目录
[一、 前言:为什么需要 kube-proxy?](#一、 前言:为什么需要 kube-proxy?)
[二、 kube-proxy 的核心原理:非侵入式流量拦截](#二、 kube-proxy 的核心原理:非侵入式流量拦截)
[2.1 核心职责](#2.1 核心职责)
[2.2 工作模式:从低效到高效的演进](#2.2 工作模式:从低效到高效的演进)
[三、 魔法揭秘:数据包的一生(以 ClusterIP 为例)](#三、 魔法揭秘:数据包的一生(以 ClusterIP 为例))
[四、 三种 Service 类型的流量路径分析](#四、 三种 Service 类型的流量路径分析)
[4.1 ClusterIP(内部服务发现)](#4.1 ClusterIP(内部服务发现))
[4.2 NodePort(节点端口暴露)](#4.2 NodePort(节点端口暴露))
[4.3 LoadBalancer(云服务集成)](#4.3 LoadBalancer(云服务集成))
[五、 总结](#五、 总结)
一、 前言:为什么需要 kube-proxy?
在 Kubernetes 中,Pod 是应用部署的基本单位,但它们却是短暂无常的。Pod 可能会因为故障、滚动更新或扩缩容而被频繁地创建和销毁,每次都会获得一个全新的 IP 地址。如果让前端应用直接通过后端 Pod 的 IP 进行访问,这种动态性将导致服务完全不可用。
为了解决这个问题,Kubernetes 引入了 Service 资源。Service 为一组功能相同的 Pod 提供了一个稳定的虚拟 IP(VIP) 和单一的访问入口。而 kube-proxy 就是这个抽象背后的魔法师,正是它负责将发送到 Service VIP 的流量,智能地转发到后端健康的 Pod 上。
本文将深入剖析 kube-proxy 的工作原理,并详细追踪数据包在三种不同 Service 类型(ClusterIP, NodePort, LoadBalancer)下的完整旅程。
二、 kube-proxy 的核心原理:非侵入式流量拦截
2.1 核心职责
kube-proxy 是运行在集群每个节点 上的网络代理守护进程。它的核心职责只有一个:监听 Kubernetes API Server 中 Service 和 Endpoint(Pod 集合)的变化,并实时配置本机 Linux 内核的网络规则(iptables 或 IPVS),使得任何发往 Service VIP 的请求都能被负载均衡到后端 Pod。
2.2 工作模式:从低效到高效的演进
kube-proxy 支持三种工作模式,其本质是流量拦截和转发实现技术的演进。
| 模式 | 工作原理 | 性能 | 适用场景 |
|---|---|---|---|
| userspace(弃用) | kube-proxy 进程在用户空间监听端口,像传统代理一样接收和转发流量。 | 差 | 已弃用,仅作历史了解 |
| iptables(默认) | 通过在内核态配置 iptables 规则链,直接进行目标地址转换(DNAT)。 | 良好 | 中小型集群 |
| IPVS(推荐) | 使用内核级的 IPVS 模块,基于哈希表实现 L4 负载均衡。 | 优秀 | 大型、超大型集群 |
最重要的理念是 :在 iptables 和 IPVS 模式下,kube-proxy 本身并不直接处理数据包 。它只是一个"配置管理员",负责生成规则。真正的流量转发是由 Linux 内核高效完成的,这使得 Service 的负载均衡具有接近原生的网络性能。
三、 魔法揭秘:数据包的一生(以 ClusterIP 为例)
让我们通过一个具体的例子,追踪一个数据包从发起请求到收到响应的完整生命周期。这是理解 kube-proxy 工作原理的关键。
环境设定:
- Pod A (客户端):
10.244.1.10,位于Node-1 (192.168.1.100) - Service SVC-B (目标): ClusterIP
10.96.105.201,端口80 - Pod B1 (端点1):
10.244.2.20,位于Node-2 (192.168.1.101) - Pod B2 (端点2):
10.244.2.21,位于Node-2
当我们在 Pod A 中执行 curl http://10.96.105.201 时,会发生以下精妙的连锁反应:
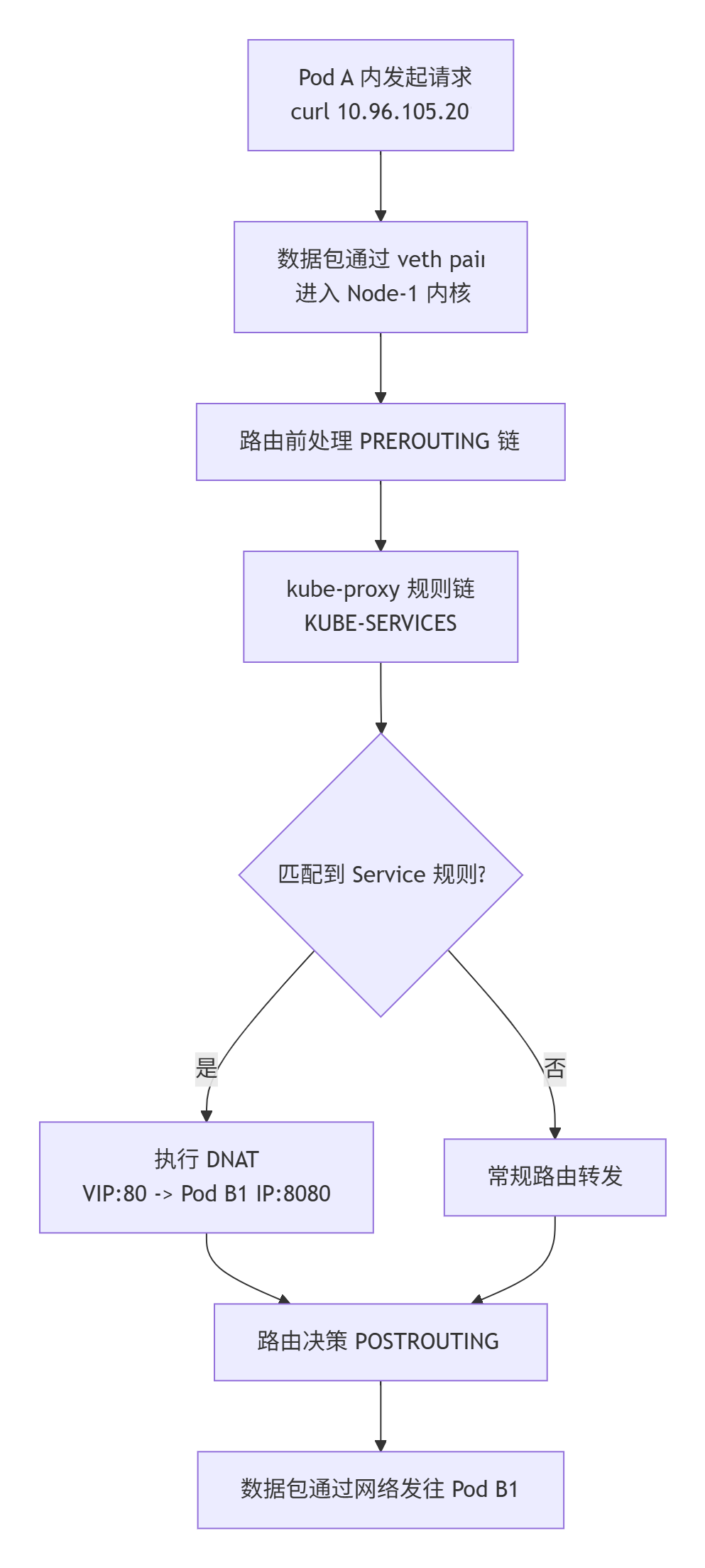
步骤详解:
-
请求发起与进入节点协议栈
- Pod A 内的应用发起请求,数据包源 IP 为
10.244.1.10,目标 IP 为10.96.105.201。 - 由于 Pod 的网络是虚拟的(通过
veth pair设备对实现),数据包立即离开 Pod 的网络命名空间,进入其所在节点 **Node-1** 的根网络命名空间,并出现在虚拟网桥(如cni0)上。
- Pod A 内的应用发起请求,数据包源 IP 为
-
内核路由与 kube-proxy 拦截(关键步骤)
- 内核查看数据包的目标 IP (
10.96.105.201),发现它不属于本节点的任何物理或虚拟网卡。 - 在根据路由表将数据包发送出物理网卡之前 ,它必须经过 **
PREROUTING** 这个 iptables 链。 - kube-proxy 在此链中设置了跳转规则:
-A PREROUTING -j KUBE-SERVICES。所有数据包都被强制送入 kube-proxy 定制的规则链。
- 内核查看数据包的目标 IP (
-
目标地址转换(DNAT)
- 在
KUBE-SERVICES链中,数据包匹配到规则:-d 10.96.105.201/32 -p tcp --dport 80 -j KUBE-SVC-XXX。 - 进而进入
KUBE-SVC-XXX链进行负载均衡(例如,50%概率跳转到 Pod B1 的规则链)。 - 在 Pod B1 的规则链 (
KUBE-SEP-YYY) 中,执行最重要的 DNAT 操作:-j DNAT --to-destination 10.244.2.20:8080。内核悄无声息地将数据包头的目标 IP 和端口修改为真实的后端 Pod 地址。
- 在
-
重新路由与发送
- DNAT 后,目标 IP 已变为
10.244.2.20。内核重新进行路由决策。 - 查询路由表发现,通往
10.244.2.20的路径需要经过节点Node-2 (192.168.1.101)。 - 数据包经过
POSTROUTING链(可能做 SNAT 确保回包路径),最终通过Node-1的物理网卡发出,送往Node-2。
- DNAT 后,目标 IP 已变为
-
到达目标节点与 Pod
- 数据包到达
Node-2,经过类似但相反的过程,通过cni0网桥最终被送入 Pod B1 的veth设备,从而被 Pod B1 内的应用进程接收并处理。
- 数据包到达
回程报文会经历类似的逆向过程,确保响应能正确返回给 Pod A。
总结一下:kube-proxy 的魔力不在于直接处理流量,而在于它通过配置内核网络规则,在数据包流出的必经之路上设置了一个"智能路由中心",透明地完成了虚拟 IP 到真实 IP 的转换。
四、 三种 Service 类型的流量路径分析
4.1 ClusterIP(内部服务发现)
- 特点:默认类型,仅在集群内部可访问。
- 数据包路径 :如上文所述,完全在集群内部网络中流转。流量从不离开集群的 Pod CIDR 和 Service CIDR 网段。这是最基础、最安全的方式。
4.2 NodePort(节点端口暴露)
- 特点 :在 ClusterIP 基础上,在每个节点的固定高位端口(30000-32767)上暴露服务。
- 数据包路径 (外部客户端访问):
- 外部客户端请求
http://<任意节点IP>:31000。 - 数据包到达该节点(如
Node-1)的31000端口。 - 节点的内核协议栈接收到这个目标端口为
31000的数据包。 - 接下来的过程与 ClusterIP 完全一致! 该节点上的 kube-proxy 设置的 iptables/IPVS 规则会捕获此数据包,将其目标 IP 转换为 ClusterIP,继而通过 DNAT 转发到后端 Pod。
- 如果 Pod 在另一个节点上,数据包会被转发过去。
- 外部客户端请求
4.3 LoadBalancer(云服务集成)
- 特点:在 NodePort 基础上,集成云供应商的负载均衡器,分配公网 IP。
- 数据包路径 (外部客户端访问):
- 外部客户端请求云供应商提供的公网 IP(如
35.226.100.100)。 - 云负载均衡器接收请求,在其后端池 (包含所有集群节点的
NodePort)中进行第一层负载均衡 ,将请求转发到某个健康节点的NodePort(如Node-1:31000)。 - 接下来的过程与 NodePort 完全一致! 请求在
Node-1内部被 kube-proxy 的规则处理,最终转发到后端 Pod。
- 外部客户端请求云供应商提供的公网 IP(如
关系总结 :LoadBalancer 基于 NodePort,NodePort 基于 ClusterIP。无论入口多么复杂,请求最终都会进入某个集群节点,并由该节点上的 kube-proxy 规则完成到最后端 Pod 的最终负载均衡。
五、 总结
kube-proxy 是 Kubernetes 服务发现和负载均衡的无声引擎。它通过一种非侵入式的方式,巧妙地利用 Linux 内核的强大网络能力,将不稳定的后端 Pod 抽象成一个稳定的服务入口。
- 它不是代理,而是规则制定者:它不直接转发流量,而是通过管理 iptables/IPVS 规则让内核高效地完成转发。
- 透明拦截是关键:利用容器网络的 veth pair 和 Linux 的 Netfilter 框架,确保所有 Pod 的出入流量都能被无缝拦截和处理。
- 理解数据包流程是根本:通过追踪 ClusterIP 的请求路径,可以清晰地理解 Kubernetes 服务网络的内部工作原理。
正是 kube-proxy 的稳健工作,使得我们在 Kubernetes 中能够轻松实现应用的弹性伸缩、滚动更新和高可用部署,而无需关心后端实例的动态变化。