HTTP
在上一章已经初次认识了HTTP,接下来介绍更深层次的内容,探究HTTP的秘密
方法
先从HTTP请求的首行Method来讲,常用的方法有GET、POST、PUT、DELETE...
| 方法 | 说明 |
|---|---|
| GET | 获取资源 |
| POST | 传输实体主体 |
| PUT | 传输文件 |
| DELETE | 删除文件 |
| TRACE | 追踪路径 |
虽然分了很多的方法,但大多数都是用到的GET与POST方法,且各个方法之间的运用界限也没有那么的清,GET有时候也能做POST的事情,POST也能干GET的事情
那既然GET和POST的界限不是很清,但它们有没有很大的区别呢?
- 回答是没有本质的区别,只是在使用习惯上有一定的区别
- GET通常用来表示"获取数据"的语义,POST表示"提交数据"的语义
- GET通常把服务器传输的数据放到query string中,而POST一般放到body中
🤔另外,基于GET和POST在网络上的讨论包括但不限于
-
GET请求一般是实现成"幂等",POST请求则没有"幂等"的要求------"幂等"是请求出现重复的时候,结果是明确的 / 一致的,否之则"不幂等"
幂等场景:第一次问1+1 = ?,回答是2。那第二次问它的结果就是明确的,是2
不幂等场景:以打开b站为例,请求相同,都是刷新网页,但是看到的内容都不一样的,这是大模型在给你做个性化推荐,必然不幂等
这话来源于HTTP RFC标准文档,建议程序员这么做,但实际上,程序员并没有很遵守这套规则
-
❌ GET请求不安全,POST请求安全,因为GET把数据放query string里,POST则放到了body中
这个结论是错误的。安不安全是针对数据有没有加密来说的,POST即使放到了body中,用抓包工具一抓也能看到,这种掩耳盗铃的说法站不住脚跟
-
❌ GET单次请求传输的数据量小,POST大
这个言论并不准确。这是以前非常久的说法,受限于久远的IE浏览器来说是这样的,但现在URL的长度也可以很长
-
❌针对GET请求只能传输文本数据,POST可以传输文本和二进制数据
这个言论并不准确。对于GET来说,二进制数据可以通过urlencode / base64来进行转码成文本的数据,再通过GET的URL来传输,所以GET实际上也可以传输二进制的数据(URL中确实不能放二进制数据)
网络上充斥着杂乱的信息,所以我们需要怀有求真的精神来学习 ᕙ(`▿´)ᕗ~
在实际开发中,这几个常见方法可以一起搭配使用,规范化以Restful风格来编写更有效率
Host
通过抓包其中一个HTTP请求来看,在请求报头第一行有Host
Host表示了服务器的地址和端口
Content-Length
表示了body中的数据长度,单位是字节
Content-Type
表示了请求的body的解码格式

常见的数据格式有
- text/html
- text/css
- application/json
- application/javascript
- image/gif
- image/jpg
- image/png
- text/plain
在网页前端开发中
- html 负责网页结构 (骨)
- css 负责网页的样式 (皮)
- json 负责网页的交互逻辑 (灵魂)
在Content-Type中,告诉了浏览器body的数据格式,浏览器会根据不同的数据格式来解析,来渲染网页
User-Agent
用来告诉浏览器的所在的用户的设备、操作系统、浏览器版本号...
浏览器通过UA来区分用户是PC端or手机端,以此来渲染不同尺寸的页面,所以以前的前端程序员需要写两套代码来适配不同的人群
除此之外,根据UA的不同,程序员来写不同的代码以此适配不同的浏览器版本
随着技术发展,还有别的方案来代替写两套代码的情况------"响应式编程"(基于css3),工作原理是根据用户端屏幕的尺寸,自动进行不同的排版,效率更高,且不需要写两套代码
Referer
是记录从哪个页面跳转过来的
注意:这个Referer是面向服务器的,与浏览器的"前进" / "后退"不一样,后者是浏览器记录的,前者是发给服务器的

Referer的作用一般有收集数据来源 / 溯源 / 统计 的作用,是重要的数据
Cookie
我们一般在新下载一个浏览器的时候都会弹出"接受Cookie"的选项,那什么是Cookie呢?
Cookie是浏览器给网页提供的向本地存储数据的机制,但这个存储权限是有限的,且经过浏览器的安全操作再写入到本地硬盘中
类似的机制还有Local Storage,IndexDB(浏览器通过类似SQL语句方式来操作表)
在HTTP请求抓包中可以看到,Cookie保存的也是一系列的键值对,键值之间用 = 分开,键值对之间用 ;分开

网页本身是不允许向本地存储 / 修改数据的,因为这种操作很危险。那为什么会允许写入本地存储数据呢?接着看下去
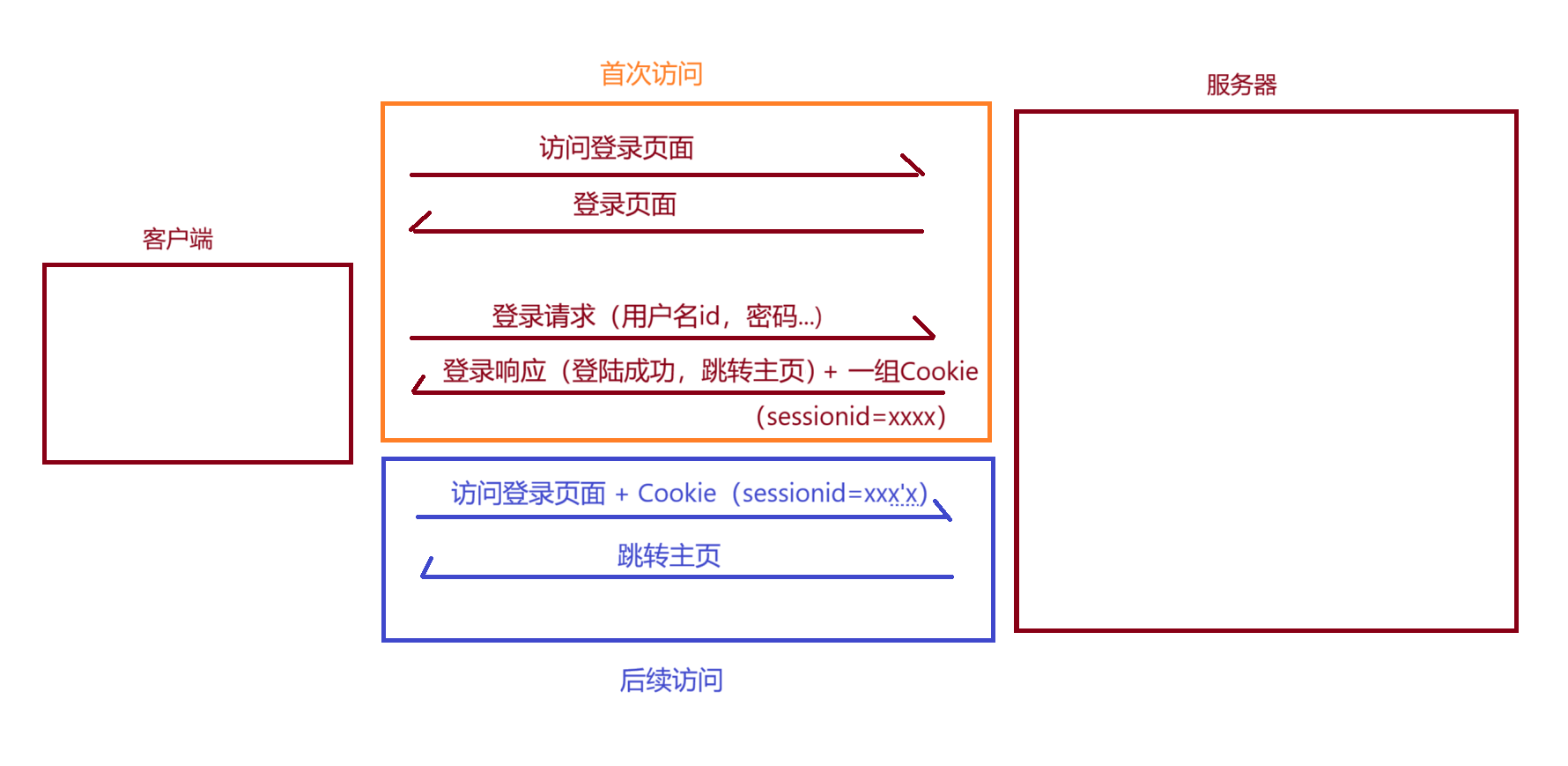
Cookie用途
当用户首次访问网页时,服务器会为该客户端创建一个会话,并通过 Cookie 中的一系列键值对来标识该会话。这些键值对会组成字符串,由浏览器存储在本地。
由于服务器会维护多个会话,不同用户对应着不同会话。所以用户通过SessionId都能找到,至于Session对象(对象里存什么,是程序员之间决定的)
当本地用户存储了一系列的Cookie后,如果后续再访问同一个网页,HTTP请求首先会把Cookie发给服务器,此时服务器维护了一个类似HashMap的一个表,里面存储了<会话ID>与<会话对象>的一系列键值对
当客户端发来的Cookie,服务器检查后有与之对应的<SessionId-Session对象>的时候,服务器就会直接返回对应的信息,例如登录信息、用户权限、配置等其他功能,避免了重复访问请求的情况出现
状态码
响应的状态码在HTTP响应的首行中
最常见的就是200 请求成功,2xx开头的都可以视为成功,只是成功的内容有不一样
404 Not Found 意思是访问的资源在服务器上不存在,一般是客户端填写的URL有问题,服务器找不到

403 Forbidden 拒绝访问,说明访问的页面无权限,以码云的403举栗

4xx 都属于是"客户端错误"
除此之外还有
500 Internal Server Error 服务器出错------服务器挂了 / 服务器非常繁忙 5xx都属于"服务器错误"
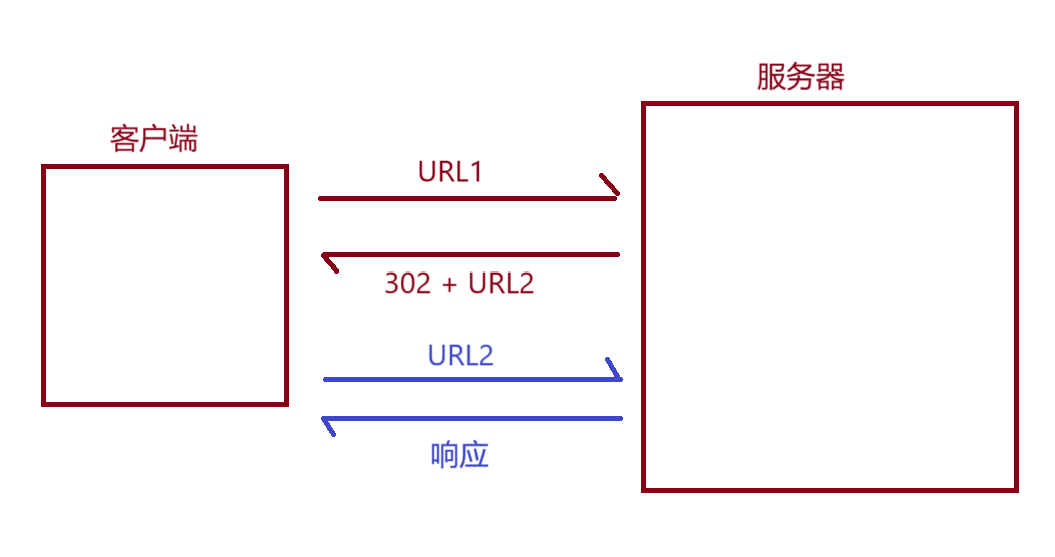
302 Move temporarily 临时重定向------belike手机号的呼叫转移,当你呼叫手机号码1的时候,运营商会自动转接到手机号码2
客户端想要请求URL1的时候,服务器会告诉客户端你去访问URL2就能得到你想要的东西了!!然后客户端就去访问URL2了~~
有临时重定向,那就会有永久重定向
301 redirect 永久重定向------即URL2的地址永远不会变,不过一般永久重定向的问题,浏览器可以做缓存,也没有必要再访问服务器重定向,这样效率更高,所以301很少出现
总结一下状态码
| 状态码 | 类别 | 小幽默(以服务器的视角) |
|---|---|---|
| 1xx | 请求正在处理 | 别急,我有我自己的节奏 |
| 2xx | 成功 | Here you go ~ |
| 3xx | 重定向 | Go away ! |
| 4xx | 客户端错误 | You fucked up |
| 5xx | 服务器错误 | I fucked up |
以下就是对HTTP更进一步的学习 我将持续更新
希望对看到这里的你有所帮助,祝愿身体健康~(∠・ω< )⌒★