服务器存储数据恢复环境:
某单位一台某品牌DS5300存储,1个机头+4个扩展柜,50块的硬盘组建了两组RAID5阵列。一组raid5阵列有27块硬盘,存放Oracle数据库文件。存储系统上层一共划分了11个卷。
服务器存储故障:
存储设备上两个硬盘指示灯亮黄色。其中一组RAID5阵列崩溃,存储不可用,设备已经过保。
服务器存储数据恢复过程:
1、硬件工程师对出现故障的raid5阵列中的27块硬盘做硬件故障检测,发现其中2块硬盘存在坏道、SMART的错误冗余级别已经超过阈值,其他25块硬盘正常。对25块正常硬盘以只读方式进行全盘镜像,对2块存在坏道的硬盘使用专业工具处理后生成镜像文件。后续的数据分析和数据恢复操作基于镜像文件进行,避免对原始磁盘数据造成二次破坏。
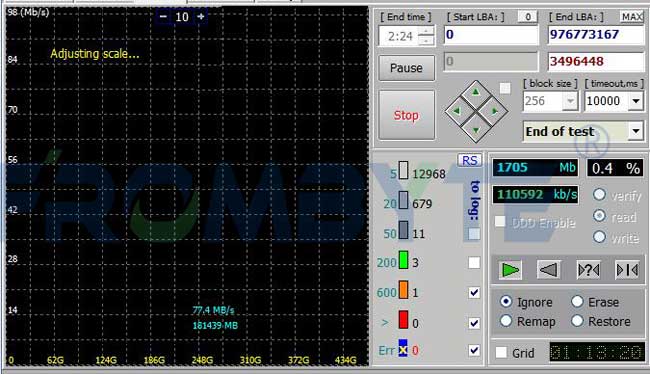
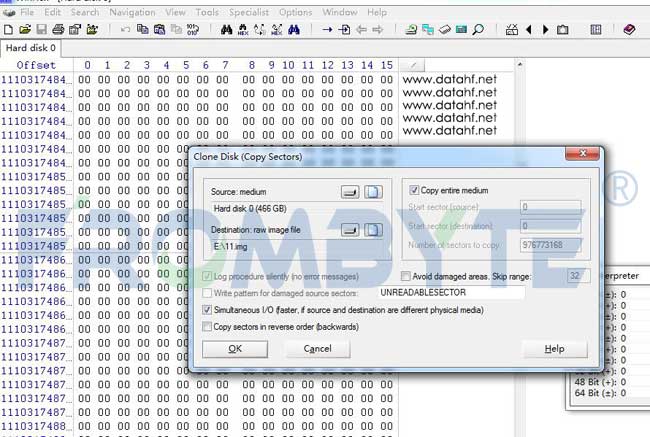
2、收集&分析故障存储的日志信息。分析两块硬盘的掉线时间,搞清楚数据较新的那块硬盘,使用数据较新的硬盘来恢复数据。
3、经过北亚企安数据恢复工程师的会诊,敲定了2个数据恢复方案:
方案一:通过存储设备的管理软件强制上线,强制上线之前把存储的所有硬盘进行备份。
方案二:分析硬盘底层数据,重组RAID。从底层提取数据,重新加载oracle数据库,调试上层应用。
4、首先、按照方案一实施:将故障存储上的所有硬盘都进行完整备份。先在模拟器上测试,之后再在存储上进行上线操作。
通过存储管理软件进行强制上线的操作,强制上线之后raid处于降级状态。设置好热备盘,让热备盘上线同步数据。同步完成后,上层的卷直接可以使用了,所有数据也都可见,上层应用也能正常使用。
第一种方案就成功恢复出数据,节省很多时间,上层应用也不需要调试,可以直接启动。
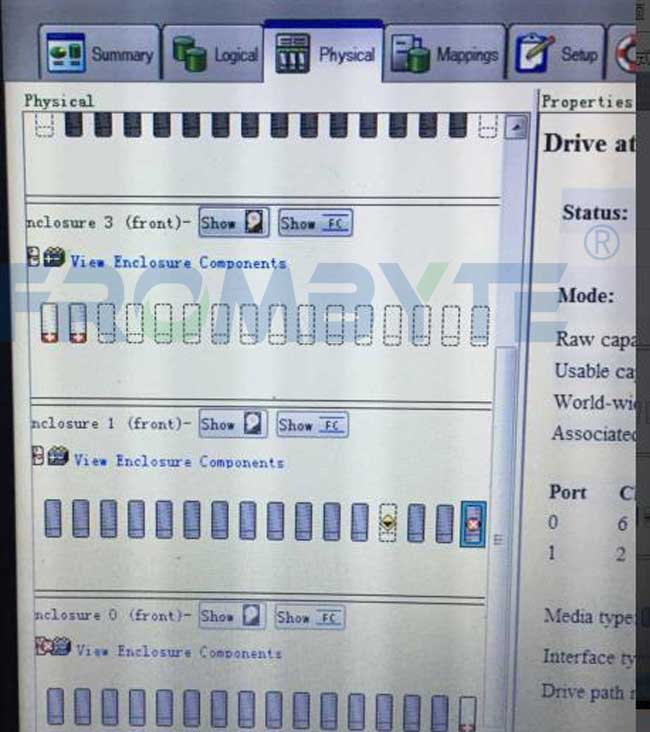
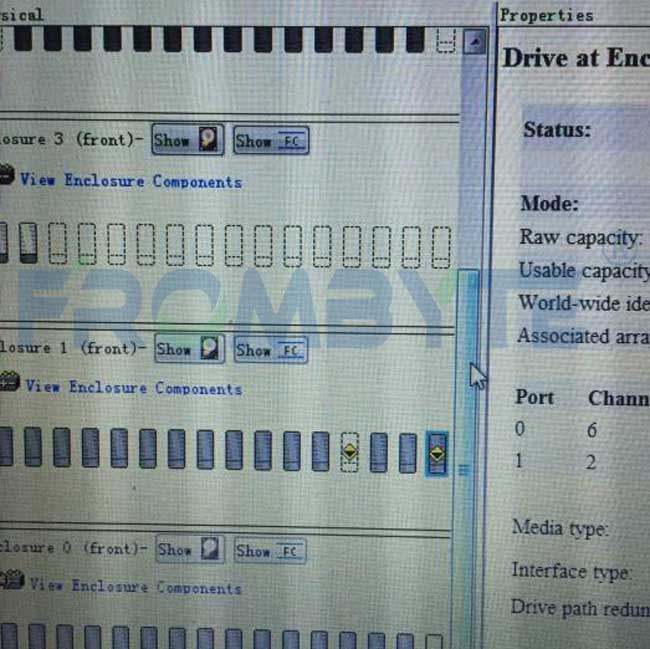
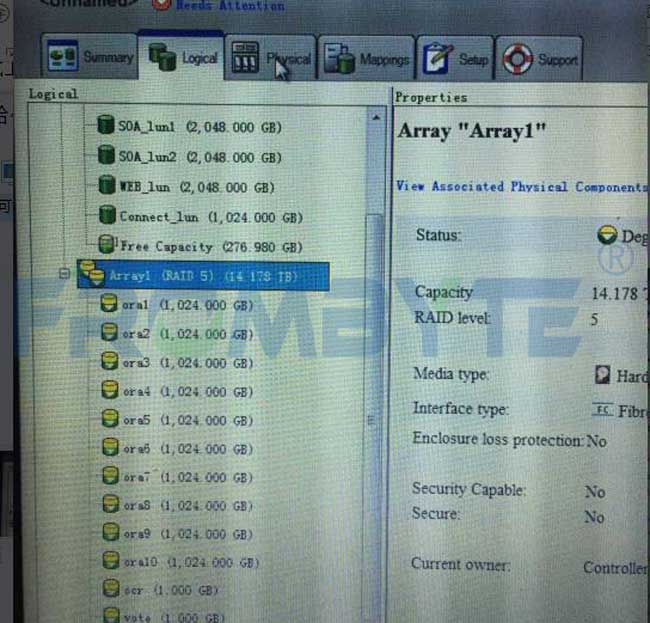
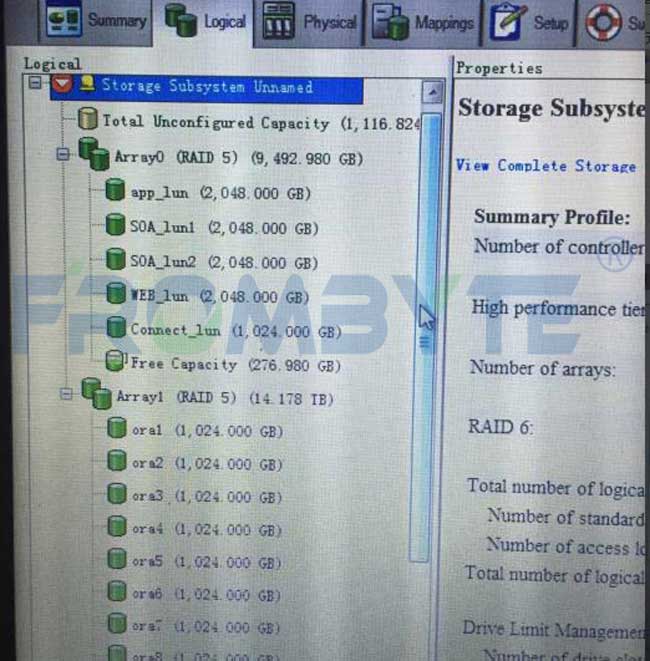
5、将卷里的文件都拷贝出来,移交给用户方。本次数据恢复工作完成。