拥塞控制对于理解网络如何稳定、高效地运行至关重要。
那什么是拥塞控制呢?我们为什么需要它呢。
什么是拥塞控制
1. 拥塞的定义:
网络中的负载 (发送到网络中的数据包)超过了网络的处理能力(路由器、链路等的容量),导致网络性能急剧下降的现象。
2. 拥塞的后果:
-
数据包时延急剧增加:路由器队列变长。
-
数据包丢失:路由器队列满,新到的数据包被丢弃。
-
上层应用性能下降:吞吐量降低,延迟抖动。
-
拥塞崩溃:极端情况下,网络有效吞吐量趋近于零,因为大量资源被用于传输最终会被丢弃的数据包。
吞吐量在这里我们拓展一下:
网络吞吐量 (throughput)是单位时间内 网络能够传输的有效数据量,通常以比特每秒(bps)或其子单位(kbps、Mbps、Gbps)来表示。它反映了实际传输速度,而不仅仅是理论带宽。
(带宽 是一个网络链路在理论上能够达到的最高数据传输速率,通常以比特每秒(bps)表示。用来描述"容量上限 "或"通道的最大传输能力",就像水管的直径决定了水流的最大速度。)
影响吞吐量的因素:
- 物理层带宽:链路的理论上限,如光纤、以太网速率。
- 信道利用率:协议头、数据包大小、重传、拥塞控制等导致的有效载荷比例。
- 延迟与往返时间(RTT):高延迟会增加等待时间,降低总体吞吐量(尤其在长距离通信中)。
- 丢包与重传:丢包率高时需要重新传输,显著降低吞吐量。
- 拥塞控制与排队:路由器/交换机队列长度、排队时延、拥塞窗口调节策略(如 TCP 的拥塞控制)。
- 误码率与错误重传:物理层误码高会降低有效传输数据比例。
- 共享介质与并发性:同一链路上多用户竞争资源会降低单用户吞吐量。
- 设备性能:端点设备、网卡、CPU、内存等对协议处理与缓冲能力有影响。
- 应用层因素:数据打包策略、加密开销、压缩等对实际可用吞吐量的影响。
好我们回归拥塞控制。
打个比方 分清流量控制 和拥塞控制的区别:
-
流量控制:就像仓库(接收方)告诉供应商(发送方):"我的仓库快满了,你慢点送货。"
-
拥塞控制:就像交通管理部门(发送方自己)发现高速公路(网络)堵车了,于是主动限制上高速的车辆数量。
拥塞控制的核心思想与核心变量
TCP 拥塞控制的根本思想是:每个发送方都通过观察网络的反馈(主要是数据包丢失)来探测网络的可用带宽,并据此动态调整自己的发送速率。
为了实现这一目标,TCP 为每个连接维护了两个核心变量:
-
拥塞窗口(cwnd - Congestion Window):
-
这是发送方根据自己感知到的网络拥塞程度而设置的发送数据量的限制。
-
发送方在任何时刻,未被确认的数据量(在途字节数)不能超过 min(cwnd, 接收方通告窗口)。
-
cwnd 是动态变化的,是拥塞控制的核心操作对象。
-
-
慢启动阈值 (ssthresh - Slow Start Threshold):
-
这是一个阈值,用于决定使用慢启动算法 还是拥塞避免算法。
-
当 cwnd < ssthresh 时,使用慢启动。
-
当 cwnd >= ssthresh 时,使用拥塞避免。
-
TCP拥塞控制算法主要有四个。
TCP 拥塞控制的四个主要算法
TCP 拥塞控制不是一个单一的算法,而是四个相互协作的算法的组合。其经典实现通常被称为 Tahoe 和 Reno,我们以最经典的 Reno 为例进行讲解。
慢启动(Slow Start)
目标: 在连接刚开始或从拥塞中恢复时,快速探测网络的可用带宽。
过程:
-
初始时,cwnd 被设置为一个很小的值(例如 1 个 MSS - Maximum Segment Size(最大报文段尺寸,简称MSS))。
-
发送方每收到一个 新的 ACK ,cwnd 就增加 1 个 MSS。
-
第1次RTT:发送1个报文,收到1个ACK -> cwnd = 2
-
第2次RTT:发送2个报文,收到2个ACK -> cwnd = 4
-
第3次RTT:发送4个报文,收到4个ACK -> cwnd = 8
-
-
可以看到,cwnd 以指数级增长(每轮 RTT 翻倍)。
结束条件:
-
当 cwnd 增长到 ssthresh 时,转为拥塞避免阶段。
-
如果发生超时,则认为网络出现了严重拥塞。
拥塞避免(Congestion Avoidance)
目标: 当 cwnd 达到一定规模后,从指数增长转为线性增长,谨慎地探测更多可用带宽,避免很快再次引发拥塞。
过程:
-
此时,发送方每收到一个 新的 ACK ,cwnd 增加 1 / cwnd 个 MSS。
- 例如,当前 cwnd = 10,那么每收到一个 ACK,cwnd 增加 1/10 MSS。需要收到 10 个 ACK 后,cwnd 才增加 1 个 MSS。
-
因此,cwnd 以线性增长(每轮 RTT 增加 1 个 MSS)。
3. 快速重传(Fast Retransmit)
背景: 传统的超时重传等待时间太长(RTO 通常较大)。为了更快地修复丢包,引入了快速重传。
过程:
-
如果接收方收到一个失序的报文段(例如,期望收到 seq=5,但收到了 seq=6),它会立即重复发送一个对于最后一个按序字节的 ACK(即再次 ACK seq=4)。
-
当发送方连续收到 3 个重复的 ACK 时,它就有理由认为这个被重复 ACK 的报文段(seq=5)丢失了,而不是因为网络重新排序。
-
于是,发送方不等超时计时器到期,立即重传这个被认为丢失的报文段。
4. 快速恢复(Fast Recovery)
目标: 在快速重传之后,平滑地降低发送速率并恢复,而不是一下子退回到慢启动。这是 Reno 与早期 Tahoe 的主要区别。
过程:
-
当发生快速重传(收到 3 个重复 ACK)时:
-
将 ssthresh 设置为 cwnd / 2(至少为 2)。
-
(可选,但 Reno 通常这么做)将 cwnd 设置为 ssthresh + 3(因为收到了 3 个重复 ACK,意味着有 3 个数据包已经离开了网络到达了接收方)。
-
然后进入快速恢复阶段。
-
-
在快速恢复阶段:
-
每收到一个重复的 ACK,cwnd 就增加 1 个 MSS(因为这意味着又有一个数据包离开了网络)。
-
当收到一个新的 ACK(即对重传报文段以及之后数据的确认)时,表明重传成功,网络开始正常交付数据。
-
此时,将 cwnd 设置为 ssthresh,然后转入拥塞避免阶段。
-
为什么是快速"恢复"?
因为它没有像超时那样将 cwnd 重置为 1,而是降到了一个更温和的值(ssthresh)并直接开始拥塞避免,从而保持了较高的吞吐量。
完整流程
阶段 1:慢启动 (Slow Start)
-
起点:连接建立或发生超时后
-
初始值:cwnd = 1 MSS,ssthresh = 16 MSS
-
增长方式:每收到一个ACK,cwnd增加1 MSS
-
效果:每个RTT时间,cwnd翻倍(指数增长)
-
结束条件:当 cwnd 达到 ssthresh 时转入拥塞避免
阶段 2:拥塞避免 (Congestion Avoidance)
-
起点:cwnd ≥ ssthresh
-
增长方式:每收到一个ACK,cwnd增加 1/cwnd MSS
-
效果:每个RTT时间,cwnd增加约1 MSS(线性增长)
-
结束条件:检测到数据包丢失**
阶段 3:快速重传与快速恢复 (Fast Retransmit & Recovery)
-
触发条件:收到3个重复ACK
-
动作:
-
立即重传丢失的数据包
-
ssthresh = 当前cwnd / 2
-
cwnd = ssthresh + 3(因为有3个数据包已离开网络)
-
进入快速恢复阶段
-
阶段 4:超时处理 (Timeout)
-
触发条件:重传计时器超时(严重拥塞)
-
动作:
-
ssthresh = 当前cwnd / 2
-
cwnd = 1 MSS
-
重新开始慢启动
-
以下是完整流程图:
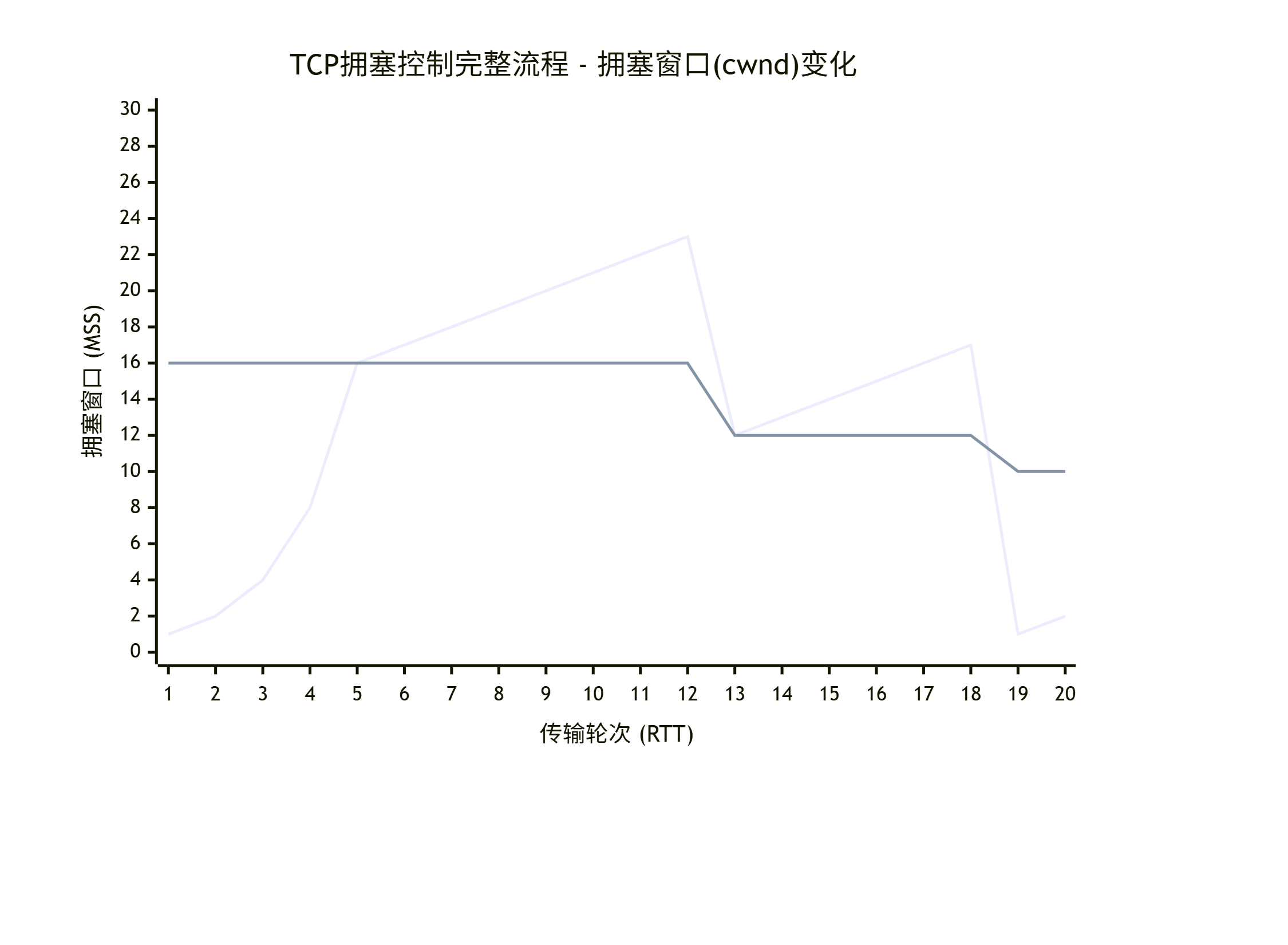
阶段讲解
📈 第1-4轮次:慢启动阶段
-
起点:cwnd = 1 MSS,ssthresh = 16 MSS
-
增长:指数增长 1 → 2 → 4 → 8 → 16
-
特点:快速探测网络可用带宽
📈 第5-12轮次:拥塞避免阶段
-
转换:当 cwnd = ssthresh = 16 时转入拥塞避免
-
增长:线性增长 16 → 17 → 18 → ... → 23
-
特点:谨慎增加,避免引发拥塞
⚡ 第12轮次:快速重传与恢复
-
事件:检测到3个重复ACK(单个丢包)
-
动作:
-
ssthresh = 23 / 2 ≈ 12
-
cwnd = 12 + 3 = 15(实际图中显示为12,简化表示)
-
-
结果:平滑降速,保持较高吞吐量
📈 第13-18轮次:重新进入拥塞避免
-
恢复:从 cwnd = 12 开始线性增长
-
增长:12 → 13 → 14 → 15 → 16 → 17
💥 第18轮次:超时事件
-
事件:重传计时器超时(严重拥塞)
-
动作:
-
ssthresh = 17 / 2 ≈ 10
-
cwnd = 1(重置为最小值)
-
-
结果:激进降速,重新开始慢启动
📈 第19-20轮次:重新慢启动
-
恢复:从 cwnd = 1 重新开始指数增长
-
增长:1 → 2 → ...(继续循环)
小结
🔄 两种增长模式:
-
指数增长(慢启动):快速探测带宽
-
线性增长(拥塞避免):谨慎增加带宽
⚠️ 两种丢包响应:
-
快速恢复(3个重复ACK):温和降速,cwnd = ssthresh
-
超时处理(计时器超时):激进降速,cwnd = 1
🎯 核心思想:
-
"大胆试探":通过慢启动快速找到网络容量边界
-
"小心求证":通过拥塞避免谨慎增加带宽
-
"遇挫则退":通过丢包反馈及时降低发送速率
这种巧妙的机制使得TCP能够在未知的网络环境中自动调整发送速率,既充分利用带宽,又避免造成网络拥塞崩溃。
Tahoe 和 Reno的区别
它们的核心区别在于对快速重传后处理方式的不同。
-
Tahoe
- 任何丢包都是严重拥塞的信号,必须激进地减速。没有快速重传的阶段。
- 当收到3个重复ACK时
*- 执行快速重传。
-
- 将 ssthresh 设置为 当前cwnd / 2。
-
- 将 cwnd 重置为 1。
-
- 重新进入慢启动阶段。
- 单个丢包就会导致吞吐量断崖式下跌,在高延迟或易丢包网络中性能不佳。
-
Reno
- 区分拥塞程度:超时是严重拥塞,重复ACK是轻微拥塞。
- 当收到3个重复ACK时
*- 执行快速重传。
-
- 将 ssthresh 设置为 当前cwnd / 2。
-
- 将 cwnd 设置为 ssthresh + 3 (或 ssthresh)。
-
- 进入快速恢复阶段。
- 在发生单个丢包时,性能更好,吞吐量下降更少。
- 在多个 数据包丢失时,可能无法有效恢复,需要等待超时 。
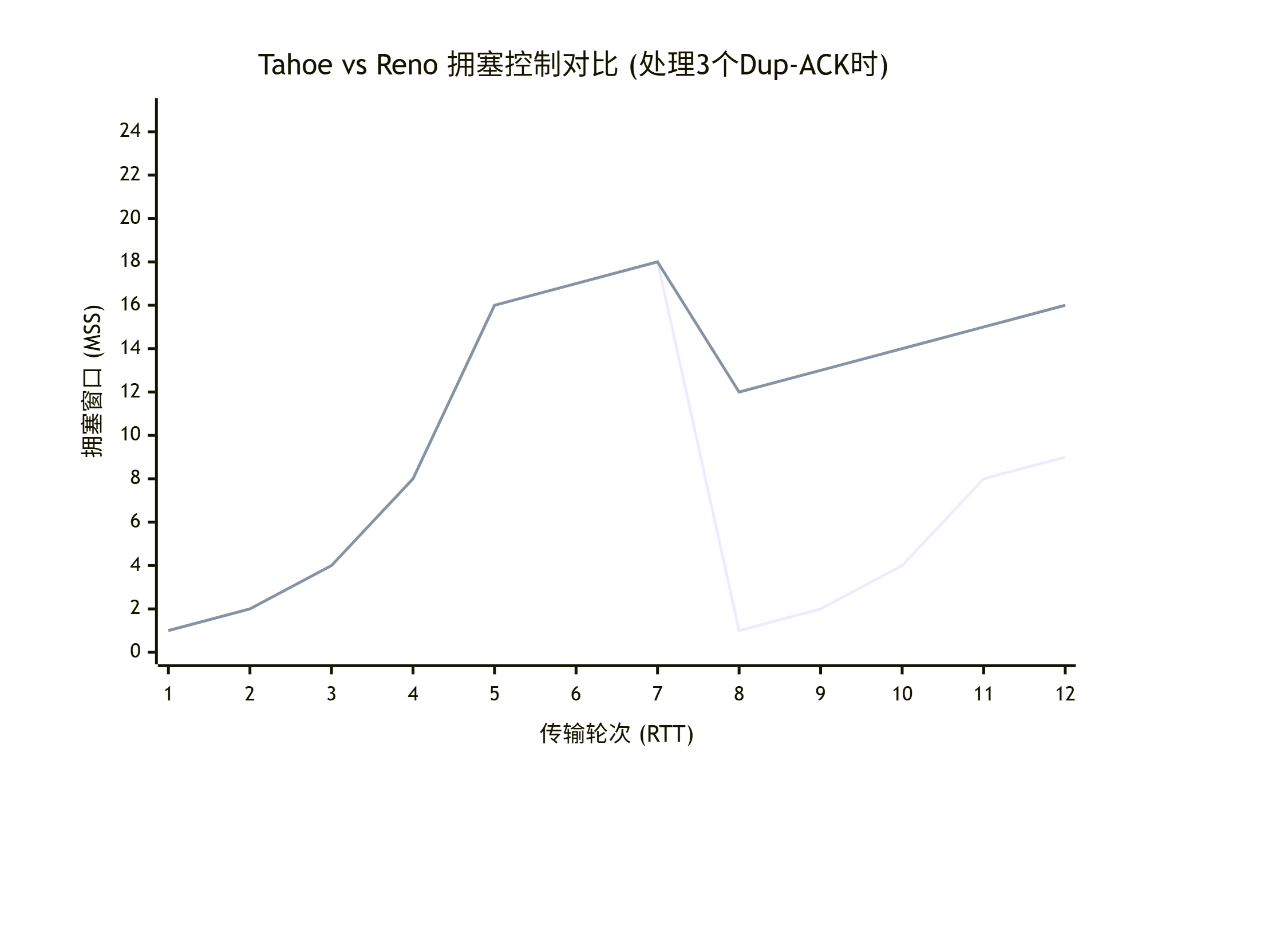
Tahoe 的反应(浅色折线)
-
第7轮次:cwnd 在拥塞避免阶段增长到 18。
-
第8轮次:检测到3个重复ACK,立即采取行动:
-
ssthresh = 18 / 2 = 9
-
cwnd = 1 (断崖式下跌)
-
重新开始慢启动。
-
-
第8-11轮次:cwnd 从1开始指数增长,直到再次达到 ssthresh=9。
-
第12轮次 :达到 ssthresh,重新进入拥塞避免。
Reno 的反应(深色折线)
-
第7轮次:cwnd 在拥塞避免阶段增长到 18。
-
第8轮次:检测到3个重复ACK,立即采取行动:
-
ssthresh = 18 / 2 = 9
-
cwnd = ssthresh = 9 (平滑下降)
-
进入快速恢复 ,随后立即转入拥塞避免。
-
-
第9-12轮次 :cwnd 从9开始线性增长。
当然Reno 及其改进版本是现代操作系统中最常见的。
后续发展与改进
经典的 Reno 算法在应对单个丢包时表现良好,但在多个包丢失或无线网络等高丢包率环境下性能会下降。因此,出现了许多改进版本:
-
New Reno: 对 Reno 的快速恢复进行了改进,它延长了快速恢复阶段,直到所有在丢失发生时已发出的数据包都被确认后,才退出快速恢复。能够在一个 RTT 内恢复多个丢失的包。
-
选择性确认(SACK) : 通过在TCP头选项中携带更多关于接收情况的信息,告知发送方所有成功接收的报文段范围,使得发送方能更精确地知道哪些包丢失,从而只重传丢失的包。
-
BIC 与 CUBIC: Linux 内核中长期使用的默认算法。CUBIC 使用一个三次函数来管理 cwnd 的增长,在高带宽长延迟网络中比 Reno 更加高效和公平。
-
BBR: 由 Google 提出的全新拥塞控制算法。它不再以丢包作为拥塞的主要信号,而是通过测量链路的最小RTT和最大带宽来构建一个模型,试图使网络运行在延迟最低且带宽最高的最优点上。
小结
| 机制 | 触发条件 | 主要动作 | 目标 |
|---|---|---|---|
| 慢启动 | 连接开始、超时 | cwnd 指数增长 | 快速探测带宽 |
| 拥塞避免 | cwnd >= ssthresh | cwnd 线性增长 | 谨慎探测,避免拥塞 |
| 快速重传 | 收到3个重复ACK | 立即重传丢失包 | 减少等待时间 |
| 快速恢复 | 快速重传之后 | cwnd 降为 ssthresh 后进入拥塞避免 | 平滑恢复,避免吞吐量骤降 |
| 超时处理 | 重传计时器超时 | cwnd 重置为1,ssthresh减半 | 应对严重拥塞 |