ApacheSpark是一个开源的大数据处理框架,它提供了丰富的功能和API,用于分布式数据处理、数据分析和机器学习等任务。在SpringBoot中整合ApacheSpark可以实现更加灵活和高效的数据分析应用。下面我们就来看看如何在SpringBoot应用中整合ApacheSpark。
第一步、添加依赖
由于需要用到Apache Spark数据处理相关的功能,所以需要引入Spark的SQL依赖,如下所示。
xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.4.2</version>
</dependency>第二步、编写配置类
在SpringBoot项目中创建SparkConfig配置类并且添加SparkSession的依赖Bean。
kotlin
@Configuration
public class SparkConfig {
@Bean
public SparkSession sparkSession() {
return SparkSession.builder()
.appName("SpringBootSparkIntegration")
.master("local[*]") // 在本地模式下运行
.getOrCreate();
}
}第三步、编写控制类
创建一个Controller类,用于处理请求并调用ApacheSpark进行数据分析
less
@RestController
@RequestMapping("/test")
public class TestController {
@Autowired
private SparkSession sparkSession;
@GetMapping("/analyze")
public Map<String,Object> test(){
Map<String,Object> ajax = new HashMap<>();
// 创建 SparkContext
JavaSparkContext sparkContext = JavaSparkContext.fromSparkContext(sparkSession.sparkContext());
// 创建一个 RDD
JavaRDD<Integer> dataRDD = sparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5));
// 执行一些数据分析操作
long count = dataRDD.count();
List<Person> personList = Arrays.asList(new Person("Alice", 30), new Person("Bob", 25));
// 创建一个 Dataset
Dataset<Row> dataset = sparkSession.createDataFrame(personList, Person.class);
// 执行一些 SQL 查询
dataset.createOrReplaceTempView("people");
Dataset<Row> result = sparkSession.sql("SELECT * FROM people");
ajax.put("data",count);
ajax.put("result",result.collectAsList().get(0).json());
sparkSession.stop();
return ajax;
}
}Person实体类如下所示。
arduino
public class Person implements Serializable {
private String name;
private int age;
public Person() {}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// Getters and setters
}这里需要注意,直接引入Apache Spark的时候,在项目启动的时候会报一个HADOOP_HOME不存在的异常。这个异常是可以忽略的,当然如果需要解决的话,就可以到
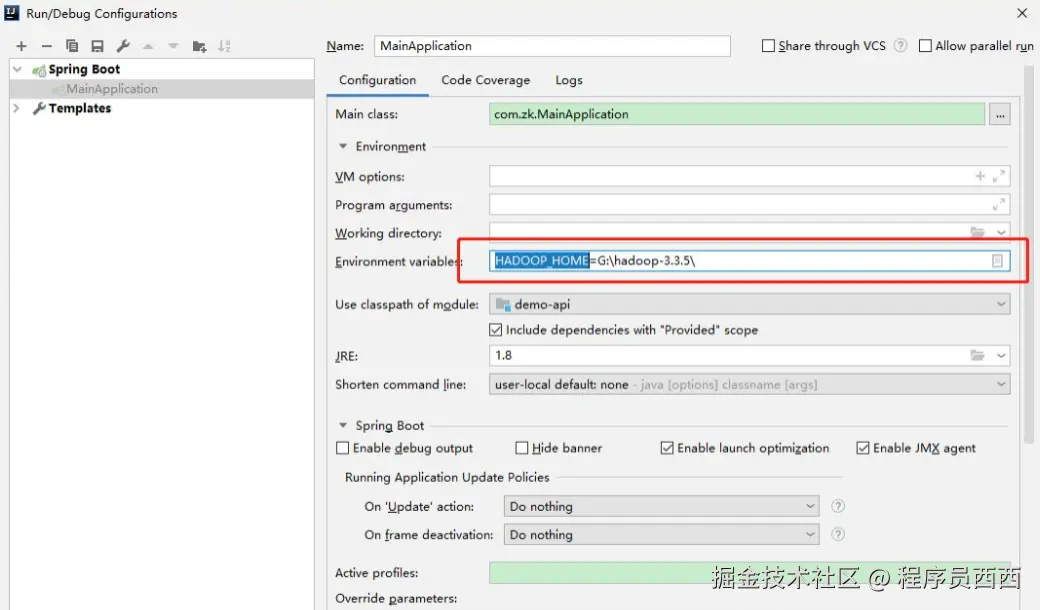
添加配置完成之后项目启动就正常了。
启动项目并测试
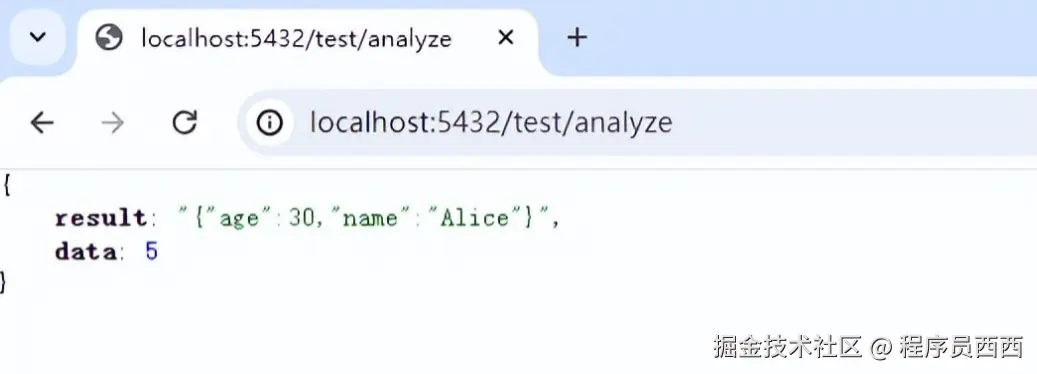
启动SpringBoot应用,并访 /analyze路径,即可触发数据分析操作。如下所示。
总结
到这里,你就可以在SpringBoot应用中使用ApacheSpark进行数据分析了。当然,实际应用中可能会涉及更加复杂的数据处理和分析任务,你可以根据实际需求扩展和优化代码。