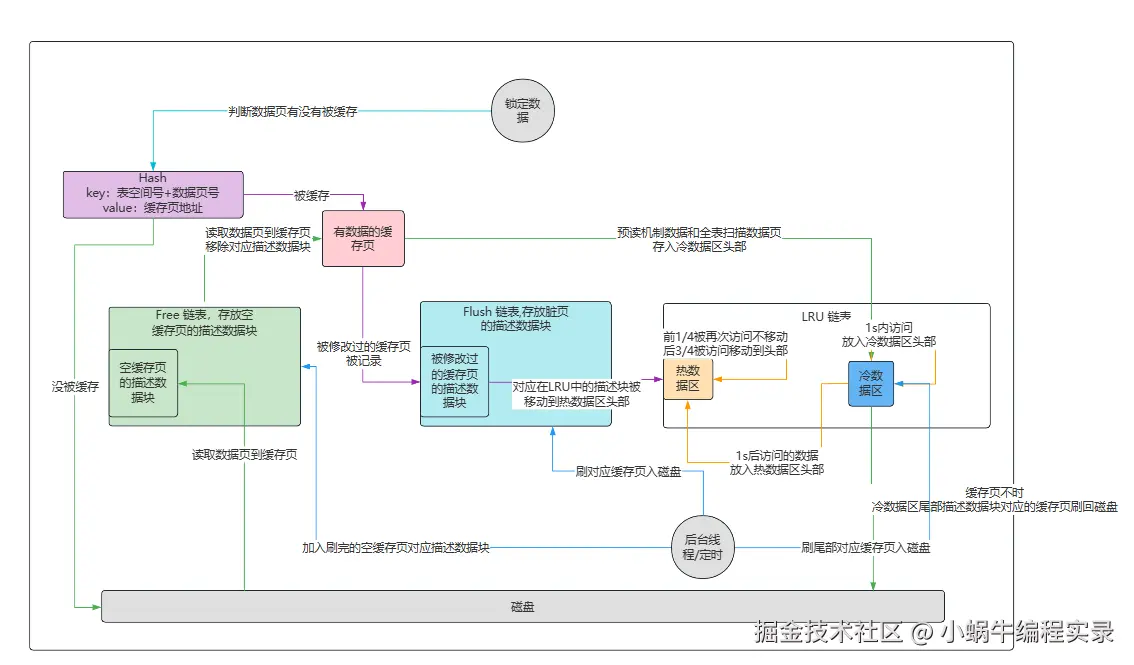
Buffer Pool:
- 数据库内存组件,缓存了磁盘上的真实数据,系统对数据库执行的增删改操作,主要就是对这个内存数据结构中的缓存数据执行的。然后数据库中有定时的IO线程,将该内存中的数据刷导磁盘,减少了磁盘IO的次数。
- Buffer Pool本质是一片内存数据结构,默认是128M,实际生产时通过innodb_buffer_pool_size来分配该内存大小。如果是16核32G,可以分配个2GB
Buffer Pool的核心作用:
首先要知道磁盘顺序IO、磁盘随机IO、内存顺序IO、内存随机IO的意义。
- 磁盘顺序IO:以顺序的方式写入文件,磁盘顺序IO比磁盘随机IO快;在某种程度下,磁盘顺序I/O访问(特别是写操作)能够匹敌内存的随机I/O访问性能的
- 磁盘随机IO:以随机的方式写入文件;MySQL的redo log、bin log都是磁盘上顺序IO,写入的时候可以很快,某种程度上来说,几乎可以跟内存随机读写的性能差不多
- 内存顺序IO:内存访问很快,内存顺序IO比内存随机IO快
- 内存随机IO:内存中随机读写
MySQL对表空间的磁盘文件进行查询数据页的时候就需要在磁盘上随机读,因为要读取的数据页可能在磁盘的任意一个位置,所以在读取磁盘里的数据页的时候只能是用随机读这种方式。
Buffer Pool就是MySQL向操作系统申请的一块内存,如果没有Buffer Pool,我们每次的DML操作都要进行磁盘的IO操作,如果是磁盘上的随机IO,那性能肯定比较差,所以Buffer Pool出现了,减少磁盘上的随机IO,这就是它的核心作用;也就是说,增加内存(Buffer Pool)是来解决磁盘随机I/O读取问题的最好的办法。
MySQL磁盘随机读写:
执行CURD时,会从表空间中磁盘文件里读取数据,可能在随机的位置读取一个数据页到缓存,这就是磁盘随机读,性能比较差。
磁盘随机读关注IOPS和响应延迟:
- IOPS代表底层存储系统每秒可以执行多少次磁盘读写操作,IOPS越高,数据库并发能力越强。
- 磁盘读写操作的响应延迟对数据库性能影响很大,比如一个sql语句,磁盘要执行随机读操作加载多个数据页,此时每个磁盘随机读响应时间是50ms,那么可能导致sql执行要几百ms。如果是10ms,sql执行就只要100ms。
核心业务数据库推荐用SSD固态,随机读写并发能力和响应延迟比机械硬盘好得多,可以大幅度提升数据库的QPS和性能。
Buffer Pool的结构:
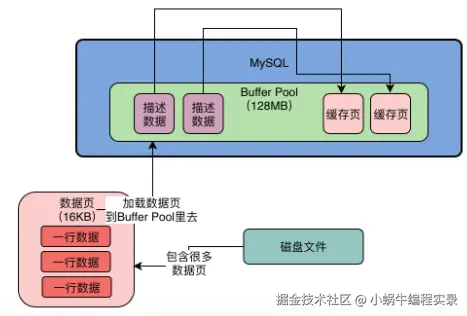
- 数据库核心数据模型:表+字段+行,MySQL将数据抽象成数据页,将很多行数据放在一个数据页。
- 假设更新一条数据,数据库会找到该行数据所在数据页,从磁盘文件将这行数据在的数据页直接加载到Buffer Pool中,默认一个缓存页大小和磁盘数据页大小一一对应,都是16KB,Buffer Pool存放的就是一个个缓存页。
- 每个缓存页,都存在一个描述信息,包含:数据页所属表空间、数据页编号、缓存页在buffer pool的地址等,描述信息本身是一块数据,放在最前面,缓存页放在后面。
- Buffer Pool中描述数据大概相当于缓存页大小的35%左右,大概800字节大小。假设设置的Buffer Pool是128M,实际大小会超出一些,可能有130多M,因为里面还要存放每个缓存页的描述数据
Buffer Pool初始化:
数据库启动后,会根据设置的Buffer Pool大小稍微再大点,去找操作系统申请一块内存区域,内存申请完毕后,会按照默认的缓存页16KB及描述文件800字节,在Buffer Pool中划分出一个个缓存页和对应的描述数据。此时缓存页都是空的,等待数据库运行起来后,对数据执行操作时,才会把数据对应的页从磁盘文件读取出来,放到缓存页中。
Free链表:
磁盘数据放入到缓存页时,如何判断缓存页是空闲的。数据库设计了一个Free链表,双向链表数据结构,每个节点都是一个空闲的缓存页的描述数据块的地址。只要一个缓存页是空的,那么对应的描述数据块会被放入free链表中。
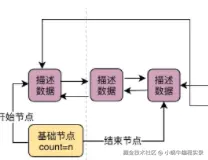
- free链表各个缓存页的描述数据块,只要缓存页是空闲的,对应的描述数据块就会加入到这个链表中,每个节点都会双向链接自己的前后节点,组成一个双向链表。
- free链表有一个基础节点,存放了free链表的头尾节点的地址,里面还存储了链表中当前有多少个节点。
- free链表本身是由Buffer Pool的描述数据块组成,每个描述数据块里都有free_pre和free_next指针,通过指针链接空闲的描述数据块。只有基础节点是不属于Buffer Pool的,大概是40字节大小的一个节点。
- 如何将磁盘上的页读取到Buffer Pool的缓存页中:
- 从Free链表获取一个描述数据块,获取到对应的空闲缓存页
- 将磁盘数据读取到该缓存页,同时把相关描述信息写入描述数据块,最后将描述数据块移出free链表,移除过程类似于链表删除节点,利用指针的变化
如何知道数据页没有被缓存:
数据库有一个哈希表,他会用表空间号+数据页号,作为一个key,然后缓存页的地址作为value。要使用一个数据页的时候,通过"表空间号+数据页号"作为key去这个哈希表里查一下,如果没有就读取数据页,如果已经有了,就说明数据页已经被缓存了。
Buffer Pool的内存碎片:
- Buffer Pool大小是设定的,很可能Buffer Pool划分完全部的缓存页和描述数据块之后,还剩一点点的内存,这一点点的内存放不下任何一个缓存页了,所以这点内存就只能放着不能用,这就是内存碎片。
- 数据库在Buffer Pool中划分缓存页的时候,会让所有的缓存页和描述数据块都紧密的挨在一起,这样尽可能减少内存浪费,就可以尽可能的减少内存碎片的产生了。
- 如果你的Buffer Pool里的缓存页是东一块西一块,那么必然导致缓存页的内存之间有很多内存空隙,这就会有大量的内存碎片了。
脏数据页的产生:
- 当操作数据的对应缓存页存在Buffer Pool中,那么更新了缓存页中的数据,在未刷入到磁盘前,缓存页中数据与磁盘不一致,因此产生了脏页。
- 有的缓存页可能被读取到Buffer Pool,然后没有被修改过,这样这个缓存页就不会刷回磁盘。Buffer Pool提供了Flush链表,通过描述数据块的两个指针,让被修改过的缓存页的描述数据块组成一个双向链表。flush的意思是这些都是脏页,后续都要flush刷新到磁盘。
Buffer Pool的缓存页淘汰问题:
Buffer Pool的缓存页大小是有限的,当不停的把磁盘数据加载到空闲缓存页中,free链表中的空闲缓存页会越来越少,当free链表中没有空闲缓存页了,就需要通过缓存页淘汰来处理内存不够的情况。
针对缓存命中率结合LRU算法来实现缓存页淘汰,从磁盘加载数据页到缓存页时,将该缓存页的描述数据块放到LRU链表头,只要有数据的缓存页,就会在LRU中,最近被加载数据的缓存页会在LRU链表头部。当缓存页没有空闲的,就将LRU链表尾部的缓存页刷入磁盘,然后将需要的磁盘数据加载到腾出来的空闲缓存页中。
预读机制带来的LRU机制隐患:
预读机制就是从磁盘加载一个数据页时,可能会连带着把这个页相邻的其他数据页也加载到缓存页中。通过预读机制加载的缓存页,可能并没有人访问,此时这两个页处于LRU链表前,如下图:
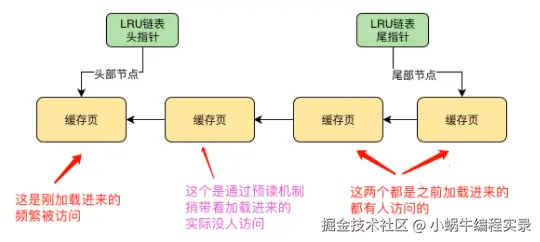
除了预读加载的缓存页外,其他缓存页都有人访问,如果这个时候没有空闲缓存页了,通过LRU就淘汰了尾部的缓存页,这样就导致了实际频繁访问的缓存页被淘汰,没人访问的缓存页就占据了内存。
区:由连续的数据页组成,每个区默认1MB,一个区64个数据页。
预读机制的触发:
- innodb_read_ahead_threshold:默认56,指如果顺序访问一个区里的多个数据页,访问的数据页超过这个阈值,就会触发预读机制,把下一个相邻的数据页加载到缓存中
- innodb_random_read_ahead:默认OFF关闭,开启时如果Buffer Pool里缓存了一个区里的13个连续的数据页,而且这些数据页都是比较频繁会被访问的,此时就会直接触发预读机制,把这个区里的其他的数据页都加载到缓存里去
- 全表扫描:类似select * from语句造成的全表扫描,没有任何where条件,会导致直接把表里所有的数据页都从磁盘加载的Buffer Pool。此时可能造成一下把所有数据页都装入各个缓存,导致LRU链表中前面一大串缓存页都是全表扫描加载进来的,后续几乎不使用。让实际频繁访问的缓存页被排到链表尾部并被淘汰。
为什么设计预读机制:
为了性能提升,如果在一个区内,顺序读取了好多数据页,MySQL会判断,可能接下来会继续顺序读取后面的数据页,利用预读提前读取,减少一次磁盘IO。
基于冷热数据分离的思想设计LRU链表:
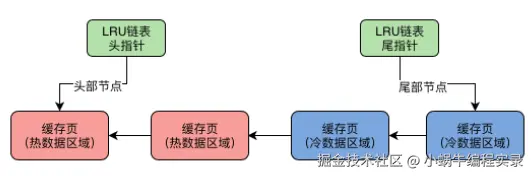
- LRU链表被拆为热数据和冷数据,比例由innodb_old_blocks_pct参数控制,默认37表示冷数据占37%。
- 数据页首次被加载会放到冷数据区的链表头部,被访问后不是立马就放到热数据区头部
- innodb_old_blocks_time参数,默认值1s。当一个数据页被加载到缓存页,在1s之后再次访问这个缓存页,这个缓存页才会被挪动到热数据区的链表头部,1s内访问时不会挪动到热数据区。
- 设置访问时间阈值,是为了避免当数据页加载到缓存页后,立刻被访问后续再也不访问的情况,这会导致实际被访问的热数据区链表头数据被挪到后面。
热数据区优化: 热数据区数据,只有在3/4部分的缓存页被访问了,才会移动到链表头部。前1/4的缓存页被访问,不会移动。因为热数据区可能经常被频繁访问,频繁移动性能不好。
冷区域数据:
- 预读机制和全表扫描加载进来的缓存页会被放在LRU链表冷数据区前面。此时热数据区被频繁访问的缓存页只要被访问还是被移到热数据区头部,避免了预读和全表扫描带来的隐患。
- 以上的数据,大部分都会在1s之内被访问一下,之后可能再也不访问了。在1s内访问结束就不会被挪到热数据区头部,除非在1s后还被访问了,会被判定为频繁访问的缓存页,移动到热数据区头部。
- 缓存页不够时,会直接找到冷数据区尾部缓存页刷入磁盘,来获得空闲缓存页。数据库不会让刚加载进来的缓存页占据LRU链表头部,所以直接淘汰尾部缓存页即可。
刷数据机制:
- LRU冷数据区:后台线程运行定时任务,将冷数据区尾部的缓存页刷入磁盘,并清空缓存页,将对应的描述数据块加入free链表,将flush链表中对应描述数据块移除。
- Flush链表:后台线程运行定时任务,在MySQL不繁忙的时候,将flush链表中描述数据块对应的缓存页刷入磁盘。并移除对应LRU链表中的描述数据块,然后加入到free链表。
- 当没有空闲缓存页,会从LRU冷数据区尾部找到一个缓存页,一定是最不经常使用的,刷入磁盘和清空,移出flush链表,添加到free链表中
Buffer Pool执行流程图: