1、Left join与标量子查询
Left join:返回包括左表的所有记录和右表满足关联关系的记录,不满足的记录置为空。
标量子查询:子查询返回的是单一值的标量。
Left join和标量子查询关联:left join中右表的关联列如果是唯一值,那么在实际的语句中可以改写成标量子查询。
2、问题语句
css
select *
from (select t1.id,
t1.c1,
sumc2,
rownum rn
from t1
left join (select sum(c2) sumc2,c1 from t2 group by c1) t2
on t1.c1=t2.c1 order by t1.c2 desc) tt
where rn>0
and rn<=25;
执行计划:
1 #NSET2: [36, 25, 20]
2 #PRJT2: [36, 25, 20]; exp_num(4), is_atom(FALSE)
3 #PRJT2: [36, 25, 20]; exp_num(4), is_atom(FALSE)
4 #SORT3: [36, 25, 20]; key_num(1), partition_key_num(0), is_distinct(FALSE), top_flag(0), is_adaptive(0)
5 #TOPN2: [35, 25, 20]; top_num(25), top_off(0)
6 #RN: [35, 100000, 20]
7 #HASH RIGHT JOIN2: [35, 100000, 20]; key_num(1), ret_null(0), KEY(T2.C1=T1.C1)
8 #PRJT2: [17, 500, 8]; exp_num(2), is_atom(FALSE)
9 #HAGR2: [17, 500, 8]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(T2.C1)
10 #CSCN2: [10, 100000, 8]; INDEX33555511(T2); btr_scan(1)
11 #CSCN2: [10, 100000, 12]; INDEX33555509(T1); btr_scan(1)语句的右表(select sum(c2) sumc2,c1 from t2 group by c1) t2与t1表关联的列是c1,已经做分组去重,是具有唯一性,求的是每组c1对应的c2总和(sum)相当于
(select sum(c2) sumc2 from t2 where c1=(t1.c1))。因此我们可以转换成标量子查询如下
css
select *
from (select t1.id,
t1.c1,
(select sum(c2) sumc2 from t2 where t2.c1=t1.c1) sumc2,
rownum rn
from t1 order by t1.c2 desc
) tt
where rn>0
and rn<=25;
执行计划:
1 #NSET2: [12, 25, 24]
2 #PIPE2: [12, 25, 24]
3 #PRJT2: [12, 25, 24]; exp_num(5), is_atom(FALSE)
4 #PRJT2: [12, 25, 24]; exp_num(5), is_atom(FALSE)
5 #SORT3: [12, 25, 24]; key_num(1), partition_key_num(0), is_distinct(FALSE), top_flag(0), is_adaptive(0)
6 #TOPN2: [11, 25, 24]; top_num(25), top_off(0)
7 #RN: [11, 100000, 24]
8 #CSCN2: [11, 100000, 24]; INDEX33555509(T1); btr_scan(1)
9 #SPL2: [1, 1, 8]; key_num(1), spool_num(0), is_atom(TRUE), has_var(1), sites(-)
10 #PRJT2: [1, 1, 8]; exp_num(1), is_atom(TRUE)
11 #AAGR2: [1, 1, 8]; grp_num(0), sfun_num(1), distinct_flag[0]; slave_empty(0)
12 #BLKUP2: [1, 200, 8]; IDX_T2_C1(T2)
13 #SSEK2: [1, 200, 8]; scan_type(ASC), IDX_T2_C1(T2), scan_range[var2,var2], is_global(0)主查询是分页查询,这里分页获取25行,达梦数据库对标量子查询做了延迟计算,我们可以看看autotrace中的情况
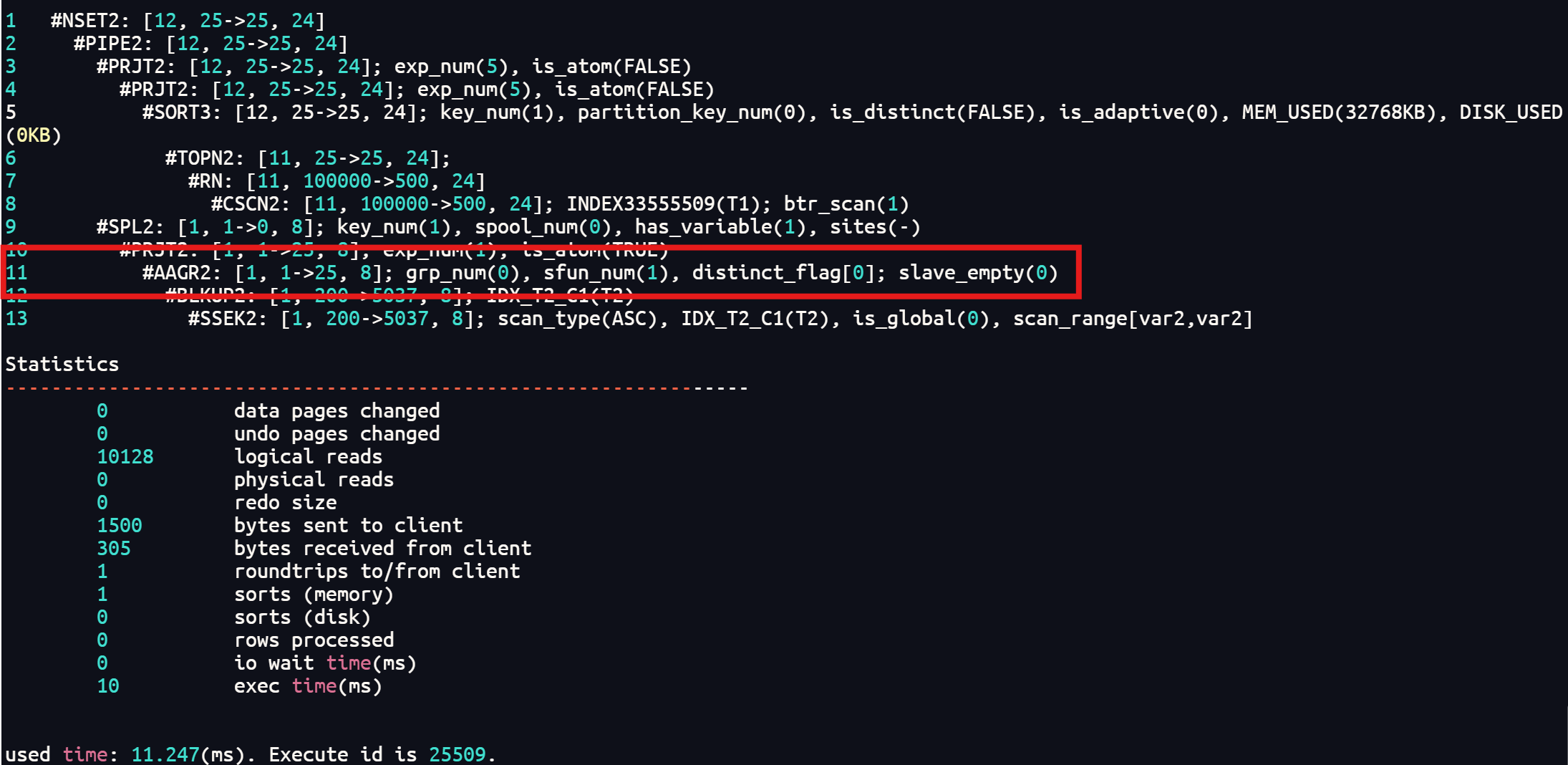
这里可以看到标量子查询只需要获取25行数据的sum值,从而性能得到提升。改写后语句的执行效率提升几倍。
3、达梦数据库对left join做了优化处理
css
select count(*)
from t1
left join (select sum(c2) sumc2,c1 from t2 group by c1) t2
on t1.c1=t2.c1
执行计划:
1 #NSET2: [10, 1, 4]
2 #PRJT2: [10, 1, 4]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [10, 1, 4]; sfun_num(1)语句求count时,我们从left join的理解中可以知道,返回的是左表数据以及右表满足的数据,如果右表关联列没有重复值,数据量其实求的是左表的结果数据量,因此达梦数据库计划中直接去掉右表,而求左表的全部数据就是求counter,就迅速返回结果。
4、小结
语句中做left join,右表的关联列是唯一值,主查询获取的结果集较少,那么改写成标量子查询能够大大提升性能。