mit6s081 lab8 locks
一、Memory Allocator(内存分配器)
📘 题目描述
为每个 CPU 实现独立的空闲列表,当 CPU 的空闲列表为空时,可以从其他 CPU 的空闲列表窃取空闲内存。
所有的锁都以 "kmem" 开头。你应该为每个锁调用 initlock() 并传入一个以 "kmem" 开头的名称。
通过运行以下命令进行验证:
kalloctest:查看锁争用是否显著减少;usertests sbrkmuch:验证是否仍然可以分配所有内存。
输出结果中,尽管具体数值可能不同,但 kmem 锁的总争用次数应显著减少。
💡 实现思路
- 所有空闲内存最初都分配给 CPU0;
- 当 CPU1 需要内存时,可以窃取 CPU0 的空闲块;
- 使用完成后,释放的内存会挂回到 CPU1 的空闲列表;
- 这样 CPU1 下次再分配时就可以直接从自己的空闲列表中获取。
🧱 数据结构定义
为每个 CPU 分配一个独立的空闲链表及其锁:
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];🔧 修改 kinit
只有一个 CPU(通常是 CPU0)会调用该函数。
该函数负责初始化每个 CPU 的锁,并调用 freerange() 将物理内存放入空闲链表中。
void
kinit()
{
char lockname[NCPU];
for (int i = 0; i < NCPU; ++i) {
snprintf(lockname, sizeof(lockname), "kmem_%d", i); // 为每个 CPU 的锁命名
initlock(&kmem[i].lock, lockname); // 初始化锁
}
freerange(end, (void*)PHYSTOP); // 将用户空间所有内存加入空闲链表
}🔩 修改 kfree
获取 CPU ID 时必须关闭中断,保证获取的 ID 正确。
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// 用垃圾数据填充,检测悬空引用
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
// 关中断
push_off();
int id = cpuid(); // 当前 CPU id
acquire(&kmem[id].lock);
r->next = kmem[id].freelist;
kmem[id].freelist = r;
release(&kmem[id].lock);
pop_off(); // 开中断
}⚙️ 修改 kalloc
当当前 CPU 的空闲列表为空时,尝试从其他 CPU 的空闲列表中窃取内存块。
void *
kalloc(void)
{
struct run *r;
push_off();
int id = cpuid();
acquire(&kmem[id].lock);
r = kmem[id].freelist;
if(r)
kmem[id].freelist = r->next;
else {
int antid; // 其他 CPU id
for (antid = 0; antid < NCPU; ++antid) {
if (antid == id) continue;
acquire(&kmem[antid].lock);
r = kmem[antid].freelist;
if (r) {
kmem[antid].freelist = r->next;
release(&kmem[antid].lock);
break;
}
release(&kmem[antid].lock);
}
}
release(&kmem[id].lock);
pop_off();
if (r)
memset((char*)r, 5, PGSIZE); // 填充垃圾数据
return (void*)r;
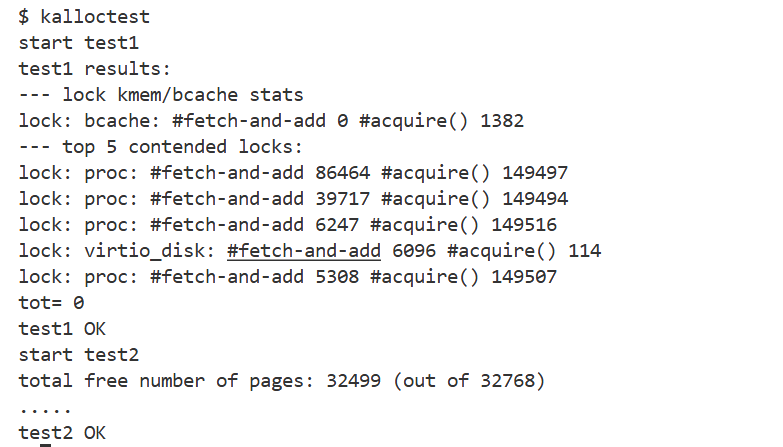
}✅ 测试截图
二、Buffer Cache(缓冲区缓存)
📘 题目描述
修改块缓存,使得运行 bcachetest 时,bcache 中所有锁的 acquire 循环迭代次数接近于 0。
理想情况是所有锁的总争用计数为 0(小于 500 也可接受)。
修改 bget() 和 brelse(),让多个进程能够并发查找和释放缓存块,减少锁竞争。
同时必须保持:
每个磁盘块最多只能缓存一个副本。
💡 优化思路
- 尽可能减少共享:能独享就独享,比如每 CPU 独立空闲链表。
- 必须共享时:减少临界区的锁粒度,缩短加锁时间。
⚙️ xv6 原设计
- 使用双向链表存储所有缓存块;
- 查找时需遍历整个链表;
- 若缓存中已有对应 block,则直接返回;
- 否则选择最近最久未使用且
refcnt == 0的 buf 进行替换; - 整个过程都要持有
bcache.lock,导致严重锁竞争。
🚀 新的改进方案
- 建立 哈希表(blockno → buf);
- 每个桶(bucket)配一把独立的自旋锁;
- 查找 / 插入时仅锁定对应桶;
- 仅当桶中无空闲 buf 时,再从其他桶"偷取";
- 大幅减少全局锁竞争。
🧱 结构体修改
struct buf {
int valid; // 是否从磁盘读取过数据
int disk; // 是否为磁盘所有
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
uint lastuse; // *新增*:记录最近一次使用时间(用于 LRU)
struct buf *next;
uchar data[BSIZE];
};🔧 全局结构定义与初始化
#define NBUFMAP_BUCKET 13
#define BUFMAP_HASH(dev, blockno) ((((dev)<<27)|(blockno))%NBUFMAP_BUCKET)
struct {
struct buf buf[NBUF];
struct spinlock eviction_lock;
// 哈希表:从 dev+blockno 到 buf 的映射
struct buf bufmap[NBUFMAP_BUCKET];
struct spinlock bufmap_locks[NBUFMAP_BUCKET];
} bcache;
void
binit(void)
{
// 初始化哈希桶
for(int i = 0; i < NBUFMAP_BUCKET; i++) {
initlock(&bcache.bufmap_locks[i], "bcache_bufmap");
bcache.bufmap[i].next = 0;
}
// 初始化缓存块
for(int i = 0; i < NBUF; i++){
struct buf *b = &bcache.buf[i];
initsleeplock(&b->lock, "buffer");
b->lastuse = 0;
b->refcnt = 0;
b->next = bcache.bufmap[0].next;
bcache.bufmap[0].next = b;
}
initlock(&bcache.eviction_lock, "bcache_eviction");
}🔍 修改 bget
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
uint key = BUFMAP_HASH(dev, blockno);
acquire(&bcache.bufmap_locks[key]);
// 查找是否已缓存
for (b = bcache.bufmap[key].next; b; b = b->next) {
if (b->dev == dev && b->blockno == blockno) {
b->refcnt++;
release(&bcache.bufmap_locks[key]);
acquiresleep(&b->lock);
return b;
}
}
// 若未命中缓存
release(&bcache.bufmap_locks[key]);
acquire(&bcache.eviction_lock);
// 再次确认是否已有缓存(防止重复创建)
for (b = bcache.bufmap[key].next; b; b = b->next) {
if (b->dev == dev && b->blockno == blockno) {
acquire(&bcache.bufmap_locks[key]);
b->refcnt++;
release(&bcache.bufmap_locks[key]);
release(&bcache.eviction_lock);
acquiresleep(&b->lock);
return b;
}
}
// 选择 LRU 块进行替换
struct buf *before_least = 0;
uint holding_bucket = -1;
for (int i = 0; i < NBUFMAP_BUCKET; i++) {
acquire(&bcache.bufmap_locks[i]);
int newfound = 0;
for (b = &bcache.bufmap[i]; b->next; b = b->next) {
if (b->next->refcnt == 0 && (!before_least || b->next->lastuse < before_least->next->lastuse)) {
before_least = b;
newfound = 1;
}
}
if (!newfound)
release(&bcache.bufmap_locks[i]);
else {
if (holding_bucket != -1)
release(&bcache.bufmap_locks[holding_bucket]);
holding_bucket = i;
}
}
if (!before_least)
panic("bget: no buffers");
b = before_least->next;
// 若需要移动到目标桶
if (holding_bucket != key) {
before_least->next = b->next;
release(&bcache.bufmap_locks[holding_bucket]);
acquire(&bcache.bufmap_locks[key]);
b->next = bcache.bufmap[key].next;
bcache.bufmap[key].next = b;
}
b->dev = dev;
b->blockno = blockno;
b->refcnt = 1;
b->valid = 0;
release(&bcache.bufmap_locks[key]);
release(&bcache.eviction_lock);
acquiresleep(&b->lock);
return b;
}🔁 修改 brelse、bpin、bunpin
void
brelse(struct buf *b)
{
if (!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
uint key = BUFMAP_HASH(b->dev, b->blockno);
acquire(&bcache.bufmap_locks[key]);
b->refcnt--;
if (b->refcnt == 0)
b->lastuse = ticks;
release(&bcache.bufmap_locks[key]);
}
void
bpin(struct buf *b) {
uint key = BUFMAP_HASH(b->dev, b->blockno);
acquire(&bcache.bufmap_locks[key]);
b->refcnt++;
release(&bcache.bufmap_locks[key]);
}
void
bunpin(struct buf *b) {
uint key = BUFMAP_HASH(b->dev, b->blockno);
acquire(&bcache.bufmap_locks[key]);
b->refcnt--;
release(&bcache.bufmap_locks[key]);
}🧩 总结
| 对象 | 是否在内存中 | 是否可每 CPU 独立 | 是否需要全局同步 | 优化方式 |
|---|---|---|---|---|
| 空闲内存(kalloc) | ✅ 是 | ✅ 可以 | 否 | 每 CPU 独立空闲链表 |
| 磁盘缓存(bcache) | ✅ 是 | ❌ 不行 | ✅ 必须 | 哈希分桶 + 每桶独立锁 |
结论:
- 虽然磁盘缓存也使用内存,但它存储的是全局共享的文件系统块数据;
- 因此必须保证数据一致性,不能按 CPU 独立分配;
- 为提高并发性能,应将全局锁细化为哈希桶锁;
| ------------ | ----------------- | ---------------- | --------------------- |
| 空闲内存(kalloc) | ✅ 是 | ✅ 可以 | 否 | 每 CPU 独立空闲链表 |
| 磁盘缓存(bcache) | ✅ 是 | ❌ 不行 | ✅ 必须 | 哈希分桶 + 每桶独立锁 |
结论:
- 虽然磁盘缓存也使用内存,但它存储的是全局共享的文件系统块数据;
- 因此必须保证数据一致性,不能按 CPU 独立分配;
- 为提高并发性能,应将全局锁细化为哈希桶锁;
- 从而在全局共享一致性的前提下实现高并行度的访问。