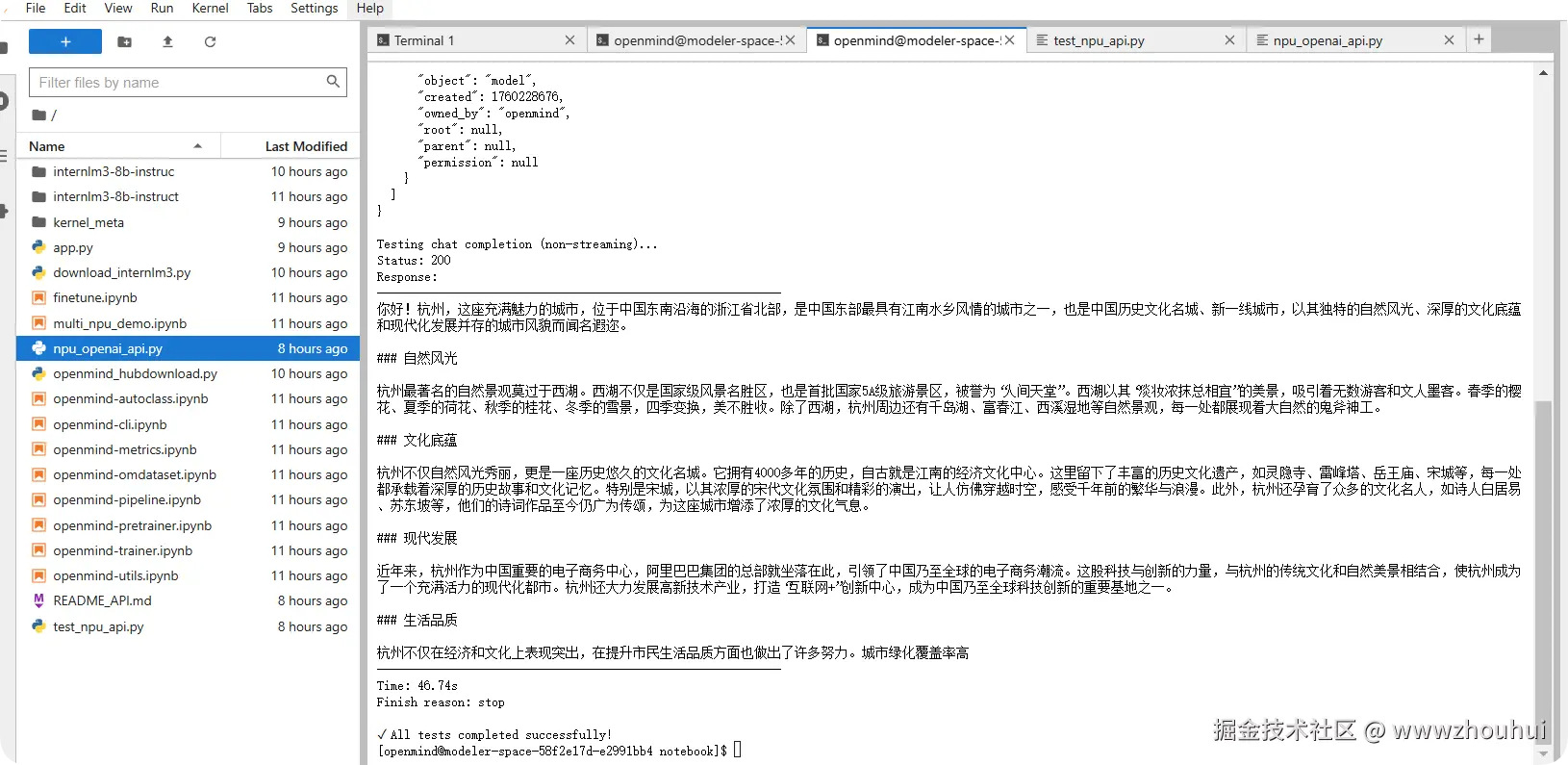
使用代码接口实现推理结果如下:
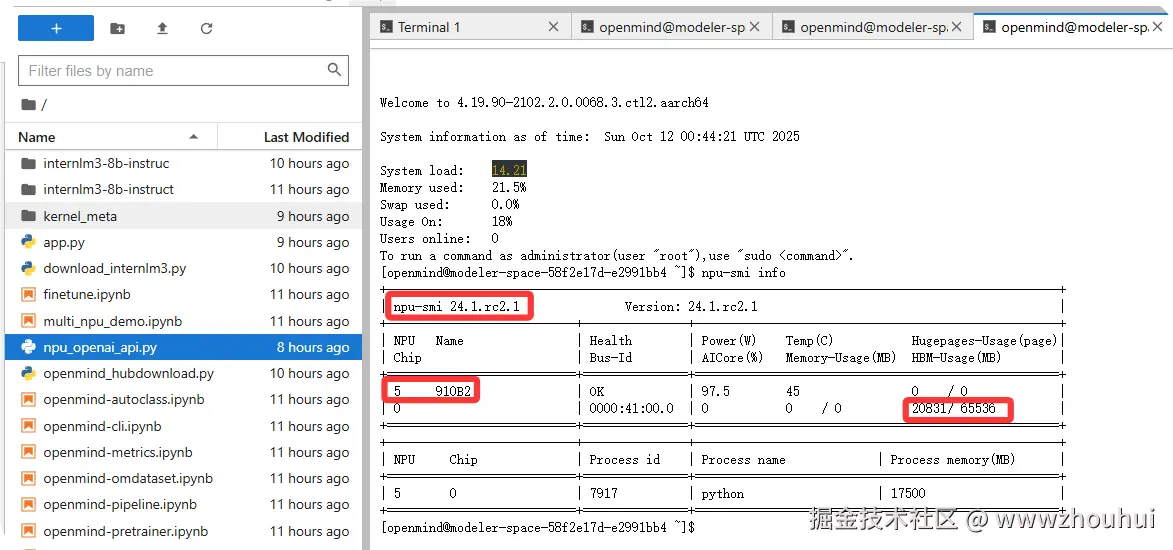
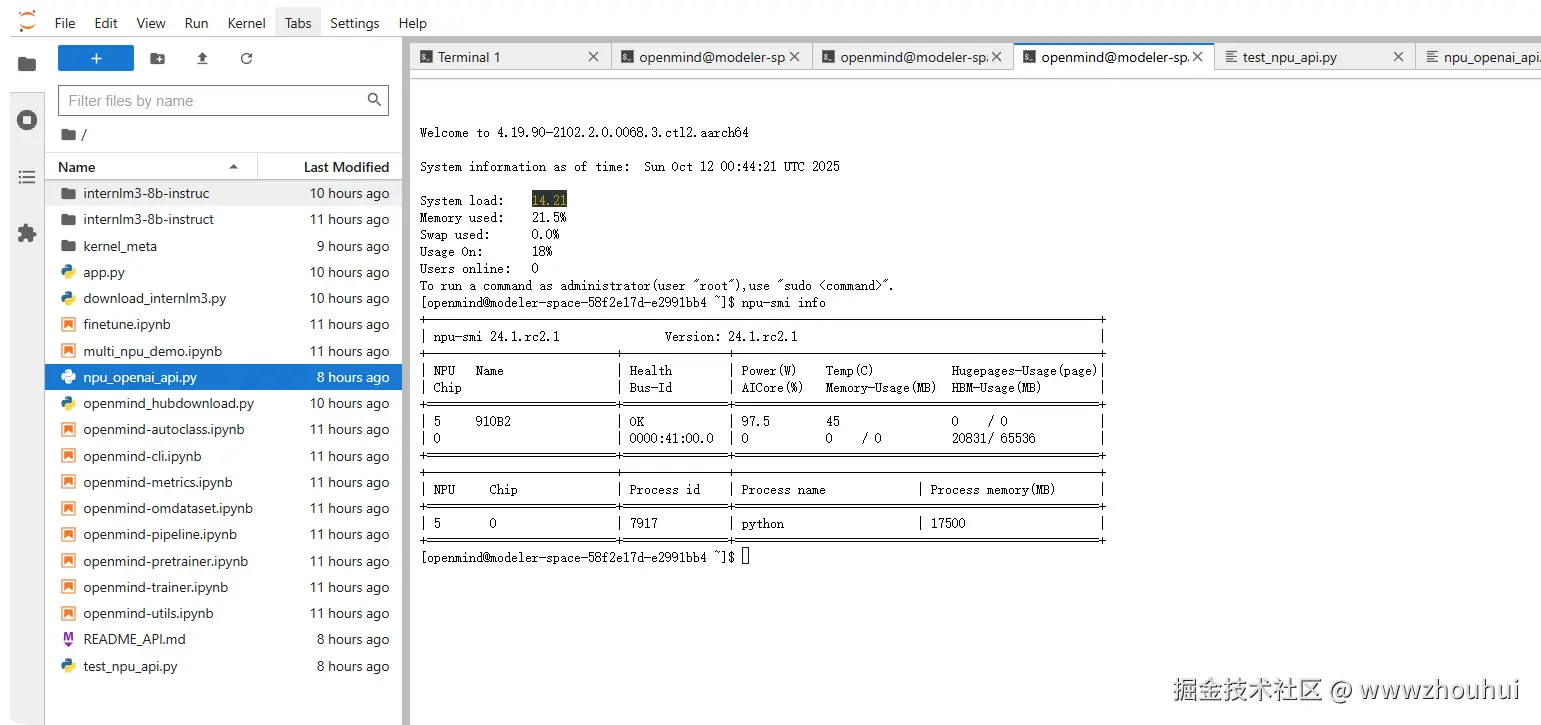
显卡监控情况
那么这样的基于国产化显卡模型推理是如何实现的呢?下面手把手教会大家如何在魔乐社区上实现模型下载、模型部署、模型推理等全过程。
2.魔乐社区推理过程
魔乐社区(Modelers,常称 Modelers.cn)是由中国电信天翼云牵头、华为等产业伙伴共同打造的 国产人工智能开源社区 。它面向 AI 开发者、研究人员和爱好者,提供模型托管、数据集管理、体验空间、工具链集成等"一站式"服务。魔乐社区是一个 中立、公益、开放的 AI 开源平台 ,通过资源聚合、协同开发和产业链协作,帮助开发者快速获取、训练、部署和分享 AI 模型,推动国产人工智能技术的创新与普及的平台。地址modelers.cn/
以上我们是基于魔乐社区,平台的注册这里就不做详细展开了。
创空间应用创建
点击体验地址-创空间
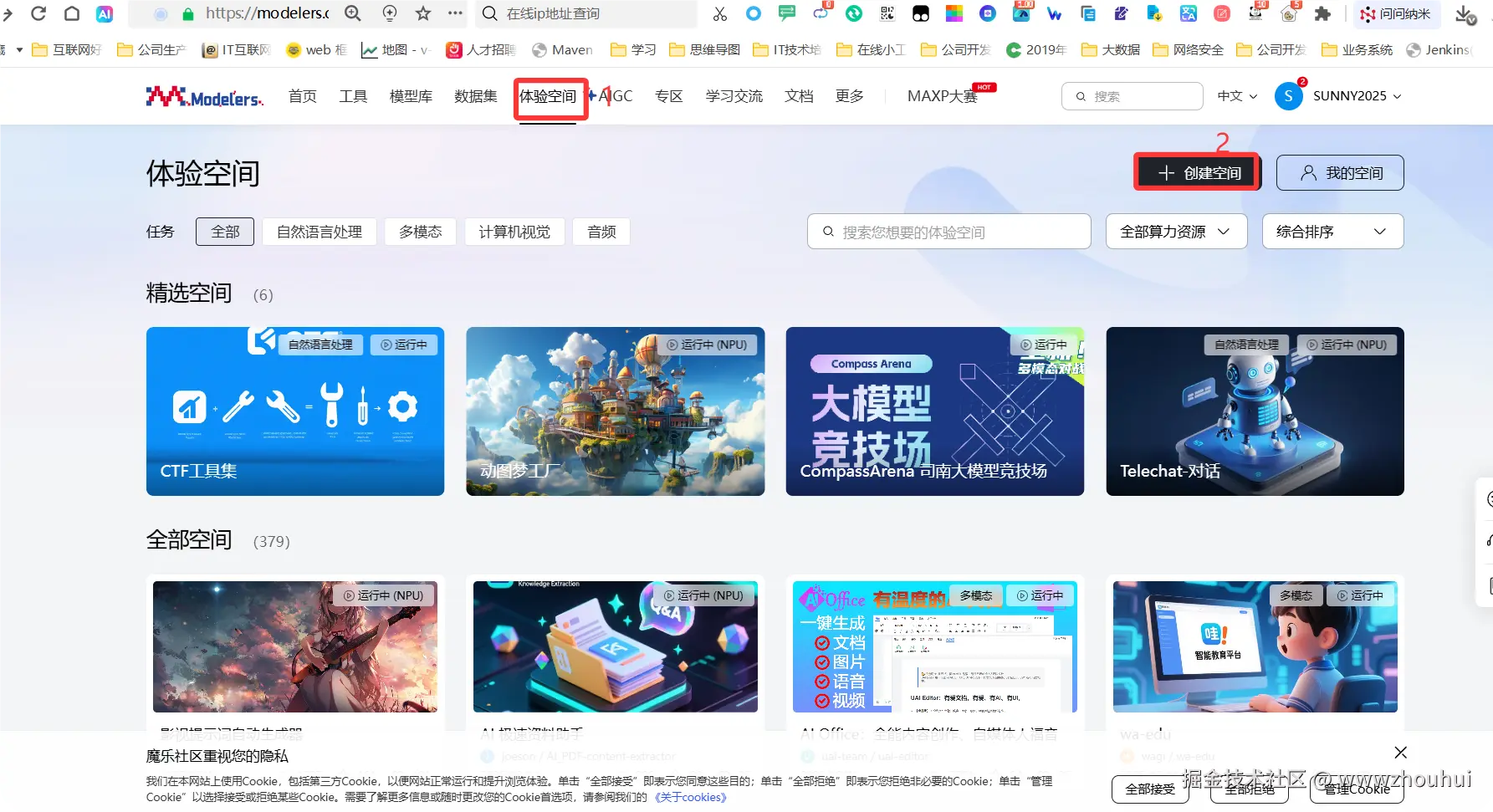
弹出创空间应用,这里我们需要填写如下信息:
空间名:test20251011(随便写一个名字)
许可证: 选择一个开源的协议(mit、apache-2.0等)
接入SDK:这里目前有一个选项gradio 和Application,我们模型还需要部署和调试,所以先选择Application
算力资源:这里免费的只能选择CPU,NPU的需要和管理员联系
基础环境: 这里我们选择openeuler-python3.10-cann8.0.rc3.beta1-pytorch2.1.0-openmind1.0.0
是否公开:默认调试状态选择私有空间,等调试完成基于gradio页面发布在选择公开空间
完成的基础配置如下:
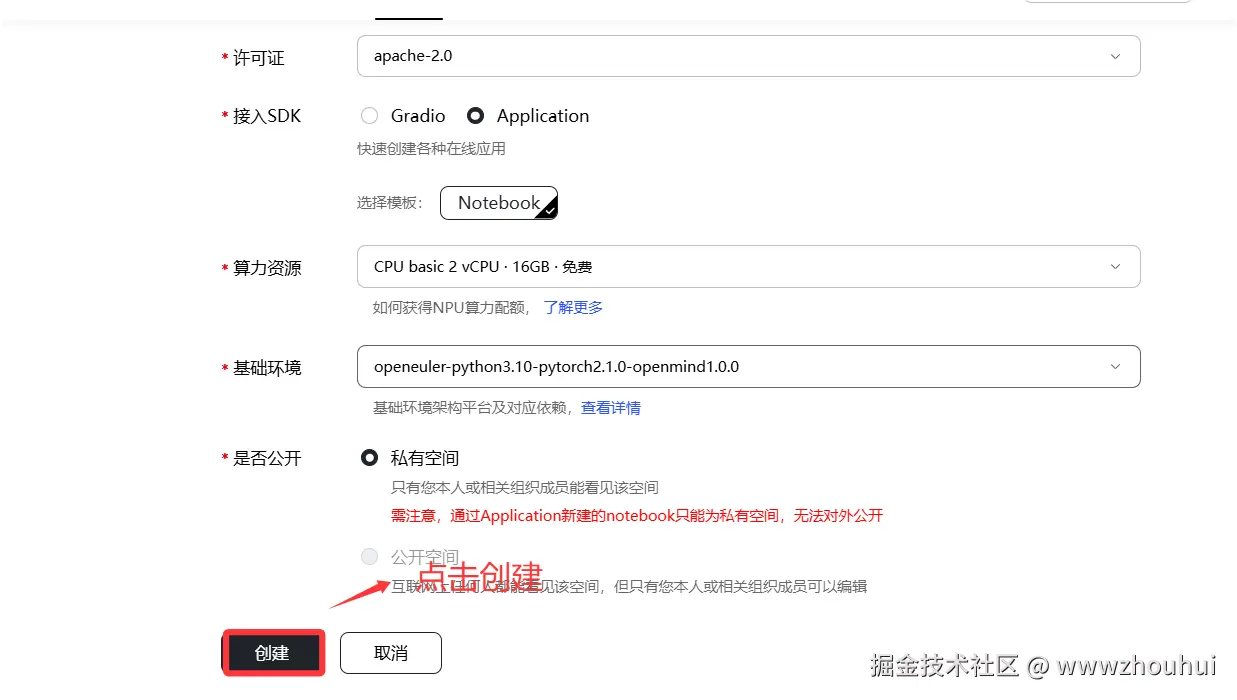
上面的截图我已经使用了NPU没有多余NPU显卡,只能给大家展示CPU配置。下面的图是我配置好的带有NPU的截图
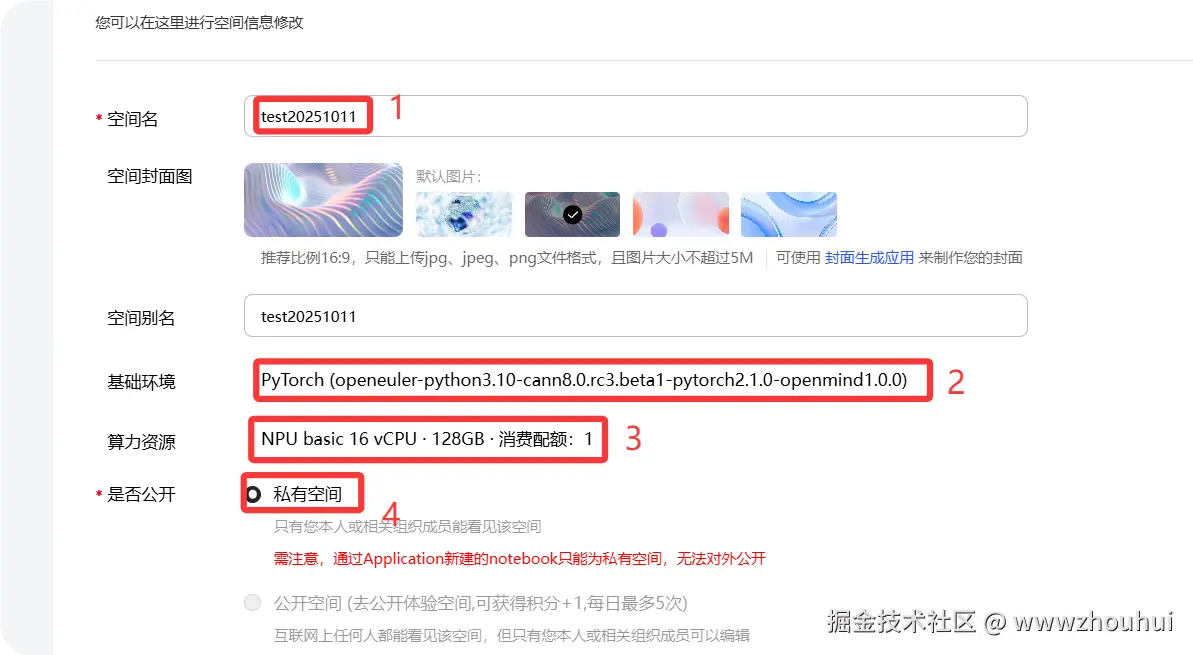
通过上面的方式我们完成了创空间创建,创建过程需要一点时间,主要是下载镜像和启动容器镜像。
创空间应用调试
当创空间应用启动完成后我们会看到下面的画面
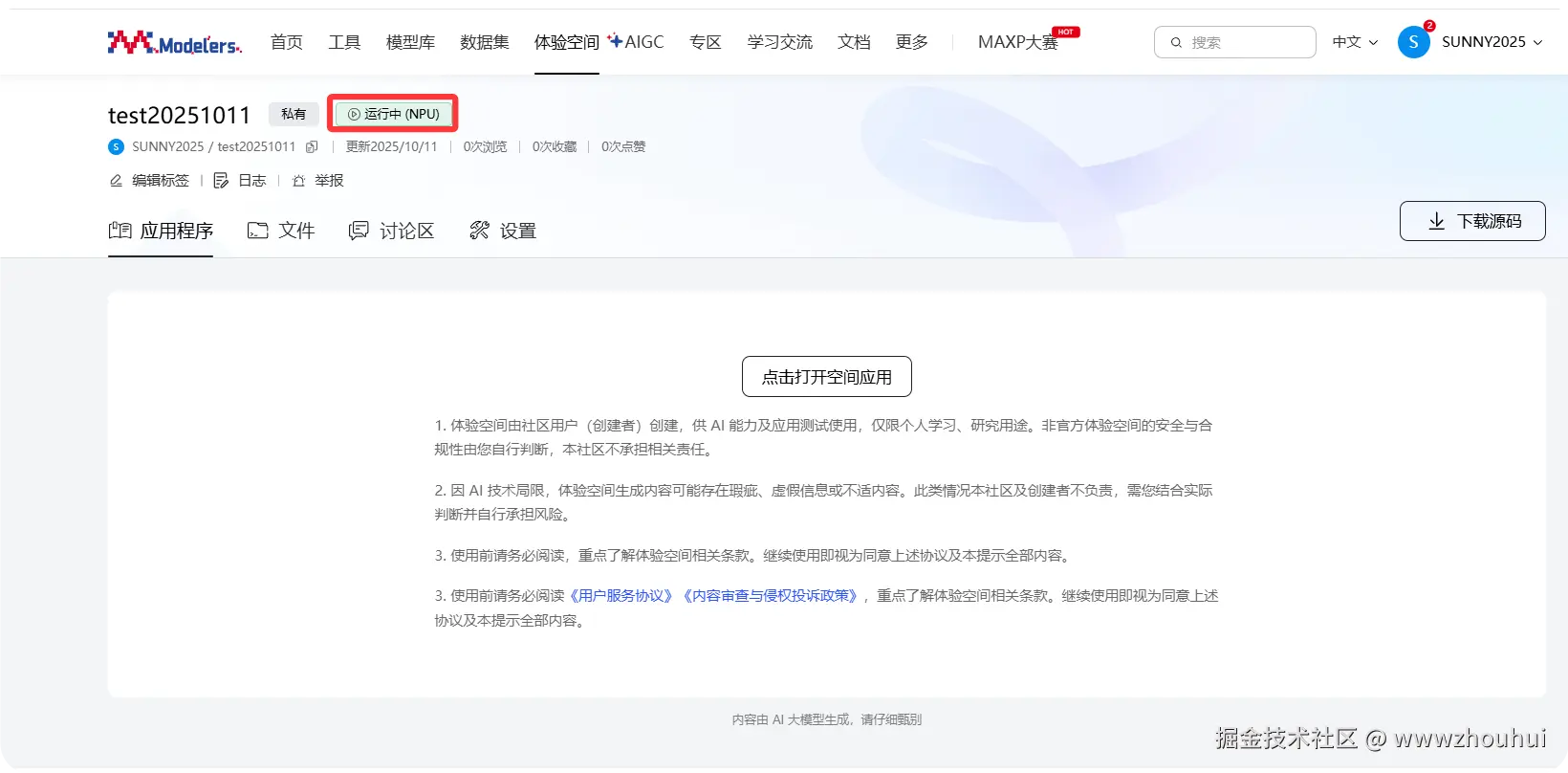
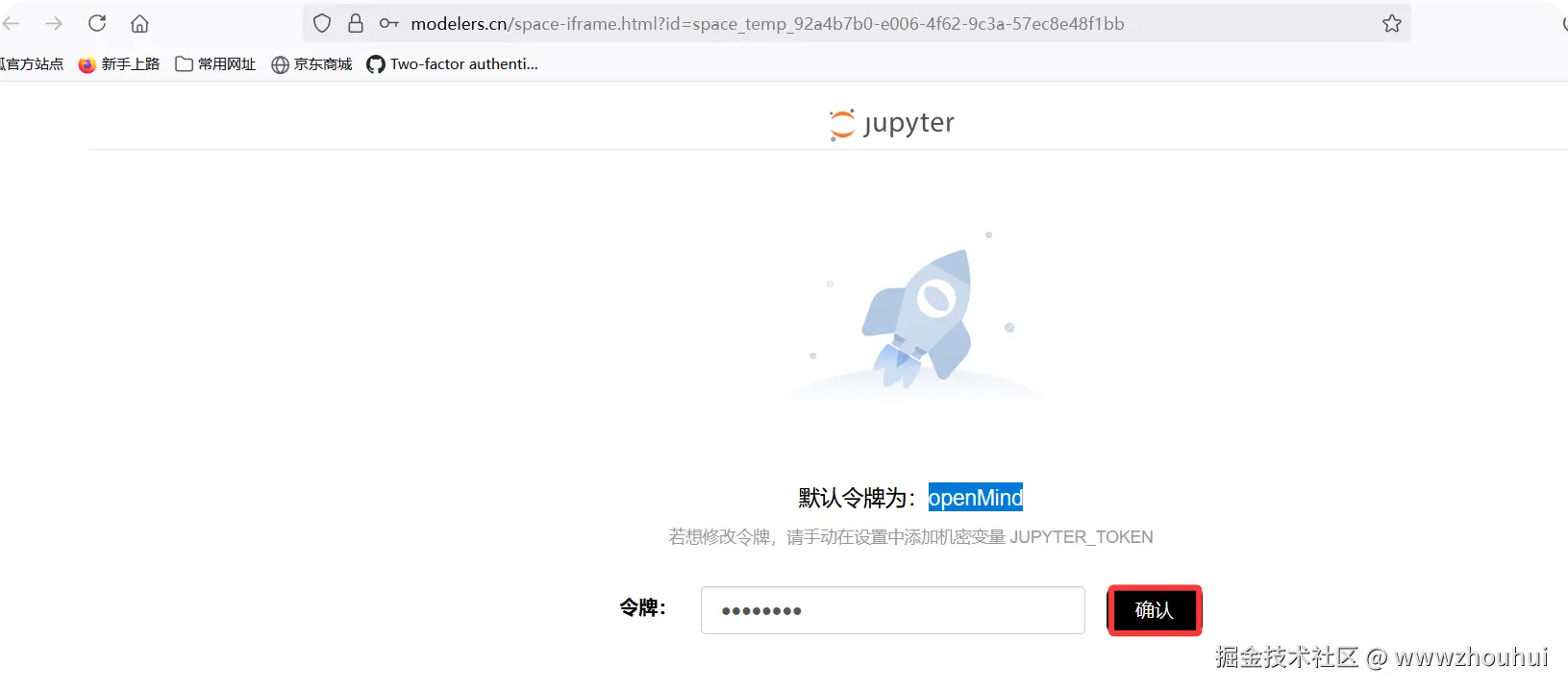
说明应用创建完成。点击中间"点击打开空间应用" 弹出openmind调试界面,输入默认令牌"openMind" 点击确定进入调试页面
模型下载
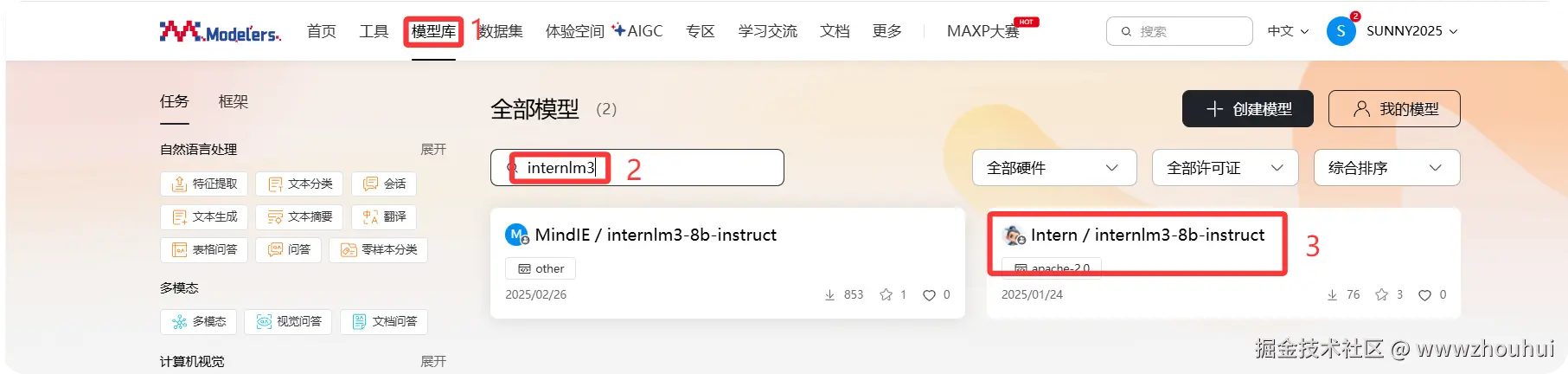
关于模型这块我们可以在魔乐社区提供模型库里面找模型。这里我们用到了internlm3-8b-instruct模型,所以我们搜索这个关键字检索这个模型。
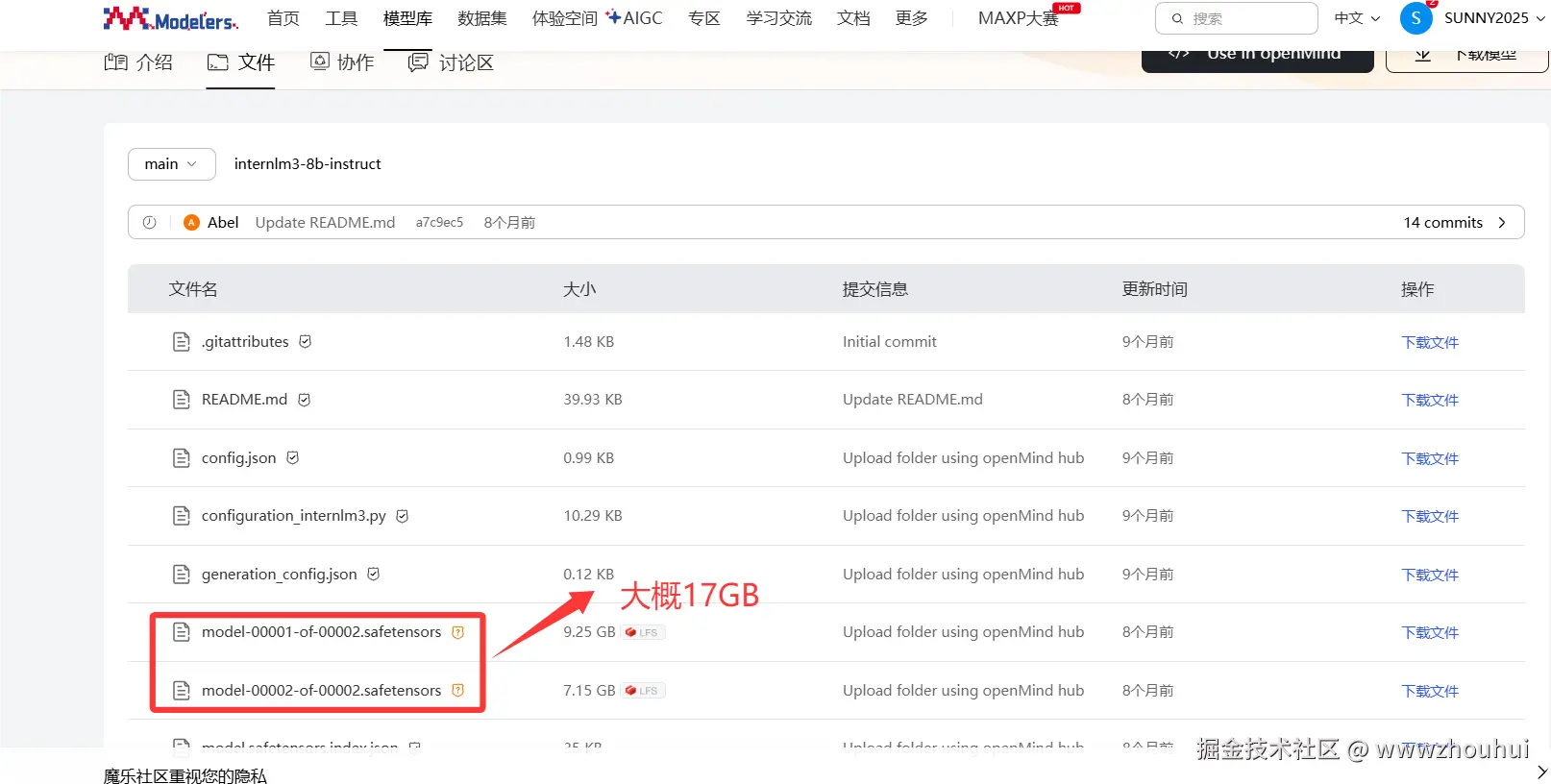
我们可以打开模型权重看一下模型文件,2个大的模型权重文件大概17GB
我们回到调试窗口页面,编写模型权重下载代码
openmind_hubdownload.py
python
from openmind_hub import snapshot_download
snapshot_download(
repo_id="Intern/internlm3-8b-instruct",
repo_type=None,
local_dir="/home/openmind/volume/notebook/internlm3-8b-instruct",
)然后重新打开窗口执行下面命令执行模型权重下载
shell
cd /home/openmind/volume/notebook
python openmind_hubdownload.py
这个样我们在/home/openmind/volume/notebook/internlm3-8b-instruct 文件夹下看到我们刚下载好的模型权重
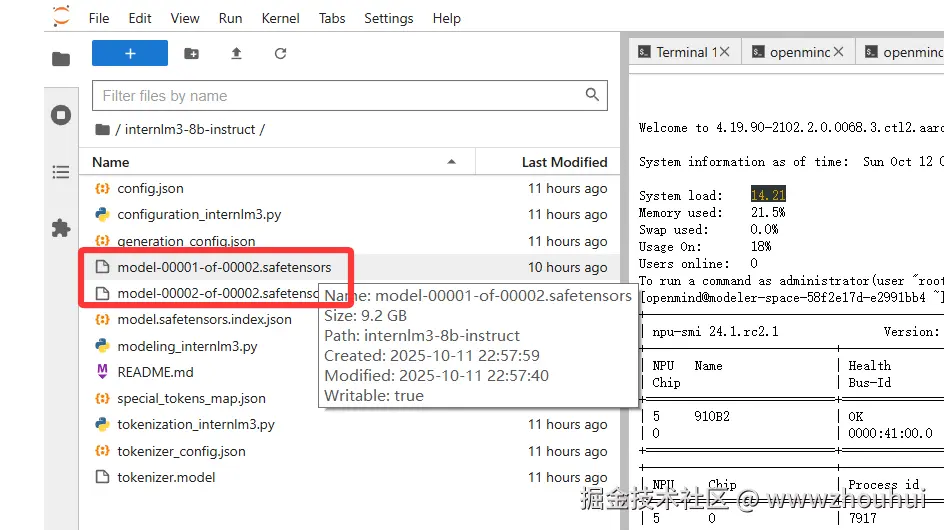
通过以上步骤我们就完成了模型下载。
依赖包安装
接下来我们需要编写推理代码,其中我们的推理代码包括接口代码和基于gradio页面代码,代码中会用到一些依赖包。
我编写依赖包文件requirements.txt
txt
fastapi
uvicorn
sse-starlette
pydantic
requests
transformers==4.47.1这里主要注意的是transformers 版本,因为容器镜像本身自带transformers 但是版本不符合模型推理要求,我们需要安装transformers==4.47.1 版本
执行下面命令确保依赖包安装
bash
cd /home/openmind/volume/notebook
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
模型推理代码
接下来我们编写模型推理代码。这块有2个代码一个是基于gradio 一个是api接口的
python
import os
import gradio as gr
import torch
from openmind import AutoModelForCausalLM, AutoTokenizer
from transformers import StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
from threading import Thread
tokenizer = AutoTokenizer.from_pretrained("/home/openmind/volume/notebook/internlm3-8b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("/home/openmind/volume/notebook/internlm3-8b-instruct", torch_dtype=torch.bfloat16, trust_remote_code=True)
model.to("npu:0")
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [2]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
def predict(message, history):
stop = StopOnTokens()
conversation = []
for user, assistant in history:
conversation.extend([{"role": "user", "content": user}, {"role": "assistant", "content": assistant}])
conversation.append({"role": "user", "content": message})
print(f'>>>conversation={conversation}', flush=True)
prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(tokenizer, timeout=100., skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=1024,
do_sample=True,
top_p=0.95,
top_k=50,
temperature=0.7,
repetition_penalty=1.0,
num_beams=1,
stopping_criteria=StoppingCriteriaList([stop])
)
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
partial_message = ""
for new_token in streamer:
partial_message += new_token
yield partial_message
if '</s>' in partial_message:
break
# Setting up the Gradio chat interface.
gr.ChatInterface(predict,
title="internlm3-8b-instruct对话",
description="警告:所有答案都是AI生成的,可能包含不准确的信息。",
examples=['合肥有哪些著名的旅游景点?', '海钓有哪些要领?']
).queue().launch()npu_openai_api.py
python
# NPU OpenAI API Server for InternLM3-8B-Instruct
# Usage: python npu_openai_api.py
# Visit http://localhost:8000/docs for API documentation
import time
from argparse import ArgumentParser
from contextlib import asynccontextmanager
from typing import Dict, List, Literal, Optional, Union
import torch
import uvicorn
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from openmind import AutoModelForCausalLM, AutoTokenizer
from pydantic import BaseModel, Field
from sse_starlette.sse import EventSourceResponse
from transformers import TextIteratorStreamer
from threading import Thread
@asynccontextmanager
async def lifespan(app: FastAPI):
"""Lifecycle manager for the FastAPI app"""
yield
# Cleanup if needed
pass
app = FastAPI(
title="InternLM3-8B NPU API",
description="OpenAI-compatible API for InternLM3-8B-Instruct on NPU",
version="1.0.0",
lifespan=lifespan
)
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
# Global variables for model and tokenizer
model = None
tokenizer = None
args = None
# ==================== Pydantic Models ====================
class ModelCard(BaseModel):
id: str
object: str = 'model'
created: int = Field(default_factory=lambda: int(time.time()))
owned_by: str = 'openmind'
root: Optional[str] = None
parent: Optional[str] = None
permission: Optional[list] = None
class ModelList(BaseModel):
object: str = 'list'
data: List[ModelCard] = []
class ChatMessage(BaseModel):
role: Literal['user', 'assistant', 'system']
content: str
class DeltaMessage(BaseModel):
role: Optional[Literal['user', 'assistant', 'system']] = None
content: Optional[str] = None
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
temperature: Optional[float] = 0.7
top_p: Optional[float] = 0.95
top_k: Optional[int] = 50
max_new_tokens: Optional[int] = 1024
stream: Optional[bool] = False
repetition_penalty: Optional[float] = 1.0
num_beams: Optional[int] = 1
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ChatMessage
finish_reason: Literal['stop', 'length']
class ChatCompletionResponseStreamChoice(BaseModel):
index: int
delta: DeltaMessage
finish_reason: Optional[Literal['stop', 'length']] = None
class UsageInfo(BaseModel):
prompt_tokens: int = 0
completion_tokens: int = 0
total_tokens: int = 0
class ChatCompletionResponse(BaseModel):
id: str = Field(default_factory=lambda: f"chatcmpl-{int(time.time())}")
model: str
object: Literal['chat.completion', 'chat.completion.chunk']
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
created: int = Field(default_factory=lambda: int(time.time()))
usage: Optional[UsageInfo] = None
# ==================== API Endpoints ====================
@app.get('/v1/models', response_model=ModelList)
async def list_models():
"""List available models"""
model_card = ModelCard(
id='internlm3-8b-instruct',
owned_by='openmind'
)
return ModelList(data=[model_card])
@app.get('/health')
async def health_check():
"""Health check endpoint"""
return {
'status': 'healthy',
'model_loaded': model is not None,
'device': 'npu:0'
}
def _dump_json(data: BaseModel, *args, **kwargs) -> str:
"""Dump pydantic model to JSON string"""
try:
return data.model_dump_json(*args, **kwargs)
except AttributeError: # pydantic<2.0.0
return data.json(*args, **kwargs)
def parse_messages_to_conversation(messages: List[ChatMessage]) -> tuple:
"""
Parse OpenAI-style messages to conversation format
Returns: (conversation_list, latest_user_message)
"""
conversation = []
system_message = None
# Extract system message if present
for msg in messages:
if msg.role == 'system':
system_message = msg.content
break
# Build conversation history (exclude the last user message)
user_msgs = []
assistant_msgs = []
for msg in messages:
if msg.role == 'system':
continue
elif msg.role == 'user':
user_msgs.append(msg.content)
elif msg.role == 'assistant':
assistant_msgs.append(msg.content)
# Pair up user and assistant messages for history
min_len = min(len(user_msgs), len(assistant_msgs))
for i in range(min_len):
conversation.append({
"role": "user",
"content": user_msgs[i]
})
conversation.append({
"role": "assistant",
"content": assistant_msgs[i]
})
# Get the latest user message (unpaired)
current_message = user_msgs[-1] if len(user_msgs) > len(assistant_msgs) else ""
return conversation, current_message, system_message
async def generate_stream(
messages: List[ChatMessage],
model_id: str,
temperature: float,
top_p: float,
top_k: int,
max_new_tokens: int,
repetition_penalty: float,
num_beams: int,
):
"""Generate streaming response"""
global model, tokenizer
# Parse messages
conversation, current_message, system_message = parse_messages_to_conversation(messages)
# Apply chat template
full_conversation = conversation.copy()
full_conversation.append({"role": "user", "content": current_message})
prompt = tokenizer.apply_chat_template(
full_conversation,
tokenize=False,
add_generation_prompt=True
)
# Tokenize
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Setup streamer
streamer = TextIteratorStreamer(
tokenizer,
timeout=100.0,
skip_prompt=True,
skip_special_tokens=True
)
# Generation kwargs
generate_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=max_new_tokens,
do_sample=True if temperature > 0 else False,
top_p=top_p,
top_k=top_k,
temperature=temperature,
repetition_penalty=repetition_penalty,
num_beams=num_beams,
)
# Start generation in a separate thread
thread = Thread(target=model.generate, kwargs=generate_kwargs)
thread.start()
# Send initial chunk with role
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(role='assistant', content=''),
finish_reason=None
)
chunk = ChatCompletionResponse(
model=model_id,
choices=[choice_data],
object='chat.completion.chunk'
)
yield f"data: {_dump_json(chunk, exclude_unset=True)}\n\n"
# Stream tokens
for new_token in streamer:
if '</s>' in new_token:
break
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(content=new_token),
finish_reason=None
)
chunk = ChatCompletionResponse(
model=model_id,
choices=[choice_data],
object='chat.completion.chunk'
)
yield f"data: {_dump_json(chunk, exclude_unset=True)}\n\n"
# Send final chunk with finish_reason
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(),
finish_reason='stop'
)
chunk = ChatCompletionResponse(
model=model_id,
choices=[choice_data],
object='chat.completion.chunk'
)
yield f"data: {_dump_json(chunk, exclude_unset=True)}\n\n"
yield "data: [DONE]\n\n"
def generate_non_stream(
messages: List[ChatMessage],
temperature: float,
top_p: float,
top_k: int,
max_new_tokens: int,
repetition_penalty: float,
num_beams: int,
) -> str:
"""Generate non-streaming response"""
global model, tokenizer
# Parse messages
conversation, current_message, system_message = parse_messages_to_conversation(messages)
# Apply chat template
full_conversation = conversation.copy()
full_conversation.append({"role": "user", "content": current_message})
prompt = tokenizer.apply_chat_template(
full_conversation,
tokenize=False,
add_generation_prompt=True
)
# Tokenize
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Generate
with torch.no_grad():
outputs = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=True if temperature > 0 else False,
top_p=top_p,
top_k=top_k,
temperature=temperature,
repetition_penalty=repetition_penalty,
num_beams=num_beams,
pad_token_id=tokenizer.eos_token_id,
)
# Decode response
response = tokenizer.decode(
outputs[0][len(model_inputs.input_ids[0]):],
skip_special_tokens=True
)
return response
@app.post('/v1/chat/completions')
async def create_chat_completion(request: ChatCompletionRequest):
"""Create a chat completion (OpenAI-compatible endpoint)"""
global model, tokenizer
if model is None or tokenizer is None:
raise HTTPException(status_code=503, detail="Model not loaded")
# Validate messages
if not request.messages:
raise HTTPException(status_code=400, detail="Messages cannot be empty")
if request.messages[-1].role != 'user':
raise HTTPException(
status_code=400,
detail="Last message must be from user"
)
try:
# Handle streaming
if request.stream:
return EventSourceResponse(
generate_stream(
messages=request.messages,
model_id=request.model,
temperature=request.temperature,
top_p=request.top_p,
top_k=request.top_k,
max_new_tokens=request.max_new_tokens,
repetition_penalty=request.repetition_penalty,
num_beams=request.num_beams,
),
media_type="text/event-stream"
)
# Handle non-streaming
response_text = generate_non_stream(
messages=request.messages,
temperature=request.temperature,
top_p=request.top_p,
top_k=request.top_k,
max_new_tokens=request.max_new_tokens,
repetition_penalty=request.repetition_penalty,
num_beams=request.num_beams,
)
choice = ChatCompletionResponseChoice(
index=0,
message=ChatMessage(role='assistant', content=response_text),
finish_reason='stop'
)
return ChatCompletionResponse(
model=request.model,
choices=[choice],
object='chat.completion',
usage=UsageInfo() # You can calculate actual token counts if needed
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# ==================== CLI Arguments ====================
def _get_args():
parser = ArgumentParser(description="InternLM3-8B NPU OpenAI API Server")
parser.add_argument(
'-c',
'--checkpoint-path',
type=str,
default='/home/openmind/volume/notebook/internlm3-8b-instruct',
help='Model checkpoint path'
)
parser.add_argument(
'--server-port',
type=int,
default=8000,
help='Server port (default: 8000)'
)
parser.add_argument(
'--server-name',
type=str,
default='0.0.0.0',
help='Server host (default: 0.0.0.0 for all interfaces)'
)
parser.add_argument(
'--npu-device',
type=str,
default='npu:0',
help='NPU device to use (default: npu:0)'
)
return parser.parse_args()
# ==================== Main ====================
if __name__ == '__main__':
args = _get_args()
print(f"Loading model from {args.checkpoint_path}...")
print(f"Target device: {args.npu_device}")
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path,
trust_remote_code=True
)
print("✓ Tokenizer loaded")
# Load model
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.to(args.npu_device)
model.eval()
print(f"✓ Model loaded on {args.npu_device}")
print(f"\n{'='*60}")
print(f"🚀 Server starting on http://{args.server_name}:{args.server_port}")
print(f"📖 API docs available at http://{args.server_name}:{args.server_port}/docs")
print(f"{'='*60}\n")
# Start server
uvicorn.run(
app,
host=args.server_name,
port=args.server_port,
workers=1,
log_level="info"
)验证测试
启动程序非常简单执行python app.py 和python npu_openai_api.py 这块我们考虑到调试窗口没办法通过网页打开测试,所以我们使用接口调试。启动接口
shell
cd /home/openmind/volume/notebook
python npu_openai_api.py 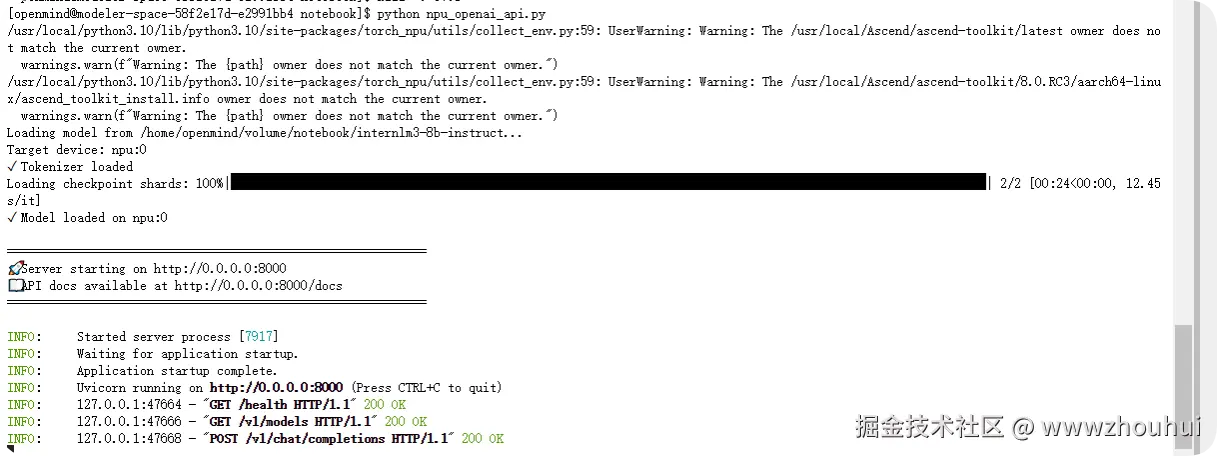
看到上面的画面模型接口启动完成,对外提供一个8000的接口服务。
接下来我们编写测试代码
test_npu_api.py
python
#!/usr/bin/env python3
"""
Test script for NPU OpenAI API
Usage:
python test_npu_api.py # Non-streaming test
python test_npu_api.py --stream # Streaming test
python test_npu_api.py --benchmark # Benchmark test
"""
import argparse
import json
import time
import requests
BASE_URL = "http://localhost:8000"
def test_health():
"""Test health check endpoint"""
print("Testing health check...")
response = requests.get(f"{BASE_URL}/health")
print(f"Status: {response.status_code}")
print(f"Response: {json.dumps(response.json(), indent=2)}\n")
def test_list_models():
"""Test model listing endpoint"""
print("Testing model listing...")
response = requests.get(f"{BASE_URL}/v1/models")
print(f"Status: {response.status_code}")
print(f"Response: {json.dumps(response.json(), indent=2)}\n")
def test_chat_completion(stream=False):
"""Test chat completion endpoint"""
print(f"Testing chat completion ({'streaming' if stream else 'non-streaming'})...")
payload = {
"model": "internlm3-8b-instruct",
"messages": [
{"role": "system", "content": "你是一个有帮助的AI助手。"},
{"role": "user", "content": "你好,请简单介绍一下合肥这座城市。"}
],
"temperature": 0.7,
"top_p": 0.95,
"top_k": 50,
"max_new_tokens": 512,
"stream": stream
}
start_time = time.time()
if stream:
# Streaming request
response = requests.post(
f"{BASE_URL}/v1/chat/completions",
json=payload,
stream=True,
headers={"Accept": "text/event-stream"}
)
print(f"Status: {response.status_code}")
print("Response (streaming):")
print("-" * 60)
full_content = ""
for line in response.iter_lines():
if line:
line = line.decode('utf-8')
if line.startswith('data: '):
data = line[6:] # Remove 'data: ' prefix
if data == '[DONE]':
break
try:
chunk = json.loads(data)
if chunk['choices'][0]['delta'].get('content'):
content = chunk['choices'][0]['delta']['content']
full_content += content
print(content, end='', flush=True)
except json.JSONDecodeError:
pass
print("\n" + "-" * 60)
elapsed = time.time() - start_time
print(f"Time: {elapsed:.2f}s")
print(f"Total characters: {len(full_content)}")
else:
# Non-streaming request
response = requests.post(
f"{BASE_URL}/v1/chat/completions",
json=payload
)
print(f"Status: {response.status_code}")
result = response.json()
elapsed = time.time() - start_time
print("Response:")
print("-" * 60)
print(result['choices'][0]['message']['content'])
print("-" * 60)
print(f"Time: {elapsed:.2f}s")
print(f"Finish reason: {result['choices'][0]['finish_reason']}")
print()
def test_multi_turn_conversation():
"""Test multi-turn conversation"""
print("Testing multi-turn conversation...")
messages = [
{"role": "system", "content": "你是一个有帮助的AI助手。"},
{"role": "user", "content": "合肥有哪些著名的旅游景点?"}
]
# First turn
print("Turn 1:")
print("-" * 60)
payload = {
"model": "internlm3-8b-instruct",
"messages": messages,
"temperature": 0.7,
"max_new_tokens": 256,
"stream": False
}
response = requests.post(f"{BASE_URL}/v1/chat/completions", json=payload)
result = response.json()
assistant_message = result['choices'][0]['message']['content']
print(f"User: {messages[-1]['content']}")
print(f"Assistant: {assistant_message}")
print()
# Add assistant response to conversation
messages.append({"role": "assistant", "content": assistant_message})
# Second turn
messages.append({"role": "user", "content": "那合肥最佳游览季节是什么时候?"})
print("Turn 2:")
print("-" * 60)
payload["messages"] = messages
response = requests.post(f"{BASE_URL}/v1/chat/completions", json=payload)
result = response.json()
assistant_message = result['choices'][0]['message']['content']
print(f"User: {messages[-1]['content']}")
print(f"Assistant: {assistant_message}")
print("-" * 60)
print()
def benchmark():
"""Run benchmark tests"""
print("Running benchmark...")
print("=" * 60)
test_cases = [
{"content": "你好", "desc": "Short query"},
{"content": "请详细介绍一下人工智能的发展历史。", "desc": "Medium query"},
{"content": "请从技术原理、应用场景、优缺点等多个角度详细分析深度学习技术。", "desc": "Long query"},
]
for i, test_case in enumerate(test_cases, 1):
print(f"\nTest {i}: {test_case['desc']}")
print("-" * 60)
payload = {
"model": "internlm3-8b-instruct",
"messages": [
{"role": "user", "content": test_case['content']}
],
"temperature": 0.7,
"max_new_tokens": 256,
"stream": False
}
start_time = time.time()
response = requests.post(f"{BASE_URL}/v1/chat/completions", json=payload)
elapsed = time.time() - start_time
if response.status_code == 200:
result = response.json()
content = result['choices'][0]['message']['content']
tokens = len(content) # Approximate
print(f"Query: {test_case['content']}")
print(f"Response length: {tokens} chars")
print(f"Time: {elapsed:.2f}s")
print(f"Speed: {tokens/elapsed:.2f} chars/s")
else:
print(f"Error: {response.status_code}")
print("\n" + "=" * 60)
def main():
parser = argparse.ArgumentParser(description="Test NPU OpenAI API")
parser.add_argument('--stream', action='store_true', help='Test streaming mode')
parser.add_argument('--multi-turn', action='store_true', help='Test multi-turn conversation')
parser.add_argument('--benchmark', action='store_true', help='Run benchmark tests')
parser.add_argument('--all', action='store_true', help='Run all tests')
args = parser.parse_args()
try:
# Always test health and models first
test_health()
test_list_models()
if args.all:
test_chat_completion(stream=False)
test_chat_completion(stream=True)
test_multi_turn_conversation()
benchmark()
elif args.benchmark:
benchmark()
elif args.multi_turn:
test_multi_turn_conversation()
elif args.stream:
test_chat_completion(stream=True)
else:
test_chat_completion(stream=False)
print("✓ All tests completed successfully!")
except requests.exceptions.ConnectionError:
print("❌ Error: Cannot connect to the API server.")
print(f" Make sure the server is running at {BASE_URL}")
except Exception as e:
print(f"❌ Error: {e}")
if __name__ == '__main__':
main()我们开启另外一个终端窗口执行下面命令
bash
cd /home/openmind/volume/notebook
python test_npu_api.py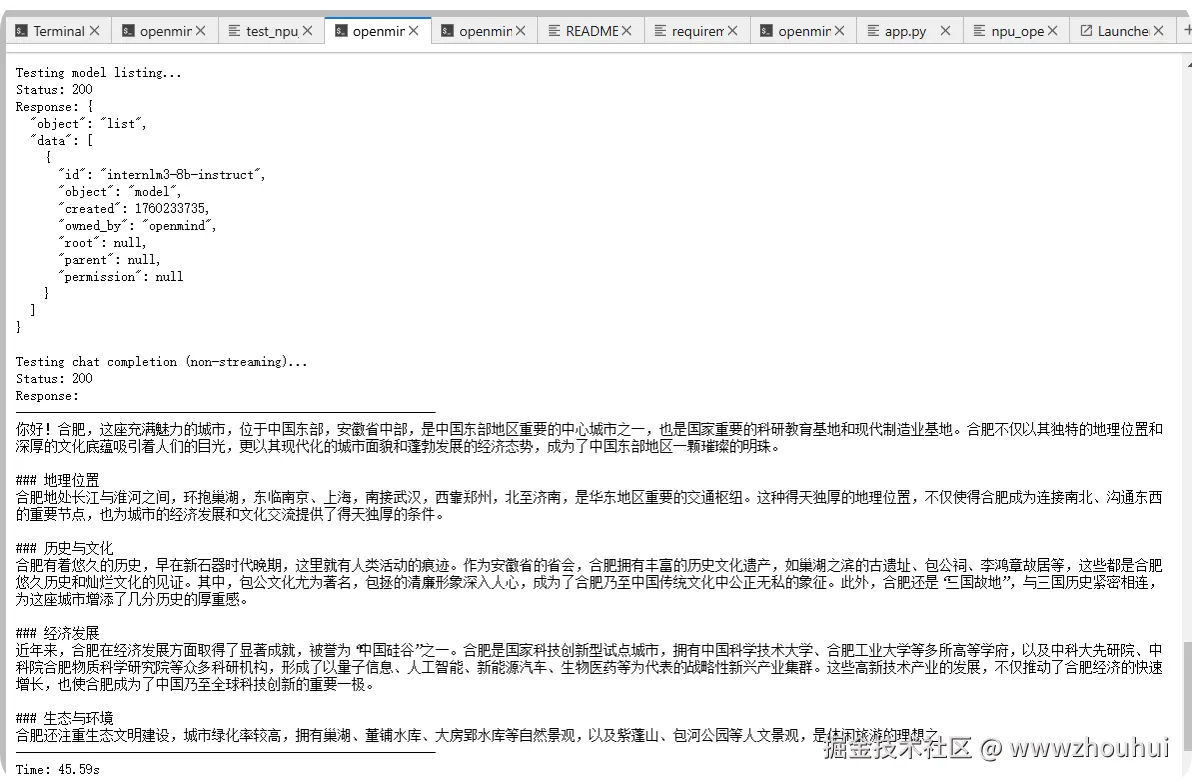
通过上面的方式我们就实现模型推理
部署和发布
我们前面的步骤主要的目的是在调试窗口中实现了模型下载,模型接口推理和验证测试。实际这个过程我们需要把上面的代码上传到魔乐社区。这里我们拿我之前的一个项目"历史人物科普短视频(4个图生视频多分镜版)"给大家介绍这个代码目录结构
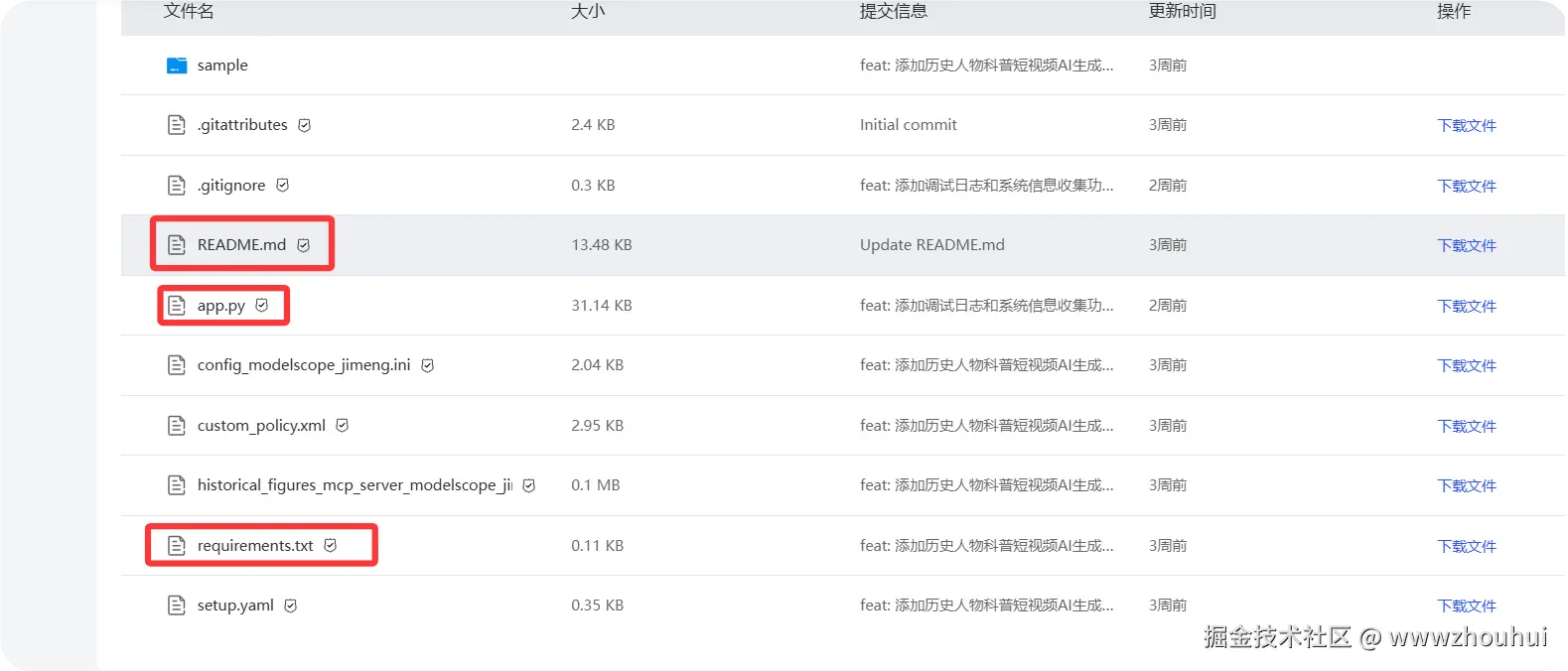
最主要的是三个文件其中app.py是程序的入口 ,requirements.txt 程序依赖包。README.md 项目说明
创空间应用前面使用的基于Application,这次就需要换成graido
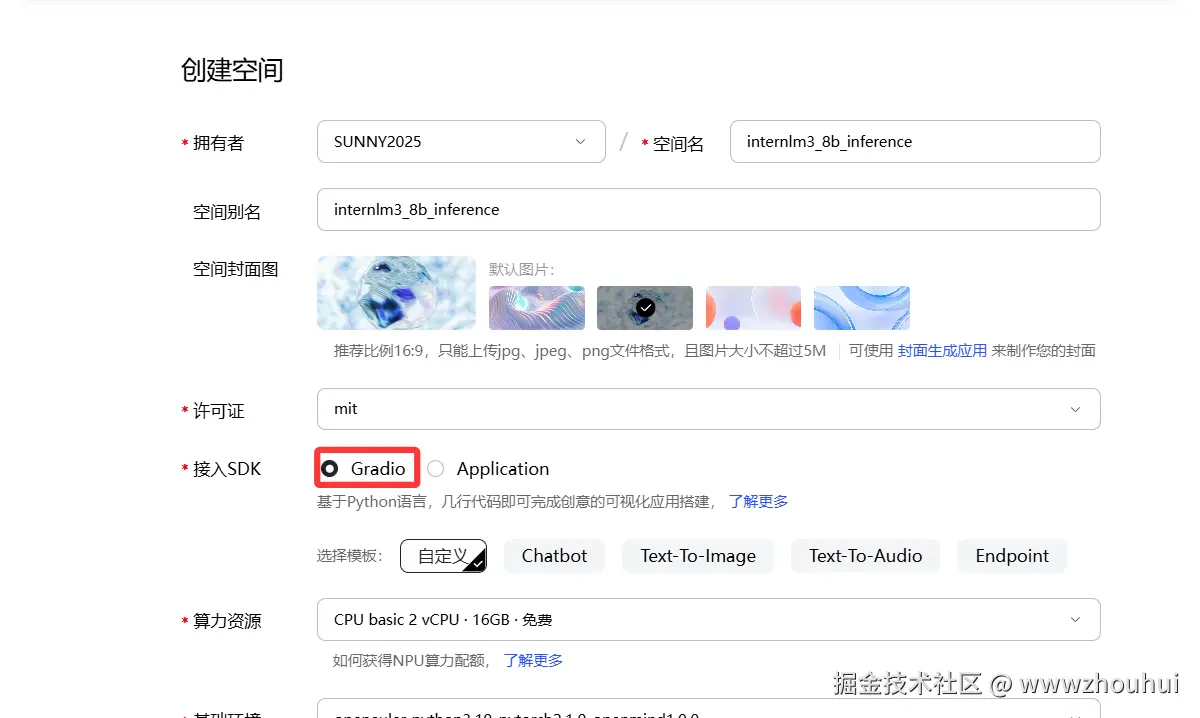
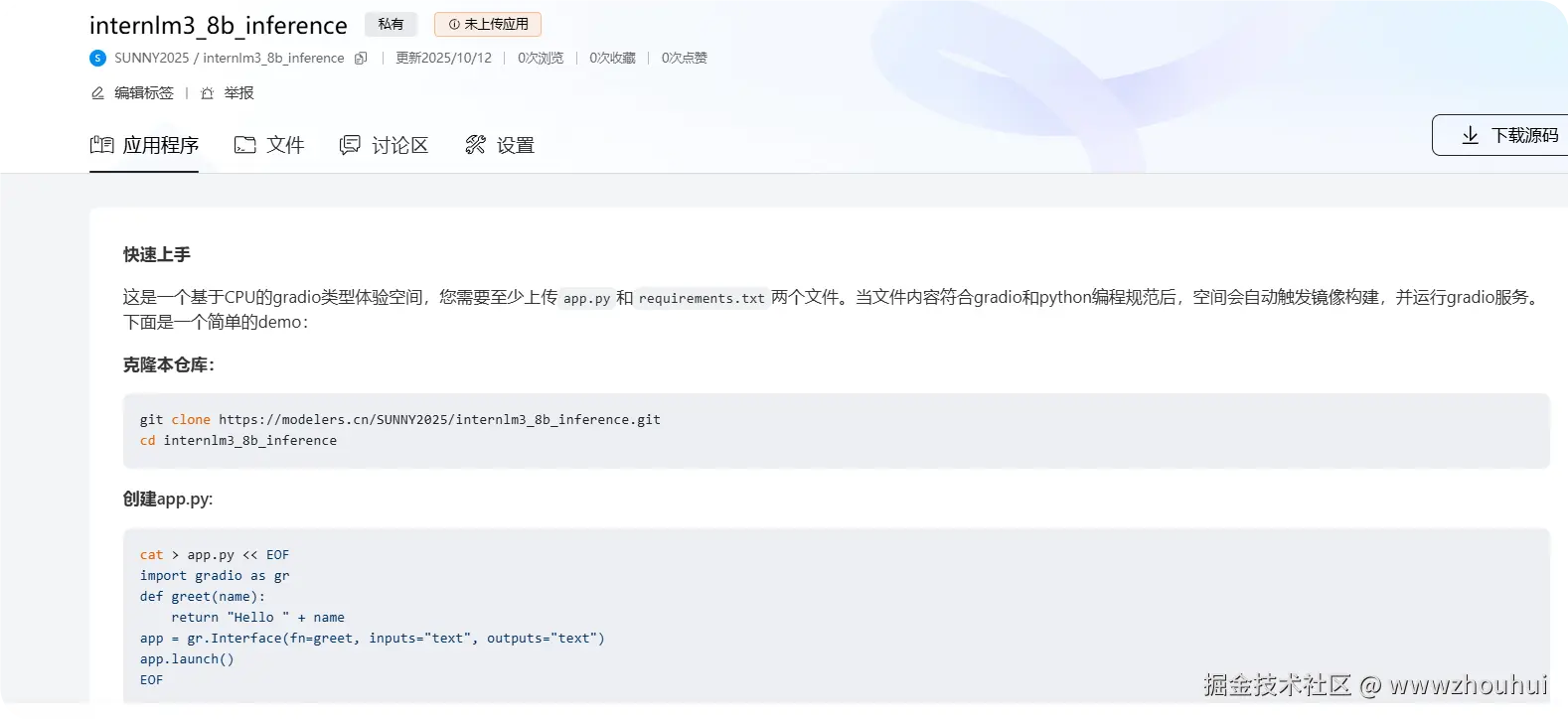
根据上面的提示我们把代码上传到魔乐社区仓库中,重启完成应用部署。
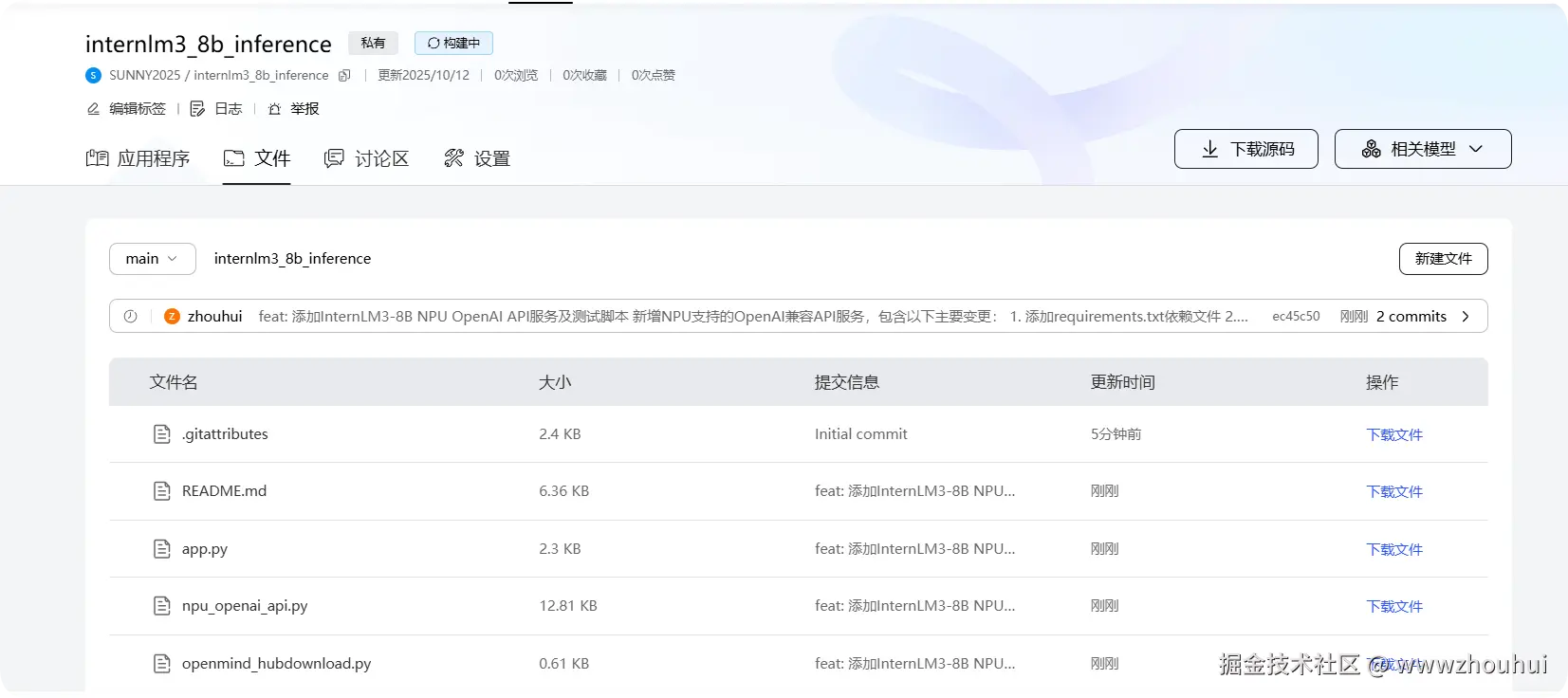
后面的流程就不详细给大家介绍了。
完整的代码打包放百度网盘,需要自取(链接: pan.baidu.com/s/1_HFC1qe4... 提取码: v46q)
3.项目介绍
上面提到了我们的一个历史人物科普短视频(4个图生视频多分镜版)的项目,目前我们也在魔乐社区上部署了。
这个一键生成完整视频用户只需要输入一段简单的提示词比如:曹操。这样时候系统会自动调用文本生成模型,文本生图模型、图生视频模型、文生生成语音模型最后把这些合成一个完整的短视频。由于生图和生成视频时间限制这里我们做了4个分境,然偶把最后生成4个分镜短视频合成一个大概有20秒短视频。生成时间大概3-5分钟(主要取决后端生成视频和合成视频所需花费时间)
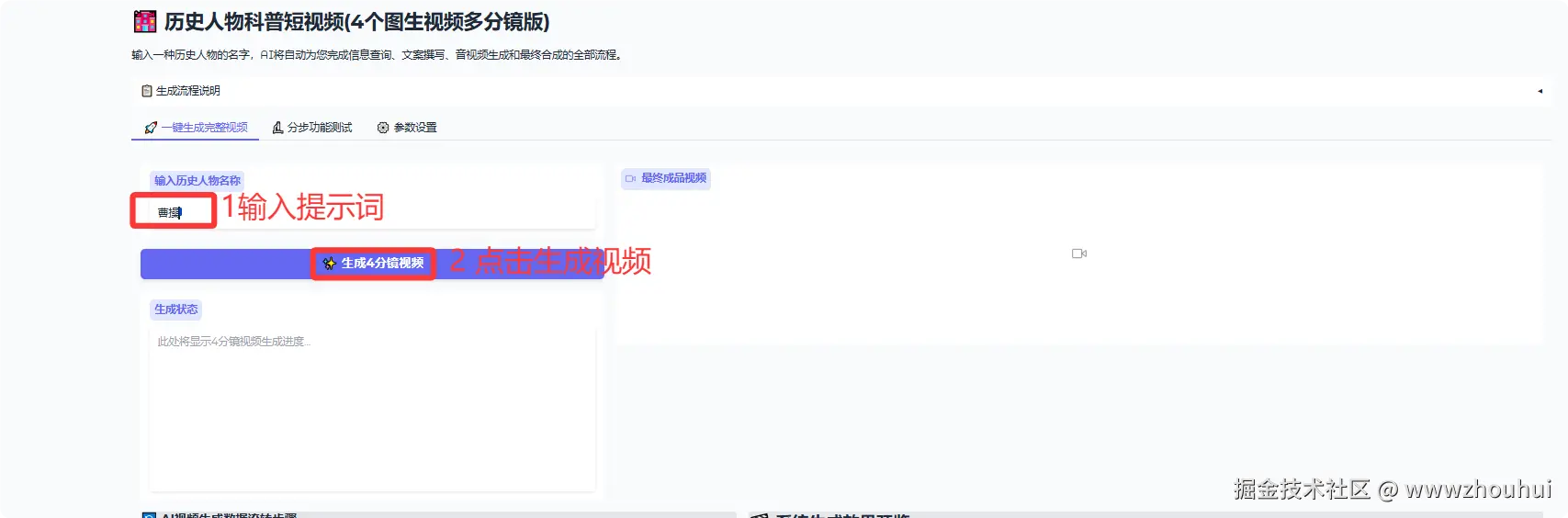
生成的效果如下:
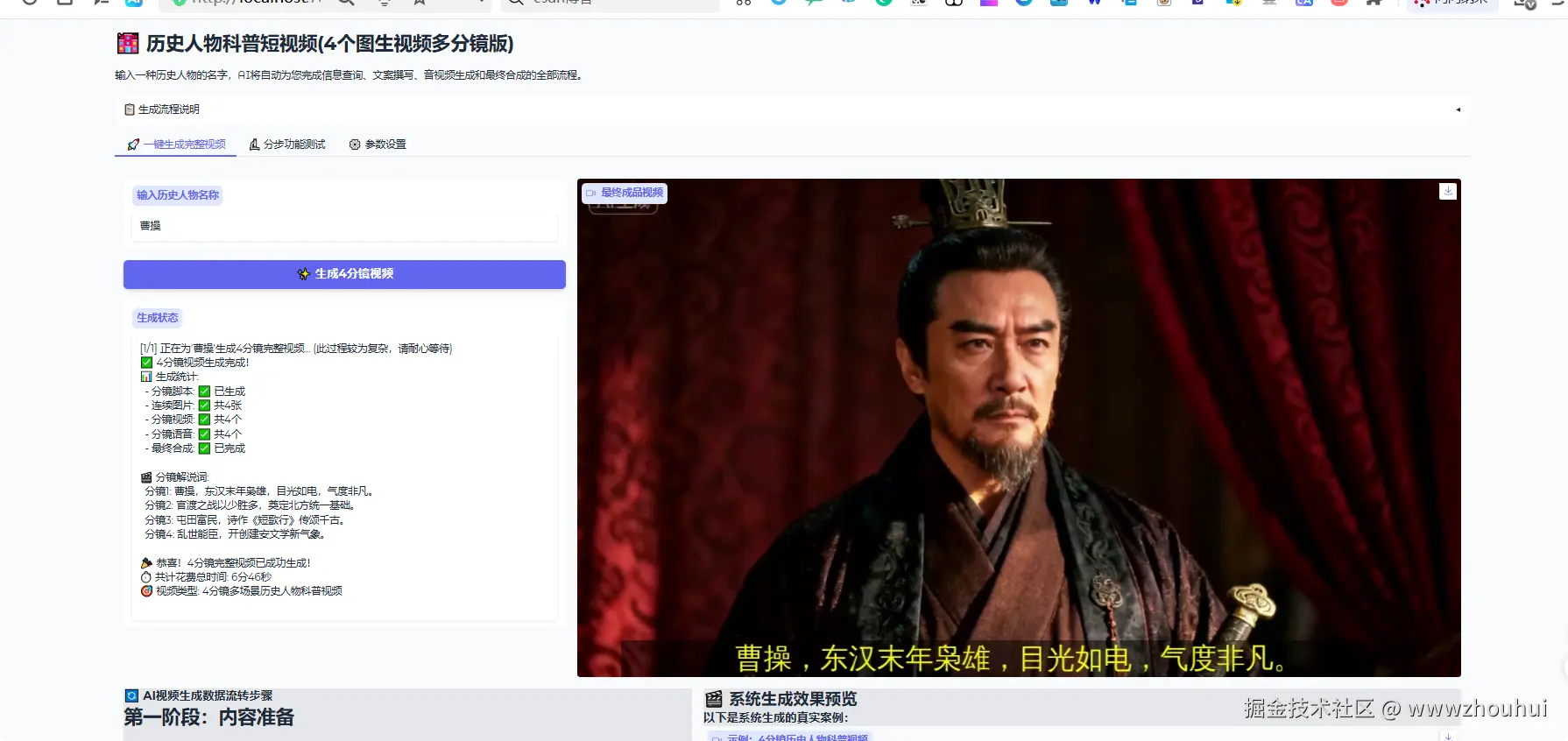
生成的视频效果如下:
这个项目非常有意思感兴趣的小伙伴去魔乐社区来体验搜索关键字"历史" 可以检索到这个项目
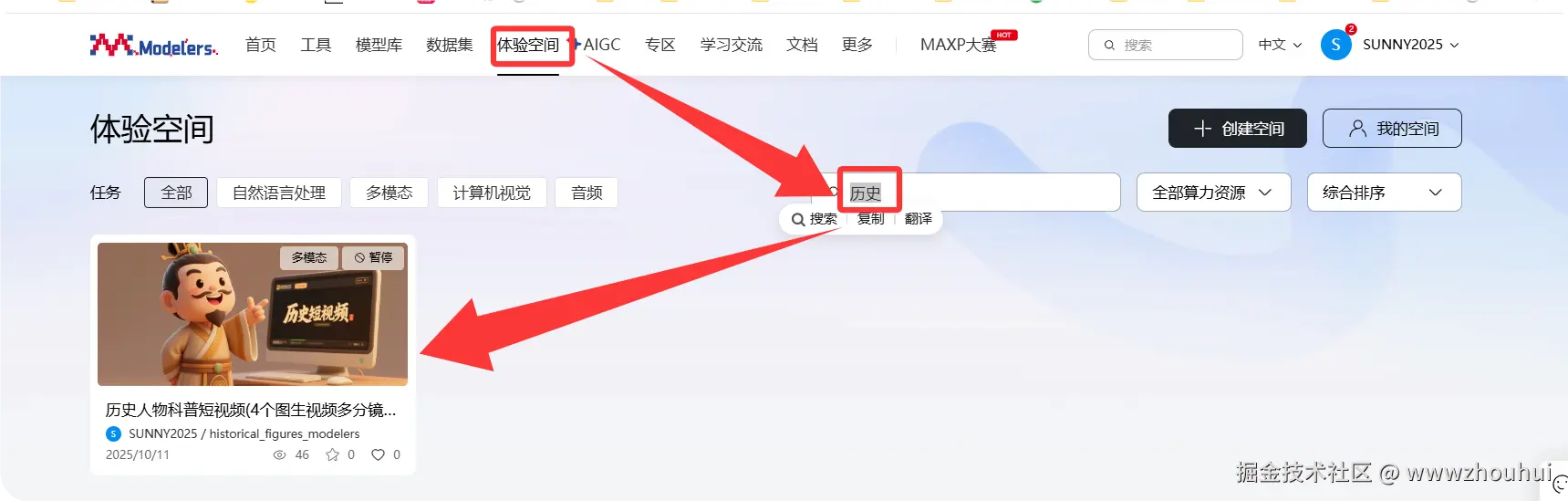
也可以输入下面网站直达体验地址modelers.cn/spaces/SUNN...
觉的项目不错麻烦,点赞,收藏,转发。
4.总结
今天主要带大家了解并实现了基于魔乐社区和华为昇腾 NPU 显卡进行模型推理的完整流程,该流程以华为昇腾 NPU 显卡为算力核心,结合魔乐社区的开源平台支持,搭配 Gradio 交互界面与 OpenAI 兼容 API 接口,形成了一套从模型下载、环境配置到推理验证、部署发布的国产化 AI 模型应用解决方案。
感兴趣的小伙伴可以通过文中提供的魔乐社区体验地址直接试用相关项目,也可以参考源码根据实际需求进行自定义开发。今天的分享就到这里结束了,我们下一篇文章见。