1、问题语句
最近遇到一个问题,发现开发人员比较喜欢单一的将表放一块一起做关联。如果有了先过滤后关联的思维,大部分语句的性能会获得提升。
以下是真实项目简化而来的例子
css
select *
from ( select a.c1,
a.mid,
a.bcode,
c.ttime ,
row_number()over(
partition by a.bcode
order by c.ttime desc) rn
from "T11" A,
T12 b,t13 c
where a.id1=b.id1
and a.id1=c.id1(+)
and a.c1=3
and b.c1=3
and b.bcode='0300'
) tt
where tt.rn=1;计划:

该语句最终是获取去重后rn=1(即每组第一行)的数据,而我们分析到t13表数据量很多,这里简单的关联后再去重,性能消耗较多,而优化思路是先t11表和t12表先过滤条件和去重之后,以及t13表去重过滤后,两个小的结果集进行关联,这样性能会提升。因此根据我们的思路进行改写。
2、改写
css
select tt.c1,
tt.mid,
tt.bcode,
b.ttime,
rn
from ( select a.c1,
a.mid,
a.bcode,
a.id1,
row_number()over(
partition by a.bcode
order by null desc) rn
from "T11" A,
T12 b
where a.id1=b.id1
and a.c1=3
and b.c1=3
and b.bcode='0300') tt,(select max(ttime) ttime,id1 from t13 group by id1) b
where tt.rn=1
and tt.id1=b.id1(+);计划:
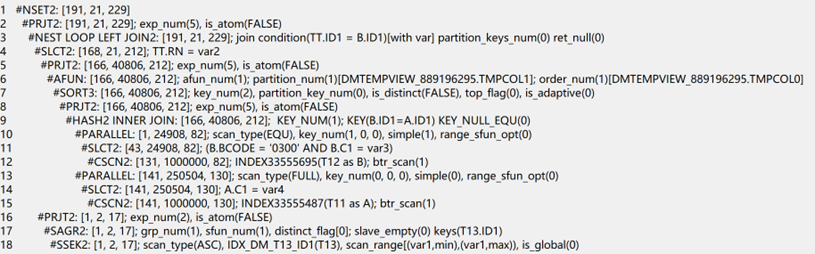
最终性能提升了几倍,在项目中的数据较多,原本语句也复杂,改写后从原来跑20分钟,到最终秒级执行完。
3、小结
我们一般要先过滤出小结果集再关联,相当于我们先分组减去重复的部分,减少对比次数,从而提升效率。