认识知名端口号,执行cat /ect/services 可以查看。我们在自己写程序使用端口号时,要避开这些知名端口号
我们再来学习udp协议
面向数据报的协议---不灵活地控制数据的读写次数和数量。读写字节个数是一致的,边界明显(俄国:写信 收信)
http/网络版本计算器都会序列化成为字节流
udp协议需要分离与分用?我们来重点理解分离与分用
分离?
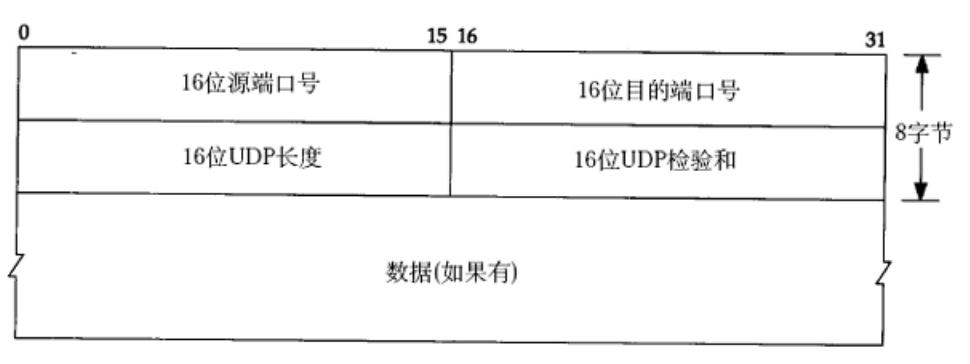
udp是八字节定长报头,数据报除去定长报头后剩下的就是有效载荷。报头和有效载荷分离,有效载荷分离后将自己的有效载荷交给上层的哪个协议
分用?
有目的端口号。系统根据目的端口号查询这个表,找到对应的应用进程,再把 "分离" 后得到的有效载荷,准确交付给该进程内核协议是16位的,使用端口号也是16位的
本质是结构体
协议的报头部分有着固定的格式和字段,很适合用结构体这种数据类型定义和解析
struct udphdr{
__be16 source; // 源端口号
__be16 dest; // 目的端口号
__be16 len; // UDP数据报长度(包括报头和数据部分)
__be16 check; // 校验和
};
报文和报文之间都是有边界的,os之间,直接传递结构体对象
直接交换二进制流
报文:
数据,每个长度交付上层,都是固定的
缓冲区的问题
没有真正意义上的发送缓冲区。因为udp传输不能保证可靠性,把udp的数据缓存起来没有意义
具有接收缓冲区,上层忙的时候可以有自己的缓存。但不能保证收到的和发送的udp报的顺序一致,缓冲区满了,后面的数据就会被丢弃
++udp:传输层的一个协议,给上层提供最简单的面向数据报的通信服务++
报文的理解
在OS内部,一定可能会同时存在大量的报文,os就必须管理这些报文
数据链路层存在套接字缓冲区sk_buff,os将sk_buff上交给网络层
应用层正在进行报文的解析,处理,不会影响os从网络中读取数据
报文=报头+有效载荷
所谓的封装和解包,本质上是移动套接字缓冲区内的data指针在缓冲区中的指向