
先看几个令人心动又让钱包一紧的 GPU 型号:NVIDIA A100 80GB、H800 80GB、RTX 4090 24GB...

这些 AI 时代的"超级马力",无论我们是砸钱买断,还是花高价租用,都只能整块拿下。可除了模型训练,更多时候只是用来跑推理、开发/测试环境,几十上百 GB 的显存真的全能派上用场吗?多数情况下,你的 GPU 算力其实都在"摸鱼",利用率可能连 20% 都不到。
在算力就是钞票的 AI 时代,GPU 闲置哪是"摸鱼",这分明是"撒币"行为。
- 如果你是 AI 团队的 Leader,一边要交代高昂算力开销,一边还要安抚抱怨"GPU 不够、流程太慢"的团队成员,是不是早已身心俱疲?
- 如果你是 MLOps 或平台工程师,每天盯着 GPU 集群利用率长期低于 20%,还得处理各种"抢资源"工单,是不是觉得自己的技术没用在刀刃上?
- 如果你是 AI 算法工程师,只是想跑个预处理、验证模型、调试代码,却要为一张被"霸占"却没被用满的 A100/H800 排队数小时,灵感都快被磨光了吧?
别急,今天的主角------HAMi,就是你的"开源解药"!
GitHub 地址:github.com/Project-HAM...
简单来说,HAMi 是由上海密瓜智能发起的,面向 K8s 的异构 AI 计算虚拟化中间件。它的核心能力,就是像切蛋糕一样,把一整块物理 GPU 灵活切分为多块虚拟 GPU(vGPU),并按需分配给不同业务(Pod),实现算力的精细化共享与隔离。
最关键的是,你的 AI 应用代码,一行都不用改!
一、GPU 共享的两个"陷阱",为何需要 HAMi?
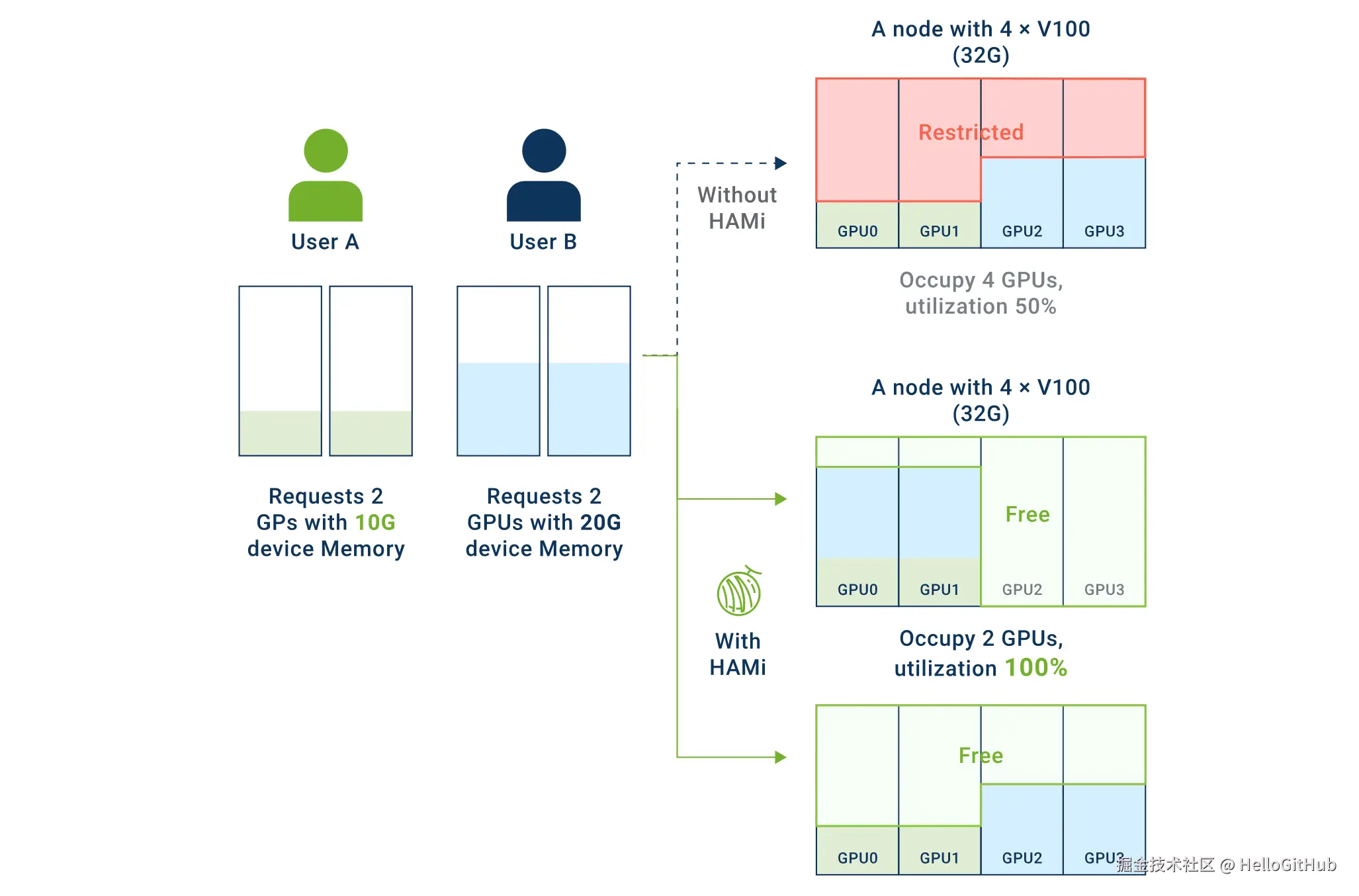
要理解 HAMi 的价值,我们首先要明白一块 GPU 包含了两种核心资源:显存 (Memory) 和计算核心 (Compute Cores)。在没有管理机制的"原生共享"模式下,这两种资源都会陷入困境:
- 显存的"独占性"(OOM 问题):GPU 显存是一个"硬性资源"。一个程序启动时,必须先申请到足够的显存空间来加载模型和数据。在原生共享模式下,这就是一场"先到先得"的游戏。
- 算力的"混沌竞争"(性能问题):即便多个任务都成功挤进了显存,它们接下来也要争抢有限的算力核心。这就像一场没有规则的"大乱斗"。一个计算密集型任务可能会在某个瞬间霸占几乎所有的计算资源,导致其他任务被"饿死",响应变得极慢。
面对以上两个陷阱,HAMi 提供了精准且优雅的解决方案。它能同时对显存和算力进行精细化切分和管理:
对于显存:实现"硬性隔离"
HAMi 会为每个任务划分出一段完全独立的、大小固定的虚拟显存空间。每个任务只能在自己的"包间"里活动,彻底杜绝了因某个任务过度占用而导致其他任务无法启动的 OOM 问题。
对于算力:实现按比例分配
HAMi 允许你为每个任务分配特定比例的算力(例如,为 A 任务(pod)分配 30% 的算力,B 任务 50%)。确保每个任务都能获得其应有的计算资源,从而保障性能的稳定和可预期,告别"性能抖动"。
总结一下,HAMi 可以将 GPU 从一个混乱、不可预测的"公共资源",转变为多个独立、稳定、可度量的"私有资源",这就是它实现 GPU 高效利用的核心所在。
搞懂了这一点,我们再来看 HAMi 在 K8s 里的操作,你就会觉得豁然开朗。
二、三步搞定,简单到不像话!
在我们熟悉的 K8s 环境里,GPU 一直是个"倔强的老顽固"------一个 Pod 就得独占一整张卡,申请 GPU 资源也只能按"卡"来。
但 HAMi 的出现,彻底改变了这一游戏规则。
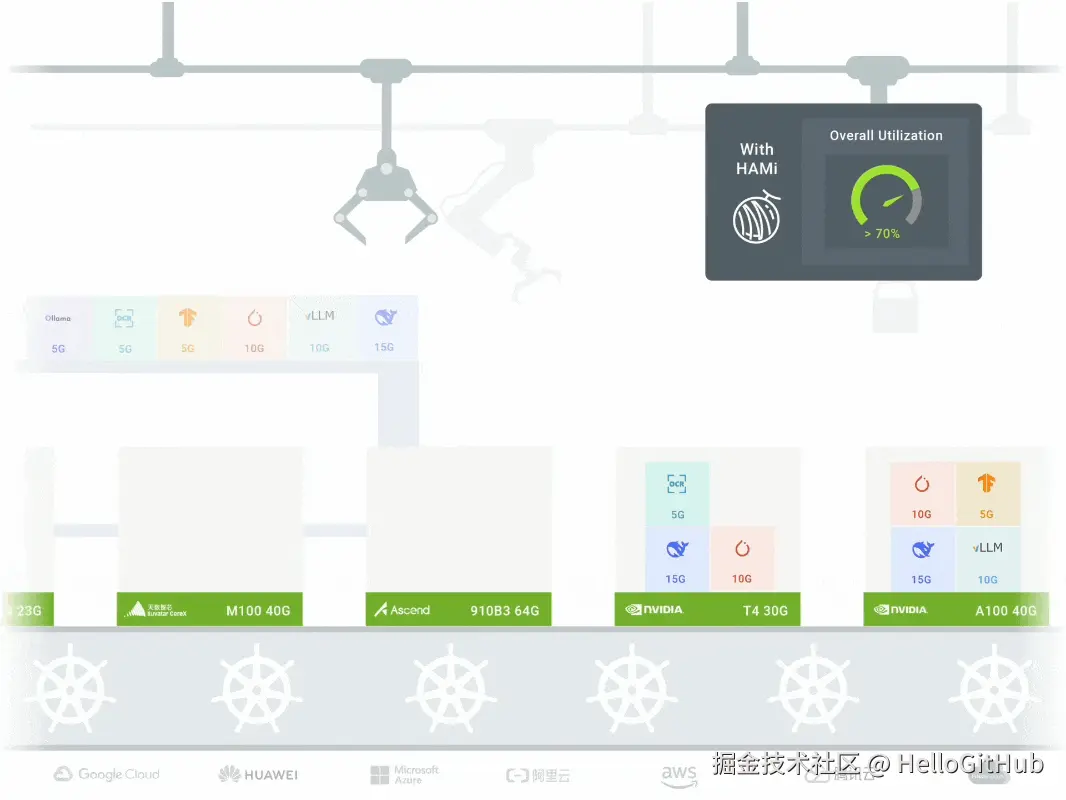
有了 HAMi,你可以像点菜一样,随心为 AI 应用选配告别 GPU 资源浪费,比如「1GB 显存、30% 算力」。
别看功能这么牛,但安装 HAMi 却超级简单。它就像 K8s 的即插即用扩展包,用 Helm 工具三条命令搞定:
csharp
# 1. 先给你有 GPU 的机器打个标签,让 HAMi 认识它
kubectl label nodes {nodeid} gpu=on
# 2. 添加 HAMi 的官方"菜单"
helm repo add hami-charts https://project-hami.github.io/HAMi/
# 3. 下单安装!
helm install hami hami-charts/hami -n kube-system搞定!看到 hami-device-plugin 和 hami-scheduler 这两个 Pod 都正常地 Running 起来,就说明你已经成功化身"GPU 管理大师"了。
以后,你就可以用下面的配置,为你的 AI 应用轻松+愉快地申请任意大小的 vGPU 了。
yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 1 # 申请 1 个 vGPU
nvidia.com/gpumem: 1024 # 每个 vGPU 包含 1024MB 设备内存
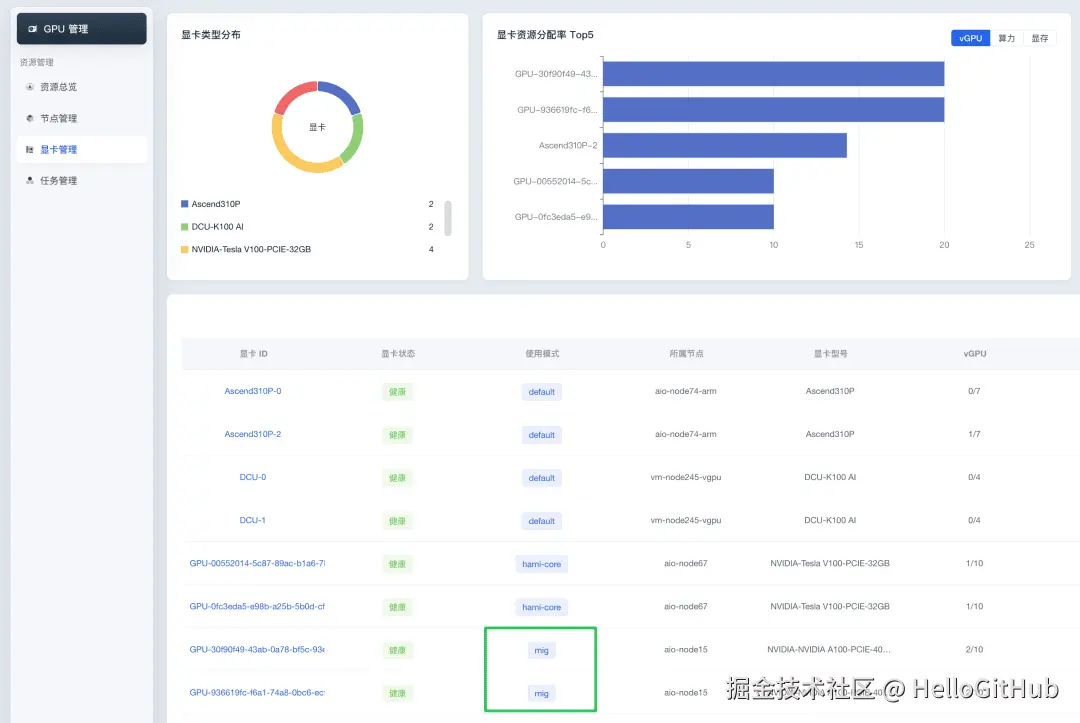
nvidia.com/gpucores: 30 # 每个 vGPU 分配 30% 的计算核心此外,官方还贴心地准备了可视化界面 HAMi-WebUI,让摸鱼的 GPU 无所遁形!
三、揭秘 HAMi 技术核心,个人开发者也能玩转!
你肯定好奇,HAMi 到底用了什么黑科技,竟然能瞒天过海,"骗"过 CUDA,让程序觉得自己拥有一整块 GPU?
答案全在它的核心武器:HAMi-core。
这玩意儿的原理,说白了,就是"欺上瞒下"的高级玩法。
3.1 HAMi 核心原理
HAMi-core 本质上是一个实现了 CUDA API Hook(钩子)的动态链接库 (libvgpu.so)。它的工作原理非常巧妙,也十分经典:
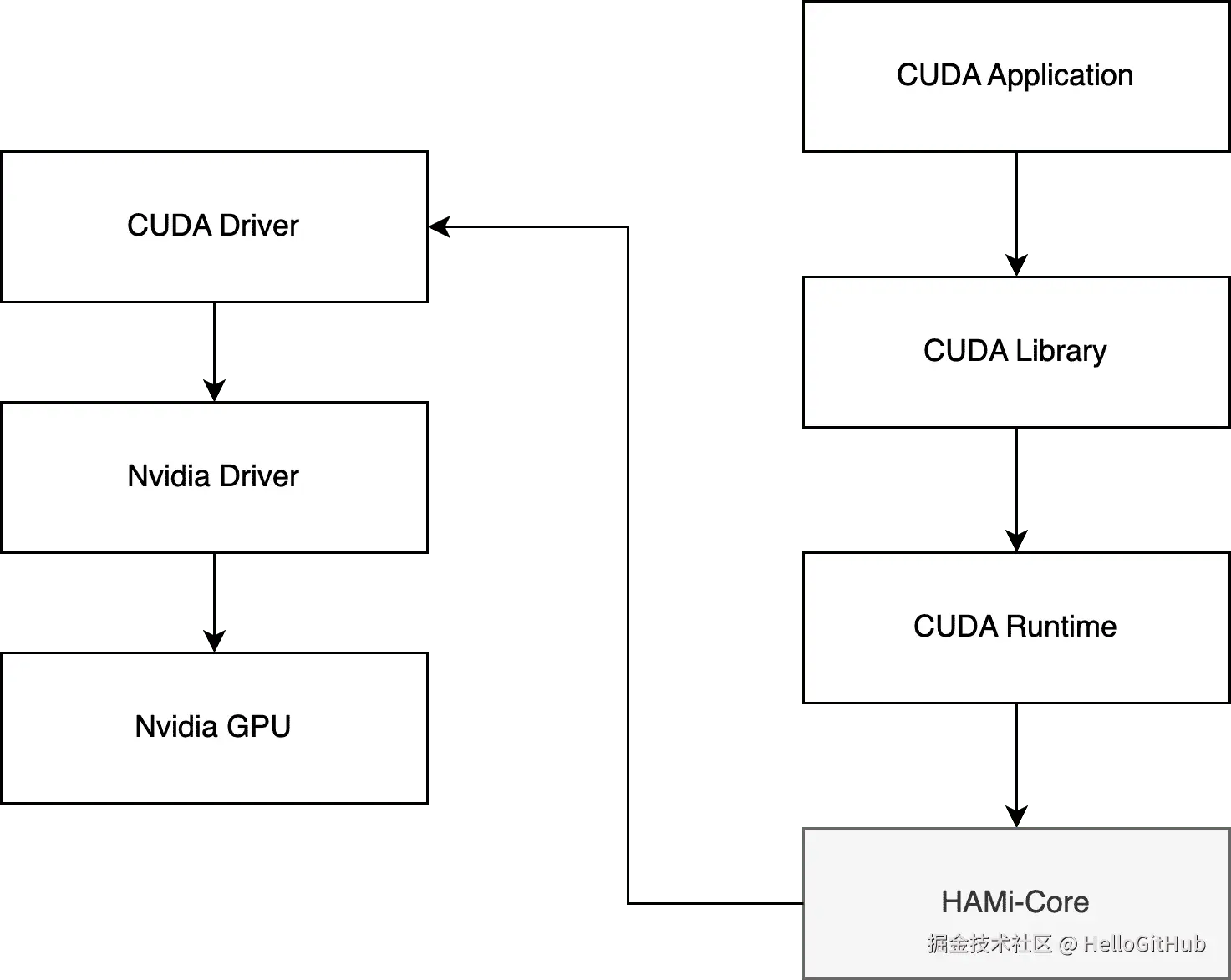
如上图所示,它通过 LD_PRELOAD 环境变量,在你的应用程序和真正的 CUDA 驱动之间"插入"了自己。当你的程序调用一个 CUDA API(比如申请显存)时,HAMi-core 会先"劫持"这个请求,然后根据你设置的限制(比如 2GB 显存)进行判断和管理,最后再把一个"修改过"的请求或者一个"虚拟"的响应回传给你的程序。
整个过程,你的程序和驱动都被蒙在鼓里,还以为对方是原装的。就靠这手"瞒天过海",它轻松实现了显存虚拟化、算力限制和用量监控。
3.2 本地体验 GPU 虚拟化
这个设计的精髓在于,HAMi-core 完全可以脱离 K8s 单飞!这意味着,在你自己的电脑上,用 Docker 就能体验到 GPU 精准分配的快乐!
这对于想在单张卡上模拟多环境测试的个人开发者来说,简直太实用了!
假设你的显卡是 12G,我们切个 2G 的 vGPU 出来玩玩。
第一步:构建包含 HAMi-core 的镜像
ini
# 在 HAMi-core 项目里,用官方 Dockerfile 构建一个新镜像
docker build . -f=dockerfiles/Dockerfile -t cuda_vmem:tf1.8-cu90第二步:准备 Docker 运行所需的环境变量
ini
# 把英伟达驱动、工具啥的都准备好挂载进去
export DEVICE_MOUNTS="..."
export LIBRARY_MOUNTS="..."第三步:运行容器并应用 vGPU 限制!
最关键的一步来了,通过环境变量"激活"我们的 GPU 管家:
ini
docker run ${LIBRARY_MOUNTS} ${DEVICE_MOUNTS} -it \
-e CUDA_DEVICE_MEMORY_LIMIT=2g \
-e LD_PRELOAD=/libvgpu/build/libvgpu.so \
cuda_vmem:tf1.8-cu90当你在容器里敲下 nvidia-smi 并回车,你会看到......
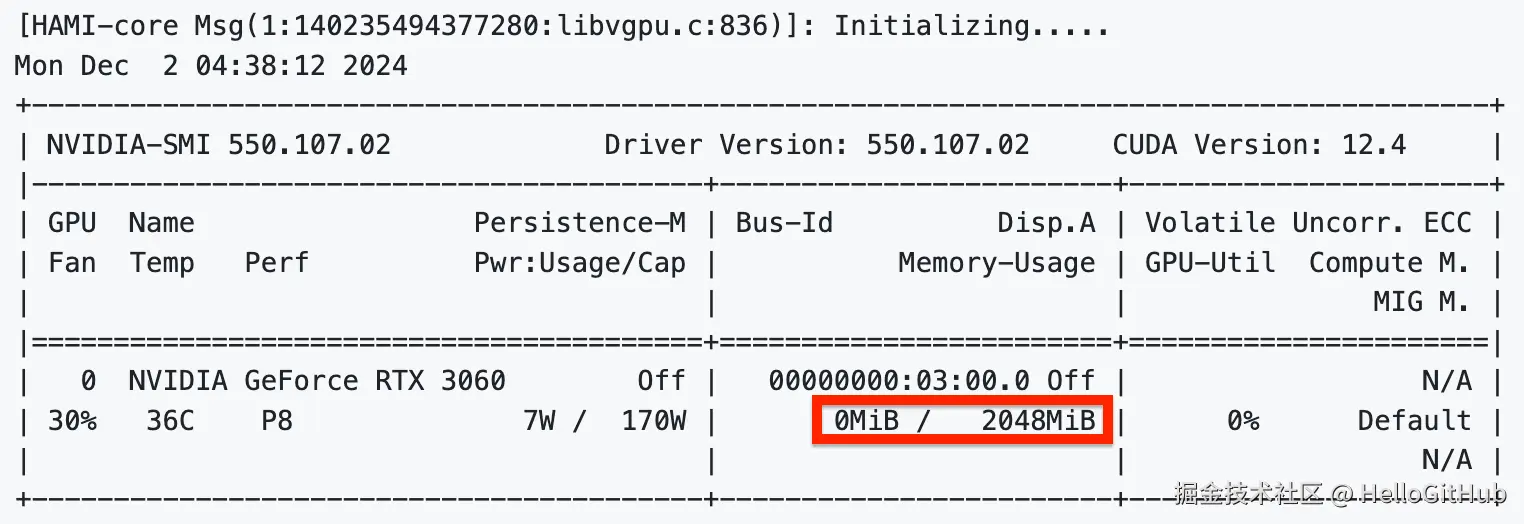
总显存不多不少,正好是我们设定的 2048MB!在这个容器里,任何程序都休想突破这个"结界"。是不是泰酷辣!
四、为什么说 HAMi 是 AI 算力的"必选项"?
看到这里,你应该明白了,HAMi 代表了一种更聪明、更高效的算力利用方式。
-
降本增效,立竿见影:GPU 利用率大幅提升,让本只能跑一个任务的显卡,轻松承载更多任务,资源价值直接翻倍。
-
国产芯的"瑞士军刀":不止支持英伟达,HAMi 还兼容寒武纪、海光、昇腾等众多国产 AI 芯片。在信创大潮下,战略价值不言而喻。
-
出身名门,CNCF 认证:作为 CNCF 官方沙箱项目,HAMi 拥有云原生世界的"正统身份",稳定性和社区支持有保障,选它更安心。
-
久经沙场,巨头验证:顺丰、AWS 等国内外头部企业都已在生产环境深度应用,早已证明 HAMi 不是"玩具",是真正能打的"正规军"。

五、最后
在 AI 大模型"军备竞赛"白热化的今天,谁能把算力用得更精、更省,谁就掌握了未来的主动权。HAMi 正是为此而生的一把"瑞士军刀",它优雅、无感,却能实实在在地帮你把钱花在刀刃上。
最后,别再让你的 GPU 继续摸鱼了,给它上点强度吧!
- GitHub 地址:github.com/Project-HAM...
- 社区动态:HAMi 2.7.0 重磅发布
开源不易,期待你的 Star 支持!