一、介绍
1.1 简介
PowerJob是一款分布式任务调度工具。
- 拥有可视化界面,可以在界面对定时任务进行增删改查
- 拥有多种定时策略,常见的就是corn表达式、固定频率
- 支持在线日志,方便错误定位以及运维
其他详细信息请查看
文档:www.yuque.com/powerjob/gu...
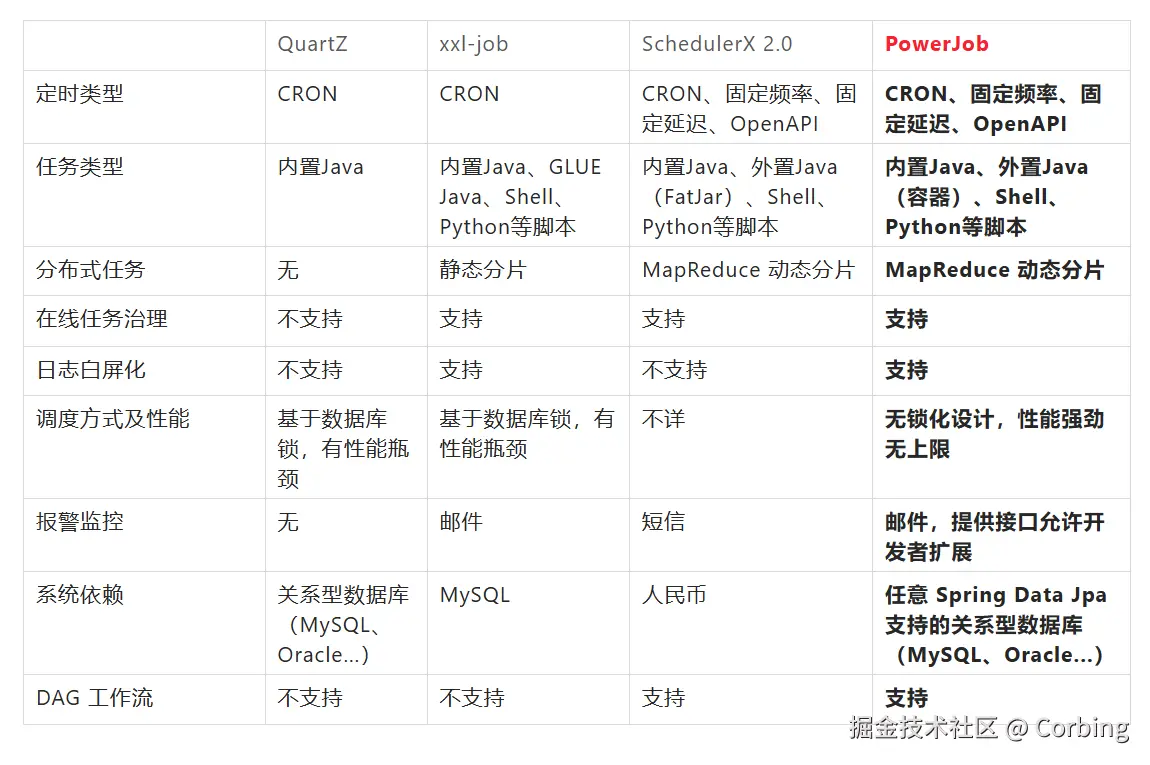
1.2 选型对比
1.3 基本概念
- appName:应用名称,用于业务分组隔离,一般使用我们的spring.application.name 作为appName
- Job:任务,需要被PowerJob调度的任务信息
- JobInstance:任务实例,任务被调度后会生成任务实例,类似于类和对象的关系
- Task:作业,一个任务实例至少有一个作业,具体规则如下
- STANDALONE:单机任务,一个实例对应一个作业
- BROADCAST:广播任务,一个实例对应N个作业,这里的N为集群机器的数量,即每一台机器都会生成一个Task
- Map/MapReduce任务:一个 JobInstance 对应若干个 Task,由开发者手动 map 产生
- 工作流(Workflow):由 DAG(有向无环图)描述的一组任务(Job),用于任务编排。
- 工作流实例(WorkflowInstance):工作流被调度执行后会生成工作流实例,记录了工作流的运行时信息。
1.4 定时任务类型
- API:该任务只会由 powerjob-client 中提供的 OpenAPI 接口触发,server 不会主动调度。
- CRON:该任务的调度时间由 CRON 表达式指定。
- 固定频率:秒级任务,每隔多少毫秒运行一次,功能与 java.util.concurrent.ScheduledExecutorService#scheduleAtFixedRate 相同。
- 固定延迟:秒级任务,延迟多少毫秒运行一次,功能与 java.util.concurrent.ScheduledExecutorService#scheduleWithFixedDelay 相同。
- 工作流:该任务只会由其所属的工作流调度执行,server 不会主动调度该任务。如果该任务不属于任何一个工作流,该任务就不会被调度。
备注:固定延迟和固定频率任务统称秒级任务,这两种任务无法被停止,只有任务被关闭或删除时才能真正停止任务。
1.5 项目结构说明
plain
├── LICENSE
├── powerjob-client // powerjob-client,普通Jar包,提供 OpenAPI
├── powerjob-common // 各组件的公共依赖,开发者无需感知
├── powerjob-remote // 内部通讯层框架,开发者无需感知
├── powerjob-server // powerjob-server,基于SpringBoot实现的调度服务器
├── powerjob-worker // powerjob-worker, 普通Jar包,接入powerjob-server的应用需要依赖该Jar包
├── powerjob-worker-agent // powerjob-agent,可执行Jar文件,可直接接入powerjob-server的代理应用
├── powerjob-worker-samples // 教程项目,包含了各种Java处理器的编写样例
├── powerjob-worker-spring-boot-starter // powerjob-worker 的 spring-boot-starter ,spring boot 应用可以通用引入该依赖一键接入 powerjob-server
├── powerjob-official-processors // 官方处理器,包含一系列常用的 Processor,依赖该 jar 包即可使用
├── others
└── pom.xml二、本地搭建PowerJob环境
2.1 拉取项目
plain
git clone https://github.com/PowerJob/PowerJob.git2.2 创建数据库
项目目录下找到01schema.sql 创建数据库
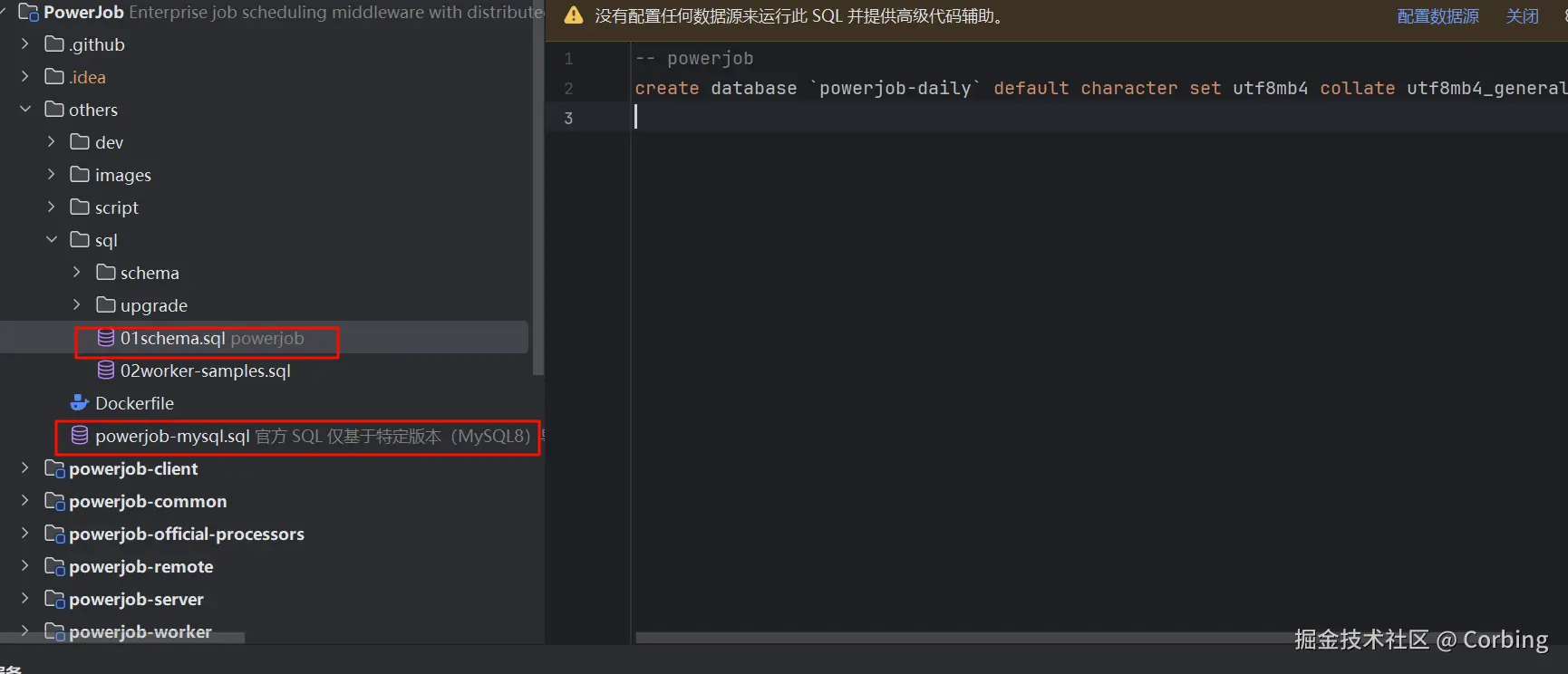
plain
-- powerjob
create database `powerjob-daily`
default character
set utf8mb4 collate utf8mb4_general_ci;项目目录下找到powerjob-mysql.sql新建表结构
plain
/*
官方 SQL 仅基于特定版本(MySQL8)导出,不一定兼容其他数据库,也不一定兼容其他版本。此 SQL 仅供参考。
如果您的数据库无法使用此 SQL,建议使用 SpringDataJPA 自带的建表能力,先在开发环境直连测试库自动建表,然后自行导出相关的 SQL 即可。
*/
/*
Navicat Premium Data Transfer
Source Server : Local@3306
Source Server Type : MySQL
Source Server Version : 80300 (8.3.0)
Source Host : localhost:3306
Source Schema : powerjob5g
Target Server Type : MySQL
Target Server Version : 80300 (8.3.0)
File Encoding : 65001
Date: 17/08/2025 21:58:30
*/
SET NAMES utf8mb4;
SET
FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for app_info
-- ----------------------------
DROP TABLE IF EXISTS `app_info`;
CREATE TABLE `app_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`app_name` varchar(255) DEFAULT NULL,
`creator` bigint DEFAULT NULL,
`current_server` varchar(255) DEFAULT NULL,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`modifier` bigint DEFAULT NULL,
`namespace_id` bigint DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`tags` varchar(255) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_app_info` (`app_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for container_info
-- ----------------------------
DROP TABLE IF EXISTS `container_info`;
CREATE TABLE `container_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`app_id` bigint DEFAULT NULL,
`container_name` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`last_deploy_time` datetime(6) DEFAULT NULL,
`source_info` varchar(255) DEFAULT NULL,
`source_type` int DEFAULT NULL,
`status` int DEFAULT NULL,
`version` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx01_container_info` (`app_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for instance_info
-- ----------------------------
DROP TABLE IF EXISTS `instance_info`;
CREATE TABLE `instance_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`actual_trigger_time` bigint DEFAULT NULL,
`app_id` bigint DEFAULT NULL,
`expected_trigger_time` bigint DEFAULT NULL,
`extend_value` varchar(255) DEFAULT NULL,
`finished_time` bigint DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`instance_id` bigint DEFAULT NULL,
`instance_params` longtext,
`job_id` bigint DEFAULT NULL,
`job_params` longtext,
`last_report_time` bigint DEFAULT NULL,
`meta` varchar(255) DEFAULT NULL,
`outer_key` varchar(255) DEFAULT NULL,
`result` longtext,
`running_times` bigint DEFAULT NULL,
`status` int DEFAULT NULL,
`task_tracker_address` varchar(255) DEFAULT NULL,
`type` int DEFAULT NULL,
`wf_instance_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx01_instance_info` (`job_id`,`status`),
KEY `idx02_instance_info` (`app_id`,`status`),
KEY `idx03_instance_info` (`instance_id`,`status`),
KEY `idx04_instance_info_outer_key` (`outer_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for job_info
-- ----------------------------
DROP TABLE IF EXISTS `job_info`;
CREATE TABLE `job_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`advanced_runtime_config` varchar(255) DEFAULT NULL,
`alarm_config` varchar(255) DEFAULT NULL,
`app_id` bigint DEFAULT NULL,
`concurrency` int DEFAULT NULL,
`designated_workers` varchar(255) DEFAULT NULL,
`dispatch_strategy` int DEFAULT NULL,
`dispatch_strategy_config` varchar(255) DEFAULT NULL,
`execute_type` int DEFAULT NULL,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`instance_retry_num` int DEFAULT NULL,
`instance_time_limit` bigint DEFAULT NULL,
`job_description` varchar(255) DEFAULT NULL,
`job_name` varchar(255) DEFAULT NULL,
`job_params` longtext,
`lifecycle` varchar(255) DEFAULT NULL,
`log_config` varchar(255) DEFAULT NULL,
`max_instance_num` int DEFAULT NULL,
`max_worker_count` int DEFAULT NULL,
`min_cpu_cores` double NOT NULL,
`min_disk_space` double NOT NULL,
`min_memory_space` double NOT NULL,
`next_trigger_time` bigint DEFAULT NULL,
`notify_user_ids` varchar(255) DEFAULT NULL,
`processor_info` varchar(255) DEFAULT NULL,
`processor_type` int DEFAULT NULL,
`status` int DEFAULT NULL,
`tag` varchar(255) DEFAULT NULL,
`task_retry_num` int DEFAULT NULL,
`time_expression` varchar(255) DEFAULT NULL,
`time_expression_type` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx01_job_info` (`app_id`,`status`,`time_expression_type`,`next_trigger_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for namespace
-- ----------------------------
DROP TABLE IF EXISTS `namespace`;
CREATE TABLE `namespace`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`code` varchar(255) DEFAULT NULL,
`creator` bigint DEFAULT NULL,
`dept` varchar(255) DEFAULT NULL,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`modifier` bigint DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`status` int DEFAULT NULL,
`tags` varchar(255) DEFAULT NULL,
`token` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_namespace` (`code`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for oms_lock
-- ----------------------------
DROP TABLE IF EXISTS `oms_lock`;
CREATE TABLE `oms_lock`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`lock_name` varchar(255) DEFAULT NULL,
`max_lock_time` bigint DEFAULT NULL,
`ownerip` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_oms_lock` (`lock_name`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for pwjb_user_info
-- ----------------------------
DROP TABLE IF EXISTS `pwjb_user_info`;
CREATE TABLE `pwjb_user_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`username` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for server_info
-- ----------------------------
DROP TABLE IF EXISTS `server_info`;
CREATE TABLE `server_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`ip` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_server_info` (`ip`),
KEY `idx01_server_info` (`gmt_modified`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for sundry
-- ----------------------------
DROP TABLE IF EXISTS `sundry`;
CREATE TABLE `sundry`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`content` varchar(255) DEFAULT NULL,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`pkey` varchar(255) DEFAULT NULL,
`skey` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_sundry` (`pkey`,`skey`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for user_info
-- ----------------------------
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`account_type` varchar(255) DEFAULT NULL,
`email` varchar(255) DEFAULT NULL,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`nick` varchar(255) DEFAULT NULL,
`origin_username` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`phone` varchar(255) DEFAULT NULL,
`status` int DEFAULT NULL,
`token_login_verify_info` varchar(255) DEFAULT NULL,
`username` varchar(255) DEFAULT NULL,
`web_hook` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_user_name` (`username`),
KEY `uidx02_user_info` (`email`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for user_role
-- ----------------------------
DROP TABLE IF EXISTS `user_role`;
CREATE TABLE `user_role`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`role` int DEFAULT NULL,
`scope` int DEFAULT NULL,
`target` bigint DEFAULT NULL,
`user_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `uidx01_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for workflow_info
-- ----------------------------
DROP TABLE IF EXISTS `workflow_info`;
CREATE TABLE `workflow_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`app_id` bigint DEFAULT NULL,
`extra` varchar(255) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`lifecycle` varchar(255) DEFAULT NULL,
`max_wf_instance_num` int DEFAULT NULL,
`next_trigger_time` bigint DEFAULT NULL,
`notify_user_ids` varchar(255) DEFAULT NULL,
`pedag` longtext,
`status` int DEFAULT NULL,
`time_expression` varchar(255) DEFAULT NULL,
`time_expression_type` int DEFAULT NULL,
`wf_description` varchar(255) DEFAULT NULL,
`wf_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx01_workflow_info` (`app_id`,`status`,`time_expression_type`,`next_trigger_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for workflow_instance_info
-- ----------------------------
DROP TABLE IF EXISTS `workflow_instance_info`;
CREATE TABLE `workflow_instance_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`actual_trigger_time` bigint DEFAULT NULL,
`app_id` bigint DEFAULT NULL,
`dag` longtext,
`expected_trigger_time` bigint DEFAULT NULL,
`finished_time` bigint DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
`parent_wf_instance_id` bigint DEFAULT NULL,
`result` longtext,
`status` int DEFAULT NULL,
`wf_context` longtext,
`wf_init_params` longtext,
`wf_instance_id` bigint DEFAULT NULL,
`workflow_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx01_wf_instance` (`wf_instance_id`),
KEY `idx01_wf_instance` (`workflow_id`,`status`,`app_id`,`expected_trigger_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
-- ----------------------------
-- Table structure for workflow_node_info
-- ----------------------------
DROP TABLE IF EXISTS `workflow_node_info`;
CREATE TABLE `workflow_node_info`
(
`id` bigint NOT NULL AUTO_INCREMENT,
`app_id` bigint NOT NULL,
`enable` bit(1) NOT NULL,
`extra` longtext,
`gmt_create` datetime(6) NOT NULL,
`gmt_modified` datetime(6) NOT NULL,
`job_id` bigint DEFAULT NULL,
`node_name` varchar(255) DEFAULT NULL,
`node_params` longtext,
`skip_when_failed` bit(1) NOT NULL,
`type` int DEFAULT NULL,
`workflow_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx01_workflow_node_info` (`workflow_id`,`gmt_create`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
SET
FOREIGN_KEY_CHECKS = 1;powerjob-server 日常环境配置文件:application-daily.properties
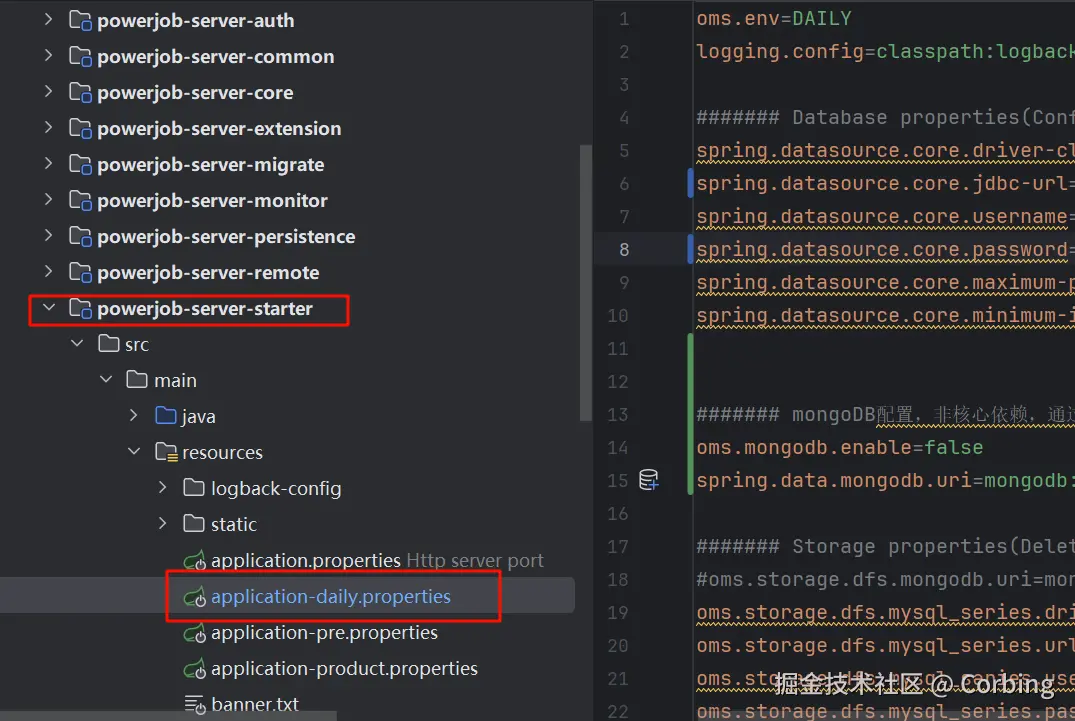
如果mongodb没有的话,可以将enable设置为false
plain
oms.env=DAILY
logging.config=classpath:logback-dev.xml
####### 外部数据库配置(需要用户更改为自己的数据库配置) #######
spring.datasource.core.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.core.jdbc-url=jdbc:mysql://localhost:3306/powerjob-daily?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
spring.datasource.core.username=root
spring.datasource.core.password=No1Bug2Please3!
spring.datasource.core.hikari.maximum-pool-size=20
spring.datasource.core.hikari.minimum-idle=5
####### mongoDB配置,非核心依赖,通过配置 oms.mongodb.enable=false 来关闭 #######
oms.mongodb.enable=true
spring.data.mongodb.uri=mongodb://localhost:27017/powerjob-daily
####### 邮件配置(不需要邮件报警可以删除以下配置来避免报错) #######
spring.mail.host=smtp.163.com
spring.mail.username=zqq@163.com
spring.mail.password=GOFZPNARMVKCGONV
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
####### 资源清理配置 #######
oms.instanceinfo.retention=1
oms.container.retention.local=1
oms.container.retention.remote=-1
####### 缓存配置 #######
oms.instance.metadata.cache.size=1024
####### 用户与权限体系配置 #######
oms.auth.initiliaze.admin.password=powerjob_admin2.3 启动应用
右键调试 PowerJobServerApplication
访问Web页面:http://localhost:7700
账号:ADMIN,密码:powerjob_admin
三、Docker搭建PowerJob环境
3.1 拉取项目
plain
git clone --depth=1 https://github.com/PowerJob/PowerJob.git3.2 docker-compose启动
在正式运行之前,首先需要删除低版本 powerjob 相关依赖
plain
docker rmi $(docker images | grep "powerjob" | awk '{print $3}') 进入到PowerJob工作目录
plain
cd PowerJob
# 前台运行(初次运行时,推荐使用该方式,方便实时查看日志,排查问题)
docker-compose up
# 后台运行
docker-compose up -d刚开始启动时,powerjob-worker-samples会启动失败,等powerjob-server启动成功后,powerjob-worker-samples才会启动成功。这大概需要几分钟。
3.3 启动成功
运行成功后,浏览器访问 http://127.0.0.1:7700/
应用名称:powerjob-worker-samples
密码:powerjob123
3.4 停止应用
plain
docker-compose down
Stopping powerjob-worker-samples ... done
Stopping powerjob-server ... done
Stopping powerjob-mysql ... done
Removing powerjob-worker-samples ... done
Removing powerjob-server ... done
Removing powerjob-mysql ... done
# 删除数据目录
cd PowerJob
rm -rf powerjob-data3.4. 进阶使用
plain
# 使用说明 V4.3.1
# 1. PowerJob 根目录执行:docker-compose up
# 2. 静静等待服务启动。
version: '3'
services:
powerjob-mysql:
environment:
MYSQL_ROOT_HOST: "%"
MYSQL_ROOT_PASSWORD: No1Bug2Please3!
restart: always
container_name: powerjob-mysql
image: powerjob/powerjob-mysql:latest
ports:
- "3307:3306"
volumes:
- ./powerjob-data/powerjob-mysql:/var/lib/mysql
command: --lower_case_table_names=1
powerjob-server:
container_name: powerjob-server
image: powerjob/powerjob-server:latest
restart: always
depends_on:
- powerjob-mysql
environment:
JVMOPTIONS: "-Xmx512m"
PARAMS: "--oms.mongodb.enable=false --spring.datasource.core.jdbc-url=jdbc:mysql://powerjob-mysql:3306/powerjob-daily?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai"
ports:
- "7700:7700"
- "10086:10086"
- "10010:10010"
- "10077:10077"
volumes:
- ./powerjob-data/powerjob-server:/root/powerjob/server/
powerjob-worker-samples:
container_name: powerjob-worker-samples
image: powerjob/powerjob-worker-samples:latest
restart: always
depends_on:
- powerjob-mysql
- powerjob-server
# environment:
# PARAMS: "--powerjob.worker.server-address=powerjob-server:7700"
ports:
- "8081:8081"
- "27777:27777"
volumes:
- ./powerjob-data/powerjob-worker-samples:/root/powerjob/worker
- ./others/script/wait-for-it.sh:/wait-for-it.sh
entrypoint:
- "sh"
- "-c"
- "chmod +x wait-for-it.sh && ./wait-for-it.sh powerjob-server:7700 --strict -- java -Xmx512m -jar /powerjob-worker-samples.jar --powerjob.worker.server-address=powerjob-server:7700"docker-compose方式运行,会创建3个容器:
- powerjob-mysql :存储 PowerJob 服务端运行时数据,启动时会自动创建
powerjob-daily数据库,用户名:root,密码:No1Bug2Please3!; - powerjob-server:
PowerJob服务端,源码路径:PowerJob/powerjob-server/powerjob-server-starter; - powerjob-worker-samples:PowerJob 提供的 Worker 示例,源码路径:PowerJob/powerjob-worker-samples。
注意:如果我们不想再创建一个MySQL应用,我们可以把powerjob-mysql去掉,然后修改powerjob-server的数据库信息为我们自己的数据库信息
四、SpringBoot集成PowerJob
4.1 引入依赖
plain
<dependency>
<groupId>tech.powerjob</groupId>
<artifactId>powerjob-worker-spring-boot-starter</artifactId>
<version>${latest.powerjob.version}</version>
</dependency>4.2 配置文件
plain
###Powerjob配置
powerjob:
worker:
# akka 工作端口,可选,默认 27777
akka-port: 27777
# 接入应用名称,用于分组隔离,推荐填写 本 Java 项目名称
app-name: ${spring.application.name}
# 调度服务器地址,IP:Port 或 域名,多值逗号分隔
server-address: 81.70.117.188:7700
# 持久化方式,可选,默认 disk
store-strategy: disk
# 任务返回结果信息的最大长度,超过这个长度的信息会被截断,默认值 8192
max-result-length: 8192
# 单个任务追加的工作流上下文最大长度,超过这个长度的会被直接丢弃,默认值 8192
max-appended-wf-context-length: 81924.3 处理器开发示例
4.3.1 单机处理器
单机执行的策略下,server 会在所有可用 worker 中选取健康度最佳的机器进行执行。单机执行任务需要实现接口 BasicProcessor,代码示例如下:
java
@Component
@Slf4j
public class StandaloneProcessor implements BasicProcessor {
@Override
public ProcessResult process(TaskContext context) throws Exception {
OmsLogger omsLogger = context.getOmsLogger();
omsLogger.info("处理器启动成功,context 是 {}.", context);
log.info("单机处理器正在处理");
log.info(context.getJobParams());
omsLogger.info("处理器执行结束");
boolean success = true;
return new ProcessResult(success, context + ": " + success);
}
}4.3.2 广播处理器
广播执行的策略下,所有机器都会被调度执行该任务。为了便于资源的准备和释放,广播处理器在BasicProcessor 的基础上额外增加了 preProcess 和 postProcess 方法,分别在整个集群开始之前/结束之后选一台机器执行相关方法。代码示例如下:
java
@Slf4j
@Component
public class BroadcastProcessorDemo implements BroadcastProcessor {
@Override
public ProcessResult preProcess(TaskContext context) throws Exception {
OmsLogger omsLogger = context.getOmsLogger();
omsLogger.info("预执行,会在所有 worker 执行 process 方法前调用");
log.info("预执行,会在所有 worker 执行 process 方法前调用");
// 预执行,会在所有 worker 执行 process 方法前调用
return new ProcessResult(true, "init success");
}
@Override
public ProcessResult process(TaskContext context) throws Exception {
OmsLogger omsLogger = context.getOmsLogger();
// 撰写整个worker集群都会执行的代码逻辑
omsLogger.info("撰写整个worker集群都会执行的代码逻辑");
log.info("撰写整个worker集群都会执行的代码逻辑");
return new ProcessResult(true, "release resource success");
}
@Override
public ProcessResult postProcess(TaskContext context, List<TaskResult> taskResults) throws Exception {
// taskResults 存储了所有worker执行的结果(包括preProcess)
// 收尾,会在所有 worker 执行完毕 process 方法后调用,该结果将作为最终的执行结果
OmsLogger omsLogger = context.getOmsLogger();
omsLogger.info("收尾,会在所有 worker 执行完毕 process 方法后调用,该结果将作为最终的执行结果");
log.info("收尾,会在所有 worker 执行完毕 process 方法后调用,该结果将作为最终的执行结果");
return new ProcessResult(true, "process success");
}
}4.3.3 并行处理器
MapReduce 是最复杂也是最强大的一种执行器,它允许开发者完成任务的拆分,将子任务派发到集群中其他Worker 执行,是执行大批量处理任务的不二之选!实现 MapReduce 处理器需要继承 MapReduceProcessor类,具体用法如下示例代码所示:
java
@Slf4j
@Component
public class MapReduceProcessorDemo implements MapReduceProcessor {
@Override
public ProcessResult process(TaskContext context) throws Exception {
final OmsLogger omsLogger = context.getOmsLogger();
// 判断是否为根任务
if (isRootTask()) {
// 构造子任务
List<SubTask> subTaskList = Lists.newLinkedList();
SubTask subTask=new SubTask();
subTask.setSiteId(1L);
subTask.setName("iron.guo");
subTaskList.add(subTask);
/*
* 子任务的构造由开发者自己定义
* eg. 现在需要从文件中读取100W个ID,并处理数据库中这些ID对应的数据,那么步骤如下:
* 1. 根任务(RootTask)读取文件,流式拉取100W个ID,并按1000个一批的大小组装成子任务进行派发
* 2. 非根任务获取子任务,完成业务逻辑的处理
*/
// 调用 map 方法,派发子任务(map 可能会失败并抛出异常,做好业务操作)
map(subTaskList, "DATA_PROCESS_TASK");
omsLogger.info("执行根任务-派发子任务");
return new ProcessResult(true, "ROOT_PROCESS_SUCCESS");
}
// 非子任务,可根据 subTask 的类型 或 TaskName 来判断分支
if (context.getSubTask() instanceof SubTask) {
omsLogger.info("执行子任务开始");
omsLogger.info("Get from SubTask : name is {} and id is {}",((SubTask) context.getSubTask()).getName(),((SubTask) context.getSubTask()).getSiteId());
// 执行子任务,注:子任务人可以 map 产生新的子任务,可以构建任意级的 MapReduce 处理器
return new ProcessResult(true, "PROCESS_SUB_TASK_SUCCESS");
}
return new ProcessResult(false, "UNKNOWN_BUG");
}
@Override
public ProcessResult reduce(TaskContext taskContext, List<TaskResult> taskResults) {
// 所有 Task 执行结束后,reduce 将会被执行
// taskResults 保存了所有子任务的执行结果
// 用法举例,统计执行结果
AtomicLong successCnt = new AtomicLong(0);
taskResults.forEach(tr -> {
if (tr.isSuccess()) {
successCnt.incrementAndGet();
}
});
// 该结果将作为任务最终的执行结果
return new ProcessResult(true, "success task num:" + successCnt.get());
}
// 自定义的子任务
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
private static class SubTask {
private Long siteId;
private String name;
}
}五、常用操作
5.1 新建命名空间
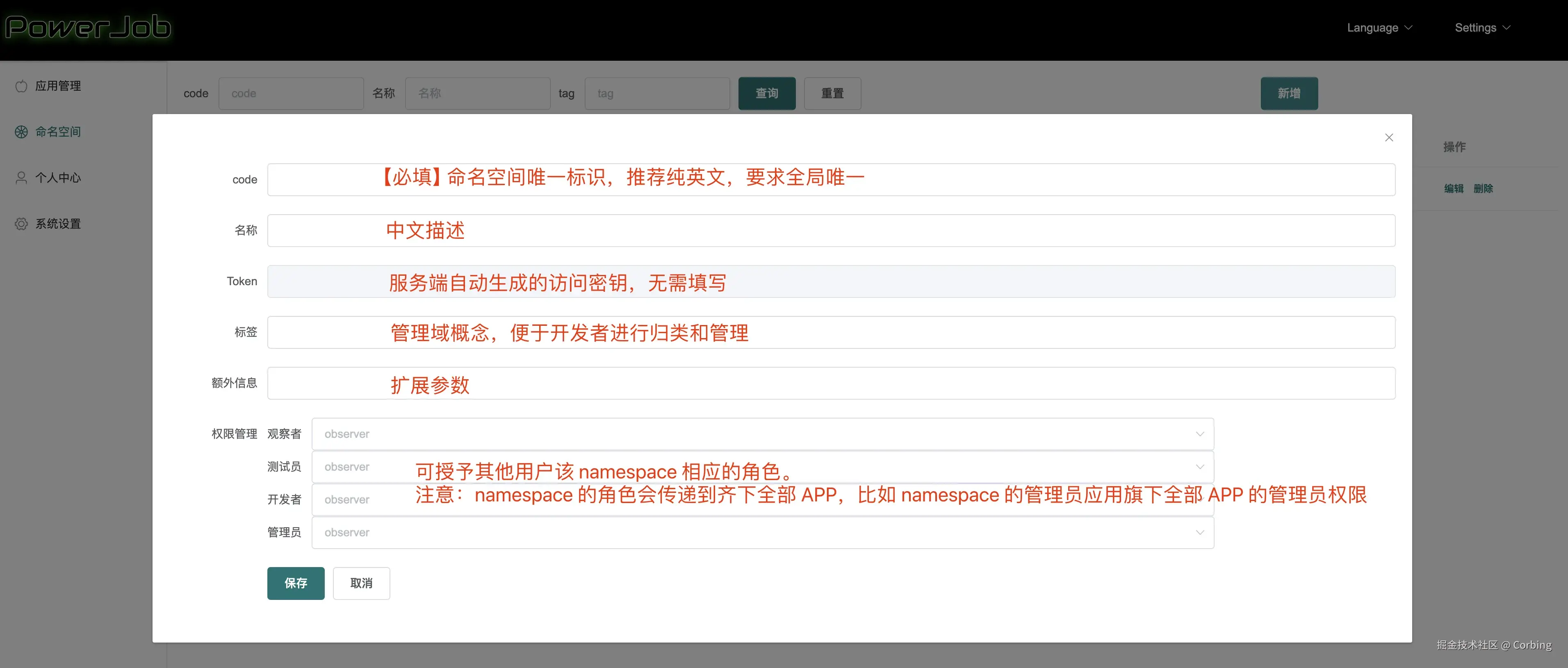
命名空间是提供一个二级分类的概念
5.2 新建应用
一个应用可以理解为一个java程序

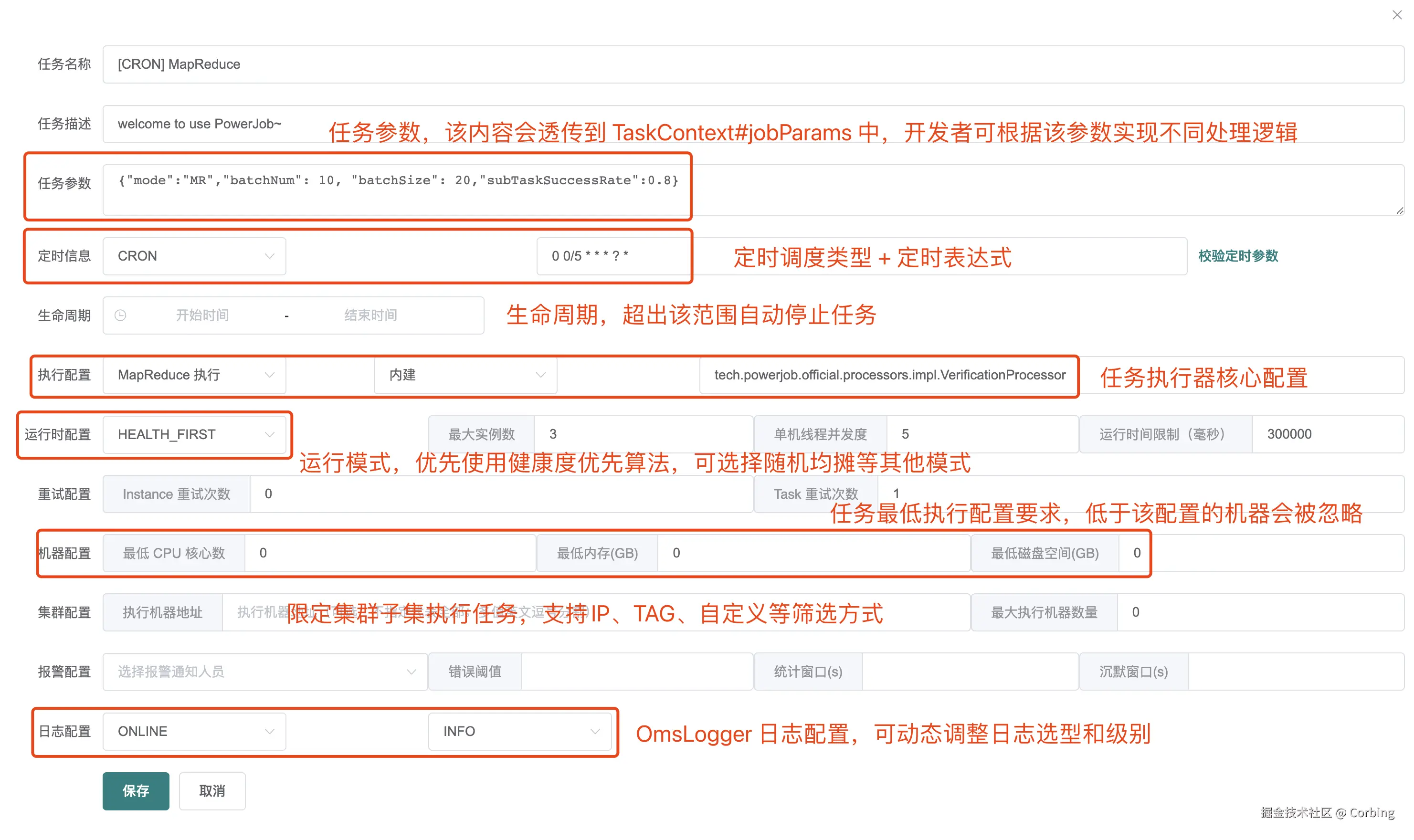
5.3 新建任务
进入应用,新建任务(一个java程序可以有多个任务)
cron生成器:cron.qqe2.com/