Embedding
Embedding是一种将离散的非结构化数据(如文字、图像、用户ID)映射为连续向量空间的技术。
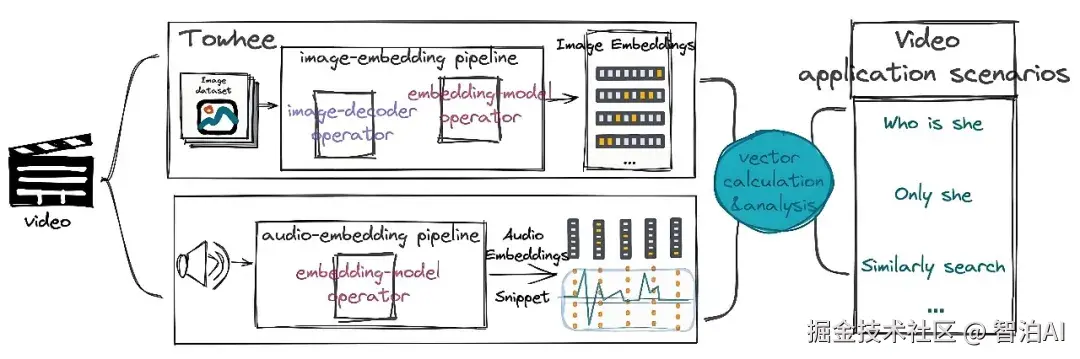
其核心是将高维稀疏数据转化为低维稠密向量,每个向量包含对象的语义信息(如词义、关联性)。
向量间的距离(如余弦相似度)可量化对象相关性,距离越小表示语义越相近。
讲人话
想象把每个词变成一串数字坐标(如"猫"=0.2,-1.3,4.5),就像用经纬度定位城市。

这些数字不仅代表词本身,还隐含它的含义: 比如"猫"和"狗"的坐标接近,但"猫"和"汽车"的坐标相距甚远。
计算机通过这种数字化的"地图"理解词语之间的关系。
Embedding的原理
Embedding的生成依赖上下文学习模型(如Word2Vec)。以Skip-gram模型为例: 输入中心词(如"国王"),模型预测其周围词(如"王冠""城堡")。
训练后,模型权重矩阵的行向量即对应词的Embedding。

通过调整向量空间,使语义相近词(如"国王-女王")的向量方向一致,数学关系可推导(如"国王-男人+女人≈女王")。
通俗来说
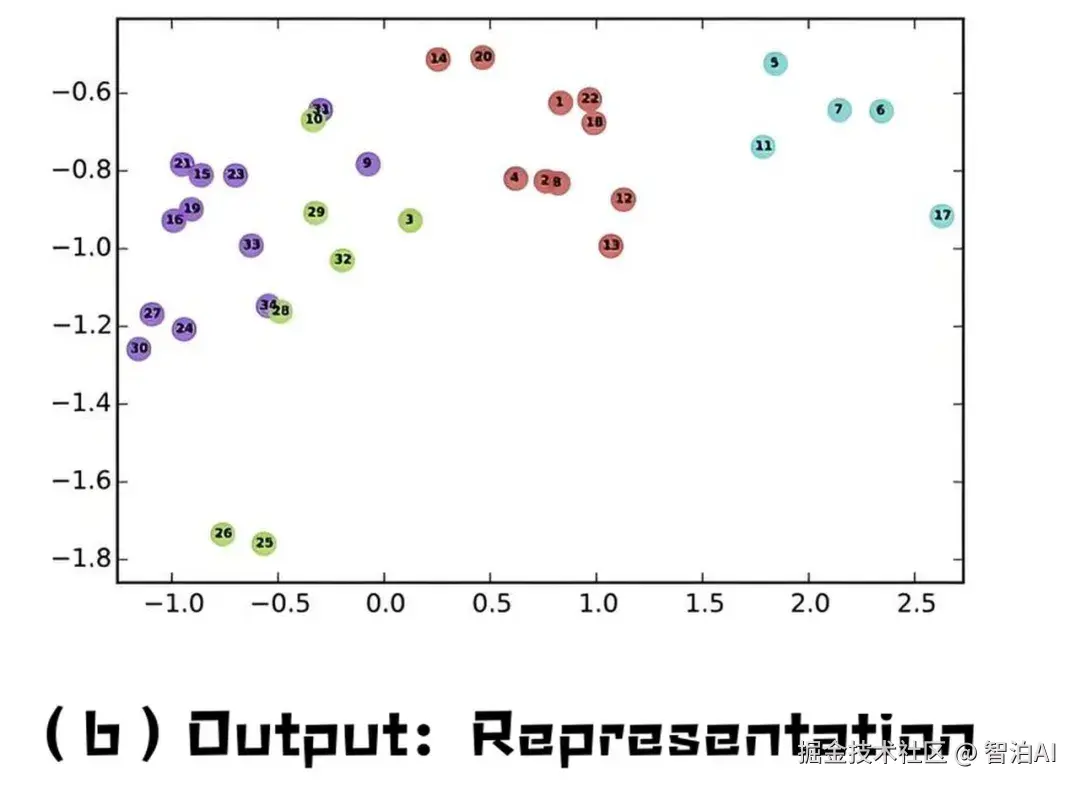
模型通过"猜邻居词"学习词语含义。例如,给"苹果"一词,模型需猜出周围可能是"吃""甜'"手机"(水果或品牌)。
反复训练后,含义相似的词会聚在一起,而"苹果(水果)"和"苹果(公司)"会因不同上下文分布在向量空间的不同区域。
Embedding实践案例
RAG(检索增强生成): 将文档库转化为Embedding存入向量数据库。
用户提问时,系统检索语义最相关的文档片段,输入大模型生成精准答案,解决"幻觉"问题。
多模态应用: CLIP模型将图像和文本映射到同一向量空间,实现"以图搜文"(如上传猫图搜索"宠物照片"描述)。
讲人话
客服机器人用Embedding匹配用户问题(如"退款流程")与知识库答案,无需手动设置关键词。
电商平台通过用户浏览商品的Embedding,推荐相似商品(如喜欢球鞋的用户看到运动袜)。
总结
Embedding是数据的"数字化DNA": 它将语言、图像等高维信息压缩为低维向量(如300个数字),向量距离反映语义相关性。
技术本质是通过模型学习上下文规律(如Word2Vec),使计算机理解"猫接近狗而远离汽车"。
实际应用中,Embedding支撑了推荐系统、多模态搜索、RAG等场景,成为大模型落地企业的核心基础设施。
简而言之: 它让机器像人类一样"联想"万物关系。