目录
- 前言
- [1. 前置准备](#1. 前置准备)
-
- [1.1 环境、软件](#1.1 环境、软件)
- [1.2 主模型](#1.2 主模型)
- [1.3 LoRa](#1.3 LoRa)
- [1.4 文生图](#1.4 文生图)
- [2. 姿态生成](#2. 姿态生成)
-
- [2.1 N视图](#2.1 N视图)
- [2.2 帧动画](#2.2 帧动画)
-
- [2.2.1 免费动作素材](#2.2.1 免费动作素材)
- [2.2.2 快速生成骨骼图](#2.2.2 快速生成骨骼图)
- [2.2.3 快速绘制单张骨骼图](#2.2.3 快速绘制单张骨骼图)
- [2.2.4 更细致的摆放](#2.2.4 更细致的摆放)
- [3. 绘图](#3. 绘图)
-
- [3.1 思路](#3.1 思路)
- [3.2 结果样例](#3.2 结果样例)
- [3.3 遗留问题](#3.3 遗留问题)
- [3.4 解决思路 - 像素帧动画问题](#3.4 解决思路 - 像素帧动画问题)
前言
仅做个人尝试,目前效果不达预期。
1. 前置准备
1.1 环境、软件
| K | V | 备注 |
|---|---|---|
| 系统 | Ubuntu 24.04 LTS | cat /etc/os-release |
| 软件 | stable diffusion Web UI | 安装过程详见同专栏文章 《SD:在一个 Ubuntu 系统安装 stable diffusion Web UI》 |
| 插件1 | control net | 详见 《SD:在一个 Ubuntu 系统安装 stable diffusion Web UI》7节 |
| 插件2 | openpose editor | 详见同专栏文章 《SD:Ubuntu 系统 stable diffusion Web UI - 安装更多插件》2节 |
| 插件3 | 3D openpose editor | 详见同专栏文章 《SD:Ubuntu 系统 stable diffusion Web UI - 安装更多插件》3节 |
1.2 主模型
| 模型id | 模型名称 | 后文简称 |
|---|---|---|
| 1 | PUS古风小说推文大模型_v1.0 | 漫画模型 |
| 2 | 2D_Pixel_Sprites(2D像素)_1.0 | 像素模型 |
1.3 LoRa
| 模型id | 模型名称 | 后文简称 |
|---|---|---|
| 1 | 2D Pixel Toolkit (2D像素工具包)_角色和序列帧 | 像素帧LoRa |
| 2 | 年轻武侠弟子,长衫,宝剑_剑侠1.0 | 武侠LoRa |
| 3 | 汉服唐风_v3.5 | 汉服LoRa |
| 4 | 国风甲胄~愿与君共征守四方_v1.0 | 甲胄LoRa |
| 5 | 三视图_二次元设定_V 1.0 | 多视图LoRa |
1.4 文生图
详见同专栏文章《stable-diffusion试验1-静态人物》,里面介绍了:
- 提示词
- 生成古风人物、像素人物的方法
2. 姿态生成
这一步的根本目的是生成 control net 可用的骨骼图(形如下图)
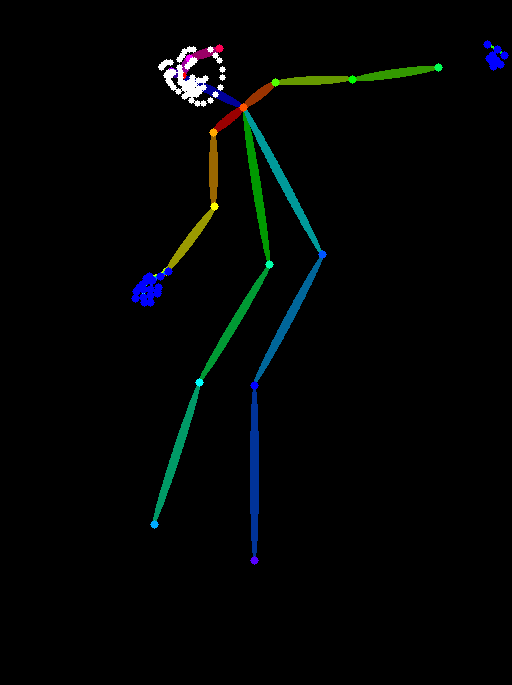
2.1 N视图
这里建议采用 3D openpose editor 工具,详见同专栏文章 《SD:Ubuntu 系统 stable diffusion Web UI - 安装更多插件》3节
通过旋转→生成→保存→拼接 即可得到下图:
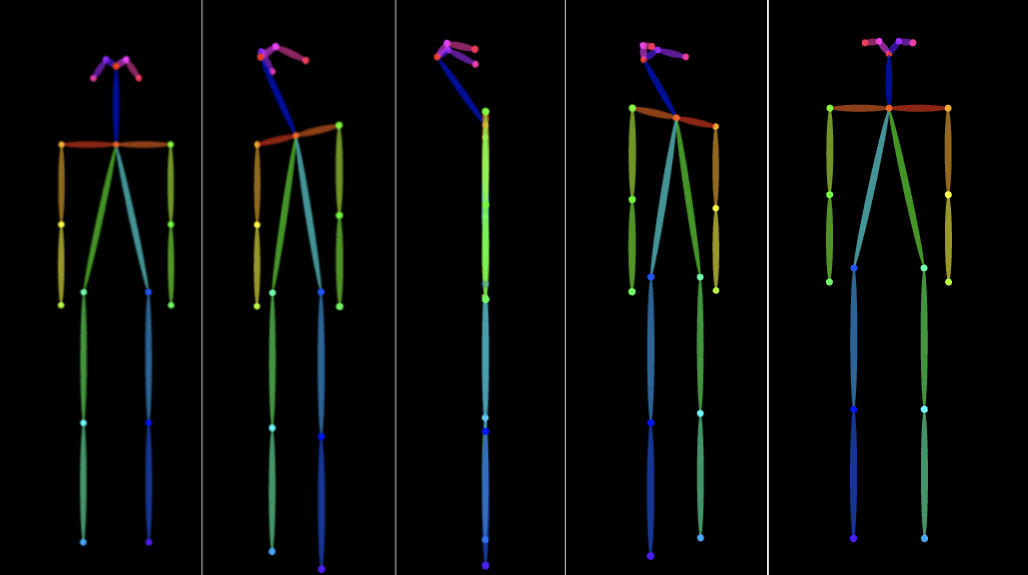
2.2 帧动画
2.2.1 免费动作素材
- 网站:https://www.mixamo.com/#/
- 使用方法
- 选角色:对于 stable diffusion 中内置的工具,建议先选角色,便于后续识别
- 选动作:进入动作页面,支持搜索动作(例如搜: walk)
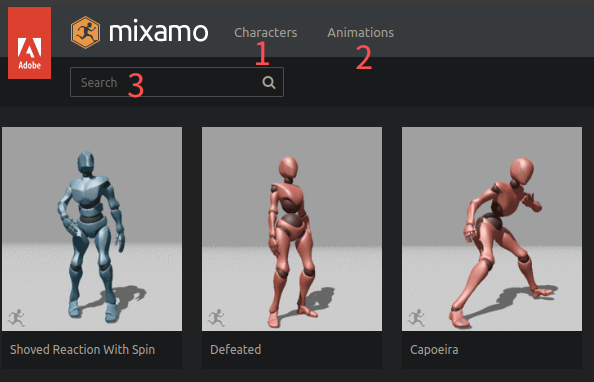
2.2.2 快速生成骨骼图
- 简单截图
由于是给 SD 的插件做识别,可以截图。如果想要更专业的处理方式,可以下载 .fbx 文件用专业工具处理。

- 使用 control net 的 one pose 功能,点击💥预览即可生成,可保存
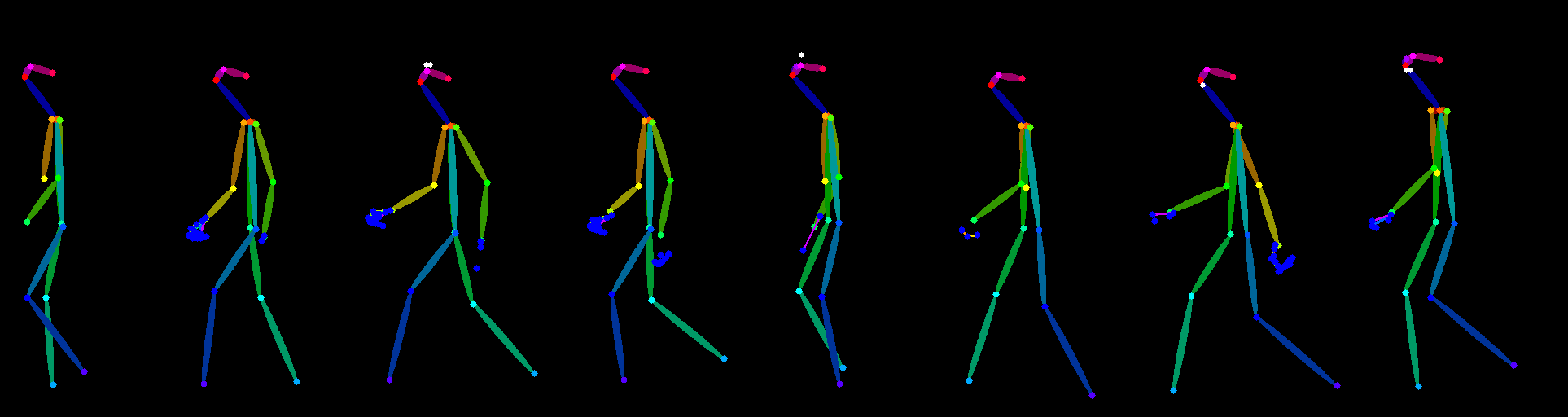
2.2.3 快速绘制单张骨骼图
可以看到直接对长图生成骨骼图会有瑕疵,使用 openpose editor 逐一生成会更精确(用 control net 逐一生成也行)

2.2.4 更细致的摆放
使用 3D openpose editor,需要 手动调整 位置(例如下图中的手脚的方向;而且只有这个侧视图能看,旋转到正面发现骨骼的摆放是不对的)。

3. 绘图
3.1 思路
-
风格
- 方法1:漫画主模型 + 像素LoRa
- 方法2:像素主模型
- 方法3:漫画主模型 + N 视图 → 然后进行转绘生成像素风图片
- 注:可选加武侠LoRa、汉服LoRa、甲胄LoRa,具体方法详见同专栏文章 《stable-diffusion试验1-静态人物》
-
姿态
- 需求1:只需要角色概念图,动画交由其他工具处理
使用 多视图LoRa - 需求2:需要生成帧动画
使用 control net 的姿态控制
- 需求1:只需要角色概念图,动画交由其他工具处理
3.2 结果样例
- 多视图 LoRa(提示词:front view,rear view,side view,five-view,)
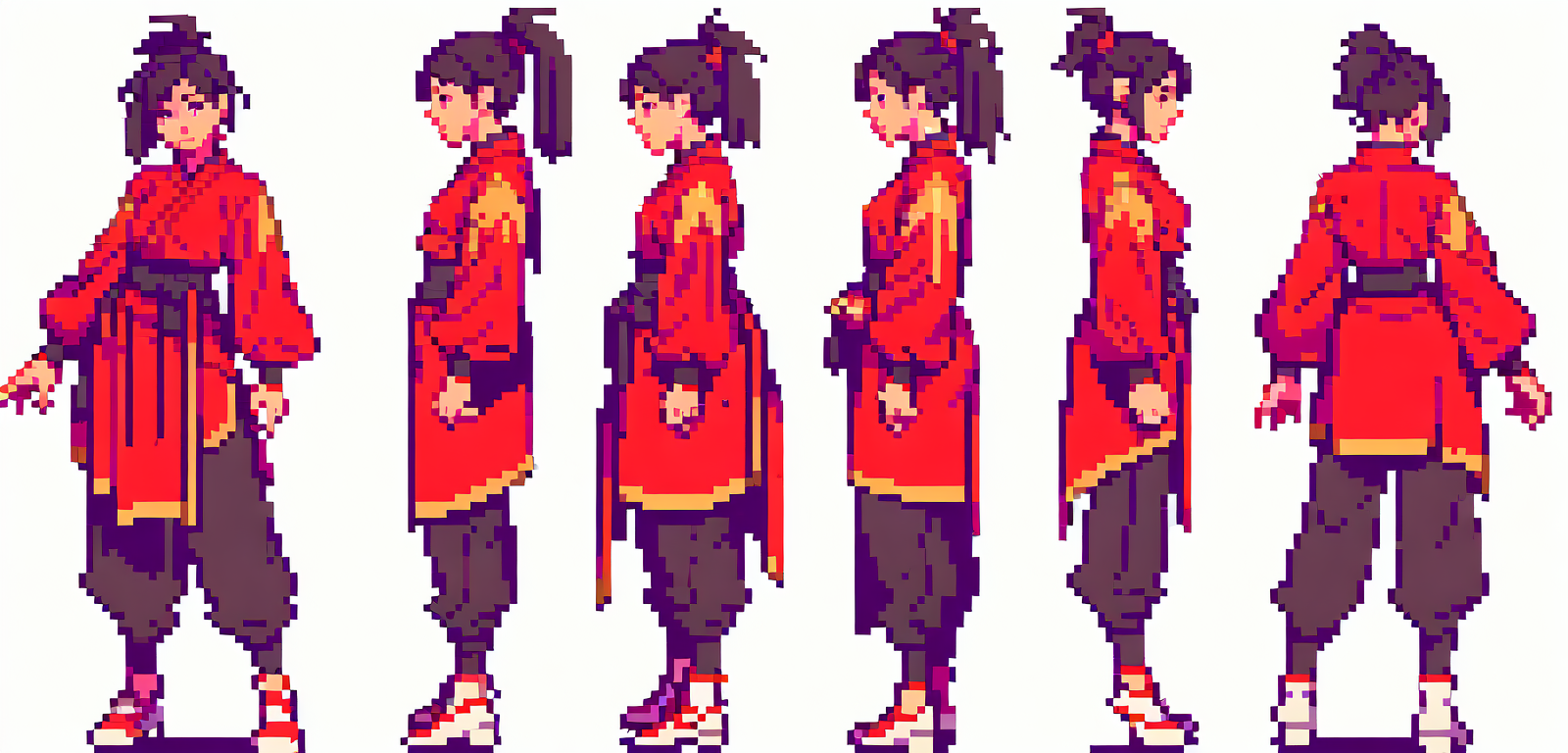
注:使用 control net 可以实现类似的效果,和 LoRa 的区别如下(1表示可以画出,0表示不能画出)
| LoRa | contorl net | |
|---|---|---|
| 正面 | 1 | 1 |
| 斜前方 | 0 | 1 |
| 侧面 | 1 | 1 |
| 斜后方 | 0 | 1 |
| 背面 | 1 | 0 |
-
control net
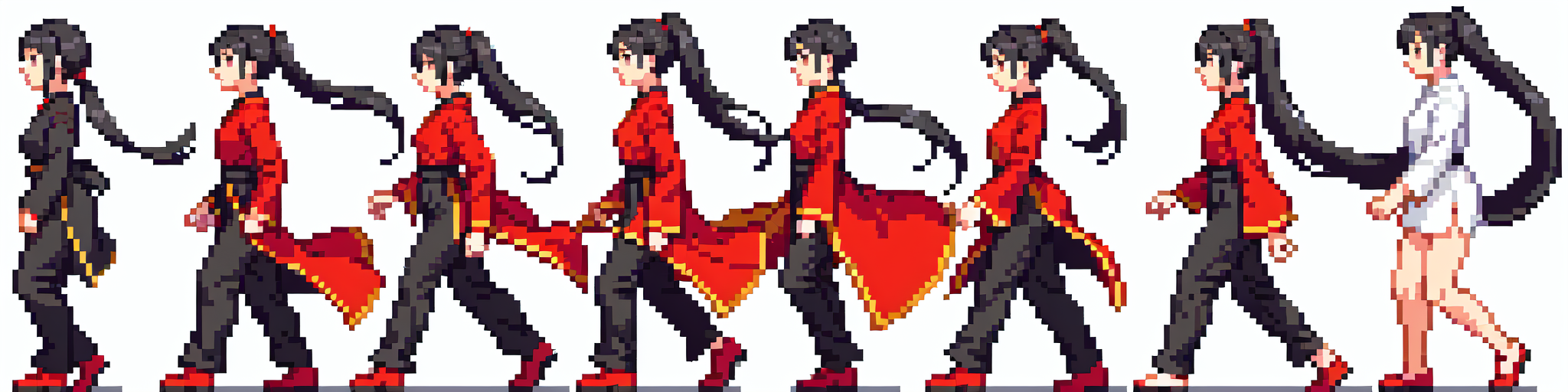
-
转绘
先试用 txt2img 成漫画图片,再使用 img2img 进行重绘
-
图生图关键参数
| 参数名 | 取值 |
|---|---|
| 模型 | 像素主模型 |
| 提示词 | 重要的是人物描述:black hair,purple long-sleeved shirt, black pants,white shoes,Hanfu |
| 采样方法 Sampling method | DPM++ 2M |
| 采样步数 Sampling steps | 25 |
| 提示词系数 CFG Scale | 7 |
| ★ 重绘幅度 Denoising strength ★ | 0.55 |
| 插件 | control net - one pose - 正视图骨骼 |
- 重绘样例:

3.3 遗留问题
- 关于帧动画
核心问题是保持角色的一致性问题,展开来说有如下几点
| 问题序号 | 问题 | 描述 |
|---|---|---|
| 1 | 图片大小限制 | 受限于显卡,一张图能画的动作有限,8帧已经很多了 |
| 2 | 人物细节 | 同一张图画多个人物时,服装、发型、面部细节可能有差异 |
| 3 | 更多动作 | 如果想支持同一人物的各种动作(走路、跑步、武打)那面临的是要画多张图,这种一致性极难保证 |
- 关于像素帧动画
如果不是像素帧动画,可能通过 N视图 + 专门的骨骼动画工具可以做到一张图生成多组动画的效果。
但如果是像素帧动画,那么就不能通过旋转肢体来完成动作,否则像素角度就会有旋转,不是真正的像素风了。
3.4 解决思路 - 像素帧动画问题
- 思路1:找一找有没有好用的图生视频工具 待学习
- 思路2:sd生成像素动作草图,用传统的像素动画制作工具进行修改、补帧 动作有限
- 思路3:生成N视图,用骨骼动画工具生成大量动作,用转绘工具转为像素风 待学习