Hudi系列:Hudi核心概念(版本1.0)
•Hudi架构
◦一. 时间轴(TimeLine)s
▪1.1 时间轴(TimeLine)概念
▪1.2 Hudi的时间线由组成
▪1.3 时间线上的Instant action操作类型
▪1.4 时间线上State状态类型
▪1.5 时间线官网实例
◦二. 文件布局
◦****三. 索引
3.1 简介
3.2 对比其它(Hive)没有索引的区别
3.2 多态索引
布隆过滤器
记录索引
表达索引
二级索引
3.3写入端的索引类型
3.4 全局索引与非全局索引
四. 表类型
4.1 COW:(Copy on Write)写时复制表
4.1.1概念
4.1.2 COW工作原理
4.1.3 COW表对表的管理方式改进点
4.2 MOR:(Merge on Read)读时复制表
4.2.1 概念
4.2.2 MOR表工作原理
4.3 总结了两种表类型之间的权衡
五. 查询类型
四、简介
Hudi 表类型定义了数据的存储方式以及如何在表上执行写入操作(即如何写入数据)。反过来,查询类型定义了如何将底层数据暴露给查询(即如何读取数据)。
sql
Hudi 引入了以下目前已在业界广泛使用的表类型,根据实际情况权衡取舍。
Copy On Write :Merge On Read:读取时合并 (MoR) 表类型通过使用定期压缩将轻量级日志文件与基础文件合并,从而平衡写入和读取性能。
数据更新和删除操作会写入日志文件(以基于行的格式,例如 Avro 或列式/基础文件格式),然后在查询执行期间将日志文件中的这些更改与基础文件动态合并。这种方法降低了写入延迟,
并支持近乎实时的数据可用性。但是,查询性能可能会因日志文件是否压缩而有所不同。
核心事务功能(例如原子写入、索引)以及独特的新功能(例如增量查询、自动文件大小调整和可扩展表元数据跟踪)均在两者中提供,且与表类型无关。4.1Copy On Write Table
4.1概念
scss
写时复制 (COW) 表类型针对读取密集型工作负载进行了优化。在此模式下,记录更新或删除会触发在文件组中创建新的基础文件,并且不会写入日志文件。这确保每个查询仅读取基础文件,从而提供
较高的读取性能,而无需动态合并日志文件。虽然 COW 表非常适合 OLAP 扫描/查询,但由于在更新或删除期间重写基础文件的开销,即使每个文件中只修改了少量记录,它们的写入操作也可能较慢。
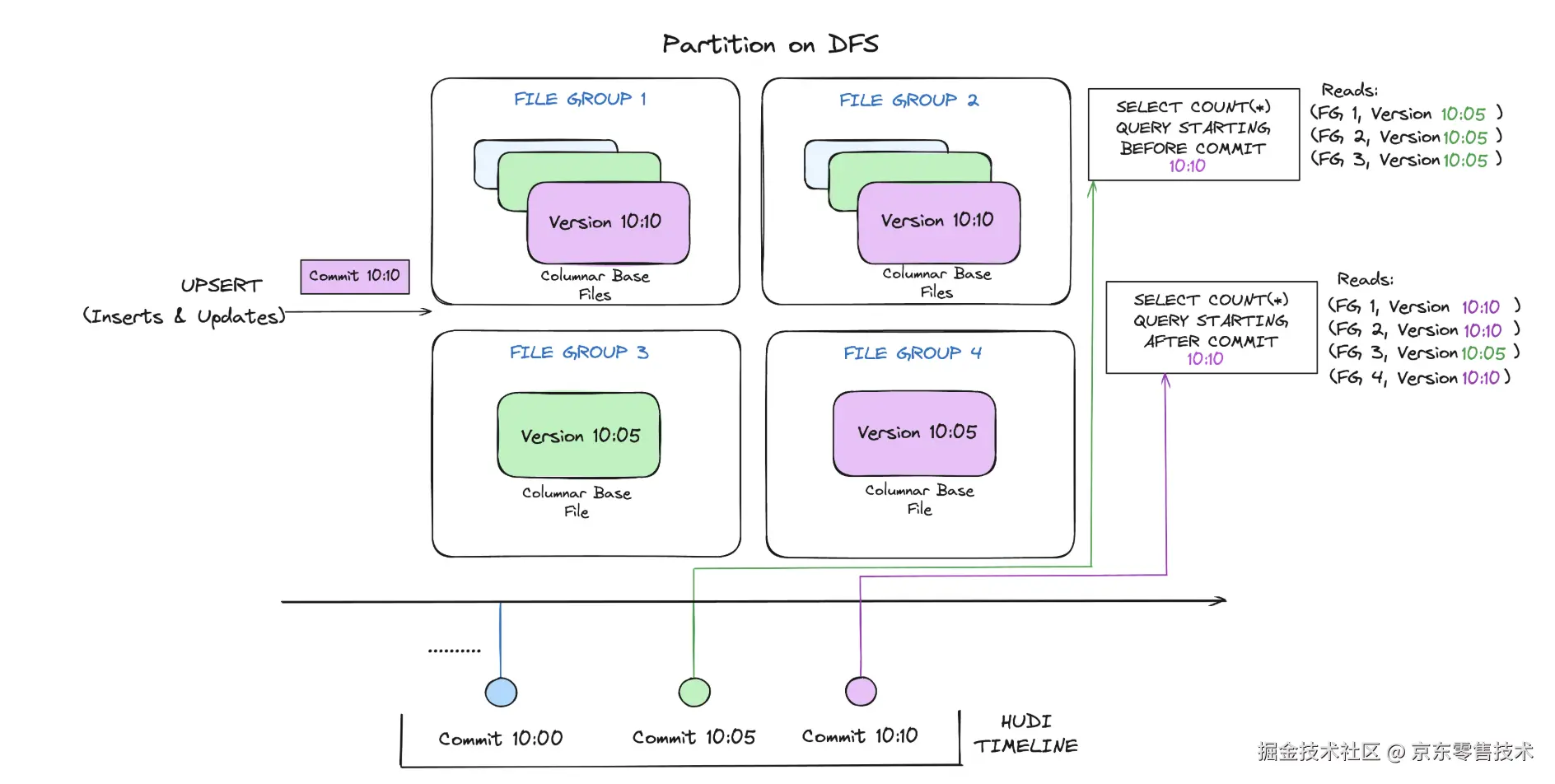
下面从概念上说明了当数据写入时复制表并在其上运行两个查询时其工作原理。4.1.2COW工作原理
sql
随着数据的写入,对现有文件组的更新会为该文件组生成一个新的切片,并标记与提交请求的时刻相关联;而插入操作则会分配一个新的文件组,并为该文件组写入其第一个切片。
这些文件切片及其提交完成的时刻已在上方以同一颜色编码。针对上图 SQL 查询首先检查已完成写入的时间线,并过滤每个文件组除最新文件切片之外的所有文件切片。如您所见,较旧的查询不会看到
当前正在进行的提交的文件(以粉红色编码),但提交后启动的新查询会获取新数据。因此,查询不会受到任何写入失败/部分写入的影响,并且只会读取已提交的数据。4.1.3 COW表对表的管理方式改进点
1.在原有文件上进行自动更新数据,而不是重新刷新整个表/分区
2.能够只读取修改部分的数据,而不是浪费查询无效数据
3.严格控制文件大小来保证查询性能(小文件会显著降低查询性能)
4.2 Merge On Read Table
4.2.1概念
scss
读取时合并 (MOR) 表类型通过使用定期压缩将轻量级日志文件与基文件合并,从而平衡写入和读取性能。数据更新和删除操作会写入日志文件(以基于行的格式,例如 Avro 或列式/基文件格式),
然后在查询执行期间将日志文件中的这些更改动态地与基文件合并。这种方法可以降低写入延迟并支持近乎实时的数据可用性。但是,查询性能可能会因日志文件是否被压缩而有所不同。4.1.2MOR工作原理
下面说明了 MOR 表的工作原理,并展示了两种类型的查询 - 快照查询和读取优化查询。
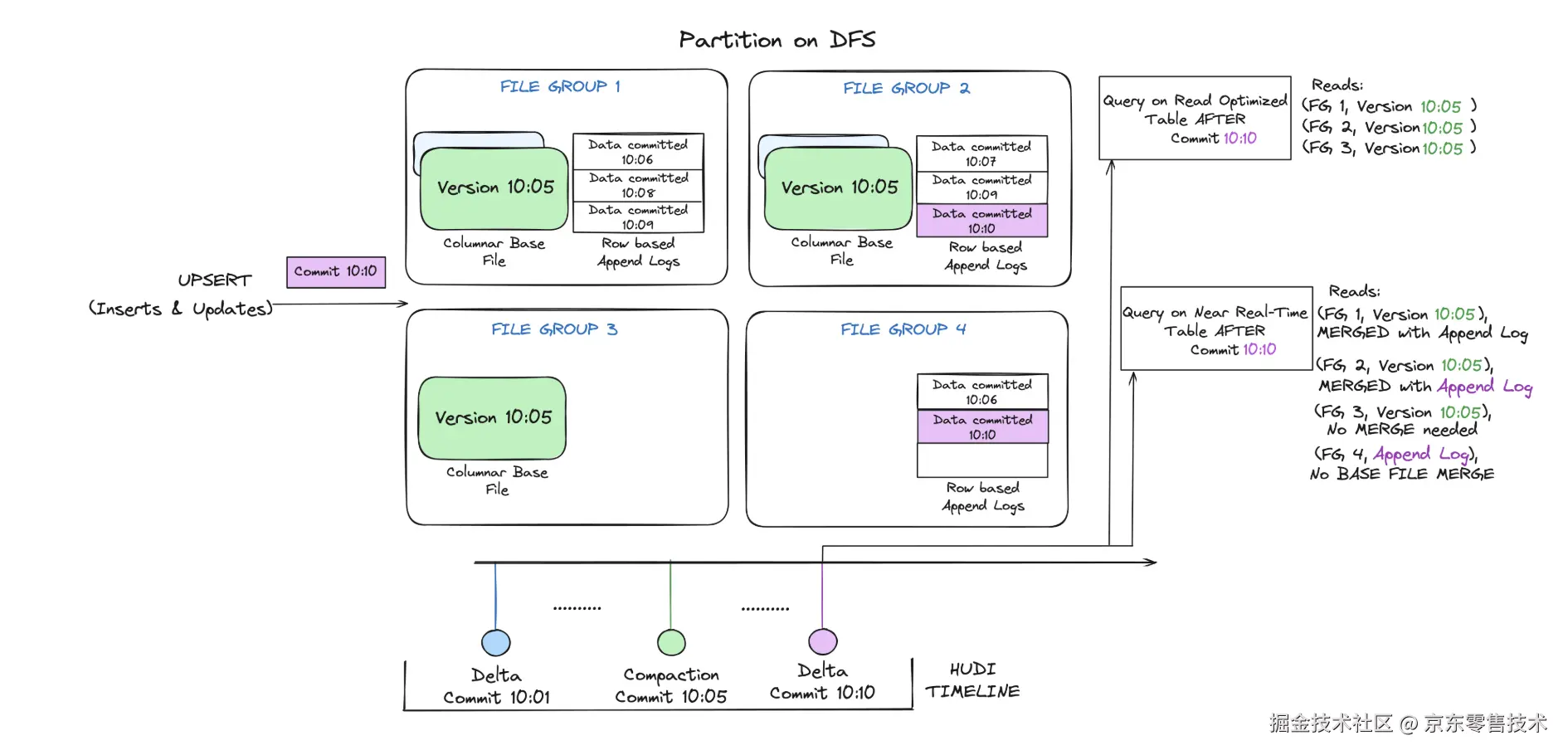
这个例子中发生了很多有趣的事情,方法出方法的微妙之处。
erlang
1)如上图所示,可以做到每一分钟提交一次写入操作
2)查询表的方式有两种,Read Optimized query和Snapshot query,取决于我们选择是要查询性能还是数据最新
3)如上图所示,Read Optimized query查询不到10:05之后的数据(查询不到增量日志里的数据,没有合并到base文件),而Snapshot query则可以查询到全量数据(基本列数据+行式的增量日志数据)4.3总结两种表的类型之前的权衡
| 权衡 | 写时复制COW | 读取时合并MOR |
|---|---|---|
| 写入延迟 | 更高 | 降低 |
| 查询延迟 | 降低 | 更高 |
| 更新成本 | 更高(重写整个基础文件) | 较低(附加到增量日志) |
| 基本文件大小 | 需要更小以避免高更新(I/0)成本 | 可以更大,因为更新成本很低且可以摊销 |
| 读取放大 | 0 | 对于查询读取的文件组:O(records_changed) |
| 写入放大 | 对于给定的更新/删除模式,最高为O(file_groups_written) | 对于写入的文件组:O(records_changed) |
五. 查询类型
•Snapshot Queries:查询会查看截至最新完成操作的最新表快照。这些是每个人都习惯在表上运行的常规 SQL 查询。Hudi 存储引擎会在支持的查询引擎上尽可能使用索引来加速这些快照查询。
•Time Travel Queries:查询过去某个时刻的表快照。时间旅行查询有助于访问表的多个版本(例如,机器学习特征存储,用于根据用于训练算法/模型的精确数据对其进行评分),这些版本位于活动时间线中的某个时刻或过去的保存点。
•Read Optimized Queries (Only MoR tables):读优化查询通过纯列式文件(例如Parquet 基础文件)提供出色的快照查询性能。用户通常使用与事务边界一致的压缩策略,以提供表/分区的旧一致性视图。这对于集成来自数据仓库的 Hudi 表非常有用,因为这些数据仓库通常仅将列式基础文件作为外部表进行查询,或者对于延迟不敏感、更注重效率而非数据新鲜度的 ML/AI 训练作业。
• Incremental Queries (Latest State):增量查询仅返回自时间轴上某一时刻以来写入表的新数据。提供自表的给定时间点以来插入/更新的记录的最新值(即,查询为每个记录键输出一条记录)。可用于比较两个时间点之间的表状态差异。
•Incremental Queries(CDC):这是另一种增量查询,它提供类似数据库的 Hudi 表变更数据捕获流。CDC 查询的输出包含自某个时间点或两个时间点之间插入、更新或删除的记录,以及每条变更记录的前后图像,以及导致变更的操作。
| 权衡 | Snapshot | Read Optimized |
|---|---|---|
| 数据延迟 | 降低 | 更高 |
| 查询延迟 | 更高(合并基础/列式文件 + 基于行的增量/日志文件) | 较低(原始基/柱状文件性能) |