主从复制是 MySQL 实现高可用、读扩展的核心技术,本质是 "主库记录日志、备库重放日志" 的异步数据同步机制。本文将从复制的基础类型出发,拆解其核心价值、工作原理、常见问题及优化方案,所有内容基于 MySQL 主流版本逻辑,确保技术准确性与实用性。
一、主从复制基础:类型与本质
1. 两种核心复制类型
MySQL 主从复制按 "日志记录方式" 可分为两类,均基于 "二进制日志(binlog)" 实现异步同步:
(1)基于语句的复制(逻辑复制)
- 原理:主库记录 "执行的 SQL 语句" 到 binlog,备库读取 binlog 后,重新执行相同的 SQL 语句以同步数据;
- 特点:binlog 体积小(仅记录 SQL),但存在 "SQL 语句依赖环境" 的问题(如NOW()函数、LIMIT无排序的语句,主备执行结果可能不一致),MySQL 5.1 后逐渐被混合模式替代。
(2)基于行的复制
- 原理:主库记录 "数据行的修改内容" 到 binlog(如某行数据从 "name=A" 改为 "name=B"),备库直接按行修改数据,无需重新执行 SQL;
- 特点:数据同步更精准(无环境依赖),但 binlog 体积较大(记录每行修改),适用于数据一致性要求高的场景,是 MySQL 5.7 + 的默认复制方式。
2. 复制的本质:异步与数据一致性
无论哪种复制类型,核心逻辑都是 "主库写日志→备库读日志→备库重放日志",但需注意两个关键点:
- 异步特性:主库执行事务后,无需等待备库同步完成即可返回结果,因此同一时间点备库数据可能与主库不一致;
- 延迟不可避免:日志传输、备库重放都需要时间,无法完全消除主备延迟,极端场景下可能出现 "主库宕机后,备库缺失部分数据"。
二、主从复制的价值与开销:权衡利弊
主从复制虽能解决诸多业务问题,但也会带来一定开销,需在 "收益" 与 "成本" 间平衡。
1. 复制的四大核心价值
(1)数据分布:灵活部署备份
可按需启停复制,将备库部署在不同地理位置(如主库在北京,备库在上海),实现 "异地数据备份",降低单点故障导致的数据丢失风险。
(2)负载均衡:优化读密集场景
将读操作(如查询)分流到备库,主库专注处理写操作(如新增、修改),缓解主库压力 ------ 尤其适用于读密集型应用(如电商商品详情页查询),提升整体系统并发能力。
(3)数据备份:降低备份风险
传统备份(如 mysqldump)会占用主库资源,而通过备库备份(如在备库执行全量备份),可避免影响主库业务,同时保障数据安全性。
(4)高可用与故障切换
当主库宕机时,可将备库切换为新主库,避免 MySQL 单点故障;配合故障切换工具(如 MHA、Orchestrator),能大幅缩短宕机时间,提升系统可用性。
(5)版本升级:平滑过渡
可先将备库升级到高版本 MySQL(如从 5.7 升级到 8.0),验证查询兼容性后,再将主库切换为升级后的备库,避免直接升级主库导致的业务中断。
2. 复制的三大核心开销
(1)主库:binlog 记录开销
复制本身不增加主库额外负担,但 "启用 binlog" 会消耗主库资源 ------ 主库需在事务提交前,将操作串行写入 binlog,若写 binlog 的 I/O 性能不足,可能影响主库事务提交速度。
(2)主库:备库连接负载
每个备库会与主库建立连接(用于读取 binlog),若备库数量过多(如一主十备),会增加主库的网络 I/O 开销;尤其当备库因延迟需读取旧 binlog 时,主库需从磁盘读取历史日志,进一步增加 I/O 压力。
(3)资源浪费:多备库数据冗余
一主多备架构下,多台备库存储相同数据,且缓存中多为重复数据(如备库均缓存热门商品数据),导致硬件资源(内存、磁盘)利用率低,非经济的部署方式。
关键限制
复制仅适用于 "读扩展",无法优化写操作 ------ 所有写操作仍需在主库执行,备库仅同步主库的写结果,因此写密集型应用无法通过复制提升写性能。
三、主从复制的工作原理:三步完成数据同步
MySQL 主从复制依赖 "主库 binlog""备库 I/O 线程""备库 SQL 线程" 三个核心组件,具体步骤如下(以一主一备为例):
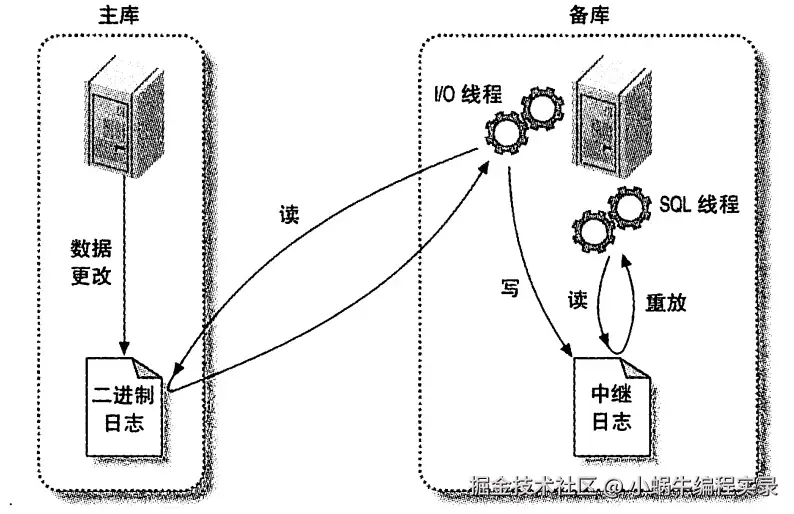
步骤 1:主库记录 binlog
主库在每个事务更新数据完成前,将该操作(语句或行修改)串行写入 binlog 文件 ------binlog 是顺序写入的,I/O 效率高,确保主库所有写操作都被记录。
步骤 2:备库 I/O 线程读取并写入中继日志
备库启动后,会开启一个I/O 线程,该线程与主库建立普通 TCP 连接,并在主库启动一个 "二进制转储线程(binlog dump thread)":
- 二进制转储线程:读取主库 binlog 的新增事件(若已追上主库进度,则进入睡眠状态,等待主库产生新事件);
- I/O 线程:接收主库发送的 binlog 事件,将其写入备库的 "中继日志(relay log)"------ 中继日志格式与 binlog 一致,仅用于备库重放,避免直接修改 binlog。
步骤 3:备库 SQL 线程重放中继日志
备库同时开启一个SQL 线程,该线程读取中继日志中的事件,并按顺序执行(如执行 SQL 语句或修改数据行),最终实现备库数据与主库同步。
关键特性
- 中继日志缓存:当 SQL 线程追赶上 I/O 线程时,中继日志通常已在系统缓存中,因此重放开销低;
- 选择性执行:备库可通过replicate_do_db(复制指定库)、replicate_ignore_table(忽略指定表)等参数,决定执行 binlog 中的哪些事件,默认执行所有事件。
四、主从同步的核心问题:延迟与数据丢失
主从同步的最大挑战是 "主备延迟" 和 "数据丢失",二者本质是异步复制的固有缺陷,需针对性优化。
1. 主从延迟的四大核心原因
主从延迟是指 "主库执行事务后,备库同步该事务的时间差",主要由以下因素导致:
(1)主库写 binlog 的时间
主库执行事务本身需要时间(如复杂 SQL 的执行耗时),只有事务完成后才会写 binlog,因此事务执行耗时越长,延迟的基础越大。
(2)binlog 传输时间
主库 binlog 需通过网络传输到备库,若主备跨地域部署(如跨机房),网络延迟高,传输时间长;若 binlog 体积大(如基于行的复制),传输时间进一步增加。
(3)备库 SQL 线程串行执行(核心瓶颈)
默认情况下,备库仅开启一个 SQL 线程,而主库支持并发写操作(如同时执行多个 UPDATE)------ 备库需将主库的并发写操作串行化执行,导致:
- DDL/DML 竞争:主库上顺序执行的 DDL(如 ALTER TABLE)和 DML(如 INSERT),在备库上可能与其他查询产生锁竞争,阻塞 SQL 线程;
- 高并发场景延迟加剧:当主库每秒执行数百个事务时,备库一个 SQL 线程无法及时重放,延迟逐渐累积(可能达秒级甚至分钟级)。
(4)硬件与资源瓶颈
主备硬件配置差异(如主库用 SSD,备库用机械硬盘)、备库 CPU / 内存不足(如重放复杂 SQL 时 CPU 负载高)、备库磁盘随机 I/O 高(如重放大量 DML 导致频繁写磁盘),均会导致 SQL 线程执行缓慢,增加延迟。
2. 数据丢失的极端场景
当主库突然宕机(如断电、硬件故障)时,若主库已执行的事务未同步到备库(binlog 未传输或备库未重放),则这部分数据在备库中缺失,切换备库后会导致数据不一致。
五、主从同步的优化方案:降低延迟与避免丢失
针对延迟与数据丢失问题,可从 "事务控制""并行复制""架构优化""半同步复制" 四个维度优化:
1. 控制事务大小:减少主库执行与备库重放耗时
- 拆分大事务:将单次修改大量数据的事务(如批量更新 10 万行)拆分为多个小事务(如每次更新 1000 行),避免大事务在主库执行耗时过长,同时减少备库 SQL 线程的阻塞时间;
- 避免长事务:长事务(如持有锁时间久的事务)会导致主库 binlog 记录延迟,且备库重放时易与其他操作冲突,需尽量优化(如缩短事务执行逻辑)。
2. 优化日志传输:减少 binlog 体积与传输时间
- 使用 MIXED 日志格式:MySQL 自动判断场景,简单 SQL 用语句复制(减小 binlog 体积),复杂 SQL 用行复制(确保一致性),平衡体积与准确性;
- 设置binlog_row_image=minimal:基于行的复制时,仅记录 "修改的列"(而非整行数据),大幅减少 binlog 体积,降低传输时间。
3. 并行复制:解决备库 SQL 线程串行瓶颈(MySQL 5.7+)
通过开启备库多 SQL 线程,并行重放中继日志,提升备库同步速度,核心配置如下:
- 停止复制:STOP SLAVE;
- 设置并行复制类型:SET GLOBAL slave_parallel_type = 'logical_clock';------ 按 "逻辑时钟" 分组,同一逻辑时钟的事务可并行执行(主库中并发的事务逻辑时钟不同,备库可并行重放);
- 设置并行线程数:SET GLOBAL slave_parallel_workers = 4;(根据备库 CPU 核心数调整,如 4 核设为 4,8 核设为 8);
- 重启复制:START SLAVE;
并行策略
- 按表分发:若事务修改不同表,可并行执行(适用于分库分表场景);
- 按行分发:若事务修改同表不同行,可并行执行(需slave_parallel_type=logical_clock支持)。
4. 架构优化:分散压力与提升硬件性能
(1)分库分表:分散主库写压力
将大库拆分为多个小库(如按业务拆分为用户库、订单库),每个小库部署主从架构,避免单主库写压力过大,从源头减少延迟。
(2)引入缓存中间件:降低备库读压力
在业务与 MySQL 之间部署缓存(如 Redis),缓存热门读请求(如商品详情、用户信息),减少备库的查询次数,避免备库因读压力大导致 SQL 线程阻塞。
(3)提升备库硬件配置
使用比主库更优的硬件部署备库,减少备库资源瓶颈:
- CPU:用多核 CPU(如 8 核→16 核),提升并行复制线程的执行效率;
- 存储:用 SSD 替代机械硬盘,提升备库重放日志时的随机写性能;
- 网络:主备部署在同一交换机,降低网络延迟,减少 binlog 传输时间。
5. 主从同步加速:牺牲部分安全性换性能
若业务对数据安全性要求不高(如非金融场景),可通过以下配置减少备库开销,加速同步:
(1)降低备库 binlog 安全性
- 备库设置sync_binlog=0:MySQL 不主动刷新 binlog 到磁盘,由文件系统控制刷新 ------ 减少备库写 binlog 的 I/O 开销,但系统崩溃时可能丢失 binlog_cache 中的数据;
- 禁用备库 binlog:若备库无需作为其他备库的主库(即无级联复制),可设置skip-log-bin,直接禁用备库 binlog,避免写 binlog 开销。
(2)优化 InnoDB 日志刷新策略
备库设置innodb_flush_log_at_trx_commit=2:事务提交时,InnoDB 将 redo log 从缓存写入日志文件,但不立即刷新到磁盘(文件系统每秒刷新一次)------ 减少备库磁盘 I/O,即使崩溃,最多丢失 1-2 秒的更新,平衡性能与安全性。
6. 半同步复制:避免数据丢失(牺牲部分性能)
半同步复制(semi-sync replication)是 MySQL 解决数据丢失的核心方案,通过 "主库等待备库确认" 实现准同步:
原理
- 主库执行事务并写入 binlog 后,不立即返回结果,而是等待至少一个备库的确认;
- 备库 I/O 线程收到 binlog 并写入中继日志后,向主库返回一个 "ack(确认)";
- 主库收到 ack 后,才向客户端返回 "事务执行成功",确保事务已同步到至少一个备库。
特点
- 数据安全性高:主库宕机时,至少有一个备库已同步该事务,避免数据丢失;
- 性能降低:主库需等待备库 ack,增加事务响应时间(如网络延迟 10ms,事务响应时间增加 10ms),适用于数据安全性要求高的场景(如金融交易)。
配置
- 主库安装半同步插件:INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
- 备库安装半同步插件:INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
- 启用主库半同步:SET GLOBAL rpl_semi_sync_master_enabled = 1;
- 启用备库半同步:SET GLOBAL rpl_semi_sync_slave_enabled = 1;
- 重启备库 I/O 线程:STOP SLAVE IO_THREAD; START SLAVE IO_THREAD;
六、总结:主从复制的核心应用原则
MySQL 主从复制是高可用架构的基础,实际应用中需遵循以下原则:
- 复制类型选择:数据一致性要求高选 "基于行的复制",需减小 binlog 体积选 "MIXED 格式";
- 延迟优化优先级:先开启并行复制(解决核心瓶颈),再优化硬件与事务大小,最后考虑牺牲安全性的加速配置;
- 数据安全权衡:非核心业务用异步复制(保性能),核心业务用半同步复制(保数据);
- 架构扩展:读密集场景用一主多备(分流读压力),写密集场景结合分库分表(分散写压力),避免单主库瓶颈。
理解主从复制的原理与优化手段,可帮助构建稳定、高效的 MySQL 架构,平衡 "性能""可用性""数据安全性",满足不同业务场景的需求。