一、DINOv3 + KNN 构建自监督图像分类模型
DINOv3 是 Meta 2025年8月推出的视觉开源模型。核心优势在于通过大规模无监督预训练获得高度通用且语义丰富的图像表征能力。最大的亮点是 DINOv3 的骨干网络在完全冻结的情况下,仅通过添加轻量级任务头就能在多种任务上取得优异表现,无需微调即可直接应用。
这一特性可以改变传统视觉任务的开发流程。以往,面对一个新的视觉任务,开发者通常需要准备大量带标签的数据,并投入计算资源对预训练模型进行微调,以使其适应特定的数据分布和类别。现在依据 DINOv3 骨干网络强达的语义特征提取能力,无需骨干网络额外的训练,仅结合简易的线性任务头 或 KNN 、SVM、朴素贝叶斯等下游算法,即可快速构建效果良好的模型,进一步简化了模型构建的流程和复杂度,还减少了对标注数据的依赖。
如下图所示,展示了 DINOv3 提取特征获得的余弦相似度图,每张图中都呈现了被红叉标记的区域,与其他区域的相似程度:

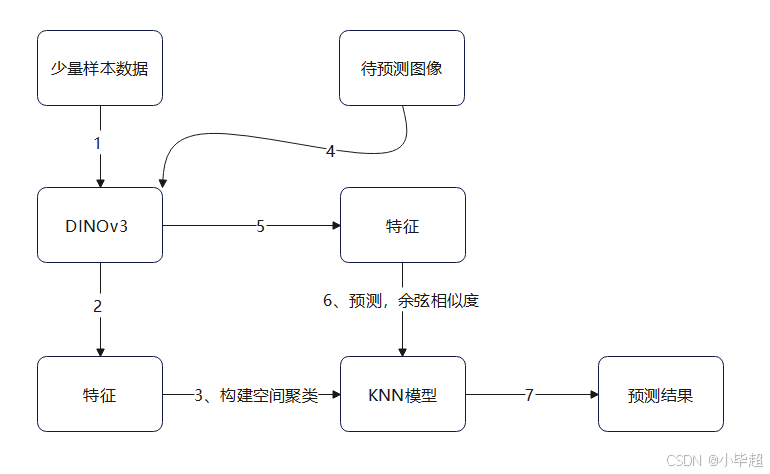
本文就基于 DINOv3 强大的特征提取能力,构建 DINOv3 + KNN 的图像分类模型,整个过程无需对模型进行任何微调训练,仅提供少量样本由 DINOv3 提取语义特征,然后使用 KNN 构建空间聚类模型,后续预测图像同样先由 DINOv3 提取语义特征,然后由 KNN 依据余弦相似度找到最相似样品,进而预测目标的类别,KNN 构建时间基本在秒级,所以开发过程几乎没有训练等待时长,另外就算遇到预测错误的情况仅需增加样本添加至KNN即可,而不像传统做法要重新训练模型。
该过程,在下面猫狗分类的场景中,在各种自然背景以及各种角度下仅提供猫狗各20张,共40张图像,即可在测试集图像(共2000张)上达到 99% 的准确率。
下面实验整体处理过程如下图所示:
本次实验使用 dinov3-vitb16-pretrain-lvd1689m 模型,huggleface 地址:
https://huggingface.co/facebook/dinov3-vitb16-pretrain-lvd1689m
如果网络连接不通也可以使用 ModelScope ,地址如下:
https://modelscope.cn/models/facebook/dinov3-vitb16-pretrain-lvd1689m
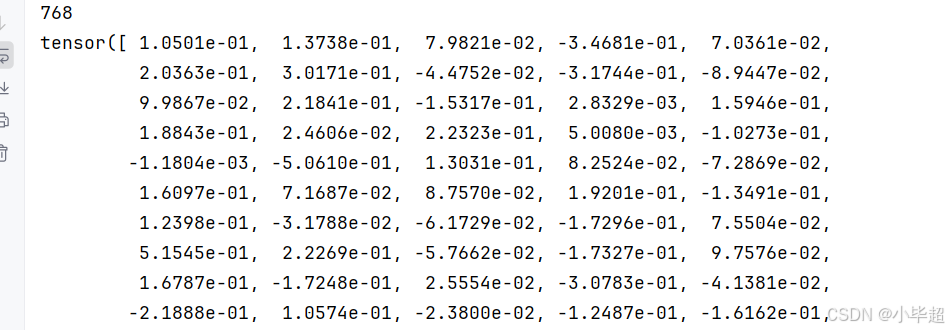
以下是使用 DINOv3 模型提取图像特征的示例过程。模型会为每张输入图像生成一个 768 维的向量作为其语义表征。
python
from transformers import AutoImageProcessor, AutoModel
import torch
from PIL import Image
def main():
# 加载模型
model_path = "facebook/dinov3-vitb16-pretrain-lvd1689m"
processor = AutoImageProcessor.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
device = torch.device('cuda:0' if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
## 特征提取
images = Image.open('img/dog.png')
with torch.no_grad():
inputs = processor(images=images, return_tensors="pt").to(device)
outputs = model(**inputs)
image_features = outputs.last_hidden_state
image_features = image_features.mean(dim=1)
image_features = image_features[0]
print(len(image_features))
print(image_features)
if __name__ == '__main__':
main()运行效果:
二、实验数据集介绍
实验数据集使用 ModelScope 上公开的猫狗二分类数据集,包含各种自然场景、各种角度下的猫和狗的图像,具有很好的多样性和挑战性。数据集地址如下:
数据集包括: 训练集:6000张,验证集:2000张,测试集:2000张,由于我们无需模型训练,本次直接取验证集下的猫和狗分别前20张,共40张图像,作为样本构建 KNN,然后对测试集的 2000 张图像进行预测和评估。
三、构建 KNN 特征空间模型
这里使用 scikit-learn 库中的 KNeighborsClassifier 来实现,并选择余弦相似度作为距离度量。
python
import os
import time
from transformers import AutoImageProcessor, AutoModel
from sklearn.neighbors import KNeighborsClassifier
import torch
from PIL import Image
import joblib
from tqdm import tqdm
## 验证集地址,下面每种分类只使用20张
val_img_path = "cat_vs_dog_class/val"
## 类别标识
classify = {"cats": 0, "dogs": 1}
# 加载模型
model_path = "facebook/dinov3-vitb16-pretrain-lvd1689m"
processor = AutoImageProcessor.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
device = torch.device('cuda:0' if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def get_features(images):
'''特征提取'''
with torch.no_grad():
inputs = processor(images=images, return_tensors="pt").to(device)
outputs = model(**inputs)
image_features = outputs.last_hidden_state
image_features = image_features.mean(dim=1)
return image_features[0].cpu()
def build_knn(knn_cache_model="knn_model.joblib"):
'''构建KNN模型'''
if os.path.exists(knn_cache_model):
return joblib.load(knn_cache_model)
knn = KNeighborsClassifier(n_neighbors=5, metric='cosine')
features, labels = [], []
for cl in os.listdir(val_img_path):
label = classify[cl]
for img_name in tqdm(os.listdir(os.path.join(val_img_path, cl))[:20], desc="Build:" + cl):
image = Image.open(os.path.join(val_img_path, cl, img_name))
feature = get_features(image)
features.append(feature)
labels.append(label)
knn.fit(features, labels)
# 保存KNN结构
joblib.dump(knn, knn_cache_model, compress=3)
return knn
def main():
## 构建 KNN
t = time.time()
knn = build_knn()
print(f"构建KNN耗时:{(time.time() - t)}s")
## 使用单个图像测试
test_image_path = 'img/dog.png'
test_image = Image.open(test_image_path)
test_features = get_features(test_image)
prediction = knn.predict([test_features])
print(f"{test_image_path} --> 预测类别: {list(classify.keys())[prediction[0]]}")
if __name__ == '__main__':
main()运行效果,构建KNN模型只需4.5s:

图像预测测试:
为了直观地展示模型的预测效果,这里从测试集中抽取部分图像进行预测并可视化。
python
import os
from transformers import AutoImageProcessor, AutoModel
import torch
from PIL import Image
import joblib
import random
import matplotlib.pyplot as plt
# 测试集
test_img_path = "cat_vs_dog_class/test"
classify = ["cat", "dog"]
# 加载模型
model_path = "facebook/dinov3-vitb16-pretrain-lvd1689m"
processor = AutoImageProcessor.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
device = torch.device('cuda:0' if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def get_features(images):
'''特征提取'''
with torch.no_grad():
inputs = processor(images=images, return_tensors="pt").to(device)
outputs = model(**inputs)
image_features = outputs.last_hidden_state
image_features = image_features.mean(dim=1)
return image_features[0].cpu()
def get_knn(knn_cache_model="knn_model.joblib"):
'''直接读取上一步创建好的KNN'''
return joblib.load(knn_cache_model)
def main():
knn = get_knn()
## 准备测试数据
test_images = []
for cl in os.listdir(test_img_path):
for img_name in os.listdir(os.path.join(test_img_path, cl))[:8]:
test_images.append(Image.open(os.path.join(test_img_path, cl, img_name)))
## 随机打乱
random.shuffle(test_images)
## 预测
# 分成四个一组
test_images = list(zip(*[iter(test_images)] * 4))
for g in test_images:
plt.figure(figsize=(8, 8))
for i, image in enumerate(g):
plt.subplot(2, 2, i + 1)
feature = get_features(image)
prediction = classify[knn.predict([feature])[0]]
plt.imshow(image)
plt.title(prediction)
plt.show()
if __name__ == '__main__':
main()预测效果:



四、大规模测试集测试
主要观察模型在测试集2000张图像上的准确率、精确率、召回率、以及 F1 分数:
python
import os
from transformers import AutoImageProcessor, AutoModel
import torch
from PIL import Image
import joblib
from tqdm import tqdm
from sklearn.metrics import f1_score, precision_score, recall_score
# 测试集
test_img_path = "cat_vs_dog_class/test"
classify = {"cats": 0, "dogs": 1}
# 加载模型
model_path = "facebook/dinov3-vitb16-pretrain-lvd1689m"
processor = AutoImageProcessor.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
device = torch.device('cuda:0' if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def get_features(images):
'''特征提取'''
with torch.no_grad():
inputs = processor(images=images, return_tensors="pt").to(device)
outputs = model(**inputs)
image_features = outputs.last_hidden_state
image_features = image_features.mean(dim=1)
return image_features[0].cpu()
def get_knn(knn_cache_model="knn_model.joblib"):
'''直接读取上一步创建好的KNN'''
return joblib.load(knn_cache_model)
def main():
knn = get_knn()
# 用于存储所有预测和真实标签
predictions = []
true_labels = []
for cl in os.listdir(test_img_path):
label = classify[cl]
for img_name in tqdm(os.listdir(os.path.join(test_img_path, cl)), desc="Prediction:" + cl):
image = Image.open(os.path.join(test_img_path, cl, img_name))
feature = get_features(image)
prediction = knn.predict([feature])[0]
predictions.append(prediction)
true_labels.append(label)
# 计算各项指标
total = len(true_labels)
ok = sum([1 for i in range(total) if predictions[i] == true_labels[i]])
accuracy = ok / total * 100
# 计算F1分数
f1 = f1_score(true_labels, predictions)
# 额外计算精确率和召回率
precision = precision_score(true_labels, predictions)
recall = recall_score(true_labels, predictions)
# 输出结果
print("评估结果")
print("=" * 50)
print(f"总样本数 (Total): {total}")
print(f"正确数 (Correct): {ok}")
print(f"准确率 (Accuracy): {accuracy:.2f}%")
print(f"精确率 (Precision): {precision:.4f}")
print(f"召回率 (Recall): {recall:.4f}")
print(f"F1分数 (F1-Score): {f1:.4f}")
if __name__ == '__main__':
main()
运行效果如下,准确率达到 99%,实测如果提供更多样本可以达到更高的准确率:
