文章目录
- [开源 ETL(Extract,Transform,Load)工具之Apache Hop](#开源 ETL(Extract,Transform,Load)工具之Apache Hop)
-
- [Apache Hop起源与背景](#Apache Hop起源与背景)
- [什么是Apache Hop](#什么是Apache Hop)
- [apache hop 核心概念](#apache hop 核心概念)
-
- Tools(工具)
- [Item types(条目类型)](#Item types(条目类型))
- Projects(项目)
- 关键概念对比与应用建议
- 术语对照
- 下载安装
- 使用
-
- [在 Hop GUI 中创建 Pipeline(步骤)](#在 Hop GUI 中创建 Pipeline(步骤))
- [Apache Hop 的局限](#Apache Hop 的局限)
- [Apache Hop 的外部插件仓库(hop-plugins)](#Apache Hop 的外部插件仓库(hop-plugins))
- 参考
开源 ETL(Extract,Transform,Load)工具之Apache Hop
Apache Hop起源与背景
1、Hop 最初(2019年底)是作为 Kettle(Pentaho Data Integration,PDI)的一个分支而启动的。Hop 是一个相对较新的项目,于 2020 年成为 Apache 软件基金会的顶级项目。它由 Kettle 的原始创建者 Tyler Mitchell 领导,旨在解决 PDI 中的一些限制,并提供更现代化的架构。
2、Kettle (PDI): Kettle 最初由 Pentaho 开发,是一个功能齐全的数据集成工具。Pentaho 后来被 Hitachi Vantara 收购,尽管如此,PDI 仍然是一个活跃的开源项目,拥有庞大的用户社区和丰富的插件生态系统。
3、Hop和Kettle/PDI是独立的项目,各自有自己的路线图和优先级。鉴于这些不同的路线图、架构愿景和开发轨迹,Hop和Kettle/PDI是不兼容的。由于Hop与Kettle/PDI有着共同的历史,Hop社区提供了一种方法,尽可能无缝地将现有的PDI/Kettle项目导入Hop。
Hop vs Kettle
hop官方对比原文https://hop.apache.org/tech-manual/latest/hop-vs-kettle/index.html
什么是Apache Hop
官网:http://hop.apache.org/
Apache Hop 是一个开源的数据编排、数据工程和数据集成平台,它源自流行的ETL 工具Kettle(也称作Pentaho Data Integration,PDI),并由Kettle 的原作者主导开发。
该平台使用可视化设计器来构建和管理数据管道(Pipelines)和工作流(Workflows),提供了一种**"一次设计,处处运行"的轻量级架构**,支持本地、云端、容器和物联网等多种场景,并可扩展到不同的执行引擎(如Apache Spark, Apache Flink, Google Dataflow 等)。
Apache Hop 的主要特点包括:
- 可视化开发,提供了图形界面用于设计工作流(workflow)和数据管道(pipeline),用户可以专注于业务逻辑而不是代码实现。
- 跨引擎支持,工作流和数据管道支持原生 Hop 引擎的本地和远程运行,数据管道也可以通过 Apache Spark、Apache Flink 以及 Google Dataflow 运行。
- 内置生命周期管理,Hop Gui 工具提供了不同的项目、环境以及运行时配置等管理功能。
- 元数据驱动,使用元数据(Metadata)描述针对数据的操作以及工作流和数据管道的编排,同时对于各种插件和功能的使用也通过元数据进行定义。
Apache Hop 常用的业务场景如下:
- 大数据加载,利用云环境、集群以及大规模并行处理将海量数据加载到数据库中。
- 数据仓库,利用内置的 SCD、CDC 以及代理主键创建功能执行 ETL 任务。
- 数据集成,实现关系型数据库、文件系统、NoSQL 数据库等不同架构的数据整合。
- 数据迁移,完成不同数据库和系统之间的数据迁移。
- 数据分析和数据清洗。
apache hop 核心概念
Tools(工具)
-
Hop Conf:命令行工具,配置工具
Hop Conf 是一个命令行工具,用于管理您 Hop 配置的各个方面:项目、环境、云配置等。
具体的文件为
hop-conf.sh或者hop-conf.bat,可以通过./hop-conf.sh -help命令查看具体的参数。 -
Hop Encrypt:命令行工具,加密工具(加密/解密敏感信息)
Hop Encrypt 是一个命令行工具,用于对明文密码进行混淆或加密,以便在 XML、密码或元数据文件中使用。请确保也将密码加密前缀复制,以指示密码的混淆性质。这样,Hop 就能够区分常规的明文密码和混淆后的密码。
-
Hop Gui:图形用户界面(IDE),用于可视化设计与调试 Pipeline / Workflow
Hop Gui 是一个可视化 IDE,Hop 数据开发者可以在其中创建、测试、运行和管理工作流和管道的生命周期。除了开发和生命周期管理功能外,Hop Gui 还包含用于管理项目和环境的工具和视角,用于搜索和管理元数据的工具和视角,用于管理和版本控制各种文件的工具和视角,以及用于在 Neo4j 图形中探索日志的工具和视角。
-
Hop Run:命令行工具,运行工作流/转换(适用于自动化与调度)
Hop Run 是一个命令行工具,用于运行工作流和管道,并提供选项以(列出或)指定项目、环境、属性和运行配置。
-
Hop Search:搜索工具,用于查找元数据或项目项
Hop Server 是一个用于管理和运行工作流和管道的 Web 服务接口。其本质就是一个jetty web 容器。
-
Hop Server:web 容器,管理和运行工作流与管道(远程部署与运行)
-
hop-import:命令行工具,用于将第三方 ETL(如 Kettle)导入为 Hop 格式
Item types(条目类型)
Pipeline(管道)
Transform(单个转换组件)
hop(连接/通道,传输行数据)
作用:行级数据处理(ETL)
Workflow(工作流)
Action(操作,工作流中的步骤)
Pipeline(在工作流中作为子流程执行)
Workflow(子工作流)
其他 Action(文件操作、脚本、通知等)
hop(连接/控制流)
作用:控制流程、任务调度与条件执行
Projects(项目)
配置 / 变量
项目级变量与参数,用于不同环境间切换
Metadata(元数据)
数据库连接、文件连接等集中管理
Environment(环境)
示例:dev(开发)、prod(生产)
Pipeline
项目内保存的转换定义
Workflow
项目内保存的工作流定义
关键概念对比与应用建议
Pipeline vs Workflow
Pipeline:
处理行级数据(ETL)
由多个 Transform 通过 hop 连接
Workflow:
管理控制流 / 任务流
由多个 Action 组成,用于调度、条件控制、触发 pipeline
建议:将数据转换逻辑放在 Pipeline,使用 Workflow 编排 Pipeline(顺序、并行、错误处理等)
核心构成:Pipeline(数据转换),Workflow(执行控制),Projects(组织与配置)
术语对照
PDI 的 Transformation/Step/Job/Spoon
对应 Hop 的 Pipeline/Transform/Workflow/Hop GUI
概念相近,仅命名不同。
Item types(条目类型)
1)Action
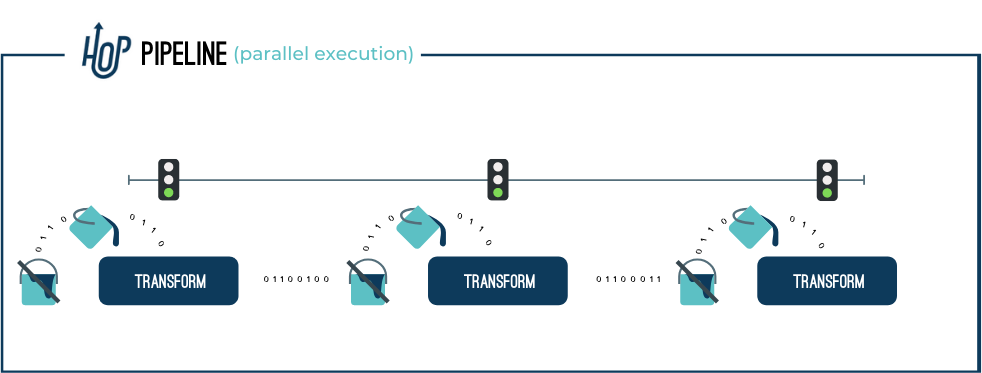
一个动作(Action)是工作流中执行的一个操作。默认情况下,动作按顺序执行,但也可以配置为并行执行。动作返回一个真(true)或假(false)的退出代码,该代码可以在工作流的执行中使用(或忽略)。
2)Hop(连线/跳)
在 Hop 中,Hops 将工作流中的动作(Actions)或管道中的转换(Transforms)连接起来。
在工作流中,Hops 根据前一个动作的退出状态进行操作;
在管道中,Hops 在转换之间传递数据。
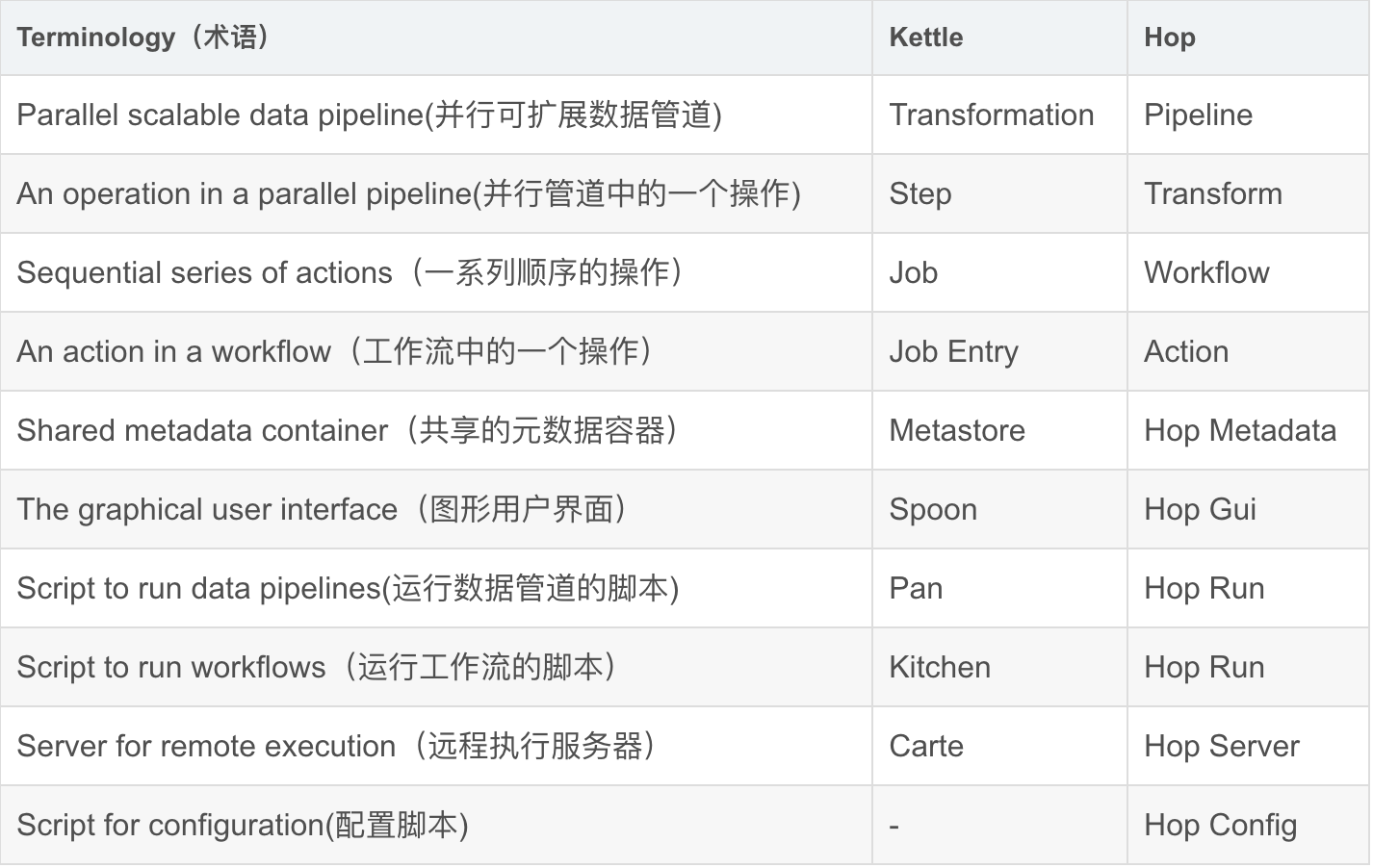
3)Pipeline
管道是实际的数据处理者。管道中的操作读取、修改、丰富、清理和写入数据。管道的编排是通过其他管道和/或工作流来完成的。
从下图可以看到Pipeline包含一些列的TRANSFORM(转换)。
4)Transform
一个转换(Transform)是管道中执行的一个工作单元 。典型的转换操作包括从文件、数据库中读取数据,执行查找或连接操作,丰富、清理数据等。管道中的所有转换都是并行执行的。转换处理数据,并通过 Hops 将处理后的数据批次传递给后续操作进行处理。
5)Workflow
工作流(Workflow)是一系列默认按顺序执行的操作 (可选择并行执行)。工作流通常不直接操作数据,而是执行编排任务。工作流中的典型任务包括检索和归档数据、发送电子邮件、错误处理等。
下载安装
github:https://github.com/apache/hop
-
打开 Apache Hop 官方下载页面:
https://hop.apache.org/download/ -
Apache Hop 基于 Java 开发,因此我们需要安装 JVM。
- OpenJDK Java 17 编译器。请务必将您的 JDK 更新到最新的补丁版本。
- Maven 3.6.3 或更高版本
官方下载地址:https://hop.apache.org/download/,本教程是基于`apache-hop-client-2.15.0.zip`进行解压。
bash
unzip apache-hop-client-2.15.0.zip解压后目录是hop
bash
cd hop学习示例
Apache Hop 提供了各种开发和运行工具,其中 Hop Gui 就是主要的图形开发工具,点击 hop-gui.bat 或者 hop-gui.sh 启动:
启动成功之后会打开hop-gui的操作界面,如下图所示
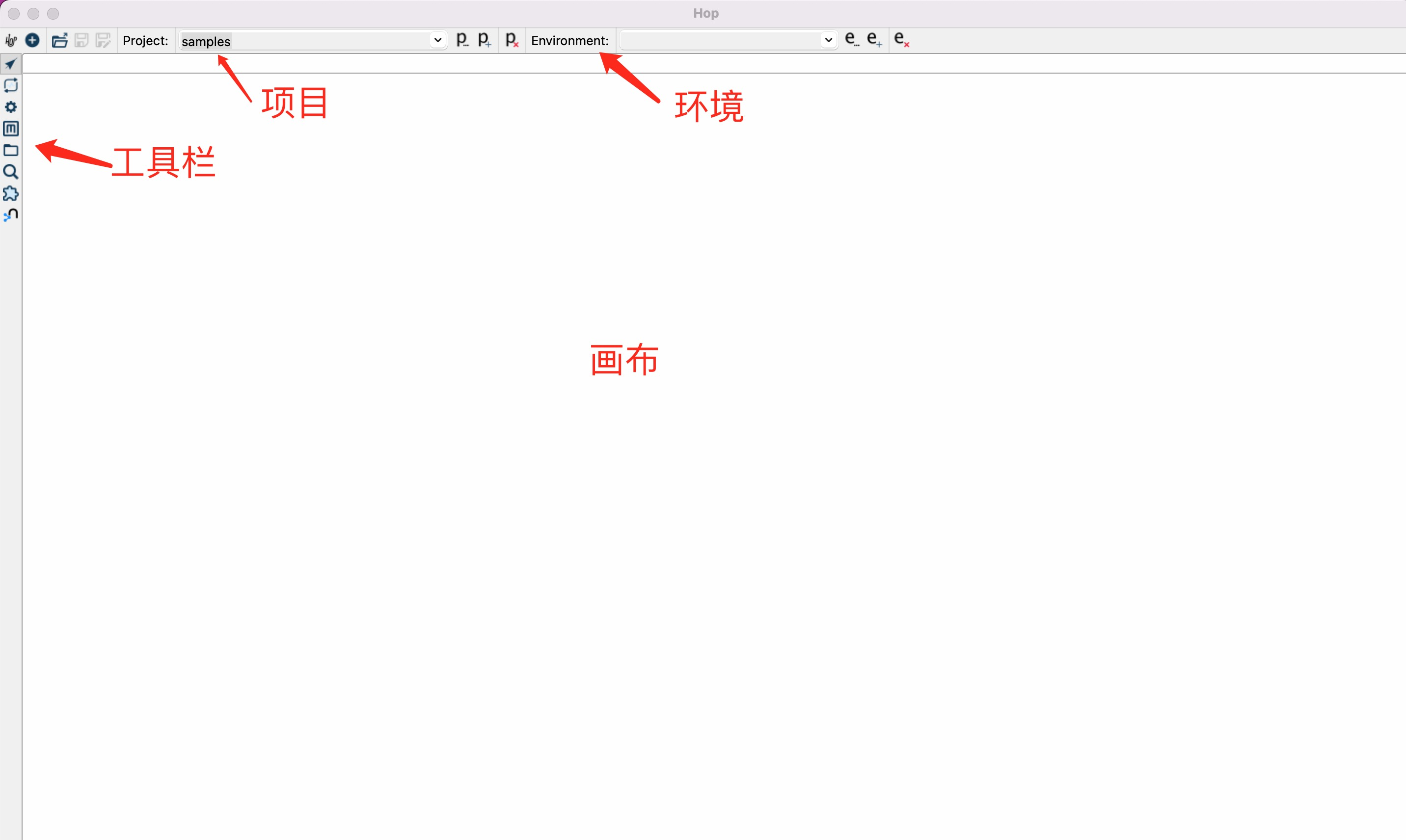
我们首先设置一下界面语言,点击界面左侧的配置视图(⚙),打开"Look & Feel"页面,选择"简体中文":
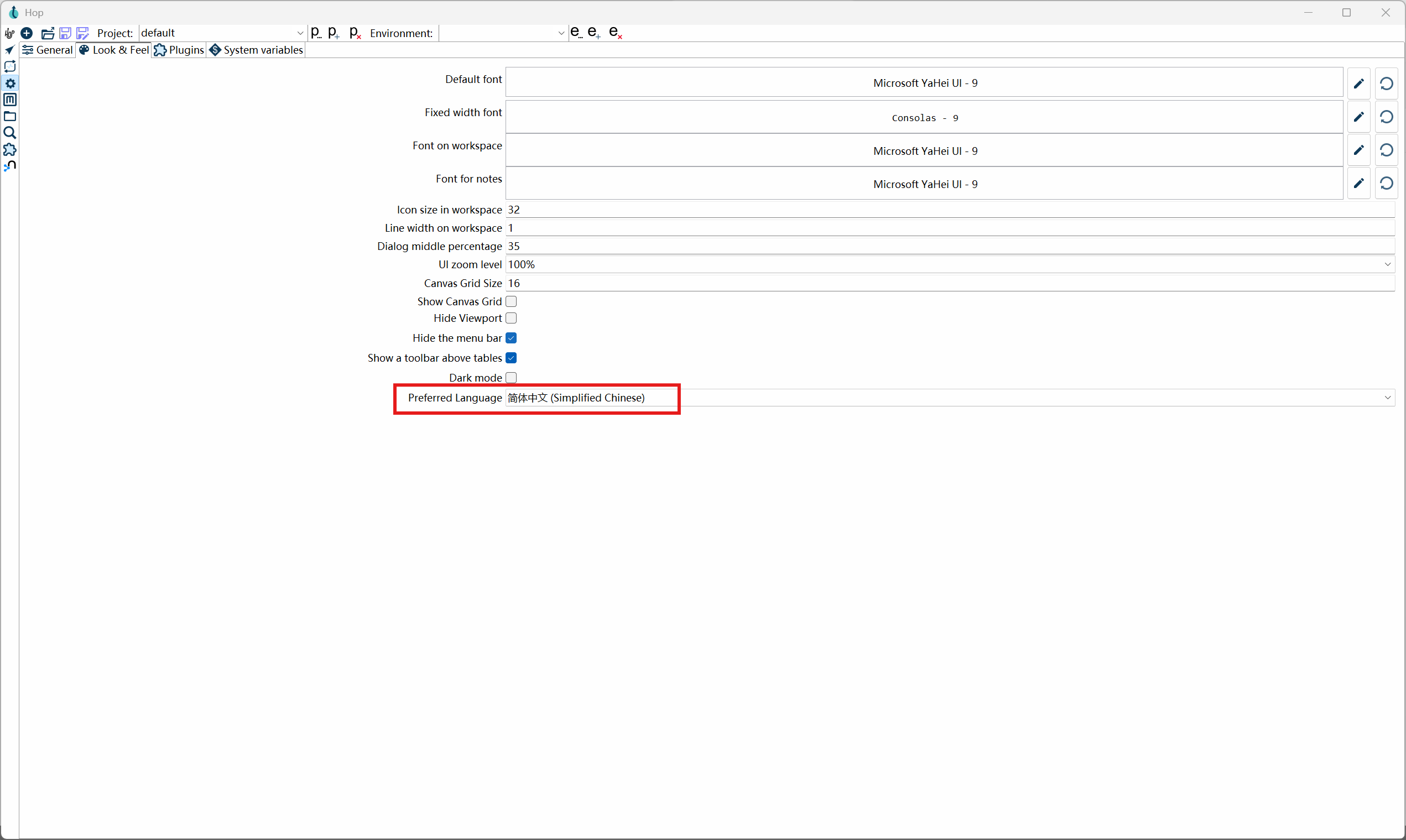
修改配置之后,需要重启 Apache Hop 才能生效。
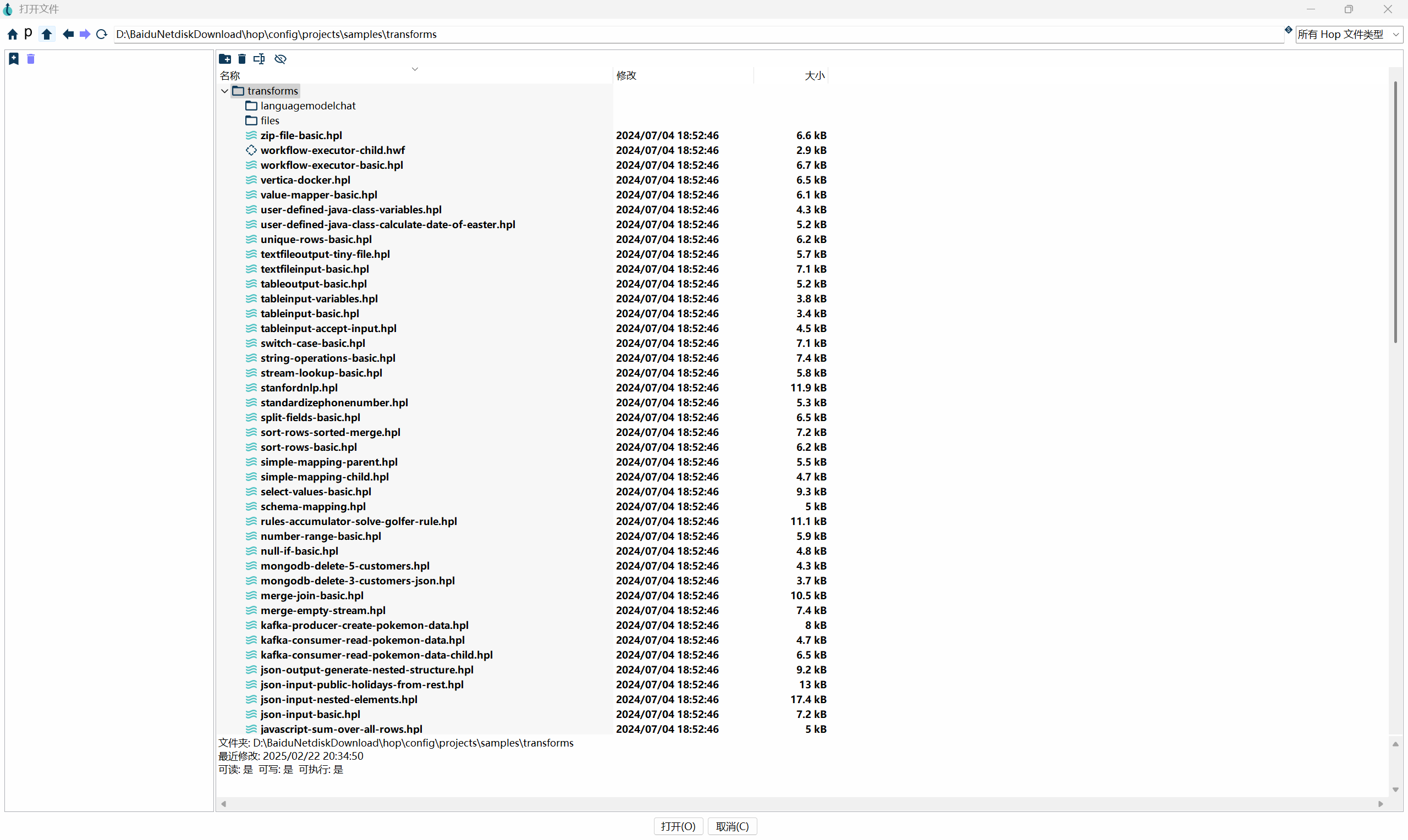
Apache Hop 自带了大量的学习案例,位于安装目录下的 config\projects\samples 子目录,可以通过"打开"菜单加载:
使用
"创建新项目/资源" 对话窗口界面
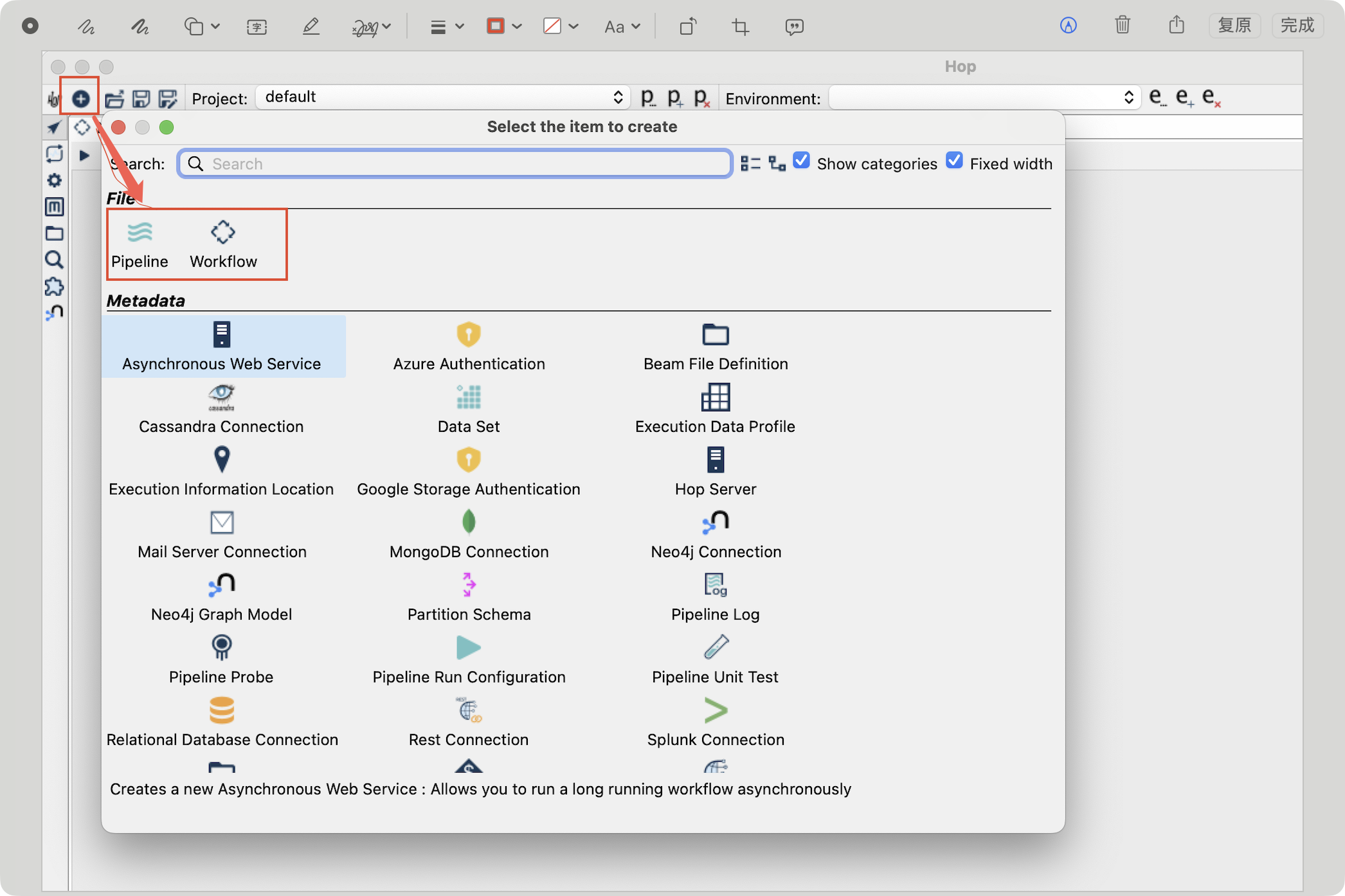
界面用于在 Hop 开发环境中创建不同类型的项目项(例如 Pipeline、Workflow)
- Pipeline:在 Hop 中等同于"转换"或"数据流",用于设计 ETL/ELT 中的数据处理步骤------读取数据、转换、输出。创建 Pipeline 后会进入可视化设计画布,向其中拖放 transform(转换步骤)、连接流向并配置属性。
- Workflow(有时也称为 Workflow 或 Workflow/Workflow):用于控制流程的执行顺序、作业调度、外部程序调用、条件分支等,常用于编排多个 Pipeline 或其他任务(类似作业/调度流程)。
先配置连接(Database / REST / Cloud auth),这样在创建 Pipeline 时可以直接复用连接。
将常用的 Pipeline/Workflow 模板保存为项目项,便于复用。
如果你的目标是处理数据(Extract/Transform/Load),通常创建 Pipeline;若目标是编排任务或调度多个阶段,创建 Workflow/。
在 Hop GUI 中创建 Pipeline(步骤)
打开 Hop GUI。点击左上角的 "+" 然后选择 Pipeline(或右上工具栏的 Pipeline 图标)。
在画布上:
先创建或选择 ClickHouse 的连接(Metadata → Relational Database Connection / JDBC Connection)。
拖入输入 transform、清洗 transform,再拖入输出 transform,按数据流连接它们。
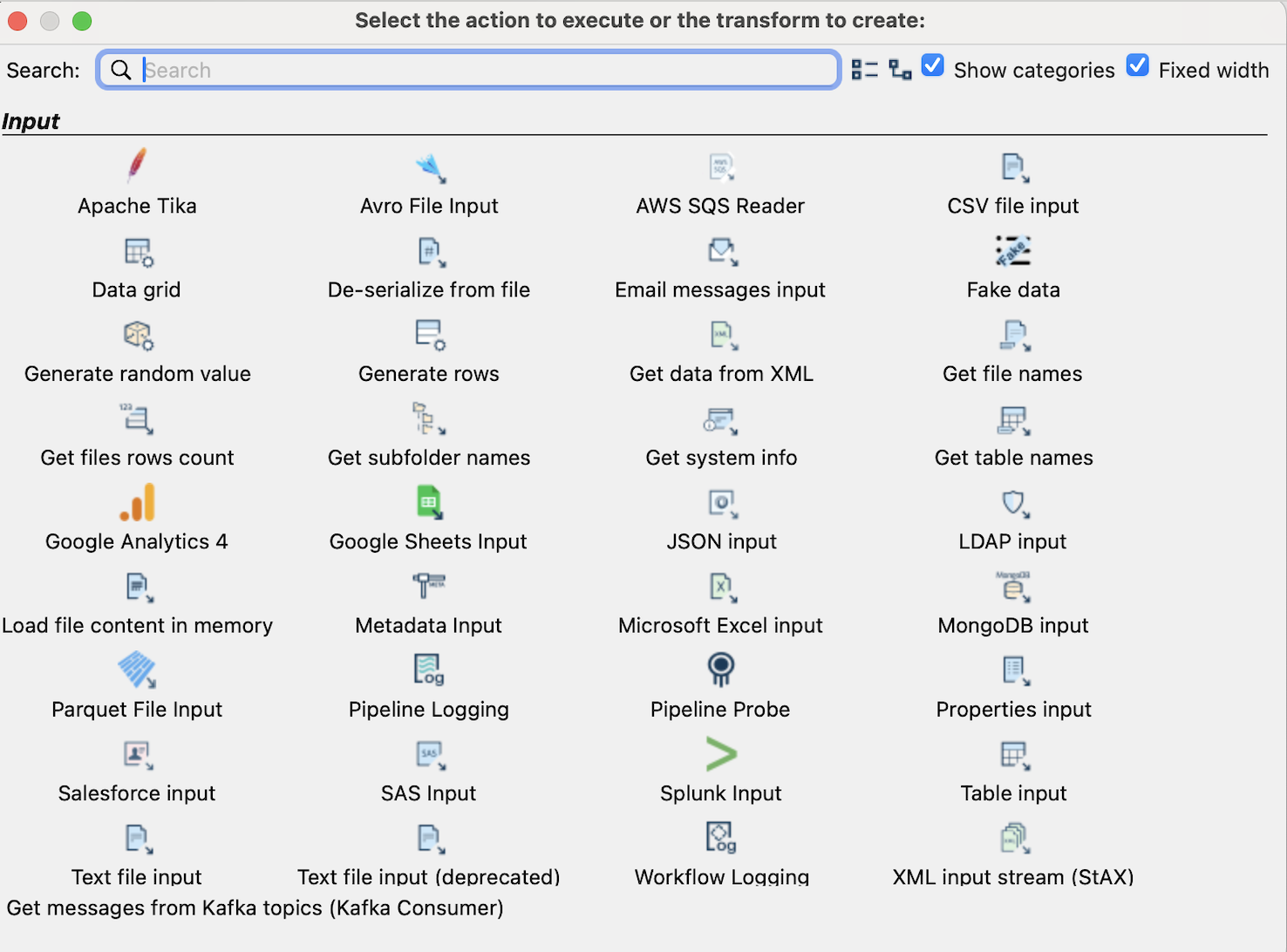
主要 transform
-
通用文件与行输入
- CSV file input
用途:从 CSV 文件读取数据;常用于从文件导入 ClickHouse 的中间步骤(如先清洗再写入) - Text file input / Text file input (deprecated)
用途:通用文本文件读取;可按行解析复杂格式。 - Microsoft Excel input
用途:读取 Excel (.xls/.xlsx) 文件内容,常见于从业务人员导入数据时。 - Parquet File Input
用途:读取 Parquet 格式(列式存储),适合大数据场景和列式分析数据源。
- CSV file input
-
数据生成与测试
- Generate rows / Generate random value
用途:用于生成测试数据或占位数据,做 Pipeline 开发/测试时很方便。 - Fake data
用途:生成假数据样本,用于功能测试或性能测试。
- Generate rows / Generate random value
-
数据库 / 表输入
- Table input
用途:通过数据库连接(JDBC)执行 SQL 查询并读取结果。 - Get table names
用途:列出数据库中的表名,便于动态处理或自动化 Pipeline。 - Get files rows count
用途:获取文件行数,常用于校验或条件判断。
- Table input
-
JSON / XML /结构化数据输入
- JSON input
用途:解析 JSON 文件或字符串,抽取字段进入流。 - Get data from XML / XML input stream (StAX)
用途:解析 XML 或大 XML 流(StAX 适合大文件逐节点处理)。
- JSON input
-
消息队列 / 流式输入
- Get messages from Kafka topics (Kafka Consumer)
用途:从 Kafka 读取流数据,适合实时或近实时 ETL 场景。
- Get messages from Kafka topics (Kafka Consumer)
-
AWS SQS Reader / Google Sheets Input / Salesforce input
- 用途:从各类外部服务读取数据(SQS、Google Sheets、Salesforce 等)。
-
日志 / 监控 / 元数据
- Pipeline Logging / Pipeline Probe
用途:记录或探测 Pipeline 的运行数据,用于调试与监控。
- Pipeline Logging / Pipeline Probe
-
NoSQL / 专用 DB 输入
- MongoDB input
用途:从 MongoDB 读取文档数据。 - LDAP input / Splunk Input / SAS Input
用途:从特定系统或格式读取数据。
- MongoDB input
其它实用输入
- Get file names / Get subfolder names
用途:遍历目录、获取文件路径用于后续 File Input。
- Load file content in memory
用途:将文件整个读入以便于后续处理(小文件场景)。
Apache Hop 的局限
- 性能局限:
Hop 本身是通用 ETL 平台,设计上偏向易用与扩展性,而不是极致的低延迟/高吞吐网络 I/O 优化。- 说明:
对于非常大的数据量、极高并发或严格的延迟 SLA(例如每秒百万行写入),Hop 可能不是最优选;底层连接与序列化往往比原生驱动慢。 - 场景 :低/中等量批量同步(每天几万到几十万行,容忍秒级到分钟级延迟)
- 说明:
Hop 本身是通用 ETL 平台,设计上偏向易用与扩展性,而不是极致的低延迟/高吞吐网络 I/O 优化。
- Apache Hop 对复杂数据类型支持有限
例如,Apache Hop 对 ClickHouse 的复杂数据类型支持有限,常见的做法是使用通用的 JDBC 插件或通用的数据库连接器来读写 ClickHouse,但这通常只覆盖基本标量类型并且对复杂类型支持有限。
Apache Hop 的外部插件仓库(hop-plugins)
官方文档:https://hop.apache.org/manual/2.10.0/plugins/external-plugins.html
Apache Hop 的外部插件仓库(hop-plugins)中无法或不会随 Apache Hop 一起发布的多类插件,重点涵盖可执行系统日志和消息的动作插件、丰富的数据转换(Transforms)插件(如 Dropbox、Google Sheets、Excel、MQTT、LDIF 等)、针对 Python、机器学习与深度学习的扩展(如 CPython 与 Hop Machine Intelligence/hop-mi)以及用于地理信息处理的 AtolCD 插件集。
一组可以与 Apache Hop 一起使用但不能或不会随 Apache Hop 一起发布的插件: https://github.com/project-hop/hop-plugins/
参考
Pentaho vs Apache Hop:選擇最佳 ETL 工具的關鍵考量
原文链接:https://www.omniwaresoft.com.tw/techcolumn/pentaho-vs-apache-hop/
kettle背景:https://kettle.bleuel.com/2015/02/14/some-historic-cornerstones-of-kettle-pentaho/?utm_source=chatgpt.com
Apache Hop从入门到精通 第二课 Apache Hop 核心概念/术语
原文链接:https://blog.csdn.net/zhangjin1222/article/details/145109711