壹、main入口函数
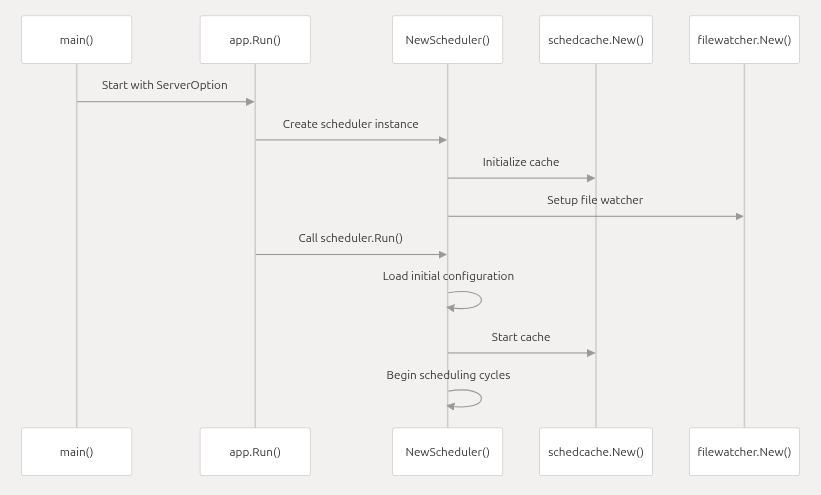
main ,负责程序启动前的核心初始化工作,包括 资源配置、参数解析、Leader 选举配置、版本打印、参数校验、日志初始化 等,最终调用
app.Run(s) 启动核心业务逻辑。
一、逐段代码逻辑拆解
**(一)1. 初始化 CPU 核心数:**runtime.GOMAXPROCS(runtime.NumCPU())
Go
runtime.GOMAXPROCS(runtime.NumCPU())- 作用:设置 Go 程序可使用的最大 CPU 核心数(GOMAXPROCS)等于当前机器的 CPU 核心数(runtime.NumCPU())。
- 原理:Go 语言的 Goroutine 调度依赖 GOMAXPROCS 控制 "同时运行的 M(系统线程)数量",默认值在 Go 1.5+ 已为 NumCPU(),此处显式设置是为了 确保程序充分利用机器 CPU 资源 ,避免因默认配置异常导致的性能瓶颈(如在容器环境中 CPU 限制未被正确识别)。
- 场景价值:Volcano 调度器需处理大量 Pod 调度请求、资源计算逻辑,充分利用 CPU 核心可提升并发处理能力,减少调度延迟。
(二)2. 日志与命令行参数初始化
Go
// 初始化 klog(Kubernetes 官方日志库)的 flags(命令行参数)
klog.InitFlags(nil)
// 创建 pflag 命令行参数集(兼容 Kubernetes 风格的参数解析)
fs := pflag.CommandLine
// 初始化 Server 配置选项(存储程序所有可配置参数,如端口、Leader 选举、证书路径等)
s := options.NewServerOption()
// 将 Server 选项的参数注册到命令行参数集(如 --port、--leader-elect 等)
s.AddFlags(fs)
// 将 Feature Gate(特性开关)的参数注册到命令行(控制组件功能的开启/关闭,如 --feature-gates=HyperNode=true)
utilfeature.DefaultMutableFeatureGate.AddFlag(fs)- 核心组件解析:
- klog:Kubernetes 生态标准日志库,支持日志级别(-v)、日志输出路径(--log-dir)等参数,此处 InitFlags(nil) 是初始化日志相关的命令行参数(如 --v=4 开启 debug 日志)。
- pflag:Go 语言的命令行参数库(比标准库 flag 支持更多特性,如短选项、参数分组),Kubernetes 生态组件统一使用 pflag 解析参数。
- options.ServerOption:程序的 "配置中心",存储所有可配置参数(如调度器端口、Leader 选举地址、证书路径、Feature Gate 等),通过 NewServerOption() 初始化默认值,再通过 AddFlags(fs) 暴露为命令行参数,支持用户启动时自定义配置。
(三)3. Leader 选举配置(高可用核心)
Go
// 为 Leader 选举设置默认值(如默认关闭 Leader 选举,或设置默认超时时间)
commonutil.LeaderElectionDefault(&s.LeaderElection)
// 设置 Leader 选举的资源名称(用于在 Kubernetes API 中标识锁资源,如 "volcano-scheduler-leader")
s.LeaderElection.ResourceName = commonutil.GenerateComponentName(s.SchedulerNames)
// 将 Leader 选举的参数(如 --leader-elect、--leader-elect-timeout)注册到命令行
componentbaseoptions.BindLeaderElectionFlags(&s.LeaderElection, fs)- Leader 选举的核心作用:Volcano 调度器作为集群级组件,需保证 "高可用"(避免单点故障) ------ 同一时间仅一个实例(Leader)处理调度请求,其他实例(Follower)处于待命状态,当 Leader 故障时,Follower 自动竞选 Leader,确保服务不中断。
- 关键参数说明:
- LeaderElection.ResourceName:在 Kubernetes API 中创建的 "锁资源" 名称(通常是 Endpoints 或 ConfigMap),用于实例间竞争 Leader 身份(通过抢占该资源实现)。
- commonutil.LeaderElectionDefault:填充 Leader 选举的默认配置(如默认 leader-elect=false,非高可用场景可关闭;默认超时时间 15 秒,避免竞争过久)。
- componentbaseoptions.BindLeaderElectionFlags:Kubernetes 组件基础库提供的工具函数,自动将 LeaderElection 结构体的字段(如 Enable、LeaseDuration、RenewDeadline)暴露为命令行参数,无需手动注册。
(四)4. 配置注册与参数初始化
Go
// 注册额外配置(如将 ServerOption 中的参数与其他模块绑定,或初始化动态配置)
s.RegisterOptions()
// 解析所有命令行参数(包括 klog、ServerOption、LeaderElection、Feature Gate 等)
cliflag.InitFlags()- s.RegisterOptions():通常用于 "配置二次处理",例如:
- 将命令行参数转换为内部模块可识别的格式(如将字符串类型的 --feature-gates 解析为 mapstringbool);
- 初始化动态配置客户端(如从 ConfigMap 加载实时配置,而非仅依赖启动参数);
- 绑定配置与其他组件(如将调度器端口配置传递给 HTTP 服务模块)。
- cliflag.InitFlags():统一解析所有注册到 pflag.CommandLine 的参数(包括用户启动时传入的自定义参数),并将值赋值到 s.ServerOption 对应的字段中(如用户传入 --port=8080,则 s.Port 会被设为 8080)。
(五)5. 版本打印与参数校验
Go
// 若用户传入 --version 参数,打印版本信息并退出
if s.PrintVersion {
version.PrintVersionAndExit()
return
}
// 校验 ServerOption 的参数合法性(如证书路径是否存在、端口是否在合法范围、Leader 选举参数是否冲突等)
if err := s.CheckOptionOrDie(); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}- 版本打印:支持用户通过 --version 查看程序版本(如 volcano-scheduler --version),version.PrintVersionAndExit() 通常会打印版本号、Git 提交哈希、编译时间等信息,便于问题排查和版本管理。
- 参数校验:CheckOptionOrDie() 是 "配置合法性守门人",避免因无效参数导致程序运行中崩溃,例如:
- 若用户配置了 --ca-cert-file 但文件不存在,直接返回错误并退出;
- 若开启 Leader 选举但未配置 Kubernetes API 访问权限(如 --kubeconfig 缺失),返回错误;
- 若端口配置为 0 或大于 65535,返回非法端口错误。
(六)6. CA 证书解析(HTTPS / 安全通信)
Go
// 若配置了 CA 证书、客户端证书、客户端密钥(通常用于 HTTPS 服务或访问 Kubernetes API 时的双向认证)
if s.CaCertFile != "" && s.CertFile != "" && s.KeyFile != "" {
// 解析 CA 证书并初始化证书池(用于验证服务端证书或客户端证书)
if err := s.ParseCAFiles(nil); err != nil {
klog.Fatalf("Failed to parse CA file: %v", err)
}
}- 核心场景:当 Volcano 调度器需要提供 HTTPS 服务(如暴露 metrics 接口供 Prometheus 采集,且要求安全通信),或访问 Kubernetes API 时启用双向 TLS 认证(而非仅用 kubeconfig 中的 token),需解析 CA 证书构建证书池,确保通信安全。
- ParseCAFiles逻辑 :通常会读取 CaCertFile 内容,添加到 Go 标准库的 x509.CertPool 中,再将证书池传递给 HTTP 客户端 / 服务端的 TLS 配置(如 tls.Config{RootCAs: certPool})。
(七)7. 日志刷新与核心业务启动
Go
// 启动日志刷新守护进程(定期将内存中的日志缓冲区写入磁盘,避免日志丢失)
klog.StartFlushDaemon(*logFlushFreq)
// 程序退出前刷新日志缓冲区(确保最后一批日志被写入)
defer klog.Flush()
// 启动核心业务逻辑(如初始化调度器、注册插件、监听 Kubernetes API 事件等)
if err := app.Run(s); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}- 日志刷新:
- klog.StartFlushDaemon(*logFlushFreq):启动一个 Goroutine,按 logFlushFreq**(默认 5 秒)定期调用****klog.Flush()**,将内存中的日志(klog 有缓冲区)写入磁盘或标准输出,避免程序崩溃时日志丢失。
- defer klog.Flush():确保程序正常退出或因错误退出前,强制刷新日志缓冲区,不遗漏关键日志。
- app.Run(s):程序的 "业务入口",负责:
二、总结这段
main 函数是 Volcano 调度器的 "启动骨架",其核心价值在于:
- 标准化初始化:遵循 Kubernetes 生态组件的启动流程,降低开发与运维成本;
- 高可用保障:集成 Leader 选举,支持生产级高可用部署;
- 灵活配置:所有核心参数可通过命令行自定义,适配不同环境;
- 安全与可观测:支持 TLS 证书解析和标准化日志,满足生产级安全与运维需求。理解该函数,可快速掌握 Volcano 调度器的启动流程,以及 Kubernetes 生态组件的通用设计模式(如 options 配置、Leader 选举、klog 日志),为后续深入分析调度核心逻辑(如 app.Run 中的调度循环)打下基础。
贰、Run 函数
Volcano 调度器的核心启动函数 Run ,负责完成调度器从 "配置解析" 到 "核心服务启动" 的全流程,包括 Kubernetes API 客户端配置、自定义插件加载、调度器实例初始化、监控 / 健康检查服务启动、Leader 选举(高可用) 等关键步骤。其逻辑紧密衔接 main 函数的初始化工作,是 Volcano 调度器 "从配置到运行" 的桥梁。
一、逐段代码逻辑拆解
(一)1. 初始化 Kubernetes API 客户端配置
Go
config, err := kube.BuildConfig(opt.KubeClientOptions)
if err != nil {
return err
}- 作用:根据 opt.KubeClientOptions(从命令行参数解析的 Kubernetes 客户端配置,如 --kubeconfig、--master 等),构建访问 Kubernetes API Server 的客户端配置(*rest.Config)。
- 核心细节:
- kube.BuildConfig 是 Volcano 封装的工具函数,兼容多种 Kubernetes 集群访问方式:
(二)2. 加载自定义调度插件
Go
if opt.PluginsDir != "" {
err := framework.LoadCustomPlugins(opt.PluginsDir)
if err != nil {
klog.Errorf("Fail to load custom plugins: %v", err)
return err
}
}- 作用:若用户通过 --plugins-dir 命令行参数指定了 "自定义插件目录",则加载该目录下的调度插件(如用户自研的 "按业务标签调度" 插件)。
- 核心细节:
- framework.LoadCustomPlugins 是 Volcano 调度框架(framework)的核心函数,负责:
i.扫描 PluginsDir 目录下的 Go 插件文件(通常是 .so 动态链接库);
ii.校验插件是否实现了 Volcano 定义的插件接口(如 FilterPlugin 过滤接口、ScorePlugin 评分接口);
iii.将插件注册到调度框架的插件管理器中,后续调度流程可调用。
若未指定 PluginsDir,则仅使用 Volcano 内置插件(如 nodeaffinity、gang、priority)。
- 场景价值:Volcano 采用插件化架构,支持用户通过自定义插件扩展调度能力(如适配特定行业的调度规则),此处是 "插件扩展" 的入口
(三)3. 初始化调度器实例
Go
sched, err := scheduler.NewScheduler(config, opt)
if err != nil {
panic(err)
}- 作用:创建 Volcano 调度器的核心实例(*scheduler.Scheduler),封装所有调度逻辑(如事件监听、任务排序、资源分配)。
- 核心细节:
- scheduler.NewScheduler 内部逻辑:
- i.基于 config 创建 Kubernetes 客户端(clientset)、缓存(cache,用于本地缓存 Node/Pod 状态,减少 API Server 访问压力);
- ii.初始化调度框架(framework),加载内置插件和自定义插件,构建 "调度插件链"(如先执行 FilterPlugin 过滤节点,再执行 ScorePlugin 评分);
- iii.初始化任务队列(如待调度 Pod 队列、重试队列),用于暂存待处理的调度任务;
- iv.注册事件处理器(如监听 Pod 的 Pending 事件、Node 的 Ready 事件,触发调度流程)。
- scheduler.NewScheduler 内部逻辑:
- 场景价值:sched 是调度器的 "大脑",后续所有调度逻辑(如 sched.Run())均围绕该实例展开。
Go
// Scheduler represents a "Volcano Scheduler".
// Scheduler watches for new unscheduled pods(PodGroup) in Volcano.
// It attempts to find nodes that can accommodate these pods and writes the binding information back to the API server.
type Scheduler struct {
cache schedcache.Cache
schedulerConf string
fileWatcher filewatcher.FileWatcher
schedulePeriod time.Duration
once sync.Once
mutex sync.Mutex
actions []framework.Action
plugins []conf.Tier
configurations []conf.Configuration
metricsConf map[string]string
dumper schedcache.Dumper
}Scheduler 结构体是 Volcano 调度器(或类似 Kubernetes 生态调度组件)的核心数据结构 ,封装了调度器运行所需的 状态缓存、配置信息、插件与动作、并发控制 等核心组件。它是调度器 "状态管理" 与 "逻辑执行" 的载体
(四)4. 启动监控(Metrics)与性能分析(PProf)服务
Go
if opt.EnableMetrics || opt.EnablePprof {
metrics.InitKubeSchedulerRelatedMetrics()
go startMetricsServer(opt)
}- 作用:若开启监控(--enable-metrics)或性能分析(--enable-pprof),则初始化监控指标并启动独立的 HTTP 服务,对外暴露指标和分析接口。
- 场景价值:监控服务是生产级部署的核心需求,用于实时观测调度器性能、排查调度延迟问题;PProf 是开发 / 运维阶段定位性能瓶颈的关键工具。
(五)5. 启动健康检查(Healthz)服务
Go
if opt.EnableHealthz {
if err := helpers.StartHealthz(opt.HealthzBindAddress, "volcano-scheduler", opt.CaCertData, opt.CertData, opt.KeyData); err != nil {
return err
}
}- 作用:若开启健康检查(--enable-healthz),则启动 Healthz 服务,对外暴露健康状态接口,供 Kubernetes 探针(Liveness/Readiness Probe)或运维工具检查调度器可用性。
(六)6. 初始化信号上下文与调度器运行逻辑
Go
// 创建信号上下文:监听系统信号(如 SIGINT、SIGTERM),用于优雅关闭
ctx := signals.SetupSignalContext()
// 定义调度器运行函数:启动调度循环,直到上下文被取消(如收到关闭信号)
run := func(ctx context.Context) {
sched.Run(ctx.Done()) // 启动调度核心循环
<-ctx.Done() // 阻塞,直到上下文被取消(如收到 SIGTERM)
}- 场景价值:信号上下文确保调度器能 "优雅关闭"(如停止新任务、完成正在处理的调度任务、清理资源),避免强制终止导致的任务丢失或数据不一致。
(七)7. Leader 选举与调度器启动(高可用核心)
Go
// 若关闭 Leader 选举(单实例部署),直接运行调度逻辑
if !opt.LeaderElection.LeaderElect {
run(ctx)
return fmt.Errorf("finished without leader elect")
}
// 若开启 Leader 选举(多实例高可用部署),初始化 Leader 选举客户端
leaderElectionClient, err := clientset.NewForConfig(restclient.AddUserAgent(config, "leader-election"))
if err != nil {
return err
}
// 初始化事件广播器:用于记录 Leader 选举相关事件(如"成为 Leader""失去 Leader")
broadcaster := record.NewBroadcaster()
broadcaster.StartRecordingToSink(&corev1.EventSinkImpl{Interface: leaderElectionClient.CoreV1().Events(opt.LeaderElection.ResourceNamespace)})
eventRecorder := broadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: commonutil.GenerateComponentName(opt.SchedulerNames)})
// 生成 Leader 选举的唯一标识(主机名+UUID,避免同一主机多实例冲突)
hostname, err := os.Hostname()
if err != nil {
return fmt.Errorf("unable to get hostname: %v", err)
}
id := hostname + "_" + string(uuid.NewUUID())
// 兼容旧版本配置:若指定 LockObjectNamespace,用其作为 Leader 选举的资源命名空间
if len(opt.LockObjectNamespace) > 0 {
opt.LeaderElection.ResourceNamespace = opt.LockObjectNamespace
}
// 创建 Leader 选举的资源锁(基于 Kubernetes Leases 资源,推荐使用,轻量且支持自动过期)
rl, err := resourcelock.New(resourcelock.LeasesResourceLock,
opt.LeaderElection.ResourceNamespace, // 锁资源所在命名空间(如 volcano-system)
opt.LeaderElection.ResourceName, // 锁资源名称(如 volcano-scheduler-leader)
leaderElectionClient.CoreV1(),
leaderElectionClient.CoordinationV1(),
resourcelock.ResourceLockConfig{
Identity: id, // 当前实例的唯一标识
EventRecorder: eventRecorder, // 事件记录器,记录选举事件
})
if err != nil {
return fmt.Errorf("couldn't create resource lock: %v", err)
}
// 启动 Leader 选举:成功竞选为 Leader 后执行 run 函数,失去 Leader 后退出
leaderelection.RunOrDie(ctx, leaderelection.LeaderElectionConfig{
Lock: rl, // 资源锁
LeaseDuration: opt.LeaderElection.LeaseDuration.Duration, // Leader 租约时长(如 15s)
RenewDeadline: opt.LeaderElection.RenewDeadline.Duration, // 租约续期截止时间(如 10s)
RetryPeriod: opt.LeaderElection.RetryPeriod.Duration, // 选举重试间隔(如 2s)
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: run, // 成为 Leader 后,执行 run 函数(启动调度循环)
OnStoppedLeading: func() { // 失去 Leader 后,打印错误并退出
klog.Fatalf("leaderelection lost")
},
},
})
// 若失去 Leader 租约,返回错误
return fmt.Errorf("lost lease")- 场景价值:Leader 选举是 Volcano 调度器 "生产级高可用部署" 的核心,确保集群中调度器服务不中断,支持实例扩容(如部署 3 个实例,1 个 Leader + 2 个 Follower)。
叁、NewScheduler 函数
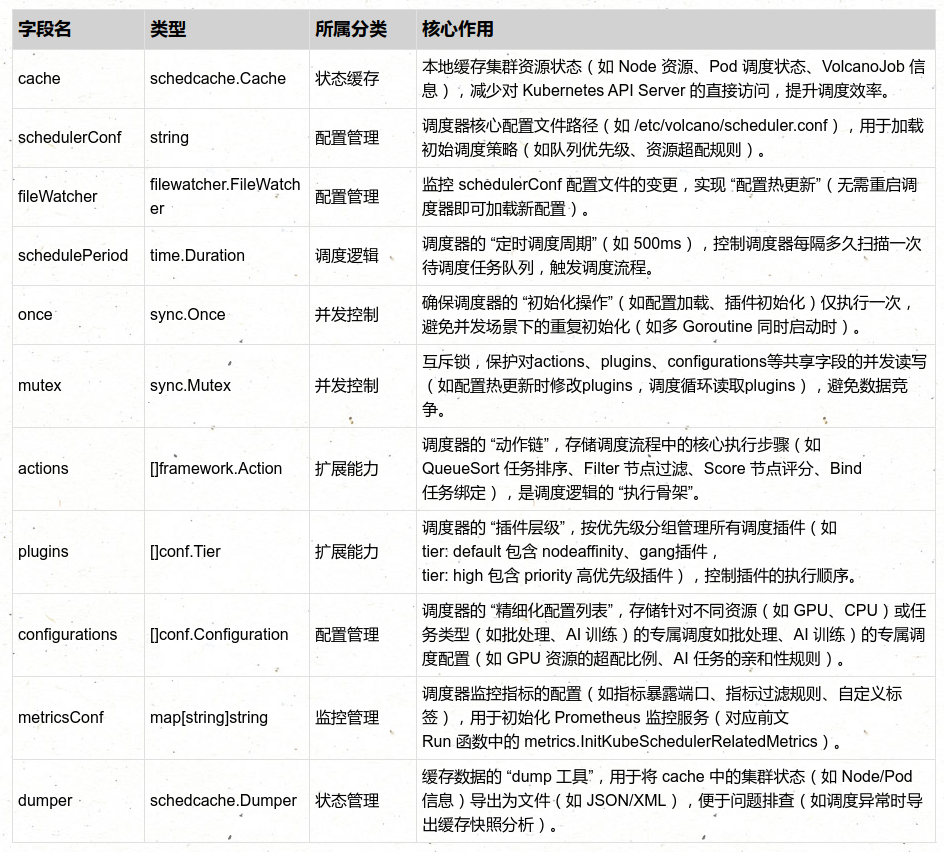
Go
type Scheduler struct {
cache schedcache.Cache
schedulerConf string
fileWatcher filewatcher.FileWatcher
schedulePeriod time.Duration
once sync.Once
mutex sync.Mutex
actions []framework.Action
plugins []conf.Tier
configurations []conf.Configuration
metricsConf map[string]string
dumper schedcache.Dumper
}Scheduler 结构体是 Volcano 调度器(或类似 Kubernetes 生态调度组件)的核心数据结构 ,封装了调度器运行所需的 状态缓存、配置信息、插件与动作、并发控制 等核心组件。它是调度器 "状态管理" 与 "逻辑执行" 的载体,所有调度相关的核心操作(如任务调度、配置更新、缓存同步)均围绕该结构体展开。以下从 字段含义、核心作用、设计逻辑、典型场景 四方面详细解析:
Scheduler 结构体的字段可分为 "状态缓存""配置管理""并发控制""扩展能力" 四大类,各字段分工明确且相互协同:
Scheduler 结构体的字段并非孤立存在,而是通过**"配置加载→缓存同步→调度执行→配置更新**" 的工作流深度协同,支撑调度器的完整运行:
Volcano 调度器核心实例 Scheduler 的构造函数 NewScheduler ,负责将 Kubernetes API 配置(rest.Config)、启动参数(options.ServerOption)转换为可运行的调度器实例,完成 文件监控初始化、本地状态缓存创建、调度器核心字段赋值 三大核心工作。它是连接 "启动配置" 与 "调度器运行" 的关键桥梁
一、逐段代码逻辑拆解
(一)1. 初始化配置文件监控(filewatcher)
Go
var watcher filewatcher.FileWatcher
if opt.SchedulerConf != "" {
var err error
// 获取调度器配置文件所在的目录(而非文件本身)
path := filepath.Dir(opt.SchedulerConf)
// 创建文件监控器,监控配置文件所在目录的变更
watcher, err = filewatcher.NewFileWatcher(path)
if err != nil {
return nil, fmt.Errorf("failed creating filewatcher for %s: %v", opt.SchedulerConf, err)
}
}- 核心作用:监控调度器配置文件(opt.SchedulerConf,如 /etc/volcano/scheduler.conf)所在目录的变更,为后续 "配置热更新" 提供基础(无需重启调度器即可加载新配置)。
- 关键细节:
a.监控目录而非文件:filepath.Dir(opt.SchedulerConf) 获取配置文件的父目录(如 opt.SchedulerConf=/etc/volcano/scheduler.conf,则 path=/etc/volcano),原因是:
-
配置文件可能通过 "替换文件" 的方式更新(如 mv scheduler.conf.new scheduler.conf),监控目录可感知文件替换;
-
若后续添加关联配置文件(如 plugin.conf),无需修改监控逻辑即可覆盖。
b.条件初始化:仅当 opt.SchedulerConf 非空时才创建 watcher(若未指定配置文件,调度器使用默认配置,无需监控)。
c.错误处理:配置文件监控是 "配置热更新" 的前提,若创建失败直接返回错误,避免调度器以 "无法更新配置" 的状态运行。
(二)2. 创建本地状态缓存(schedcache.Cache)
Go
cache := schedcache.New(config, opt.SchedulerNames, opt.DefaultQueue, opt.NodeSelector, opt.NodeWorkerThreads, opt.IgnoredCSIProvisioners, opt.ResyncPeriod)- 核心作用:创建 Volcano 调度器的 本地状态缓存 ,用于存储集群中与调度相关的核心资源(Node、Pod、VolcanoJob、Queue 等),避免每次调度都直接访问 Kubernetes API Server,提升调度效率。
- 参数含义与缓存初始化逻辑:schedcache.New 接收 7 个参数,均来自 config(API 配置)或 opt(启动参数),用于定制缓存的行为:

- 缓存的核心价值:
a.降低 API 压力:调度器每秒可能触发多次调度,本地缓存避免大量重复的 API 请求;
b.提升调度效率:从内存读取资源状态比从 API Server 读取快 1~2 个数量级;
c.状态一致性:通过 ResyncPeriod 定期同步,确保缓存状态与 API Server 近似实时一致。
(三)3. 初始化调度器实例(Scheduler)
Go
scheduler := &Scheduler{
schedulerConf: opt.SchedulerConf, // 调度器配置文件路径
fileWatcher: watcher, // 配置文件监控器
cache: cache, // 本地状态缓存
schedulePeriod: opt.SchedulePeriod, // 调度周期(如 500ms)
dumper: schedcache.Dumper{Cache: cache, RootDir: opt.CacheDumpFileDir}, // 缓存快照导出工具
}- 核心作用:将前面初始化的 watcher、cache 与 opt 中的关键参数(配置路径、调度周期、缓存快照目录)组装为 Scheduler 实例,完成调度器的 "数据初始化"。
- 字段赋值细节:
a.schedulerConf:记录配置文件路径,后续若需重新加载配置(如热更新),可直接使用该路径;
b.fileWatcher:绑定配置监控器,后续调度器运行中可通过 watcher 感知配置变更;
c.cache:绑定本地状态缓存,调度器的所有资源操作(如筛选 Node、检查 Pod 状态)均基于该缓存;
d.schedulePeriod:设置调度周期(如 500ms),控制调度器 "每隔多久扫描一次待调度任务",是调度频率的核心参数;
e.dumper:初始化缓存快照导出工具(schedcache.Dumper),绑定 cache 和快照存储目录(opt.CacheDumpFileDir,如 /var/log/volcano/cache),用于调度异常时导出缓存状态,辅助问题排查
叁.1、newSchedulerCache 函数
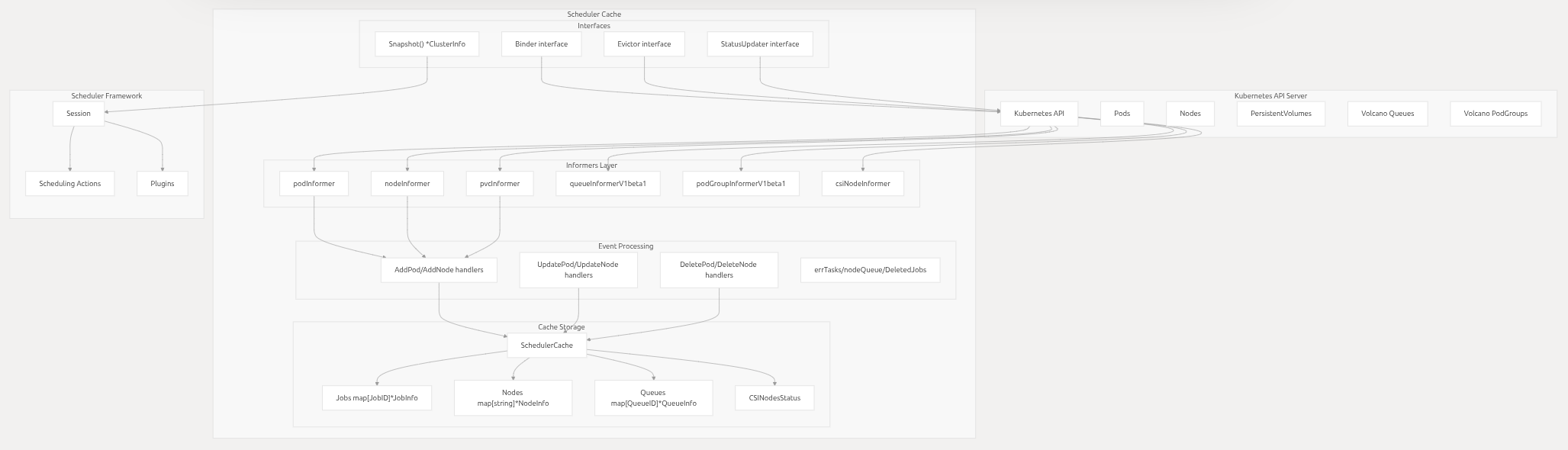
Volcano 调度器本地状态缓存( SchedulerCache )的核心构造函数 newSchedulerCache ,负责初始化调度器运行所需的 Kubernetes 客户端、核心数据结构、事件处理器、资源管理组件 等,是调度器 "本地状态管理" 的基石。
SchedulerCache 作为调度器的 "数据中枢",存储了集群中与调度相关的所有关键资源(Job、Node、Queue、Pod等),所有调度逻辑(如节点筛选、资源计算)均基于此缓存展开。
一、逐段代码逻辑拆解
(一)1. 初始化 Kubernetes 客户端(核心依赖)
Go
// 初始化 Kubernetes 核心客户端(用于操作 Pod、Node 等原生资源)
kubeClient, err := kubernetes.NewForConfig(config)
if err != nil {
panic(fmt.Sprintf("failed init kubeClient, with err: %v", err))
}
// 初始化 Volcano 自定义资源客户端(用于操作 VolcanoJob、Queue 等 CRD 资源)
vcClient, err := vcclient.NewForConfig(config)
if err != nil {
panic(fmt.Sprintf("failed init vcClient, with err: %v", err))
}
// 初始化事件客户端(用于记录调度相关事件,如"Pod 调度失败""Queue 资源不足")
eventClient, err := kubernetes.NewForConfig(config)
if err != nil {
panic(fmt.Sprintf("failed init eventClient, with err: %v", err))
}- 核心作用:创建三类客户端,分别负责操作不同资源,是缓存与 Kubernetes API Server 交互的 "桥梁":
a.kubeClient:操作 Kubernetes 原生资源(Pod、Node、PriorityClass、CSINode 等),用于同步集群基础资源状态;
b.vcClient:操作 Volcano 自定义资源(VolcanoJob、Queue、PodGroup 等 CRD),是 Volcano 调度器特有的资源客户端;
c.eventClient:专门用于记录调度事件(如通过 sc.Recorder.Event(...) 输出事件到 Kubernetes Events),便于运维排查问题
- 错误处理:客户端初始化是缓存运行的前提,若失败直接 panic 终止程序(无法与 API Server 交互的缓存无意义),符合 Go 语言 "启动阶段致命错误快速失败" 的设计理念。
(二)2. 创建默认队列与根队列
Go
klog.Infof("Creating default queue and root queue")
newDefaultAndRootQueue(vcClient, defaultQueue)- 核心作用:初始化 Volcano 调度器的 "队列基础结构"------ 确保集群中存在 default 队列(用户未指定队列时的默认队列)和 root 队列(队列层级的根节点,用于统一管理所有子队列)。
- 关键细节:
- newDefaultAndRootQueue 内部逻辑:
i.检查集群中是否存在 root 队列,若不存在则通过 vcClient 创建(root 队列是所有队列的父节点,用于资源配额的顶层管理);
ii.检查集群中是否存在 defaultQueue(如 default),若不存在则创建,并将其作为 root 队列的子队列;
iii.为默认队列设置默认资源配额(如 CPU / 内存的默认上限),避免用户未配置队列时调度失败
- 场景价值:Volcano 基于 "队列" 进行资源管理,所有任务(VolcanoJob/Pod)必须属于某个队列,初始化默认队列可降低用户使用门槛(无需手动创建队列即可提交任务)。
(三)3. 初始化错误任务速率限制器
Go
errTaskRateLimiter := workqueue.NewTypedMaxOfRateLimiter[string](
// 指数退避速率限制:失败次数越多,重试间隔越长(初始 5ms,最大 1000s)
workqueue.NewTypedItemExponentialFailureRateLimiter[string](5*time.Millisecond, 1000*time.Second),
// 令牌桶速率限制:每秒最多处理 100 个任务,令牌桶容量 1000(应对突发任务)
&workqueue.TypedBucketRateLimiter[string]{Limiter: rate.NewLimiter(rate.Limit(100), 1000)},
)- 核心作用:创建 "错误任务速率限制器",用于控制 errTasks 队列(存储调度失败的任务)的重试频率,避免 "失败任务频繁重试" 导致的资源浪费或 API 压力。
- 速率限制逻辑:
- NewTypedMaxOfRateLimiter 表示 "取两种限制策略中的较严格者":
i.指数退避:同一任务失败次数越多,重试间隔越长(如第 1 次失败后 5ms 重试,第 2 次 10ms,第 3 次 20ms... 最大 1000s),避免死循环重试;
ii.令牌桶:全局每秒最多处理 100 个错误任务,避免突发大量错误任务占用过多 CPU/API 资源。
- 设计价值:Volcano 调度器作为集群级组件,需考虑 "容错与稳定性",速率限制器是防止 "错误任务雪崩" 的关键机制。
(四)4. 初始化SchedulerCache核心数据结构
Go
sc := &SchedulerCache{
// -------------------------- 核心资源存储(Map 结构,便于快速查询) --------------------------
Jobs: make(map[schedulingapi.JobID]*schedulingapi.JobInfo), // 存储所有 VolcanoJob 信息(Key:Job ID)
Nodes: make(map[string]*schedulingapi.NodeInfo), // 存储所有 Node 信息(Key:Node 名称)
Queues: make(map[schedulingapi.QueueID]*schedulingapi.QueueInfo), // 存储所有 Queue 信息(Key:Queue ID)
PriorityClasses: make(map[string]*schedulingv1.PriorityClass), // 存储所有 PriorityClass(Key:优先级名称)
NamespaceCollection: make(map[string]*schedulingapi.NamespaceCollection), // 存储命名空间级资源统计(Key:命名空间)
CSINodesStatus: make(map[string]*schedulingapi.CSINodeStatusInfo), // 存储 CSI 节点状态(Key:Node 名称)
imageStates: make(map[string]*imageState), // 存储节点镜像拉取状态(Key:Node+镜像名)
// -------------------------- 任务队列(用于异步处理资源变更) --------------------------
errTasks: workqueue.NewTypedRateLimitingQueue[string](errTaskRateLimiter), // 调度失败的任务队列(带速率限制)
nodeQueue: workqueue.NewTypedRateLimitingQueue[string](workqueue.DefaultTypedControllerRateLimiter[string]()), // Node 变更队列
DeletedJobs: workqueue.NewTypedRateLimitingQueue[*schedulingapi.JobInfo](workqueue.DefaultTypedControllerRateLimiter[*schedulingapi.JobInfo]()), // 已删除 Job 清理队列
hyperNodesQueue: workqueue.NewTypedRateLimitingQueue[string](workqueue.DefaultTypedControllerRateLimiter[string]()), // HyperNode 变更队列
// -------------------------- 客户端与基础配置 --------------------------
kubeClient: kubeClient, // Kubernetes 核心客户端
vcClient: vcClient, // Volcano CRD 客户端
restConfig: config, // API 客户端基础配置
defaultQueue: defaultQueue, // 默认队列名称
schedulerNames: schedulerNames, // 调度器名称列表(仅处理这些调度器的 Pod)
nodeSelectorLabels: make(map[string]sets.Empty), // 节点选择器(仅同步符合条件的 Node)
// -------------------------- 其他状态与配置 --------------------------
NodeList: []string{}, // Node 名称列表(用于遍历 Node)
nodeWorkers: nodeWorkers, // 处理 Node 变更的并发线程数
IgnoredCSIProvisioners: ignoredProvisionersSet, // 忽略的 CSI 存储供应者
}- 核心作用:初始化 SchedulerCache 的所有字段,构建缓存的 "数据骨架",涵盖 资源存储、异步任务队列、客户端依赖、基础配置 四大类,是后续缓存同步与调度逻辑的基础。
- 关键数据结构解析:
a.资源存储(Map):
- 所有资源均用 map 存储,Key 为唯一标识(如 Node 名称、Job ID),确保 O (1) 时间复杂度的查询效率(调度时需快速获取 Node/Job 状态);
- 存储的是 "加工后的信息"(如 schedulingapi.NodeInfo 包含 Node 的资源使用情况、已调度 Pod 列表,而非原生 v1.Node 结构体),便于调度逻辑直接使用。
b.异步任务队列(workqueue): - 使用 Kubernetes 客户端库的 workqueue(带速率限制的队列),而非原生 chan,支持 "重试、速率限制、延迟处理" 等生产级特性;
- 不同队列处理不同类型的异步任务(如 nodeQueue 处理 Node 状态变更,errTasks 处理调度失败重试),实现任务解耦
(五)5. 补充缓存配置与核心组件
Go
// 1. 设置缓存同步周期(如 30s)
sc.resyncPeriod = resyncPeriod
// 2. 获取调度器 Pod 名称与关闭信号(用于感知自身部署状态)
sc.schedulerPodName, sc.c = getMultiSchedulerInfo()
// 3. 初始化忽略的 CSI 存储供应者集合(避免处理无关存储资源)
ignoredProvisionersSet := sets.New[string]()
for _, provisioner := range append(ignoredProvisioners, defaultIgnoredProvisioners...) {
ignoredProvisionersSet.Insert(provisioner)
}
sc.IgnoredCSIProvisioners = ignoredProvisionersSet
// 4. 更新节点选择器(仅同步符合标签的 Node)
if len(nodeSelectors) > 0 {
sc.updateNodeSelectors(nodeSelectors)
}
// 5. 初始化事件记录器(用于记录调度事件到 Kubernetes Events)
broadcaster := record.NewBroadcaster()
broadcaster.StartRecordingToSink(&corev1.EventSinkImpl{Interface: eventClient.CoreV1().Events("")})
sc.Recorder = broadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: commonutil.GenerateComponentName(sc.schedulerNames)})
// 6. 设置批量绑定的并发配置(控制同时绑定 Pod 的数量)
sc.setBatchBindParallel()
// 7. 初始化 Pod 绑定器(默认使用 Kubernetes 原生绑定逻辑)
if bindMethodMap == nil {
klog.V(3).Info("no registered bind method, new a default one")
bindMethodMap = NewDefaultBinder(sc.kubeClient, sc.Recorder)
}
sc.Binder = GetBindMethod()
// 8. 初始化 Pod 驱逐器(用于抢占时驱逐低优先级 Pod)
sc.Evictor = &defaultEvictor{
kubeclient: sc.kubeClient,
recorder: sc.Recorder,
}
// 9. 初始化 PodGroup 绑定器(用于绑定 PodGroup 与 Node 亲和性)
sc.PodGroupBinder = &podgroupBinder{
kubeclient: sc.kubeClient,
vcclient: sc.vcClient,
}
// 10. 初始化绑定器注册表(支持扩展自定义绑定逻辑)
sc.binderRegistry = NewBinderRegistry()- 核心作用:补充缓存的 "功能组件",为后续 "缓存同步、调度执行、资源操作" 提供支撑,涵盖 事件记录、Pod 绑定、Pod 驱逐、配置定制 等关键能力。
- 关键组件解析:
- sc.Recorder:事件记录器,调度过程中会记录关键事件(如 "Pod xxx 调度到 Node xxx""Job xxx 因资源不足等待"),可通过 kubectl describe pod 查看;
- sc.Binder:Pod 绑定器,负责将调度结果(Pod 与 Node 的映射)写入 API Server(即 Pod.Spec.NodeName 赋值),是调度流程的 "最后一步";
- sc.Evictor:Pod驱逐器,高优先级任务抢占资源时,用于驱逐低优先级 Pod(如删除低优先级 Pod 释放 GPU 资源);
- sc.setBatchBindParallel():设置批量绑定的并发数(如同时绑定 10 个 Pod),控制绑定操作的速率,避免 API Server 压力过大。
(六)6. 注册事件处理器与初始化 HyperNode 信息
Go
// 1. 注册资源事件处理器(监听 API Server 资源变更,同步到缓存)
sc.addEventHandler()
// 2. 初始化 HyperNode 信息(用于描述多层网络拓扑,如 AI 训练的节点组)
sc.HyperNodesInfo = schedulingapi.NewHyperNodesInfo(sc.nodeInformer.Lister())
return sc- 核心作用:完成缓存的 "最终初始化",启动资源同步机制并初始化特殊资源(HyperNode),使缓存具备 "实时同步 API 状态" 的能力。
- 关键逻辑解析:
- sc.addEventHandler():注册事件处理器,内部会:
i.为 Pod、Node、VolcanoJob、Queue 等资源创建 Informer(Kubernetes 客户端库的增量同步组件);
ii.为 Informer 注册事件回调(如 OnAdd/OnUpdate/OnDelete),当 API Server 资源变更时,自动更新缓存中的 Jobs/Nodes/Queues 等 map;
iii.启动 Informer 的同步循环,确保缓存与 API Server 状态实时同步。
- sc.HyperNodesInfo:HyperNode 是 Volcano 用于描述 "多层网络拓扑" 的概念(如 GPU 集群中的 "机架 - 节点" 层级),此处初始化其信息结构,为 AI 训练等需要拓扑感知的调度场景提供支持。
肆、Scheduler Run 函数
Volcano 调度器核心实例 Scheduler 的 Run 方法 ,负责完成调度器从 "初始化后" 到 "持续运行" 的关键过渡,涵盖 配置加载与热更新、缓存启动、调度循环触发、缓存快照监控、调度器 Socket 服务启动 五大核心工作。它是调度器 "真正开始工作" 的入口,直接决定了调度器的运行模式与核心能力。
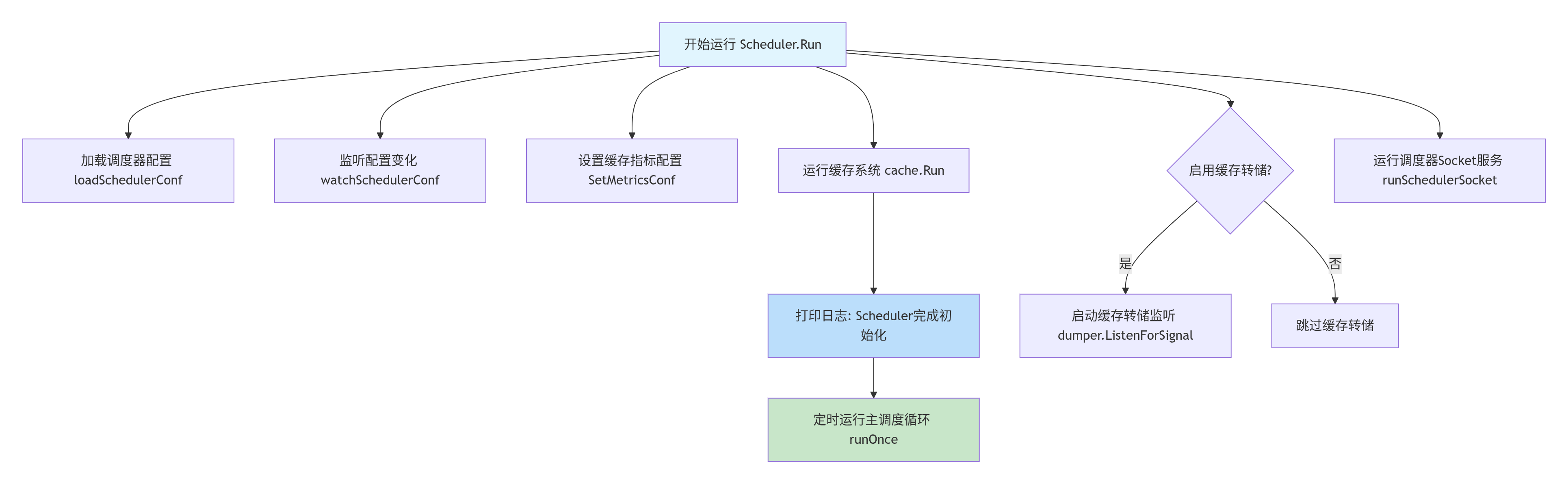
一、逐段代码逻辑拆解
(一)1. 加载调度器配置 + 启动配置热更新
Go
// 加载初始调度器配置(如插件、动作链、资源规则)
pc.loadSchedulerConf()
// 启动 goroutine 监控配置文件变更,实现"配置热更新"(不阻塞主流程)
go pc.watchSchedulerConf(stopCh)- 核心作用:完成调度器的 "配置初始化" 与 "动态更新能力部署",确保调度规则可灵活调整(无需重启调度器)。
- 关键细节:
a.pc.loadSchedulerConf():
- 从 pc.schedulerConf(配置文件路径,如 /etc/volcano/scheduler.conf)加载配置;
- 解析配置内容,初始化或更新 pc.plugins(插件层级)、pc.actions(调度动作链)、pc.configurations(精细化资源配置)、pc.metricsConf(监控配置)等核心字段;
- 若配置加载失败(如格式错误、插件不存在),通常会打印错误日志并使用默认配置(或终止启动,取决于容错设计)。
b.go pc.watchSchedulerConf(stopCh): - 基于 pc.fileWatcher(在 NewScheduler 中初始化的配置文件监控器),监听配置文件所在目录的变更;
- 当配置文件被修改 / 替换时,自动触发 loadSchedulerConf() 重新加载配置,实现 "热更新";
- 通过 stopCh 监听关闭信号(如 SIGTERM),收到信号后停止监控,确保优雅关闭;
- 使用 go 关键字启动独立 goroutine,避免监控逻辑阻塞后续的缓存启动与调度循环。
默认配置文件: /volcano.scheduler/volcano-scheduler.conf
Go
actions: "enqueue, allocate, backfill"
tiers:
plugins:
name: priority
name: gang
name: conformance
plugins:
name: overcommit
name: drf
name: predicates
name: proportion
name: nodeorder
name: binpack(二)2. 配置缓存监控参数 + 启动缓存
Go
// 将加载的监控配置(metricsConf)传递给本地缓存(cache)
pc.cache.SetMetricsConf(pc.metricsConf)
// 启动缓存的运行循环(同步 API Server 资源、维护本地状态)
pc.cache.Run(stopCh)- 核心作用:初始化缓存的监控能力,并启动缓存的核心同步逻辑,使缓存成为 "实时同步集群状态" 的数据中枢。
- 关键细节:
a.pc.cache.SetMetricsConf(pc.metricsConf):
- 将调度器的监控配置(如指标暴露端口、自定义标签、过滤规则)传递给 schedcache.Cache;
- 缓存后续会基于这些配置,初始化与自身相关的监控指标(如 volcano_cache_sync_duration_seconds 缓存同步耗时、volcano_cache_node_count 缓存中的 Node 数量),与调度器的整体监控体系联动。
b.pc.cache.Run(stopCh): 第伍章节讲解 - 启动缓存的核心运行循环,内部逻辑包括:
- 启动所有资源(Pod、Node、VolcanoJob、Queue 等)的 Informer 同步循环,增量拉取 API Server 资源变更,更新本地 Jobs/Nodes/Queues 等 map 结构;
- 启动缓存的错误任务处理循环(如 errTasks 队列的重试逻辑);
- 启动缓存监控指标的采集与暴露(如定期统计缓存中资源数量并更新指标);
- 通过 stopCh 接收关闭信号,收到信号后会:停止 Informer 同步、完成当前正在处理的缓存更新、清理资源(如关闭 goroutine),确保缓存优雅关闭;
- 注意:pc.cache.Run(stopCh) 是 阻塞调用(直到 stopCh 被关闭),但由于后续的调度循环(runOnce)和 Socket 服务均通过 go 启动,因此不会阻塞整体流程
(三)3. 启动调度循环
Go
// 启动"定时调度循环":每隔 pc.schedulePeriod 执行一次 pc.runOnce(调度核心逻辑)
go wait.Until(pc.runOnce, pc.schedulePeriod, stopCh)- 核心作用:标志调度器进入 "正常运行阶段",并启动核心的定时调度逻辑,开始处理集群中的待调度任务。
- 关键细节:
a.go wait.Until(pc.runOnce, pc.schedulePeriod, stopCh)
-
wait.Until:Kubernetes 客户端库提供的工具函数,功能是 "每隔 pc.schedulePeriod 时间,重复执行 pc.runOnce 函数,直到 stopCh 被关闭";
-
pc.runOnce:调度器的 "单次调度逻辑"(核心函数),内部会:从缓存中获取待调度任务、执行调度动作链(QueueSort→Filter→Score→Bind)、完成 Pod 与 Node 的绑定;
-
go 关键字:启动独立 goroutine 运行调度循环,避免阻塞后续的缓存快照监控与 Socket 服务
(四)4. (可选)启动缓存快照监控
Go
// 若启用了缓存快照功能(--enable-cache-dumper),则启动快照信号监听
if options.ServerOpts.EnableCacheDumper {
pc.dumper.ListenForSignal(stopCh)
}作用:为调度异常场景提供 "缓存快照导出" 能力,便于事后排查问题(如调度失败时,导出缓存中的 Node/Pod 状态分析原因)。
(五)5. 启动调度器 Socket 服务
Go
// 启动调度器的 Socket 服务(用于接收外部请求,如手动触发调度、查询调度状态)
go runSchedulerSocket()- 核心作用:提供 "外部与调度器交互" 的接口,支持手动干预调度流程或查询调度器内部状态(如运维工具调用)。
- 关键细节:
a.runSchedulerSocket():
- 内部逻辑:启动一个 Unix Domain Socket 或 TCP Socket 服务(通常绑定到本地路径,如 /var/run/volcano/scheduler.sock,或特定端口);
- 支持的请求类型(示例):
- 手动触发一次调度(无需等待 schedulePeriod);
- 查询当前待调度任务队列长度;
- 查询某 Node 的调度统计信息(如已调度 Pod 数量);
- 动态启用 / 禁用某调度插件;
- 通常会实现简单的请求认证(如基于 Unix Socket 的文件权限控制,仅 root 用户可访问),避免未授权操作;
b.go 关键字:启动独立 goroutine 运行 Socket 服务,避免阻塞其他逻辑;
c.场景价值:为运维提供 "精细化控制调度器" 的能力,如: - 紧急任务需要立即调度时,通过 Socket 发送请求手动触发调度;
- 监控系统通过 Socket 查询调度器状态,实现更细粒度的健康检查
二、核心组件协同:调度器运行的完整流程
Run 方法中的各步骤并非孤立,而是形成 "配置加载→缓存启动→调度循环→外部交互 " 的闭环,支撑调度器的持续运行,各组件协同关系如下:
- 配置与缓存协同:loadSchedulerConf() 加载的插件 / 资源规则,会被后续 pc.runOnce(调度循环)使用;而 pc.cache.Run() 启动的缓存,为 pc.runOnce 提供实时的 Node/Pod/Job 状态数据;
- 调度循环与缓存协同:pc.runOnce 每次执行时,均从 pc.cache 读取待调度任务和资源状态,执行调度逻辑后,再通过缓存的 Binder(Pod 绑定器)将调度结果写入 API Server;
- 热更新与调度循环协同:watchSchedulerConf 监控到配置变更后,重新加载的插件 / 规则会直接被下一次 pc.runOnce 使用(无需重启调度循环),实现 "动态调整调度策略";
- 快照与缓存协同:pc.dumper 绑定 pc.cache,收到信号后直接从缓存读取状态导出快照,确保快照数据与调度器当前使用的状态一致。
三、总结
Scheduler.Run 方法是 Volcano 调度器的 "运行中枢",其核心价值在于:
- 流程编排:按 "配置→缓存→调度→交互" 的顺序启动各模块,确保依赖正确(如缓存启动后才执行调度循环);
- 并发管理:通过 Goroutine 实现多模块并行,提升调度器整体吞吐量;
- 生命周期控制:基于 stopCh 实现优雅关闭,保障数据一致性;
- 可扩展性:通过配置参数和独立模块(如 Socket 服务、快照),支持灵活扩展调度器能力。理解该方法,可完整掌握 Volcano 调度器的 "运行时架构",为后续深入分析调度核心逻辑(pc.runOnce)和问题排查提供基础。
伍、SchedulerCache Run函数
SchedulerCache.Run 是 Volcano 调度器本地缓存的核心运行入口 ,负责启动缓存的 "资源同步、任务处理、监控采集" 三大核心能力,通过多协程并行实现 "实时同步集群状态 + 高效处理调度依赖任务"。其代码流程可拆解为 "Informer 启动→缓存同步→多协程任务初始化→监控采集启动→优雅关闭" 五大阶段
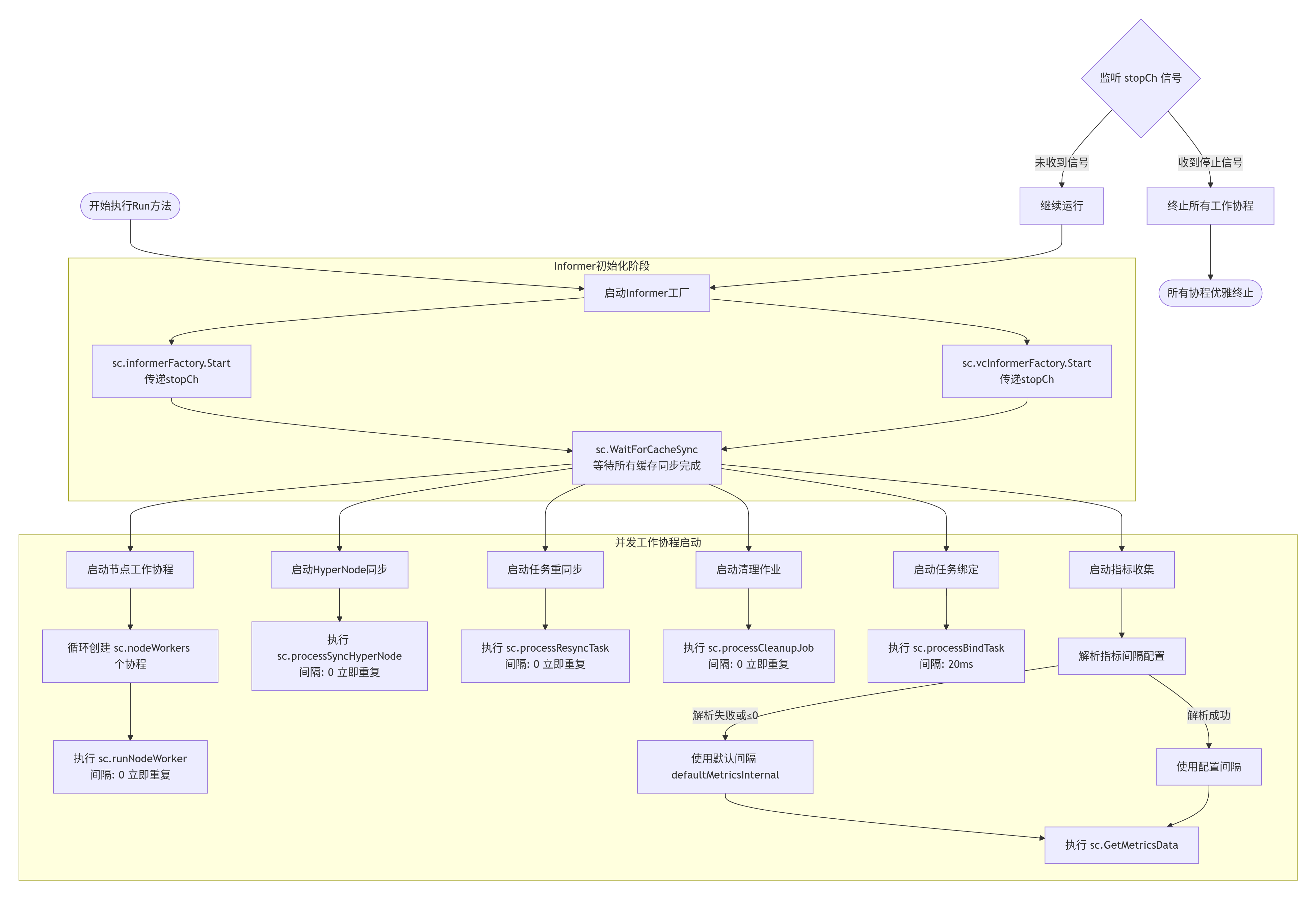
一、整体流程概览
Run 方法的核心目标是:让缓存从 "初始化状态" 进入 "持续运行状态" ,具体通过以下逻辑实现:
- 启动资源监听组件(Informer),从 Kubernetes API Server 增量同步资源;
- 等待所有资源缓存同步就绪,避免后续任务基于 "脏数据" 执行;
- 启动多组协程池,分别处理 Node 变更、HyperNode 同步、错误重试、Job 清理、Pod 绑定等核心任务;
- 初始化并启动监控采集,暴露缓存运行指标(如 Node 数量、任务队列长度);
- 通过 stopCh 监听关闭信号,确保所有组件优雅退出,无资源泄漏。
二、分阶段代码流程解析
阶段 1:启动 Informer 工厂(资源同步入口)
Go
sc.informerFactory.Start(stopCh)
sc.vcInformerFactory.Start(stopCh)核心作用
启动两类 Informer 工厂,负责从 Kubernetes API Server 增量同步资源变更 ,是缓存获取集群状态的 "数据源入口"。
关键细节
- sc.informerFactory:管理 Kubernetes 原生资源的 Informer(如 PodInformer、NodeInformer、PriorityClassInformer):
- Informer 启动后,会在后台启动 "列表 - 监听(List-Watch)" 循环:先全量拉取一次资源(如所有 Node),再监听后续增量变更(如 Node 状态从 Ready 变为 NotReady);
- 变更事件会触发预注册的回调函数(如 OnAdd/OnUpdate/OnDelete),自动更新缓存中的 sc.Nodes、sc.PriorityClasses 等映射。
- sc.vcInformerFactory:管理 Volcano 自定义资源(CRD)的 Informer(如 JobInformer、QueueInformer、PodGroupInformer):
- 逻辑与原生资源 Informer 一致,同步 Volcano 特有的调度相关资源,更新缓存中的 sc.Jobs、sc.Queues 等映射;
- 这是 Volcano 调度器区别于 Kubernetes 原生调度器的核心:需感知自定义的 "队列""作业" 资源,实现基于队列的资源调度。
- stopCh关联 :Informer 会监听 stopCh,当外部发送关闭信号(如 SIGTERM)时,自动停止 List-Watch 循环,避免 API 连接泄漏。
阶段 2:等待缓存同步就绪(数据一致性保障)
Go
sc.WaitForCacheSync(stopCh)核心作用
阻塞等待所有 Informer 的缓存同步完成,确保后续任务(如 Node 处理、Pod 绑定)启动时,缓存已包含 "最新且完整的集群资源状态",避免 "基于空数据或旧数据执行任务"。
关键细节
- 同步逻辑:WaitForCacheSync 会检查所有已启动的 Informer(原生 + CRD)的缓存状态,仅当所有 Informer 均完成 "首次全量同步" 后,才会解除阻塞;
- 失败处理:若同步过程中 stopCh 被激活(如关闭信号),或某类资源同步超时 / 失败,会直接返回并终止后续流程,避免缓存以 "不完整状态" 运行;
- 典型场景:若集群中有 100 个 Node,WaitForCacheSync 会等待 NodeInformer 全量拉取完 100 个 Node 的信息并写入 sc.Nodes 后,才继续执行下一步。
阶段 3:启动多协程任务池(缓存核心处理能力)此阶段通过
go wait.Until(...) 启动 6 组协程(含协程池),分别处理不同类型的任务,实现 "并行化任务处理",提升缓存响应效率。
3.1 Node 变更处理协程池(runNodeWorker)
Go
for i := 0; i < int(sc.nodeWorkers); i++ {
go wait.Until(sc.runNodeWorker, 0, stopCh)
}- 核心职责:处理 sc.nodeQueue(Node 变更任务队列)中的任务,更新Node 在缓存中的状态(如资源使用量、标签、亲和性规则)。
- 关键参数:
- sc.nodeWorkers:协程数量(如 4),通过启动参数 --node-worker-threads 配置,控制 Node 变更处理的并发度;
- 0 间隔:wait.Until 的第二个参数为 0,表示 "任务处理完后立即检查新任务"(无间隔轮询),确保 Node 变更快速响应。
- 内部逻辑:sc.runNodeWorker 会循环从 sc.nodeQueue 中弹出任务(如 "Node-1 资源更新"),执行以下操作:
3.2 HyperNode 同步协程(processSyncHyperNode)
Go
go wait.Until(sc.processSyncHyperNode, 0, stopCh)- 核心职责:维护 "超节点(HyperNode)" 的拓扑数据,同步 sc.HyperNodesInfo(超节点与物理节点的映射关系),支撑 Volcano 的 "拓扑感知调度"(如 AI 训练任务调度到同一机架的 Node)。
- 关键逻辑:
a.从 sc.hyperNodesQueue 中获取 HyperNode 变更任务(如 "HyperNode-rack1 新增 Node-2");
b.更新 sc.HyperNodesInfo 中的 hyperNodes(超节点详情)、realNodesSet(物理节点所属超节点)等映射;
c.若 HyperNode 资源不足(如总 GPU 数量低于阈值),标记该超节点为 "不可调度"。
3.3 错误任务重同步协程(processResyncTask)
Go
go wait.Until(sc.processResyncTask, 0, stopCh)- 核心职责:处理 sc.errTasks(调度失败任务队列)中的任务,重试同步任务状态,避免因临时异常(如 API 超时)导致任务永久失败。
- 典型场景:
- 若某 Pod 调度时因 "Node 资源查询超时" 失败,会被加入 sc.errTasks;
- processResyncTask 会取出该任务,重新查询 Node 资源状态,若资源充足则重新触发调度,若仍失败则按速率限制器(errTaskRateLimiter)延迟重试。
3.4 已删除 Job 清理协程(processCleanupJob)
Go
go wait.Until(sc.processCleanupJob, 0, stopCh)- 核心职责:处理 sc.DeletedJobs(已删除 Job 队列)中的任务,清理缓存中 Job 关联的无效数据,避免内存泄漏。
- 清理逻辑:
a.从 sc.DeletedJobs 中获取已删除的 JobInfo;
b.删除 sc.JobsjobID 映射,释放 Job 占用的内存;
c.清理该 Job 关联的 Pod 记录(如从 sc.NodesnodeName.Pods 中移除该 Job 的 Pod);
d.释放该 Job 占用的队列资源配额(如 sc.QueuesqueueID.Allocated 减去该 Job 的资源)。
3.5 Pod 绑定任务处理协程(processBindTask)
Go
go wait.Until(sc.processBindTask, time.Millisecond*20, stopCh)- 核心职责:处理待绑定的 Pod 任务(如调度成功后未完成绑定的 Pod,或绑定失败需重试的 Pod),调用 sc.Binder 完成 Pod 与 Node 的绑定。
- 关键细节:
- 20ms 间隔:绑定操作需调用 Kubernetes API(PATCH /api/v1/pods/ 更新 spec.nodeName),20ms 间隔可控制 API 调用频率,避免短时间大量绑定请求压垮 API Server;
- 重试逻辑:若绑定失败(如 Node 临时不可用),会将 Pod 重新加入绑定队列,等待下一轮重试,确保绑定成功率。
阶段 4:启动监控数据采集(运维观测能力)
Go
klog.V(3).Infof("Start metrics collection, metricsConf is %v", sc.metricsConf)
interval, err := time.ParseDuration(sc.metricsConf["interval"])
if err != nil || interval <= 0 {
interval = defaultMetricsInternal
}
klog.V(3).Infof("The interval for querying metrics data is %v", interval)
go wait.Until(sc.GetMetricsData, interval, stopCh)核心作用
初始化并启动缓存的监控采集任务,暴露缓存运行的关键指标(如 Node 数量、Job 状态、队列长度),支撑运维人员观测缓存健康状态。
关键细节
- 监控间隔配置:
- 从 sc.metricsConf"interval"(来自调度器启动参数 --metrics-conf)解析采集间隔(如 30s);
- 若解析失败(如格式错误)或间隔≤0,使用默认值 defaultMetricsInternal(通常为 30s)。
- 指标采集逻辑:sc.GetMetricsData 会周期性采集以下指标:
- 指标暴露:采集的指标会通过 Prometheus 暴露接口(如 :8080/metrics)对外提供,运维人员可通过 Grafana 配置仪表盘,实时监控缓存运行状态。
阶段 5:优雅关闭(资源泄漏防护)所有组件(Informer、协程)均监听
stopCh,当外部发送关闭信号(如 Kubernetes 执行 kubectl delete pod volcano-scheduler)时,触发以下优雅关闭流程:
- Informer 停止:sc.informerFactory 和 sc.vcInformerFactory 停止 List-Watch 循环,关闭与 API Server 的连接;
- 协程终止:所有 wait.Until 循环检测到 stopCh 激活,停止下一轮任务执行,当前任务执行完后退出协程;
- 资源清理:释放缓存中的映射资源(如 sc.Nodes、sc.Jobs),关闭监控暴露接口;
- 函数退出:所有组件清理完成后,Run 方法执行完毕,缓存服务正常退出。
三、总结
SchedulerCache.Run 是 Volcano 缓存服务的 "启动中枢",其流程设计围绕 "实时同步、高效处理、稳定观测、安全退出 " 四大目标:
- 从 "数据源"(Informer)到 "数据处理"(多协程任务),再到 "数据观测"(监控采集),形成完整的缓存运行闭环;
- 每个阶段的设计均服务于 "调度器高效稳定运行"------ 缓存同步保障数据准确性,并行任务提升响应速度,监控采集支撑运维排查,优雅关闭避免资源泄漏。理解该流程,可深入掌握 Volcano 调度器 "如何通过缓存感知集群状态",为后续分析调度核心逻辑(如 runOnce)打下基础。
陆、runOnce 函数
runOnce 是 Volcano 调度器的 单次调度核心函数 ,负责执行 "从加载配置→创建调度会话→执行调度动作链" 的完整调度周期,被 wait.Until 周期性调用(周期由 schedulePeriod 配置)。其核心目标是:基于当前集群状态(缓存数据),完成一次待调度任务的 "筛选→评分→绑定" 全流程 ,是调度器实现资源分配的核心逻辑载体。
一、代码流程逐段解析
阶段 1:安全加载调度配置(并发保护)
Go
pc.mutex.Lock()
actions := pc.actions // 获取动作列表
plugins := pc.plugins // 获取插件列表
configurations := pc.configurations // 获取配置信息
pc.mutex.Unlock()()- 核心作用:从调度器实例 pc 中加载当前生效的 "动作链、插件、配置",是后续调度逻辑的 "规则来源"。
阶段 2:初始化启用动作映射
Go
conf.EnabledActionMap = make(map[string]bool)
for _, action := range actions {
conf.EnabledActionMap[action.Name()] = true
}- 核心作用:创建 "action名称→启用状态" 的映射表(EnabledActionMap),用于后续调度会话中快速判断某动作是否启用(如插件可通过该映射跳过未启用的动作)。
- 设计意图:适配 "动态调整动作链" 场景(如通过配置临时禁用 Score 动作),避免插件重复判断动作是否生效,提升调度效率。
实现的 action 有如下六种,默认的配置有 actions: "enqueue, allocate, backfill"
阶段 3:创建并管理调度会话(资源隔离)
Go
ssn := framework.OpenSession(pc.cache, plugins, configurations)
defer func() {
framework.CloseSession(ssn)
metrics.UpdateE2eDuration(metrics.Duration(scheduleStartTime))
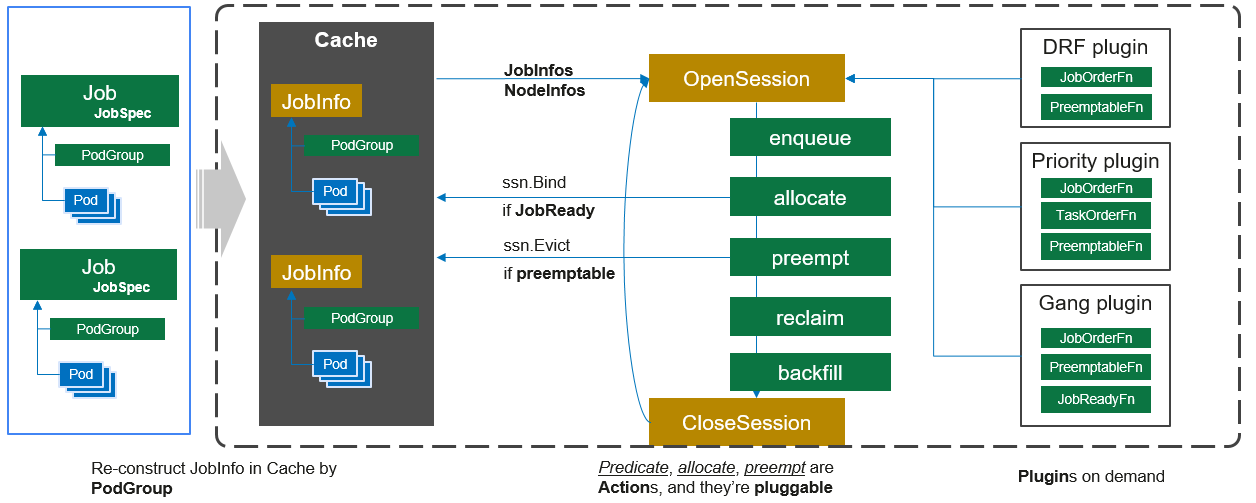
}()- 核心作用:创建单次调度的 "会话实例(Session)",实现 "调度周期内的资源隔离与状态管理",是 Volcano 调度框架的核心抽象。
- 关键逻辑:
a.framework.OpenSession:初始化会话,传入三大核心依赖:
- pc.cache:调度缓存,提供当前集群的 Node/Pod/Job 状态数据;
- plugins:当前启用的调度插件,会话会为每个插件创建独立上下文;
- configurations:调度配置,用于初始化插件参数(如 Score 动作的资源权重);
- 会话内部会维护 "待调度任务列表、候选节点列表、调度结果记录" 等临时状态,避免跨调度周期污染。
b.defer framework.CloseSession(ssn):确保单次调度结束后,释放会话资源(如临时状态、插件上下文),避免内存泄漏。
c.metrics.UpdateE2eDuration:计算并上报 "单次调度总耗时" 指标(从 scheduleStartTime 到当前时间),用于监控调度性能(如单次调度是否超时
阶段 4:执行调度动作链(核心调度逻辑)
Go
for _, action := range actions {
actionStartTime := time.Now()
action.Execute(ssn)
metrics.UpdateActionDuration(action.Name(), metrics.Duration(actionStartTime))
}-
核心作用:按预定义顺序执行所有调度动作,完成 "从待调度任务到 Pod 绑定" 的全流程,是单次调度的 "业务逻辑核心"。
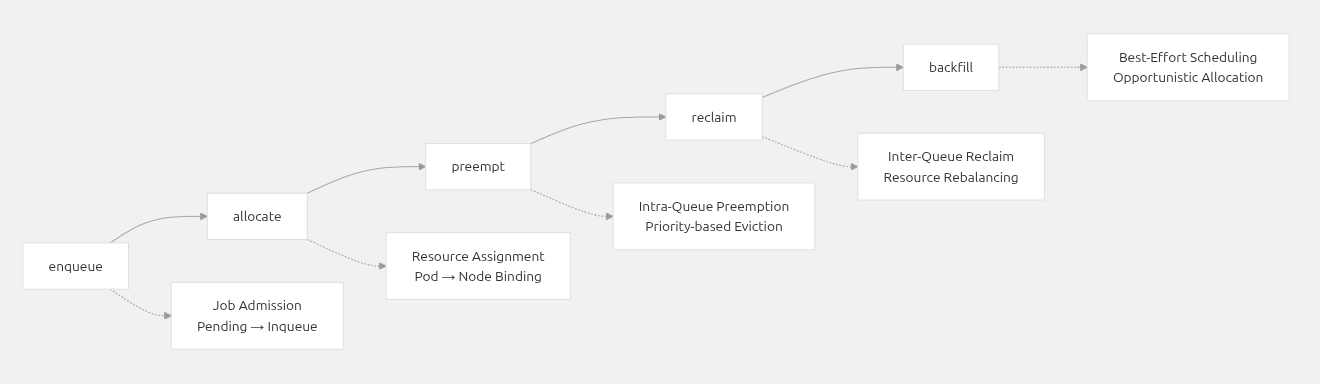
-
enqueue会对Queue和Job这两个资源排序, 然后按照此顺序,判断当前环境是否满足job运行条件,满足的job(PodGroup)将会被标记为"Inqueue"状态。
-
allocate 负责通过一系列的预选和优选算法筛选出最适合的节点。action在配置文件中必填,否则不能调度成功。
-
backfill 的逻辑是遍历待调度 jobs(Inqueue 状态),然后将没有没有指明资源申请大小的 task 进行调度。
二、总结
runOnce 是 Volcano 调度器的 "业务核心",其流程本质是:"加载一致配置→创建隔离会话→按序执行动作→上报调度指标" 的闭环。每一次 runOnce 执行,都代表调度器完成一次 "从感知集群状态到分配资源" 的完整周期,而周期性调用
runOnce(由 wait.Until 控制)则实现了 "持续监控、持续调度" 的能力,确保集群中的待调度任务能被及时处理。理解 runOnce 的流程,可掌握 Volcano 调度器 "如何将配置、插件、缓存结合起来实现资源调度",是深入分析调度逻辑(如插件工作原理、动作执行顺序)的关键基础。