2021 年 ,当 Nexa Boutique(下称 Nexa )的数据架构师在为公司评估数据治理战略时,Databricks 发布了 Unity Catalog 。这是一套原生于 Databricks 平台 的数据治理方案,是比 HMS 更强大的替代选项。Unity Catalog 将 Databricks 平台中的所有资产 纳入统一治理:包括表、视图、ML 与 AI 模型、向量表 ,以及跨工作区边界的 Unity Catalog Volumes 中的文件。
组织在其数据资产版图中通常会同时处理多种数据格式 ,这些格式来自异构源系统 ,往往需要多套数据治理工具 ------Nexa 同样面临这一挑战。在同一数据版图内使用大量定制化 治理工具,极易造成碎片化治理 ,而这通常并非出于本意。Unity Catalog 通过提供一个统一、连贯的产品来治理数据与 AI 资产,从根源上缓解了这种碎片化。
本章将介绍 Unity Catalog 的核心架构 ,探究其内部机理以及使其成为理想治理目录的那些特性。
Unity Catalog 的故事要从 Databricks 的治理历史说起,尤其是 HMS 在满足数据治理需求方面的局限 。随着我们回顾 Databricks 治理的演进与 HMS 带来的挑战,你将理解为何需要一套更健壮、可扩展 的治理方案,并看到 Unity Catalog 如何最终成为 Databricks 的中心化治理工具 。我们会给出支撑 Unity Catalog 的架构支柱 与其设计原则概览,以帮助你理解它的内在工作机制及其如何实现有效治理。
我们将说明如何基于 Unity Catalog 模型构建一个治理良好 的数据平台;同时分享一个准真实 的案例,展示 Nexa 如何在组织内成功落地 Unity Catalog 模型,并强调其在旅程中所获得的收益 与遭遇的挑战。
我们还将覆盖 Unity Catalog 的关键数据管理能力 ,包括可控对象(securable)与访问控制 。你将学会如何利用这些特性来确保对数据资产实施安全且受控的访问。
迄今为止的治理之路(The Governance Story So Far)
在深入 Unity Catalog 的架构之前,有必要先理解它诞生的动机:基于 HMS 的数据目录 之上的既有治理功能,究竟有哪些不足 ,从而催生了 Unity Catalog?为回答这一问题,我们先回顾传统 HMS 体系 中的数据治理是如何运作的,以及 HMS 如何与 Databricks 核心数据处理引擎 Apache Spark 交互。"表访问控制列表(TACL) "与"凭证透传(credential passthrough) "等特性曾经协同工作,以弥补多数治理缺口。下面我们会展开介绍这套集成机制,并回顾 Nexa 在启用 Unity Catalog 之前的 Databricks 架构。
Databricks 平台治理里程碑:
- 2015 :Databricks 平台与 HMS 集成
- 2017 :引入 表访问控制列表(TACL)
- 2018 :在 Azure 上推出 ADLS Gen1 凭证透传
- 2019 :在 Azure 上推出 ADLS Gen2 凭证透传 ;在 AWS 上推出 IAM 凭证透传
- 2021 :发布 Unity Catalog
- 2024 :Unity Catalog 开源
【定义:Apache Spark】
据 Apache Spark 官网:"Apache Spark 起源于 2009 年 UC Berkeley AMPLab 的一个研究项目,并在 2010 年初开源。多年来,其诸多思想发表于各类研究论文。发布后,Spark 发展出庞大的开发者社区,并于 2013 年进入 Apache 软件基金会。"
作为默认目录的 Hive Metastore(HMS)
2010 年 ,Apache Hive 发布;2013 年 ,在本地 Hadoop 集群主导数据版图的时代,HMS 服务 随之出现。正如《序言:基于选择的治理》所述,Nexa Boutique 也从 Hadoop 集群开启了其中央数据平台(CDP)之旅。CDP 团队在公司的本地 Hadoop 集群上累积并管理了近 10 PB 的数据。HMS 在 Nexa 的初期架构中扮演了关键角色,作为元数据的中心存储库 。Nexa 的数据工程师、分析师与科学家对 HMS 的使用路径非常熟悉,已习惯其能力。因此,当这些用户开始迁移至 Databricks 时,仍然觉得环境熟悉。
由于早于云 的广泛采用,HMS 获得了各大数据处理工具与应用(包括 Apache Spark )的广泛支持与接受 。彼时业界还经历过一场文件格式之争 :Apache Parquet、Apache ORC、Apache Avro 在大数据存储格式领域相互竞争。而近些年,业界逐渐收敛 到 Delta、Iceberg、Hudi 等开放湖仓格式 ,因其在性能、可扩展性与事务特性方面更具优势。
这些存储格式 主要在元数据层 存在差异,底层文件普遍采用 Parquet 。Databricks 还发布了 UniForm 兼容性 :消除对独立文件格式与事务日志 的需求,将一切统一到 Unity Catalog 之下,力图终结延续已久的"文件格式之争"。图 2-1 展示了 UniForm 如何自动生成元数据 ,使 Delta Parquet 文件可被以 Hudi 或 Iceberg 的方式访问 ,而无需为不同消费者复制文件。
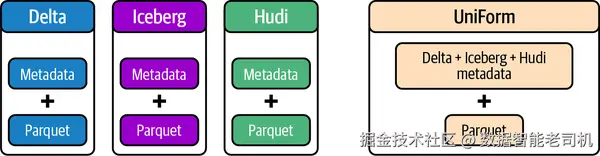
图 2-1. UniForm 兼容性使同一数据可被不同格式消费者读取
在最简化的视角下,HMS 可被视为数仓中表及其模式 的集中注册表 ,将其映射到底层数据文件 的物理存放位置 (见图 2-2)。虽然 HMS 能高效地将表元数据映射到存储位置、从而提升查询性能,但它在对数据提供强治理能力 方面仍显不足。在 Databricks 中部署 HMS 时,你可以选择使用 Databricks 托管的 RDBMS 实例 ,或配置自建外部 metastore (自托管 RDBMS)。采用自建 HMS 可以跨多个 Databricks 工作区共享元数据 ,以克服 Databricks 托管版本的限制,但代价是维护、计算资源配置与成本的额外开销。
另外,对于 AWS 上的用户,也可以在 Databricks 工作区中将 AWS Glue catalog 作为外部 HMS 进行连接。作为一家多云企业 ,Nexa 在 Azure、AWS、Google Cloud Platform(GCP) 上均部署了 Databricks 工作区:Azure 与 GCP 使用托管 HMS,AWS 则使用 AWS Glue catalog 作为其 HMS 服务。
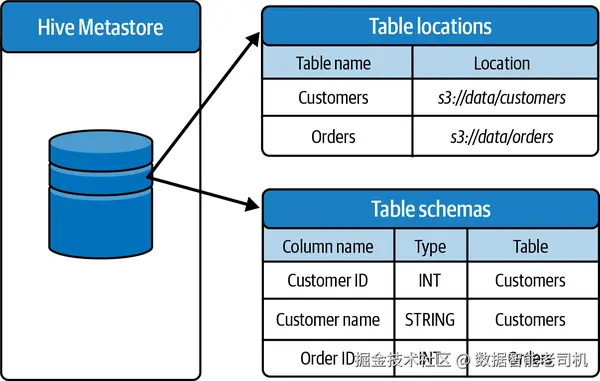
图 2-2. Hive Metastore 元数据存储的简化视图
在 Nexa,CDP 团队 为各业务域团队统一管理 Databricks 工作区的部署与运维。物流与供应链(LSC)域是平台的主要使用方,其单独就占据了整个平台最高达 25% 的支出 。LSC 是一个复杂多面 的领域,包含以下 5 个子域,各自有不同的挑战与机会:
- 需求计划(Demand planning)
- 库存管理(Inventory management)
- 仓储运营(Warehouse operations)
- 采购(Purchasing)
- 运输(Transportation)
在每个子域内,都有若干应用支撑具体业务用例,并分布在不同系统上:既包括本地事务系统 (如 MySQL、Oracle ),也包括云端 SaaS (如 Salesforce )。为支撑业务,CDP 团队在多个全球云区域下为 LSC 域部署了100+ 个工作区 。Nexa 的销售策略高度依赖历史数据分析与预测建模,以便识别趋势、优化定价与预测需求。
尽管 CDP 团队已使用 Terraform 等基础设施即代码(IaC)工具自动化了大部分基础设施部署,但在这么多工作区上管理用户接入 与 HMS 仍带来额外的运维开销。CDP 团队通过 SCIM API 集成,将其身份提供方 Microsoft Entra ID (原 Azure AD)对接到各个工作区以进行用户开通。由于当时缺乏集中式身份联邦 能力,每个工作区 都需要单独完成 SCIM 集成。
【定义:跨域身份管理系统(SCIM, System for Cross-Domain Identity Management)】
SCIM 规范简化了云应用 中的用户身份管理 。它基于既有模式与部署,强调易开发与易集成 ,并复用成熟的认证、授权与隐私 模型。其目标是:让云端用户管理快速、低成本、易用。
图 2-3 展示了使用 HMS 的美国地区 物流域架构,凸显其数据基础设施的复杂性。为简化示意,我们聚焦于需求计划 与采购 两个子域;但若考虑多区域内所有域/子域与合计 500 个 Databricks 工作区 ,实际架构会复杂得多。
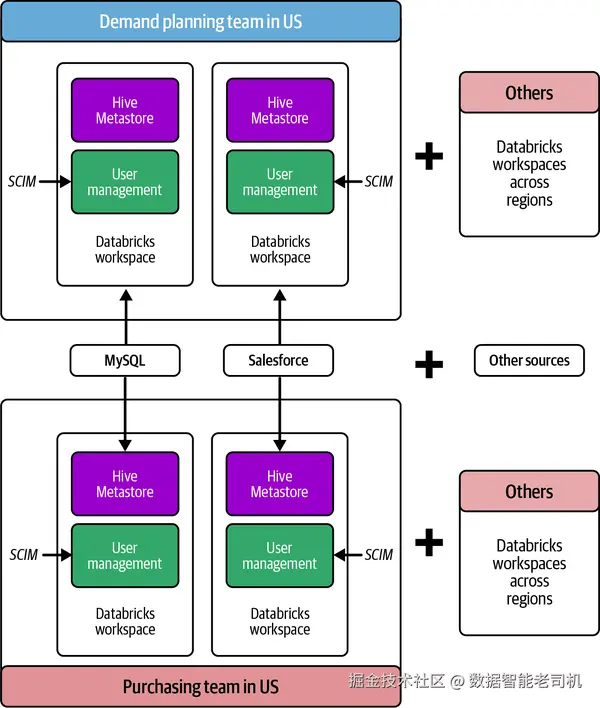
图 2-3. Nexa 在美国的物流与供应链域 Databricks 部署(基于 HMS)
在 Hive Metastore 中的治理困境(The Dilemma of Governance in Hive Metastore)
为向用户提供稳健的数据治理,HMS 这些年有了显著演进。早期,管理员尝试在 集群层 将用户与应用隔离 ,给每个用户/应用分配专属集群 ,以满足治理需求。然而这一做法在本地 Hadoop 集群 与主要云端数据处理平台 (包括早期基于 HMS 的 Databricks)中都有内在局限 :带来更高的成本 与运维负担 。Databricks 引入的凭证透传(credential passthrough)缓解了部分限制,使用户在访问基于文件 的数据时可以共享集群 。但针对 Spark 与 Python 的访问仍存在挑战。后来叠加在 HMS 之上的 TACL(表访问控制列表) 才弥补了这些缺口。本节将深入剖析上述能力如何逐步推动 HMS 的数据治理更加完备。
集群层隔离(Isolation at cluster level)
历史上,Spark 在集群层 实施访问控制,使用 Spark 集群作为 HMS 内的数据隔离边界 。默认情况下,与某个 Spark 集群绑定的 HMS 会向该集群暴露其管理的全部元数据 。此外,在 Databricks on AWS 中,与 Spark 集群关联的**实例配置文件(instance profile)**可用于访问 S3 ,对文件授予读/写权限。Azure 用户通过 **服务主体(service principal)认证访问 ADLS ,GCP 用户通过 服务账号(service account)**认证访问 GCS。
将凭证与 Spark 集群耦合 ,在多租户/多应用 环境中会成为瓶颈 :为每个用户或应用分配专属集群既昂贵 又浪费 ,易造成资源利用不足 。在集群层 做数据隔离还带来重大安全风险 :凡是能访问该集群的人,都可能读取云存储中的敏感数据 。当凭证挂在集群上时,只要能进集群,就可能访问数据,与用户本身的角色/权限无关 。因此,显然需要更细粒度 的访问控制。管理员常用的方法是为每个用户或应用 各自开一套 Spark 集群来实现隔离(见图 2-4)。
为每个用户/应用配置独立 Spark 集群并定制数据访问,会带来以下挑战:
- 维护复杂基础设施的成本高。
- 访问控制粒度粗 ,无法做到行级 或列级控制。
- 为防止形成"有毒组合 "(见下文),管理员必须规划并限制每个集群可达的资源。
- 多集群管理 复杂度提升,运维开销增大。
- 各集群上的作业常无法吃满资源 ,导致资源利用低效。
- 扩缩困难:新增用户或应用通常意味着还要再开新集群。
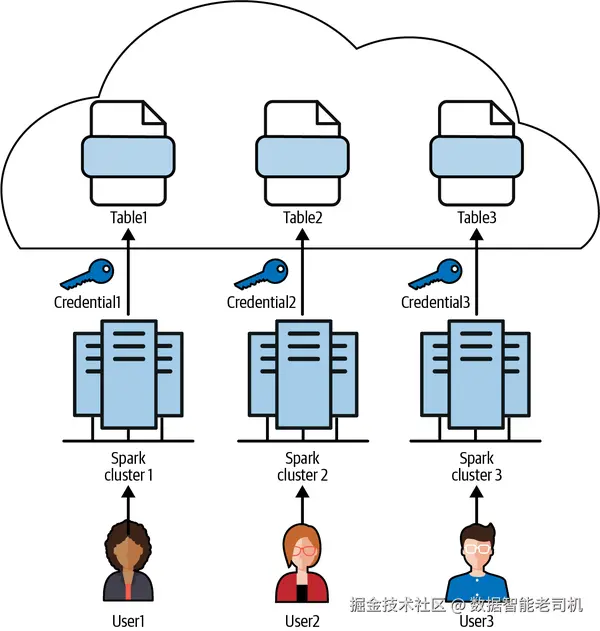
图 2-4. 以"一用户一集群"实现数据隔离
【定义:Instance Profile(实例配置文件)】
实例配置文件是 IAM 角色 的容器,用于在 EC2 启动时向实例注入角色信息。与 Spark 集群关联时,它会把与该实例配置文件等同的权限 授予所有能访问集群的用户;若管理不当,可能将所有可访问的 AWS 资源一并暴露给用户。
【定义:Toxic Combination(有毒组合)】
若干看似"无害"的因素(如漏洞或弱配置)叠加在一起,会形成更严重 的安全问题。不同系统、应用或服务之间的联动可能无意中 创造出薄弱点 ,成为攻击者可利用的隐蔽风险。
通过部署 Apache Sentry 或 Apache Ranger 等额外工具,管理员可以在 HMS 表之上提供细粒度访问控制 ,以实现更细的权限管理。然而它们有一个显著局限:默认只对 SQL 访问生效 ,对 DataFrame 或 Python 文件访问 存在缺口 。可以为 HDFS/NameNode 等组件编写自定义插件 以控制基于文件 的访问(包括 DataFrame API),但这往往侵入性强 、对云端托管的 SaaS 来说不可行 。过度依赖自定义插件还会让架构脆弱 :插件的任何变更都可能带来意外副作用 。此外,Databricks Runtime 更新节奏 很快,插件的兼容性 问题会阻碍新特性 采用。对云端 SaaS 与云存储 做全面的接入控制极其复杂 ;若仅 SQL 生效 ,用户仍可通过非 SQL方式绕过访问控制以读取敏感数据。
【定义:Apache Sentry】
(已退休)在 Hadoop 集群上为数据与元数据提供细粒度基于角色的授权。
【定义:Apache Ranger】
在 Hadoop 生态中实现、监控与管理全面数据安全的框架。
表访问控制列表(Table Access Control List, TACL)
为弥补 HMS 的治理局限,Databricks 引入 TACL ,在 Spark 集群内为 HMS 表提供细粒度访问控制 与治理。TACL 有两种形态:
- 仅支持 SQL 访问;
- 同时支持 SQL、Python、PySpark 等更广泛的访问方式。
其实现会使用元数据表 存放预定义的用户权限 ,并对所有入站数据请求 进行校验------无论请求来自 SQL 查询 还是 DataFrame API 调用。权限在运行时强制执行,从而提供稳健的访问控制与治理(见图 2-5)。
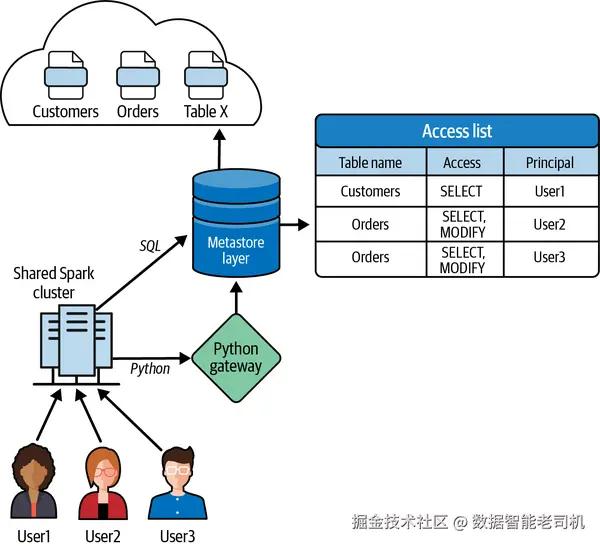
图 2-5. Databricks 中的表访问控制(TACL)实现
Nexa 在 HMS 上启用 TACL 后,结合 Python 与 SQL 的表级访问控制实现治理:
- 启用 TACL 后,可阻止用户 直接通过 Spark DataFrame 查询表。
- 面向多域 的应用在消费数据湖数据时,需要按域 进行行级过滤。
- 捕获到的 PII 需脱敏 ,仅对高权限用户可见。
在引入 TACL 之前,开发者常复制两份表 (一份含 PII,一份去 PII),管理员再按用户组 授予访问。TACL 的动态视图(dynamic views)通过行级过滤 与列级脱敏 能力,解决了数据复制 问题。TACL 提供两个关键函数以实现细粒度控制:current_user() 与 is_member():
current_user()返回登录到 Databricks 工作区的当前用户;is_member()校验当前用户是否属于某用户组。
示例(校验当前用户是否为 Nexa 需求计划团队的有效成员):
sql
SELECT
current_user AS user,
is_member("demand_planning") AS adminTACL 在 Apache Spark 中解决了四类关键治理挑战:
- 把 SQL 的 ACL 执行扩展到 DataFrame API
通过查询元数据表校验每位用户的授权,确保用户仅能访问被授予的数据。 - 阻断不受支持的 Spark API(如 RDD)
通过在 Python 与 Spark driver 通讯的网关处实施允许名单(allow list) ,禁止可能直接读取底层文件的 API。每次 API 调用都会与受支持 API 列表 比对,仅放行那些会在访问数据前做权限校验的 API。
【定义:RDD(Resilient Distributed Dataset)】
Spark 早期的主要用户 API。RDD 是不可变 的分布式数据集合,跨集群节点分区;RDD API 提供低层转换与动作操作。
-
限制网络访问绕过
- 启用 TACL 的集群禁止 连接云厂商元数据服务(其中常包含云凭证),避免用户用 Python 绕过 ACL;
- 入/出站 连接仅允许 80/443 端口,阻止访问其他可能敏感的集群服务。
-
隔离中间路径与本地写入
Spark 在洗牌(shuffle)、关联(join)等中间操作会向磁盘溢写 ,存在数据泄露风险;用户也可能直接写本地文件 。TACL 要求每位 Databricks 用户在 worker 机器上以低权限的系统用户 身份执行,且禁止读取 Spark 或其他用户写下的任何文件,确保敏感数据安全。
注释
AWS 实例元数据服务 IMDSv1 就是为何 TACL 限制访问云元数据服务的典型案例。加拿大计算机科学家 Colin Percival 在其博客《EC2 最危险的功能》中指出:"IAM 角色凭证通过 EC2 实例元数据系统暴露给实例,即可从
http://169.254.169.254/获取......程序获取凭证太容易了。"AWS 随后发布了更安全的 IMDSv2 进行修复。
有了 TACL ,管理员可以在共享 Spark 集群 上向使用 Python 与 Spark DataFrame API 的用户开放计算资源 ,同时维持多层级 的数据访问控制。TACL 之前,共享集群往往只能 进行 SQL 访问,限制了计算共享。启用 TACL 后,用户可充分利用 Spark 与 Python 的能力,并获得细粒度的访问控制。
凭证透传(Credential passthrough)
考虑到许多用户(特别是机器学习工作负载 )直接操作文件 而非表,一个合理的问题是:为何不直接依赖云厂商的文件系统 ACL 来管理数据访问与治理?通常,这些团队的云工程师已在存储层 设置了基于文件 的访问控制;只需把这套控制延展 到通过 Databricks Spark 集群的访问即可。集群级 治理有其局限,而在处理文件 而非表 时,将访问控制下放 给云存储的 ACL 往往更有效。云厂商已提供成熟的 IAM 能力(角色、策略、用户等)。
在 Databricks on AWS 中,管理员可在工作区注册 AWS instance profile 并将其与 Spark 集群关联 。集群即可扮演(assume)特定角色并生成访问云存储的凭证。若仅依赖挂在集群 上的 instance profile,所有用户都会继承同一权限 ,无法落实按用户 的精细控制;管理员也难以审计 具体是哪个用户访问了哪些资源,因为 CloudTrail 等原生日志无法 给出清晰的用户级 访问轨迹。凭证透传 正是为此而生:它使用户可以以登录 Databricks 的同一身份 自动认证到 S3。
AWS IAM 凭证透传的两个关键好处:
- 不同策略的多用户共享单一集群
与"一个 instance profile = 一个 IAM 角色 = 全体用户同权"不同,凭证透传允许多用户各用各的身份策略共享同一 Databricks 集群。 - 细粒度审计
为每位用户分配唯一身份 ,CloudTrail 可将 S3 对象访问直接归因 到用户的 ARN ,实现更细的审计与追踪。

图 2-6. 在 Databricks 集群创建界面以勾选框启用 IAM 角色透传
Databricks 提供多种凭证透传 形态,尽管在不同云与变体上的实现不同,但基础原理一致 。在 AWS 的一种实现中,使用 SAML 2.0 的联合身份透传:
- 当你通过身份提供方 登录 Databricks 工作区时,会触发一次 AWS STS 调用,并基于分配给你的 IAM 角色 签发临时凭证;
- 当你将 Notebook 附着到 Spark 集群 并尝试读取文件时,Notebook 使用该临时凭证去云存储认证访问;
- 认证通过后,你即可按云存储访问控制策略对目标文件进行读/写(见图 2-7)。
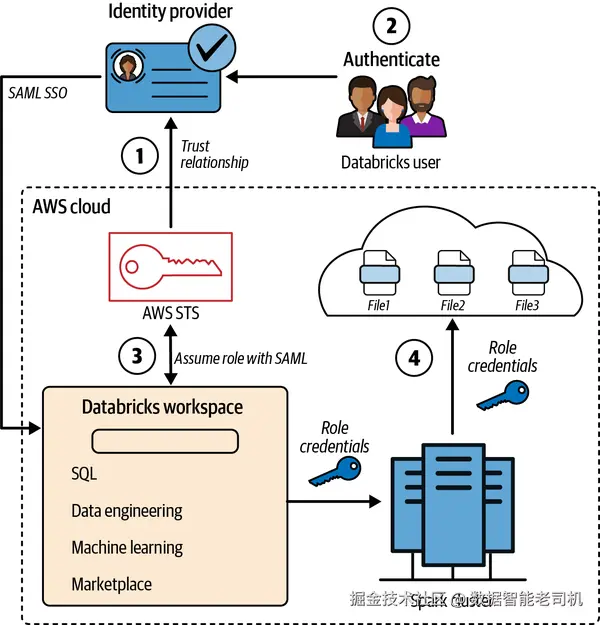
图 2-7. Databricks 中的 IAM 角色透传流程
在 AWS Databricks 工作区启用透传通常包含四个阶段:
- 云管理员 在身份提供方 与 AWS 账号 之间配置信任关系,限定用户可扮演的角色。
- 你通过 SAML SSO 登录 Databricks 时,身份提供方向 Databricks 传递你的角色授权。
- Databricks 调用 AWS STS ,提交 SAML 响应 ,并代表用户获取临时安全令牌以扮演指定角色。
- Databricks Runtime 使用该临时令牌 对发往 S3 的请求进行认证与授权 ,从而在 Databricks 集群中实现无缝且安全地访问 S3 资源。
Unity Catalog 架构(Unity Catalog Architecture)
到目前为止,我们已经讨论了 HMS 面临的一些数据治理难题,包括在集群层面实施访问控制的局限 。当一个访问请求缺少必要上下文时,管理员很难判断应授予用户的恰当访问级别 。此外,如果没有自研 方案,要追踪谁因何目的访问了哪些数据 也十分复杂。不幸的是,自研的细粒度访问控制有时会形成**"有毒组合" ,从而导致 未授权访问**。HMS 还存在其他限制:无法在工作区之间共享元数据 、不支持 ML 与 AI 模型 、以及基于文件的访问控制缺失 。这些限制使 HMS 不适用于 在 Databricks 上构建下一代数据治理 。Unity Catalog 正是为弥补 HMS 的不足而设计。本节将详细说明使这一切成为可能的架构性变革。
在评估 Unity Catalog 作为 Nexa 的治理方案时,数据架构师针对其架构与数据管理能力提出了两个关键问题:
- 团队需要弄清 Unity Catalog 的 Databricks 服务在云厂商中的托管位置 ,以及它是运行在控制平面 还是数据平面 。如第 1 章所述,Databricks 平台由控制平面(Databricks 云账号)与 数据平面(Nexa Boutique 的云账号)构成。若 Unity Catalog 作为控制平面服务 运行,就必须明确它在控制平面存储了哪些关于数据的元数据/信息。
- 团队想了解 Unity Catalog 如何帮助满足围绕 PII 数据存储、数据传输与数据主权 的监管要求 。为做出明智判断,Nexa 的架构师需要理解支撑 Unity Catalog 的关键架构组件。
本节将简要介绍 Unity Catalog 的架构:先从 Databricks 账号 入手,它有助于集中化 管理用户与工作区;随后介绍 区域级 metastore 的概念------Unity Catalog 中所有元数据的"安家之所"。我们也会回答"控制平面究竟存了哪些元数据 "这一 Nexa 架构师关心的问题。随着阅读推进,你将了解 Unity Catalog 如何处理 PII 等敏感数据,并帮助你符合法规。
借助 Unity Catalog 实现集中式治理(Centralized Governance with Unity Catalog)
表访问控制(TACL)解决了 Databricks 上基于 HMS 的诸多难题,但如何把它扩展到新时代 ?HMS 的最初目标很具体:让用户像访问数据仓库的表一样访问数据湖中的文件 。HMS 在这一目标上表现优异,但在数据治理 上欠缺,因为治理并非其首要设计考量 。为了弥补 HMS 的不足,工程师们开发了自定义方案 并插入到体系架构中。例如,eBay 的工程师编写了 Hive metastore 事件监听器 ,将表变更事件发送到 Apache Atlas ,借此在与 Apache Ranger 集成的 Hadoop 集群上构建数据治理。
【定义:Apache Atlas】
Apache Atlas 是一套可扩展的治理平台,帮助企业在 Hadoop 及更广泛的数据生态中满足合规要求,提供开放元数据管理 、数据资产编目 、分类 与协作工具。
然而,自研方案存在局限 ,并可能在企业级规模上引入安全隐患 。不断收紧的监管要求 、AI 的快速演进 以及对集中式数据治理 的需求,呼唤更加现代的解决方案。Unity Catalog 自底向上为当代的数据智能平台(Data Intelligence Platform)架构而设计。
我们已经明确:Unity Catalog 服务运行在控制平面 。那么,它在 metastore 中到底存了什么 ?为回答这个问题,我们需要深入 Unity Catalog 的架构,并理解它位于控制平面的架构含义。见图 2-8。
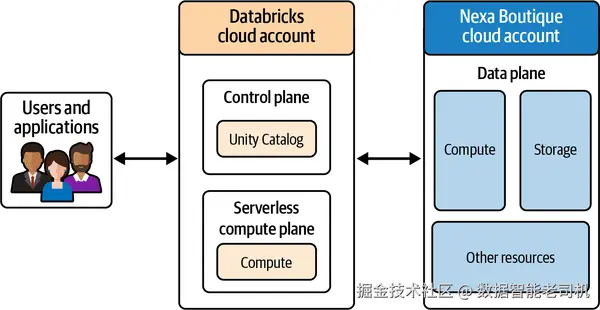
图 2-8. 含 Unity Catalog 的 Databricks 总体架构:控制平面与数据平面的部署
Databricks 账号(Databricks account)
在 HMS 时代 ,Databricks 工作区 既是访问控制 的边界,也是元数据隔离 的边界。你可以拥有多个 Databricks 工作区,各由其工作区管理员分别管理。在每个工作区内 定义访问控制与用户管理,对管理员而言负担很重 ,尤其在新团队接入 或新工作区落地时。
为满足集中化管理 的需求,Databricks 引入了账号(account)概念:允许管理员在一个中心位置 管理多个工作区。Databricks 账号使企业能够集中管理其全部工作区,显著简化管理流程。账号附带的 account console 支持账号管理员集中创建/管理用户、工作区与 metastores。
【定义:Account Admin】
账号管理员 是随 Databricks 账号引入的新角色,拥有较高权限。账号管理员可以登录 account console,对整个 Databricks 部署实施集中化管理。
与 HMS 相比,Unity Catalog 的架构在用户与元数据管理 上实现了集中化 :从封闭的工作区级 ,提升到更开放共享 的账号级 UC 。账号级集中化用户管理通过身份联邦 简化了工作区管理员的工作:管理员可以将组织的用户、用户组与服务主体 同步到 Databricks 账号控制台(例如,利用组织的身份提供方 通过 SCIM API 同步到 Databricks)。随后,管理员可通过身份联邦 将这些已开通的身份分配 到任意工作区,而无需 在每个工作区重复 该流程。在 Unity Catalog 之前 ,管理员需要对每个工作区分别配置 SCIM。第 3 章《身份管理》将介绍在 Databricks 中管理身份的方法与 Nexa 的最佳实践。
在 Nexa ,500+ 工作区 与其用户管理曾是重大挑战;而身份联邦 将 SCIM 集成流程一次性 化,管理员可以在账号控制台 集中管理 Nexa 全部工作区的用户接入。图 2-9 对比了 HMS 与 UC 在用户与元数据管理上的差异。
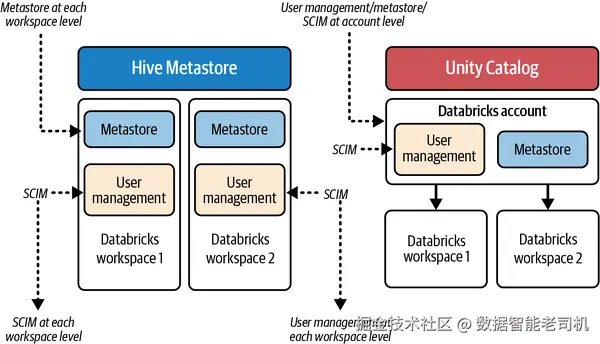
图 2-9. Unity Catalog 中的集中式 metastore 与用户管理
区域级 metastore(The metastore regional construct)
如上所述,Unity Catalog 是在 Databricks 账号层 运行的集中式元数据管理服务 。它借助底层云厂商的区域服务 来存储其元数据。UC 的核心是 metastore :它是账号内数据组织的最高抽象层 。在底层实现上,metastore 位于由 Databricks 托管与运维 的受管数据库实例 中。metastore 保存由 Unity Catalog 管理的数据资产的元数据 ,充当集中式的数据资产目录 。这些元数据包括但不限于:表定义与模式、文件在云存储中的位置、访问控制定义、系统表中的审计日志等。
为便于数据共享 ,Databricks 要求每个云区域只创建一个 metastore 。HMS 将访问限定在单一工作区 内,Unity Catalog 需要突破这一限制,才能为用户提供真正的数据民主化 体验。你可以将工作区挂接 到其所在云区域的 metastore。把所有服务部署在同一区域 ,有助于简化网络 、降低时延与成本 (同区传输通常免费或更便宜 ),同时便于满足数据属地 合规。metastore 还可可选 配置一个云存储位置 ,用来保存在 Unity Catalog 中创建的托管表、卷(volume)或 ML 模型 的数据。虽然可在 metastore 层进行存储配置,但不推荐 这么做,因为通过目录(catalog)级 存储也能实现数据隔离。账号管理员可以为某个 metastore 指定 metastore admin ,由其负责该 metastore 的访问控制 与其子对象的创建等管理任务。
将单个 metastore 附加到同一区域的多个工作区 ,就开启了跨工作区 的数据共享能力,从根本上弥补了 HMS 在共享元数据 方面的缺口。UC metastore 中的元数据及其访问控制 可以一次定义 ,并在所挂接的任意工作区 被消费与强制执行。见图 2-10。
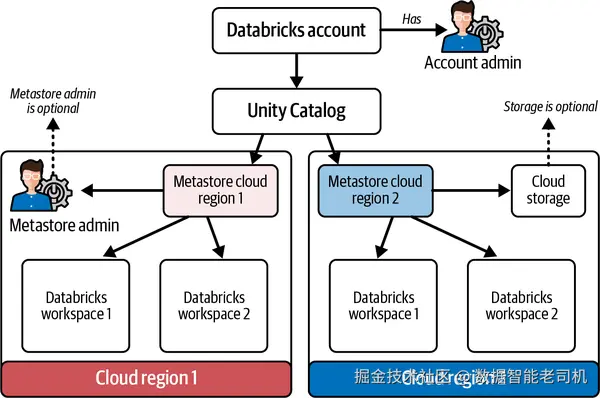
图 2-10. 含账号与 metastore 的 Unity Catalog 架构
【定义:Metastore Admin】
metastore 管理员 是在 Databricks 中权限很高的角色,负责管理某个 metastore 的所有访问控制。由于该角色可为自己授予对 metastore 内所有数据资产的访问或创建数据共享,Databricks 建议将该角色保持可选 ,并将权限适度下放给工作区管理员。
UC metastore 在控制平面持久化了哪些元数据?
UC metastore 在控制平面持久化的是关于数据资产的元信息 ,而不是数据本身。典型元数据包括:
- 表与视图 的名称、模式,以及其在云存储账号 中的文件位置;
- **卷(volumes)**的名称与文件位置;
- ML 模型的名称与**工件(artifact)**存放位置;
- 由 UC 管理的函数定义;
- 这些数据资产的访问控制(授予与权限),适用于工作区用户、服务主体与 IAM 角色;
- 云存储位置与其凭证 :UC 会基于这些位置与凭证,按需向消费者下发(vend)范围收敛、短期有效的临时凭证;
- 数据共享 时的接收方与共享明细(包含被共享的资产);
- 审计日志与使用记录(写入系统表)。
关键要点:metastore 是你数据资产元数据的"延伸" ,而非数据本体的存放处。你的数据始终保留 在你自己的云账号 (即数据平面 )中;Databricks 不会 把数据搬到位于 Databricks 控制平面的 UC metastore 中。
有了中心化 metastore ,便可将数据源一次性 引入湖仓,并在与该 metastore 处于同一区域 的任意 Databricks 工作区 中进行消费。图 2-11 展示了与基于 HMS 的部署(见图 2-3)相比,Unity Catalog 如何简化 Nexa 的湖仓架构。
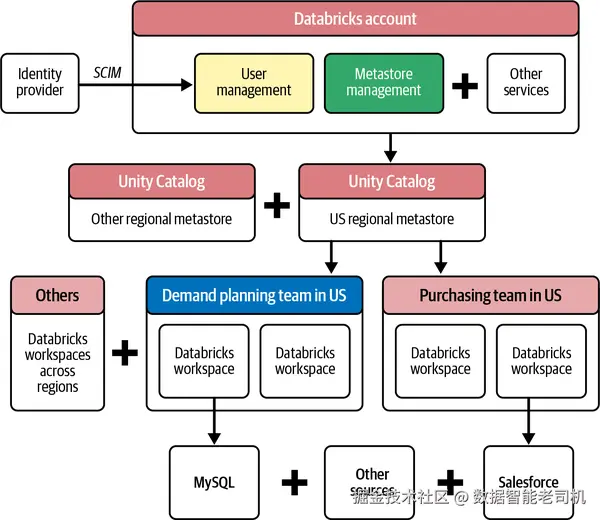
图 2-11. 相对图 2-3,使用 Unity Catalog 后 Nexa 的简化架构
Unity Catalog 的治理模型(The Governance Model of Unity Catalog)
到目前为止,我们已解释了定义 Unity Catalog 架构的两个基础特性:集中式账号 与区域绑定的 metastore 概念。接下来,我们从凭证管理流程 入手,看看 Unity Catalog 如何落实治理。我们将说明 Unity Catalog 如何在中心化 地管理凭证并安全授权 :将访问权限授予被隔离的单个用户与进程 ,而不是挂到一个"人人同权"的集群上。一旦在 Unity Catalog 中安全注册了某个凭证,我们将进一步讲解如何使用存储凭证(storage credential)来创建外部位置(external location) ,映射到云存储的位置。最后,本节将讨论 Unity Catalog 中的不同计算模式 ,以及在 Spark 集群中如何对进程与用户进行隔离------这构成了由 Unity Catalog Lakeguard(本章稍后讨论)所支持的关键架构设计。
解耦的存储凭证(Decoupled Storage Credentials)
在高度复杂的云端解决方案中,成百上千的服务相互交织,一个 漏洞就可能导致系统崩溃。这个漏洞往往并非高级黑客技术或编码错误,而是更"日常"的:凭证管理 。在启用 Unity Catalog 的 Databricks 工作区里,metastore 是中心化凭证管理体系的关键:它安全地存放并管理 连接云对象存储与外部服务所需的全部凭证,形成单点的控制与运维 入口。存储凭证 特性让 UC metastore 具备集中式的凭证管理能力:以统一且安全的方式保存、管理与控制敏感凭证的访问。采用何种存储凭证取决于承载 Databricks 工作区的云平台 。具体而言,存储凭证支持登记多种云特定 身份机制(见表 2-1)。
表 2-1. 各云平台身份机制对比
- AWS:IAM 角色(IAM roles)、服务主体(service principals)
- GCP:服务账号(service accounts)
- Azure:受管身份(managed identities)、服务主体(service principals)
不同于 HMS"把凭证挂在集群上、全体集群用户可见"的做法,在启用 UC 的工作区中,存储凭证本身是受治理的资产 :管理员可按需仅向特定用户/用户组 授予使用权限。通过将凭证管理从集群配置中解耦 ,Unity Catalog 在管理对云存储与外部服务的访问时提供了更安全 、更可扩展的方法。
在欧洲与英国 ,Nexa 将 LSC 领域的 Databricks 工作区部署在其 Microsoft Azure 云账号中,ADLS 作为数据平台的云存储层。受管身份(managed identity)是在 Databricks 计算资源连接 ADLS 时使用的凭证。Microsoft Azure 提供 Azure Databricks 访问连接器(access connector) 这一一方资源,用于把受管身份接入 Databricks 账号。UC 的 metastore 管理员或被委派的工作区管理员,会把该受管身份 注册为 Unity Catalog 存储凭证 (而不是像 HMS 那样直接挂到集群/服务主体上)。注册完成后,管理员即可向用户授予使用该凭证访问 ADLS 位置的权限。Databricks 审计日志 会把动作归因到发起用户 ,从而获得清晰的审计追踪 (反映用户行为,而非执行进程所用的受管身份)。在 Nexa,CDP 团队通过 Microsoft Entra ID 的用户组 来持有这些注册的存储凭证的所有权 ------推荐 用组 来管理资产所有权,而非分配给个人。
【定义:受管身份(Managed Identity)】
Microsoft Entra ID 中的受管身份为应用提供自动管理的身份,用于访问资源,免去显式管理凭证。在 Azure Databricks + Unity Catalog 中,推荐通过访问连接器使用受管身份。
云对象存储的外部位置(External Location for Cloud Object Storage)
Unity Catalog 将云存储位置在其 metastore 中封装 为外部位置(external location) 。管理员可使用已注册的存储凭证 来创建外部位置;要让用户创建外部位置,必须先向其授予该存储凭证上的 CREATE EXTERNAL LOCATION 权限。在 Azure 中创建外部位置时,云管理员需为受管身份授予目标存储账号的 Storage Blob Data Contributor 角色。Unity Catalog 会基于用户在 UC 中的授权 ,为其在相应外部位置上的特定数据集签发"降权限的临时令牌" ,从而限制访问范围 。在 UC 中,先注册外部位置,才能在其之上注册表 。外部位置本身也是受治理的资产 ,因此管理员可以阻止对这些云对象存储位置的未授权访问。
⚠️ 警示
Unity Catalog 禁止其管理的任何存储位置重叠 :一个外部位置不能与同一 metastore 中的另一个外部位置重叠。Databricks 建议不要 在外部位置的根目录 创建外部表,而应在其子目录下创建。
在 UC 之前,Databricks 提供的DBFS (与云存储交互的分布式文件系统)常被用于在 HMS 中建表。Nexa 大量使用 DBFS,因为可以通过服务主体 将 ADLS 容器挂载 到工作区,实现全员访问的场景。对于"人人同权"的数据访问,DBFS 很方便;而当访问需要因人而异 时,通常通过动态视图 实现行级过滤 与列级脱敏 。Unity Catalog 已弃用 DBFS ,且不支持 基于 DBFS 对象建表。Nexa 在从 HMS 迁移到 UC 时,把所有 DBFS 存储位置迁移为 UC 的外部位置,显著提升了存储层的治理能力。
这解决了基于表 访问的治理问题,但 UC 如何处理 DBFS 中的任意文件 ?上传到 DBFS 便于处理非结构化文件 (如图像处理等 ML 工作负载)。然而,DBFS 落地文件缺乏访问控制 的问题需要修复。Volumes 以更安全、受治理 的文件存储取代了 DBFS 的任意文件,从而补齐了工作区内文件治理 的缺口。图 2-12 展示了 UC 如何以简化形式存储元数据、管理存储凭证并定义外部位置。
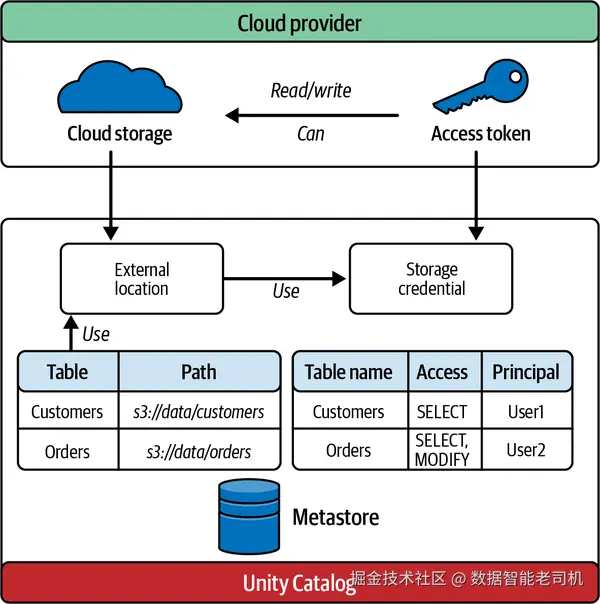
【定义:Volumes】
Unity Catalog 中的 Volume 是云对象存储中的逻辑存储空间 ,用于以任意格式(结构化/半结构化/非结构化)访问、存放、治理与组织文件。
注意:不允许 直接在 UC Volume 之上创建表 。你可以从 Volume 读数据 ,但写出的表 必须落在独立的外部位置。
⚠️ 警示
访问 UC 中注册的外部位置 中的数据,用户需要 READ FILES 权限;拥有该权限后,用户可通过路径访问直接读取存储中的数据。例如,读取已在 UC 中注册为外部位置的 S3 路径:
lua
spark.read.format("parquet").load("s3://your-bucket-name/path/to/your/data/")但如果你在该外部位置之上注册了表 ,则还需要 SELECT 权限 。仅授予 READ FILE 不足以访问该表:表级权限优先于文件级权限 ,会覆盖 READ FILE;此时,若无表的 SELECT 授权,基于路径的访问将不再生效 。该行为在 AWS S3、GCS、ADLS 上一致。
Unity Catalog 的计算模式(Compute Modes in Unity Catalog)
在前述中心化凭证管理 基础上,我们来看 UC 如何实施细粒度访问控制 ,确保只有获授权用户才能访问数据。UC 如何在 Apache Spark 计算中阻止未授权访问(历史上共享凭证 容易被滥用)?为此,需要理解 UC 的不同计算模式 以及 Lakeguard 如何让共享的 Spark 环境也能安全。
【定义:Lakeguard】
Lakeguard 是 UC 计算引擎背后的技术,用于隔离式数据处理 :在计算层 执行数据治理,隔离用户代码 与 Spark 引擎 访问,使 SQL、Python、Scala 等工作负载在共享算力下也能实现细粒度访问控制(FGAC)与行级安全(RLS) 。
一个存储凭证通常对其关联的父路径 有"总访问权 "。若直接使用该总权限,可能破坏表级的访问边界,因为某张表通常只用到父路径下的子路径 。
以 Nexa 在 AWS 的场景为例:某个 S3 桶承载了 Salesforce 的落地数据。数据分析师据此生产Power BI 的产品发运看板,与业务高管共享。CDP 团队将 s3://nb_lsc_purchasing_prod/salesforce_gold 注册为外部位置 ,并把具备该桶 读/写策略 的 IAM 角色 登记为 UC 的存储凭证 。在该路径下创建了如下 UC 表(表 2-2):
表 2-2. 云存储路径与在 UC 中对应创建的表
s3://.../salesforce_gold/shipping→ shippings3://.../salesforce_gold/drivers→ driverss3://.../salesforce_gold/vendors→ vendors
管理员仅授予分析师对 shipping 表的 SELECT 权限。分析师从 Power BI 发起查询请求 shipping 。如果 UC 直接使用"注册的存储凭证"的总权限,用户将间接获得 该外部位置下所有数据集 的访问,而不仅是 shipping。
为防止未授权访问,UC 先检查用户在目标资产 上的授权 ,若无权限即拒绝。当合法用户请求资产时,UC 作为凭证下发器(credential vendor) ,按资产 签发降权限的临时令牌 ,屏蔽对其他数据集的访问。比如,仅能读取 .../salesforce_gold/shipping 子路径的令牌,便可阻止分析师访问其他未被授予的表。图 2-13 展示了 UC 管理的数据访问全生命周期。
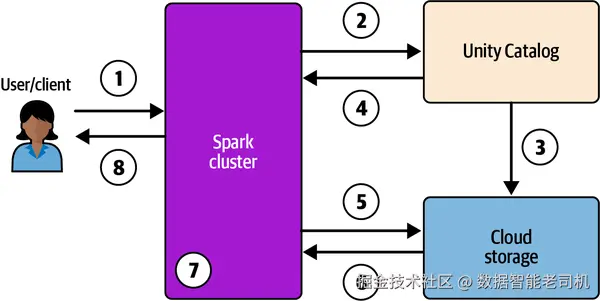
当你在 UC 计算集群或**仓库(warehouse)**中运行查询,幕后流程如下:
- 终端用户针对 UC 计算集群/仓库执行查询;
- UC 校验用户对目标表的授权;
- 若通过,UC 扮演 存储凭证所注册的角色,并生成降权限的临时凭证(限时令牌);
- UC 把该临时凭证 与文件路径返回给集群;
- 集群使用该临时令牌向云存储请求数据;
- 云存储将请求数据返回集群;
- 集群对结果强制执行策略 (如 RLS 与列级脱敏),确保用户只见其被授权的数据;
- 最终用户获得结果。
Unity Catalog 为用户提供两种计算访问模式 :标准(standard,原 shared)与专用(dedicated,原 single-user) 。
- 标准模式 :允许多用户共享 一个 Spark 集群并并发 运行作业,且彼此完全隔离;
- 专用模式 :集群专属某一用户,仅执行该用户提交的作业。
在标准/共享模式下用 Lakeguard 实现隔离
在接口层 ,UC 作为凭证下发器 ,仅 授予用户请求的数据集 所需的访问,避免"越权"。
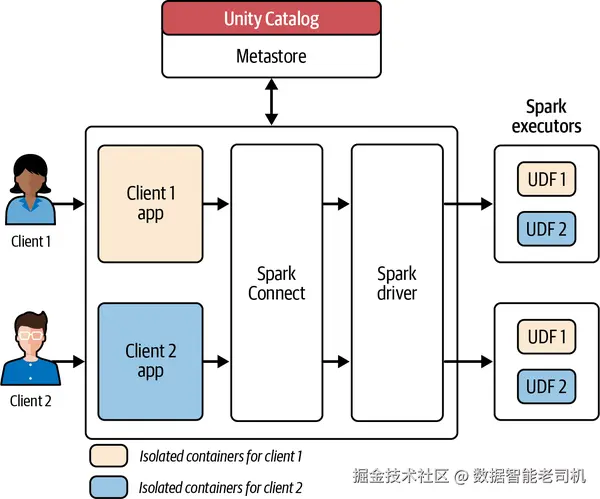
在 Apache Spark 计算中,传统上集群 是数据隔离边界;共享集群中的用户与进程共用 JVM 与中间路径 (存放 shuffle/join 结果)。共享集群通常以高权限 用户身份运行进程,默认彼此不隔离 。Lakeguard 在启用 UC 的 Spark 集群中引入强隔离 :隔离用户 、代码 与 UDF 与 Spark 引擎之间的访问,成为多租户部署的安全基座。
UC Lakeguard 通过多项架构更改 实现隔离:包括借助 Spark Connect 完成用户隔离 ,并以容器化沙箱 实现进程与代码 隔离(见图 2-14)。
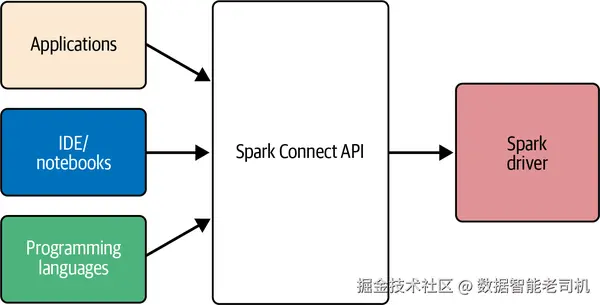
【定义:Spark Connect】
自 Apache Spark 3.4 起提供的客户端-服务器架构 :通过 DataFrame API 远程访问 Spark 集群。该解耦便于把 Spark 集成到应用、IDE、notebook 与多种语言。
注:Spark Connect 基于 DataFrame API 实现,仅适用于以 DataFrame 编写的应用;若使用 RDD API,迁移到启用 UC 的共享集群需要改造为 DataFrame API。
Spark Connect 以"瘦客户端库"的方式嵌入到应用服务器、IDE、notebook 与编程语言中;将客户端操作(如 SQL)用 protobuf 编码,并通过 gRPC 传给 Spark 服务器,从而实现客户端隔离 。当客户端向集群提交任务后,下一步是沙箱化 进程:把操作与相应用户代码部署到容器 中,互相隔离 ;UC Lakeguard 限制容器边界外的访问 ,防止用户进程跨越访问他人进程。
容器化还将高权限用户 替换为降权限用户 ,仅赋予必要资源访问,减少攻击面。UDF 的执行同样在其自有容器 中完成,防止跨数据访问 。在这样的完全隔离 下,共享模式 也可以支持 FGAC(行/列级限制与 PII 脱敏)。
需要注意的是:共享模式 下用户运行于非提升权限 环境,不安装系统级库与编译器,因此不适合 需要提升权限的工作负载;分布式 ML 等场景受限。图 2-15 展示了在 Spark driver 与 executors 内通过容器实现的进程隔离。
单用户/专用模式:面向提升权限的工作负载
对需要提升权限 的工作负载(如分布式 ML/AI )而言,共享模式因受限于底层资源访问并不适配。比如在 NVIDIA GPU 上运行 CUDA 低层编程,需要直接访问操作系统库 与底层机器 API 。共享模式的容器隔离与受限的机器 API 访问会阻断这类低层资源需求,因此无法提供GPU 支持 。
单用户模式 (专用)提供对计算资源的提升访问 ,可覆盖需要高权限与 GPU 的广谱工作负载;每位用户拥有建立在原始 Spark 架构 基础上的专属计算环境 ,由 UC 集中管理。
提升权限也带来新挑战,例如在查询启用 FGAC 的视图或表时可能出现overfetching(过取) :由于对象存储的物理特性(文件按块写入),Spark 需先读入相关文件块再过滤,即便用户仅有部分行/列权限,也可能把不必要的数据 读入集群。在提升权限 环境下,这部分过取数据可能曝光 给用户。为缓解该问题,UC 要求在查询视图时用户必须对其底层表 有访问,且不支持 对启用 FGAC 的表进行此类访问。
Unity Catalog + Lakeguard 通过在 Databricks 控制平面 引入无服务器(serverless)计算层 来处理:在把数据送入 Spark 集群前,先在该层进行过滤 ,仅传递获授权的数据 ;同时限制对该 serverless 过滤计算的访问,防止终端用户未授权接触敏感数据(见图 2-16,展示单用户模式与 serverless 计算如何实现 FGAC)。
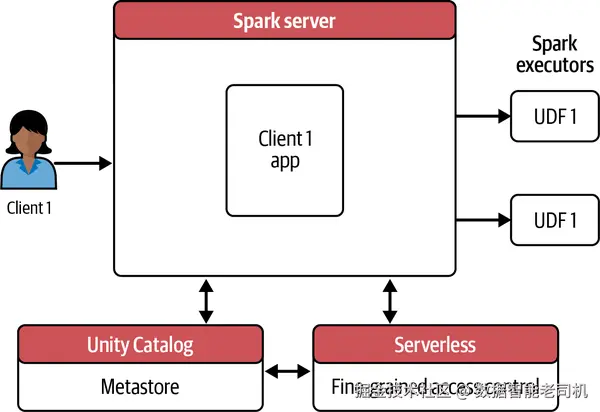
第 6 章将更详细讨论 UC 支持的不同计算选项的用例、特性与限制。
数据管理特性(Data Management Features)
良好的治理高度依赖有效的数据管理 ,而后者取决于对数据资产的精心编目与组织 。除了技术考量外,数据管理的成功也取决于人的因素 :组织中的人员、流程与实践,既可能促成有效的数据管理,也可能妨碍它。因此,在设计与实施数据管理策略时,必须将这些因素纳入考量。
在 Nexa,数据平台团队将运营集中化,并使其数据管理原则与 CDP 团队 定义的架构蓝图与标准 紧密对齐。在 Unity Catalog 之前,每个工作区都在其专属 HMS 中拥有一个 metastore,每个源系统相关的数据或元数据都存放在对应的 Hive schema 下。大多数需要出于合规或存在 PII 而进行数据隔离的场景,会单独分配一个工作区。下面看看 Unity Catalog 如何满足数据隔离需求,并提供一套健壮的数据管理框架。
以目录为命名空间(Catalog as the Namespace)
区域级 metastore 是 Unity Catalog 中的最高抽象层 ,在控制平面提供集中式的元数据存储库。你可以选择将所有托管数据 放在与该 metastore 关联的集中式云存储位置 中。然而,对于需要严格数据分离(受法规或内部数据共享政策驱动)的领域或应用,共享存储层并不能提供必要的隔离。
Catalog(目录) 通过在既有 schema 与 table 之上引入命名空间层级的第三层 ,在 Unity Catalog 中提供强隔离 。在引入 UC 之前,Nexa 的需求计划(Demand Planning)团队将他们的 Salesforce 数据存放在 HMS 中,采用 schema.table_name 约定;例如,用户通过命名空间 salesforce_gold.sales_channel 访问该团队的销售渠道数据。
引入 UC 后,CDP 团队 为每个团队建立独立的 catalog ,赋予他们对数据资产更大的灵活性与控制力。例如,需求计划团队创建了名为 nb_lsc_demand_planning_prod 的目录来存放其生产环境 的全部数据集。新的目录带来了新的命名空间:nb_lsc_demand_planning_prod.salesforce_gold.sales_channel,以更细粒度、团队与环境 为维度组织与访问数据。CDP 团队还按开发/测试/生产 环境分配不同的目录:开发者在 nb_lsc_demand_planning_dev 编码并跑单测,在 nb_lsc_demand_planning_test 跑集成测试。
在 UC 中,catalog 是按共同特征或目的对数据集进行逻辑分组 的机制。将数据集组织进目录可简化数据管理与发现 ,更易查找与访问相关数据资产。进一步地,目录为封装数据产品 与落地数据网格(data mesh)提供了简洁手段,使你能够在更开放的治理下实现平台去中心化 。对 Nexa 而言,按目录组织元数据并按环境与业务单位隔离,是一次受欢迎的变革,推动了数据访问的民主化。
目录与架构级的数据隔离(Data Isolation at Catalog and Schema Level)
在 Nexa,开发与生产环境之间有严格的数据共享限制 。同一区域内的域团队对共享同一 metastore 与其存储位置 心存顾虑,因为一些团队的监管要求规定必须对无权访问其数据的用户实施存储级隔离 。目录为元数据提供了额外的组织层级,但数据如何按团队或应用实现隔离 ?若将所有托管资产都存放在区域级 UC metastore 的云存储位置,可能导致数据难以在团队之间分离并保持机密性。
Metastore 管理员 在创建目录时,可以将该目录与由域团队拥有并管理 的独立云账号/订阅 中的外部位置(external location)关联。通过将"自有存储"带入 UC 的目录,不同域团队可以在共享的区域级 UC metastore 下工作,同时在存储层面 实现彻底的数据隔离。CDP 团队要求每个新目录 必须绑定一个全新的外部位置 ,并不允许复用 外部位置。目录创建通过 Databricks Terraform provider 自动化完成,这些规则被写入 DevOps 流程,在各域间强制最佳实践 。目录级、由域团队自有的存储,有效化解了顾虑,并以惊人的速度加速了 UC 在 Nexa 的落地。
在 Nexa,每个应用 在 UC 中都映射为一个独立的 schema ,与该应用相关的所有资产都放在同一 schema 中。按schema 实现应用级数据隔离 非常契合 Nexa 的需求。UC 将隔离能力从目录扩展到schema 级 :目录内的各个 schema 可各自绑定外部位置,从而为每个应用 提供独立的隔离路径。这对 Nexa 基于 UC 构建数据治理架构大有裨益。
目录到工作区绑定(Catalog to Workspace Binding)
与 HMS 相比,UC 在架构上有一项重要变化:允许同一区域 的多个 Databricks 工作区 共享区域级 metastore 。一旦某个工作区挂接 到一个 metastore,该工作区的用户即可访问其中对用户可见 的元数据与数据。CDP 团队为 Nexa 的 DevOps 三个环境(开发、测试、生产)分配了唯一目录 ,并严格限制生产数据的访问,防止其从低环境(如开发或测试)被访问。
然而,将一个 metastore 挂接到工作区意味着该工作区默认可见 其内的所有目录 :若某用户同时有开发与生产目录/工作区的访问权,他可能在开发工作区 访问到生产数据 ,构成安全风险。为防止跨环境过度授权 ,UC 提供目录到工作区绑定(catalog-to-workspace binding) :管理员可以更新目录可见性 ,使目录仅 对已激活绑定的工作区用户可见。
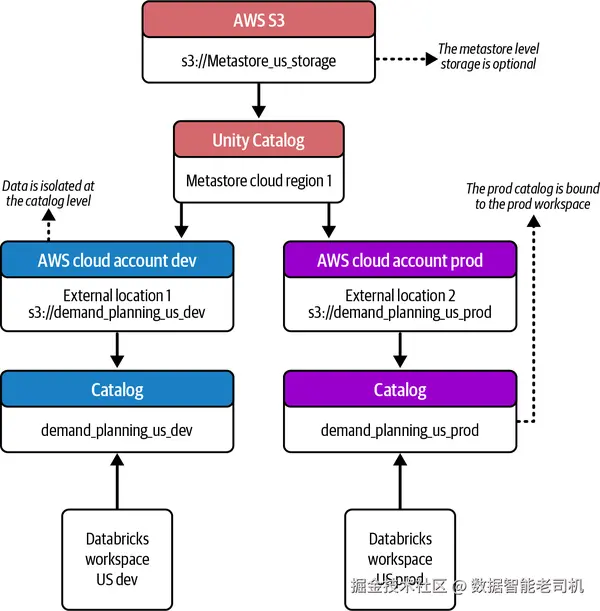
图 2-17. 通过目录级外部位置与目录-工作区绑定在 UC(AWS)中实现存储级隔离
总结(Summary)
我们最大的弱点在于放弃。取得成功最可靠的方法,永远是再尝试一次 。
------ 托马斯·爱迪生(Thomas Edison)
HMS 仍是大数据生态中互操作性最强 的 metastore,但并不适配 现代数据平台。尽管多年间不断调整以弥补缺陷,HMS 已走到应由更现代方案取代 的阶段。读完本章后,你或许最初会认为 Unity Catalog 只是为解决 HMS 带来的治理难题而生;但事实上,它在 Databricks 平台内开启了更多可能性 ,其开源版本 更将这些收益扩展至 Databricks 之外的整个社区。本章在回顾历史与架构的同时,也回答了 Nexa 的数据架构师们最关心的一个 metastore 问题。
既然我们已经夯实了对 Unity Catalog 架构 与数据隔离 的理解,接下来就将进入访问控制 这一关键主题。基于角色的访问控制(RBAC) ,尤其是如何在 Databricks 中基于 UC 处理 PII 与实施 FGAC ,是 Nexa 的数据架构师尤为关注的内容。第 3 章将通过 Nexa Boutique 的真实案例展开,帮助你汲取经验,充分利用 UC 的能力来驱动创新,并实现契合你组织独特需求的各类用例。