概要
在一些 ToB、ToC 场景中,经常会有一种业务:上游系统产生商品订单需要推送到下游系统进行订单处理(生成财务,生成报表,经营分析等等)
比如身边的中大厂朋友告诉我的例子:
- Alibaba:天猫生成支付订单,同步 WMS 进行打包发货;
- 平安银行:用户贷款审批信息同步央行征信系统;
- xx科技:海外广告投放数据回流到本地系统,用于公司投放部门和经营部门的业绩分析;
上述举例中,最终的目的就是将上游系统与下游系统形成一个解耦的链路;
在不同的厂商中,数据同步的实现方式各有不同,例如:最原始最暴力的,下游系统采用RPC拉取上游订单信息、下游系统使用RocketMQ进行解耦、又或者上下游作为公司内部产品,内部使用DataX、ESB、自研中间件的形式来解决;
上述的各种方案都为了一件事,解耦;
业务背景
博主所在公司作为国内 Top5 的ERP厂商(具体名字不方便透露),旗下拥有多款自研产品,其中最重要的就是进销存系统和财务系统;
进销存系统在2019年全面进行升级重构,但财务系统依旧还是15年的Nodejs老代码为数十万家中小客户进行服务,每个月底在进销存进行月结后大批量订单(目前监测到月均1400w+,单量不固定,618和双十一单量更大)采用RPC往财务系统推送;
但随着时间的推移以及客户量的增多(公司销售业绩变好了),老财务系统渐渐显露出来缺陷,问题主要集中在以下几个方面:
- ERP客户订单量逐年增多,RPC推送慢,网络开销大,推送失败后的处理不及时
- 财务端接收订单数量单表膨胀导致查询卡顿现象
- 旧系统无法接入Apollo,每次改配置需要发版,测试同事不接受(不过这不是主要原因,把测试屌一顿就好了/手动狗头)
- 旧财务系统满足不了客户的新需求工单,老代码因为技术栈原因没办法改(懂得都懂)
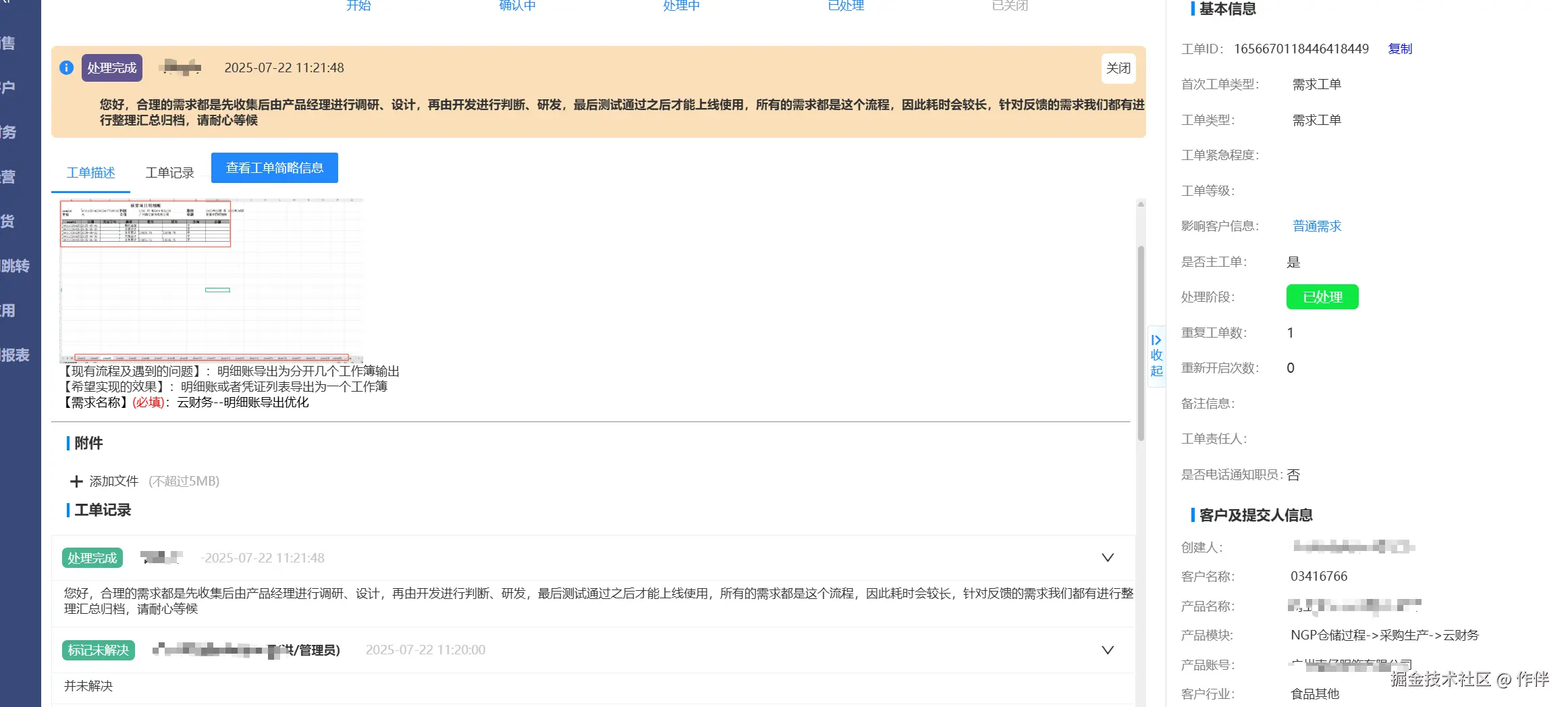
综合业务上的问题和技术上的问题,决定对老系统进行项目重构,采用Java微服务+多租户架构对老系统进行统一重构;
看到这里可能有同学会疑惑,为什么单量非要放在月底来统一同步,而不是每天定时定量同步?原因如下:
- 对于财务系统,每天从ERP获取到的业务数据转成财务数据之后并没有参考性,况且ERP中的单据经常发生变动,如果在财务方生成凭证后ERP单据发生了变化,财务无法及时获取到消息去更新凭证,会导致月底对账难度极大(客户真实场景,折磨我们处理技术工单)
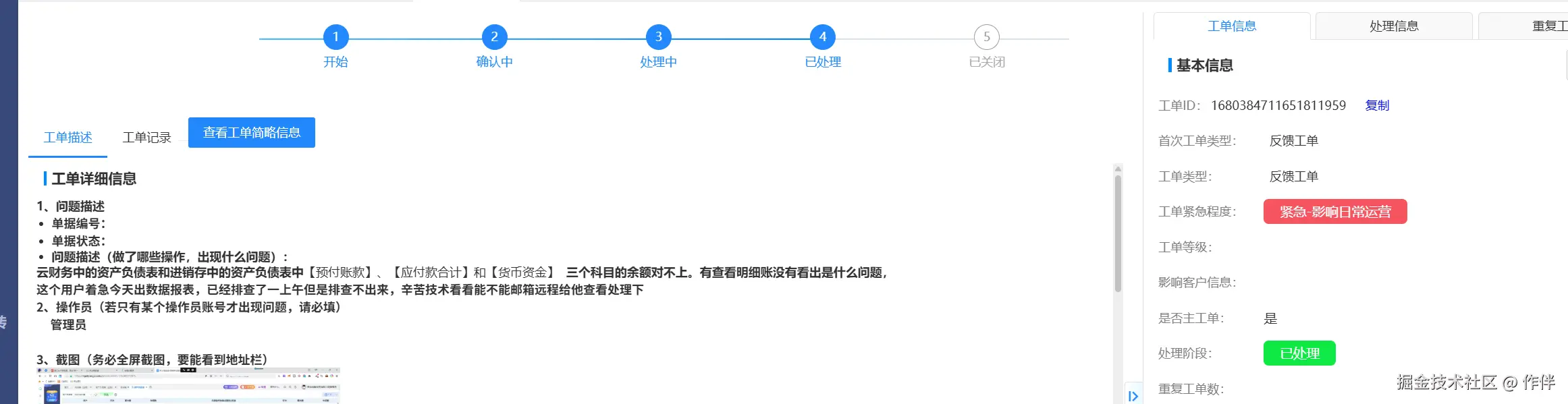
- 对于ERP系统,商品成本是多变的(ERP的三种成本算法:全月加权,移动加权,个别计价),没到月底月结,商品的成本都是不固定的,所以无法得到一个有效的确切成本值,会直接影响到财务系统中的利润表和资产负债表
技术选型
在征得大老板的同意后,我们首先分析原有财务系统架构;原有财务系统也是多租户模式,我们在新系统上也决定采用多租户模式,方便后续做数据迁移;
架构选型
多租户架构在目前行业内比较火的三种模式,综合考虑数据隔离性,成本和系统扩展性:
- 独立数据库:这种在数据隔离性上最好,但是带来的成本和运维管理复杂度也是随着用户的增长而越来越大的,方案被 pass 掉(光是成本这一个原因就被老板 pass 了);
- 共享数据库+独立 Schema:将用户放在同一个数据库中,为每一个用户都准备一个 Schema。好处就是数据库能统一进行管理,坏处所有用户共享数据库的实例和资源,在大小用户之间计算资源消耗对运维团队和 DBA 团队是一个很大的挑战;
- 共享数据库+共享 Schema+租户Id:将用户的数据放在同一个 Schema 中,行与行数据之间用租户Id进行隔离,这种方案理论上可以支撑大批量用户;带来的坏处就是某些大用户的数据量增大可能会影响到小用户的性能;
经过综合讨论后,我们决定采用混合架构模式:大租户独立数据库,小租户以租户Id做区分;小租户升级成大租户交由 DBA 团队做统一的数据迁移;
数据传输
在解决了系统架构选型后,回到解决项目重点技术问题:月均1400w+的订单量由不同部署的不同租户共同组成,采用原始 RPC 数据同步方式带来的问题点(均由线上客户工单反馈收集而来):
- 数据同步失败手动重试不好控制
- 发送端和接收端高度耦合,必须依赖对方的发版计划
- 数据传输量不好控制,数量过多会导致网络的包过大,数量少导致同步时间变慢;
消息传输选型:
参考大厂中的常用方案,引入消息中间件来做数据传输问题;
- RabbitMQ:灵活的路由,部署简单,但吞吐量不够,并且运维团队不熟悉,被运维方pass掉;
- Kafka:大吞吐量,但是不保证数据丢失,财务数据这是重点,所以也被pass
- Flink:靠解析binlog做同步,但是我们的数据需要经过一次业务处理,接收端也需要处理后续业务,所以不适合,被pass掉
- RocketMQ:高吞吐,数据至少发送一次,提供发送回调和事务控制,采用broker集群+刷盘机制存储,可以保证数据不丢失(除非机器坏了),Java开发,开发团队和运维团队更熟悉,并且项目中已有地方在使用RocketMQ,所以优先选择此结构;
数据存储
在解决掉数据传输后,数据如何存储也是一个重难点;前文中提到,单表膨胀带来的查询问题,我们线上一个真实的客户工单:
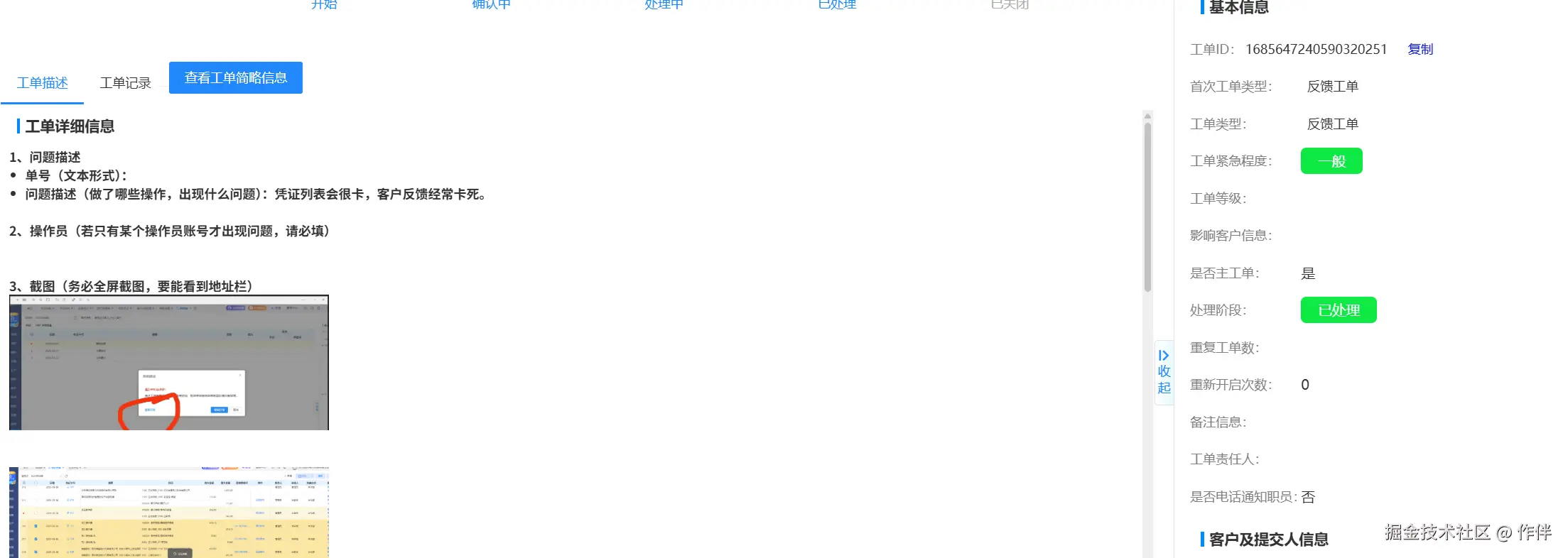

在经历过sql索引优化,DBA对数据库资源优化(大老板不给资源,所以相当于没优化)以及代码上的优化后,实在是优化不动了,所以最终需要选择做分库分表;
但是分库,对我们多租户架构来说又显得过于离谱,因为我们前面都是设计的单库存储,如果此时分库就相当于针对这个业务推翻了我们的架构设计,所以分库是必不可取的,留给我们的只剩下分表了;
好在,财务数据有一个很大的特性:按月出报表,所以我们只需要针对订单的数据按月进行存储,业务代码上自然就可以按月来出报表了;
分库分表中间件如何选型?
目前业界内比较火热的中间件,一个是MyCat,一个是Sharding-jdbc。
- MyCat:提供代理层向不同的库和表进行分发,相当于是数据先到MyCat,再由MyCat向不同的库和表写入数据;适用于团队多语言开发,不用的服务之间不同的语言;
- Sharding-jdbc:以jar包形式内嵌到项目中,通过配置实现分库分表,不经过代理层,适用于Java团队开发;
综合考虑后,MyCat存在多一层的网络开销,并且目前技术的统一,不涉及到多语言开发,所以采用Sharding-jdbc来实现分表操作;
为何一定要引入中间件?按月的特性直接按照代码硬编码的形式不好吗?
假设有目前这样一个场景:用户想要查询某几期的凭证数据,如果是硬编码的形式,写出来的代码就会是这样:
java
List<String> queryMonth = ["202508","202509","202510"]
List<String> toQuerySql = []
for (String month:queryMonth) {
String sql = "select name,code,amount,debit,credit from voucher_"+month;
toQuerySql.add(sql)
}从阅读性和扩展性上来说,对后面维护代码的同学都是一种痛苦;
而我们使用中间件之后,只需要操作逻辑表,真实表的运行交由Sharding-jdbc来帮我们执行,我们也不需要在代码的任意地方去想办法来维护这个分片的key;
不过分表之后也会有问题出现,比如分页,跨表的join问题,分布式事务问题(分库存在,分表不存在),聚合函数的问题,分页和子查询等问题;
这些问题在我们目前的实现方案中,对外提供给用户的都在分片键中解决,复杂报表,子查询采用内存解决;分页的报表尽量走单表查询(也就是查询某一个月的数据);如果读到这篇文章的小伙伴在选型时尽可能结合业务考虑是否分表分库;
技术实现
考虑到用户为分布式结构,运维团队提供给我们的消息是线上的RocketMQ为一主两从设计;
所以从生产消息时考虑,到底是采用VIP通道,还是抢占资源的形式;
- VIP通道模式:将队列根据2/8 , 或者 3/7 分为大小租户,让大租户使用更多队列,小租户使用小一点的队列;需要自定义实现 RocketMQ 的 MessageQueueSelector 根据大小客户(或者更细分大中小客户)来选择进入到哪一种队列;不过这样做的缺陷就是,假如不同的部署在同时调用消息发送,同一时刻大租户数量过多,或者小租户数量过多,资源分配需要去动态的规划;消息接收端,消费者需要编写对应的逻辑来处理不同租户之间的数据库路由进行存储;
- 抢占资源的形式:不区分大小租户,谁先调用就谁先同步;引入分布式锁,剩下的租户放到Redis中进行排队(这也是我们团队采用的方式);这样做的好处就是可能大租户的数量大,会导致小租户的数据同步会延迟;不过我们的同步是在晚上进行,用户也并不关心他的数据先到还是后到,不用去写复杂的队列资源规划,所以这才是我们选择这种方式的目的;
经过上述一系列的选型和规划后,最终得到的流程图长这样:
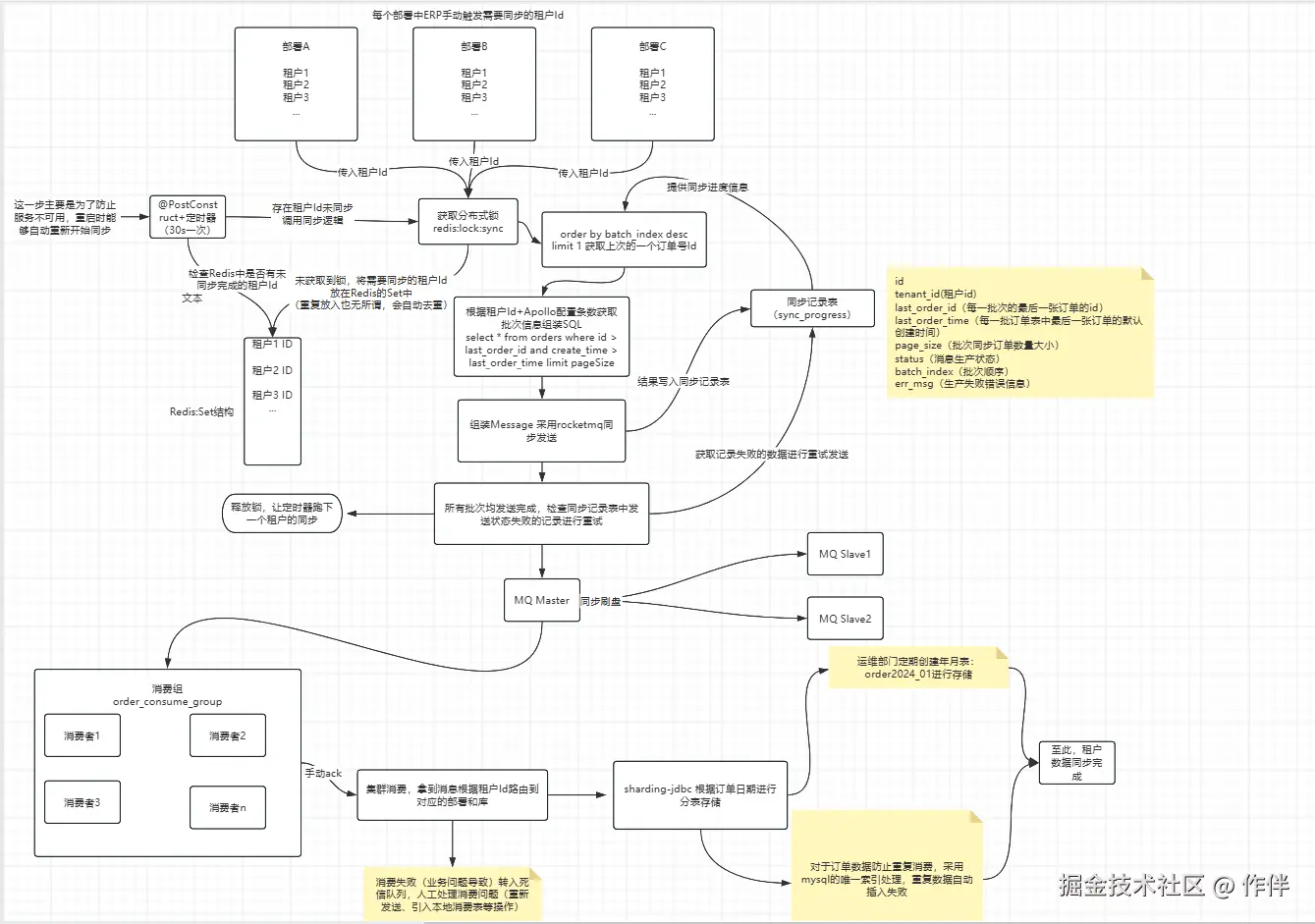
看着稍微有点复杂,其实理清顺序之后就不难
看不清的同学可以直接点链接:www.processon.com/view/link/6...
当这个方案写出来之后,我们通过单表4500w数据在压测环境做数据测试:
生成测试数据的demo地址,也是我写的,可以自由下载:gitee.com/xhyym/order...
最终执行的效果:
rpc同步:耗时在1h 27min
rocketmq同步:耗时在35min
ps:上述结果受带宽,数据量大小,服务端消费能力,批处理量级影响(正常来说rpc应该是比mq更快的,少了一层网络消耗,但是重点关注的是持久性,因为是财务数据,mq提供的持久性更好;可能是压测环境有其他功能也在执行影响到了时间)
关键代码(生产者 demo代码,不是生产代码):
java
@Service
@AllArgsConstructor
@Slf4j
public class OrderInfoServiceImpl extends ServiceImpl<OrderInfoMapper, OrderInfo> implements OrderInfoService{
private final OrderInfoMapper orderInfoMapper;
private final SyncProgressMapper syncProgressMapper;
private final RedisDistributedLock redisDistributedLock;
private final RocketMQTemplate rocketMQTemplate;
private final RedisTemplate<String, Object> redisTemplate;
private final OrderSyncScheduler orderSyncScheduler;
private static final String ORDER_TOPIC = "order-sync-topic";
@Override
public boolean sendOrder(BigInteger tenantId) {
// 不同的部署同时调用订单同步 需要有一个分布式锁来控制同步的功能
boolean lock = redisDistributedLock.tryLock("order-sync-lock-key", 30);
if (lock) {
CompletableFuture.runAsync(()->{
log.info("开始同步租户Id为:{}的订单信息", tenantId);
this.syncOrderData(tenantId);
});
return true;
}else {
// 锁获取失败 将当前租户Id放在Redis的List中去走定时器扫描排队
redisTemplate.opsForSet().add("order-sync-queue", tenantId);
return false;
}
}
private void syncOrderData(BigInteger tenantId) {
// 获取到锁 根据租户Id查询订单信息
SyncProgress lastSyncProgress = this.getLastSyncProgress(tenantId);
BigInteger lastOrderId = lastSyncProgress == null ? BigInteger.ZERO : lastSyncProgress.getLastOrderId();
Date lastOrderTime = lastSyncProgress == null ? null : lastSyncProgress.getLastOrderTime();
int batchSize = 1000;
int batchIndex = lastSyncProgress == null ? 1 : lastSyncProgress.getBatchIndex() + 1;
while (true) {
LambdaQueryWrapper<OrderInfo> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(OrderInfo::getTenantId, tenantId)
.gt(OrderInfo::getId, lastOrderId) // 基于上次ID分页 解决深度分页问题
.orderByAsc(OrderInfo::getId)
.last("limit " + batchSize);
if (lastOrderTime != null) {
wrapper.gt(OrderInfo::getCreateTime, lastOrderTime);
}
List<OrderInfo> orderInfos = orderInfoMapper.selectList(wrapper);
if (CollectionUtils.isEmpty(orderInfos)) {
break;
}
// todo 这里可以改进,因为只记录了生产进度的消息,消费端无法回写这条消息的消费状态,可以换成Redis的List来存储这一批次的信息,等全部消费完成 删除掉这个key
SyncProgress progress = new SyncProgress();
progress.setId(BigInteger.valueOf(IdUtil.getSnowflakeNextId()));
progress.setTenantId(tenantId);
progress.setLastOrderId(orderInfos.get(orderInfos.size() - 1).getId());
progress.setLastOrderTime(orderInfos.get(orderInfos.size() - 1).getCreateTime());
progress.setBatchIndex(batchIndex);
progress.setPageSize(batchSize);
progress.setStatus(0); // 0-成功
try {
// 发送消息(设置超时时间)
Message<List<OrderInfo>> message = MessageBuilder.withPayload(orderInfos)
.setHeader("messageId", progress.getId())
.setHeader("replyTo", "sync-response-topic")
.build();
SendResult sendResult = rocketMQTemplate.syncSend(ORDER_TOPIC+":"+"tagsAAAAAAA", message, 5000); // 5秒超时
if (sendResult.getSendStatus() != SendStatus.SEND_OK) {
throw new RuntimeException("消息发送状态异常:" + sendResult.getSendStatus());
}
// 消息发送成功后记录进度
syncProgressMapper.insert(progress);
log.info("租户{}第{}批订单同步成功,最后订单ID:{}",
tenantId, batchIndex, progress.getLastOrderId());
// 5. 锁续期:每次处理完一批就续期(确保锁不会过期)
redisDistributedLock.renewLock("order-sync-lock-key", 30);
// 更新订单Id
lastOrderId = progress.getLastOrderId();
lastOrderTime = progress.getLastOrderTime();
batchIndex++;
} catch (Exception e) {
log.error("订单同步异常:{}", e.getMessage());
progress.setStatus(1);
progress.setErrMsg(e.getMessage());
syncProgressMapper.insert(progress);
throw new RuntimeException(e);
}
}
// 数据同步完成 检查生产进度表中是否有失败状态的信息,推送给钉钉
LambdaQueryWrapper<SyncProgress> syncProgressLambdaQueryWrapper = new LambdaQueryWrapper<SyncProgress>().eq(SyncProgress::getStatus, 1).eq(SyncProgress::getTenantId, tenantId);
List<SyncProgress> syncProgresses = syncProgressMapper.selectList(syncProgressLambdaQueryWrapper);
if (!CollectionUtils.isEmpty(syncProgresses)) {
for (SyncProgress syncProgress : syncProgresses) {
// todo重试发送 或者引入日志排查错误原因
log.error("同步失败:{}", syncProgress);
}
}
// todo 推送钉钉或其他告警渠道补偿处理数据
// 释放锁 防止阻塞下一个用户同步数据
redisDistributedLock.unlock("order-sync-lock-key");
// 释放锁 手动开启定时器从Redis中取租户Id跑数据
orderSyncScheduler.startTask();
}
/**
* 获取最新一条同步记录
*/
private SyncProgress getLastSyncProgress(BigInteger tenantId) {
LambdaQueryWrapper<SyncProgress> syncProgressLambdaQueryWrapper = new LambdaQueryWrapper<>();
syncProgressLambdaQueryWrapper.eq(SyncProgress::getTenantId, tenantId)
.orderByDesc(SyncProgress::getBatchIndex)
.last("limit 1");
SyncProgress syncProgress = syncProgressMapper.selectOne(syncProgressLambdaQueryWrapper);
log.info("获取最新同步记录:{}", syncProgress);
return syncProgress;
}
}定时调度工具(demo代码):
java
@Slf4j
@Component
@EnableScheduling
public class OrderSyncScheduler {
// 用于存储定时任务的执行句柄
private ScheduledFuture<?> scheduledFuture;
private final RedisTemplate<String, Object> redisTemplate;
private final OrderInfoService orderInfoService;
// 注入任务调度器
private final ThreadPoolTaskScheduler taskScheduler;
public OrderSyncScheduler(RedisTemplate<String, Object> redisTemplate, OrderInfoService orderInfoService,
ThreadPoolTaskScheduler taskScheduler) {
this.redisTemplate = redisTemplate;
this.orderInfoService = orderInfoService;
this.taskScheduler = taskScheduler;
}
@PostConstruct
public void startTask() {
scheduledFuture = taskScheduler.schedule(
() -> {
log.info("开始定时扫描缓存中排队待同步的租户信息");
Long size = redisTemplate.opsForSet().size("order-sync-queue");
log.info("当前缓存中待同步的租户数量为:{}", size);
if (size!= null && size > 0) {
BigInteger tenantId = (BigInteger) redisTemplate.opsForSet().pop("order-sync-queue");
boolean b = orderInfoService.sendOrder(tenantId);
if ( b) {
log.info("已同步租户Id为:{}的订单信息", tenantId);
}else {
log.info("同步租户Id为:{}的订单信息失败,原因:未获取到锁", tenantId);
}
}else {
log.info("缓存中无待同步的租户信息");
// 没有数据就停止定时任务
if (scheduledFuture != null) {
scheduledFuture.cancel(true);
log.info("停止定时任务");
}
}
},
// 每分钟执行一次从Redis中获取待排队的租户Id进行订单同步
new CronTrigger("0 * * * * *")
);
}
}消费端 - 分片策略:
java
public class OrderMonthShardingAlgorithm implements PreciseShardingAlgorithm<Date> {
// 日期格式化:将LocalDateTime转换为yyyyMM(如2025-10-31 → 202510)
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) {
// 1. 获取分表字段值(order_date)
Date orderDate = shardingValue.getValue();
if (orderDate == null) {
throw new IllegalArgumentException("分表字段order_date不能为空");
}
// 2. 格式化日期为yyyyMM(如202510)
String month = DateUtil.format(orderDate, "yyyyMM");
// 3. 拼接目标表名(如t_order_202510)
String targetTable = shardingValue.getLogicTableName() + "_" + month;
// 4. 校验目标表是否在可用表列表中(避免表不存在的情况)
if (availableTargetNames.contains(targetTable)) {
return targetTable;
}
// 5. 表不存在时抛出异常(也可根据业务自动建表)
throw new IllegalArgumentException("目标分表不存在: " + targetTable + ", 可用表: " + availableTargetNames);
}
}消费端(demo代码)
java
@Slf4j
@Component
@RocketMQMessageListener(
topic = "order-sync-topic",
consumerGroup = "order-sync-consumer-group",
consumeMode = ConsumeMode.CONCURRENTLY,
messageModel = MessageModel.CLUSTERING
)
public class OrderConsumer implements RocketMQListener<MessageExt> {
@Autowired
private OrderInfoMapper orderInfoMapper;
@Override
public void onMessage(MessageExt message) {
log.info("接收到mq中的订单信息:{}", message.getMsgId());
List<OrderInfo> infoList;
try {
// 获取消息中的订单信息数据
String orderInfoJson = new String(message.getBody(), StandardCharsets.UTF_8);
infoList = JSONUtil.toList(orderInfoJson, OrderInfo.class);
orderInfoMapper.insertBatchSomeColumn(infoList);
} catch (Exception e) {
// 抛出异常 rocketmq会自动重试
throw new RuntimeException(e);
}
}
}