前言:在数据库管理中,MySQL 作为开源关系型数据库的标杆,其基础操作是所有开发者和运维人员的必备技能。本文将从数据库的创建、编码配置、查看修改,到备份恢复与连接监控,逐步拆解核心操作,结合实操命令与原理讲解,帮你彻底掌握 MySQL 基础管理逻辑。
一、数据库创建:基础语法与本质解析
创建数据库是 MySQL 操作的起点,掌握其语法规则与底层原理,能避免后续使用中的诸多问题。
1.1 核心创建语法
MySQL 创建数据库的标准语法如下,其中 [] 内的关键字为可选参数,用于提升操作安全性:
cpp
CREATE DATABASE [IF NOT EXISTS] database_name;IF NOT EXISTS:关键安全参数。若数据库已存在,不加此参数会直接报错;添加后会将报错转为警告,避免程序执行中断。- 语法大小写特性 :MySQL 语法不区分大小写,但行业惯例会将关键字(如
CREATE DATABASE)大写,表名 / 库名小写,方便代码阅读。
1.2 实操示例
登录 MySQL 客户端后,执行以下命令创建名为db1的数据库(推荐带IF NOT EXISTS):
mysql> create database if not exists db1;
1.3 底层本质:Linux 目录映射
在 Linux 系统中,MySQL 数据库的本质是 ****/var/lib/mysql**目录下的子目录 **。创建db1后,可通过 Linux 命令查看其物理结构:
cpp
# 进入MySQL数据存储根目录
cd /var/lib/mysql
# 查看db1目录内容
ls -l db1/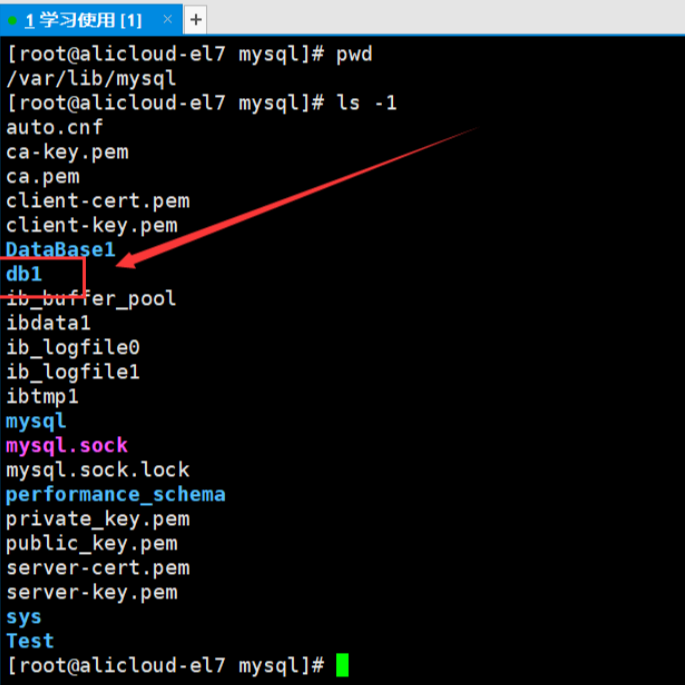
此时会发现db1目录下仅有一个**db1.opt文件** ,该文件是数据库的配置文件,存储着默认的字符集(character) 和校验集(collation) 信息,这两个配置直接影响后续数据的存储与查询。
二、数据库编码:字符集与校验集的关键作用
数据库编码决定了数据如何存储(字符集)和如何比对查询(校验集),配置不当会导致乱码或查询结果异常,必须重点理解。
2.1 字符集与校验集的核心概念
- 字符集(Character Set) :规定数据的存储编码格式,如
utf8、gbk,决定了数据库能支持哪些语言的字符**(如utf8支持多语言,gbk仅支持简体中文)。** - 校验集(Collation) :规定数据的查询比对规则,如是否区分大小写、是否识别重音,同一字符集可对应多个校验集(如
utf8对应utf8_general_ci和utf8_bin)。
2.2 查看系统默认编码配置
要了解当前 MySQL 的编码环境,可通过以下命令查看所有与编码相关的系统变量:
cpp
# 查看所有字符集相关变量
show variables like 'character_%';
# 查看所有校验集相关变量
show variables like 'collation_%';
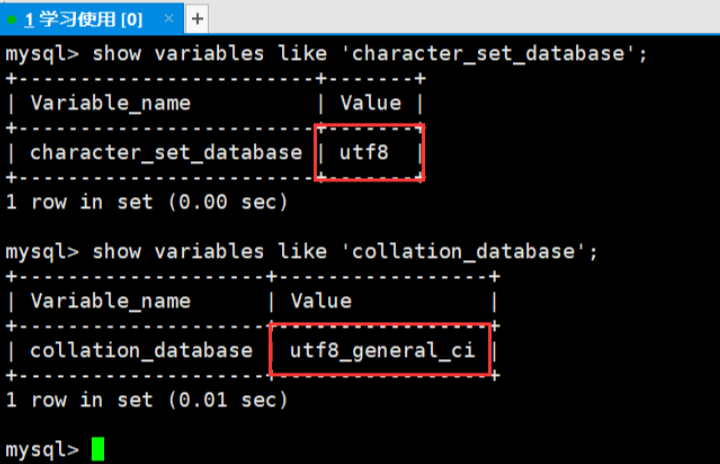
# 查看当前数据库的默认编码(需先use指定数据库)
show variables like 'character_set_database';
show variables like 'collation_database';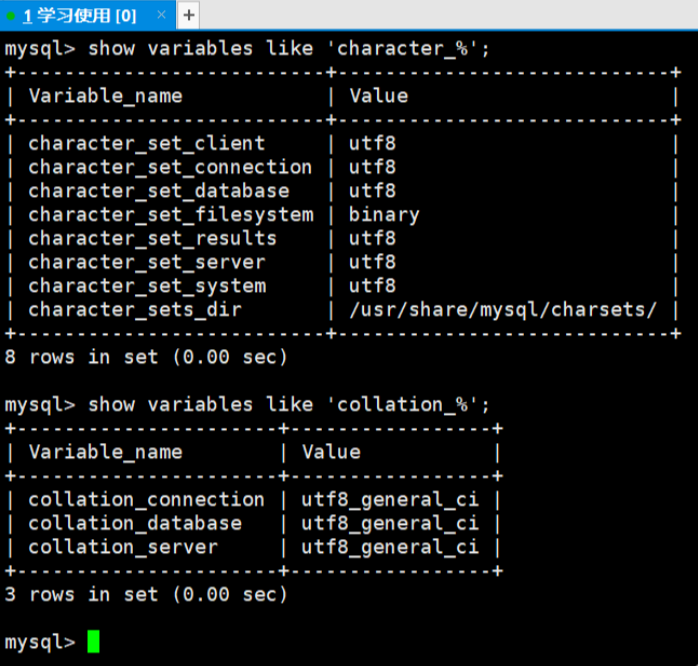
like 'xxx_%':%是 MySQL 中的通配符,匹配任意多个字符,此处用于筛选所有以character_或collation_开头的变量。- 默认配置来源 :若未手动指定,MySQL 的默认编码由配置文件
my.cnf(Linux)或my.ini(Windows)中的default-character-set参数决定,通常默认是utf8和utf8_general_ci。
2.3 MySQL 支持的编码类型
通过以下命令可查看 MySQL 支持的所有字符集和校验集:
cpp
# 查看所有支持的字符集
show charset;
# 查看所有支持的校验集(结果较多,可结合grep筛选)
show collation;关键字符集对比:
| 字符集 | 支持语言 | 适用场景 |
|---|---|---|
| utf8 | 多语言(含中文) | 通用场景(推荐) |
| gbk | 仅简体中文 | 纯中文业务,节省存储空间 |
| latin1 | 西欧语言 | 仅英文场景 |
2.4 手动指定编码创建数据库
创建数据库时,可手动指定字符集和校验集,覆盖系统默认配置。语法如下(|表示可选写法):
bash
CREATE DATABASE [IF NOT EXISTS] database_name
[CHARSET=xxx | CHARACTER SET xxx]
[COLLATE xxx];实操示例
创建字符集为**gbk** 、校验集为**gbk_chinese_ci** 的数据库**db2:**
bash
# 两种写法等价
mysql> create database if not exists db2 charset=gbk collate gbk_chinese_ci;
mysql> create database if not exists db2 character set gbk collate gbk_chinese_ci;关键规则
- 部分指定的自动推导 :若只指定字符集(如
charset=gbk),MySQL 会自动匹配该字符集的默认校验集(gbk_chinese_ci);反之只指定校验集,也会自动推导对应的字符集。 - 不兼容报错 :若指定的字符集与校验集无关联(如
charset=utf8搭配collate=gbk_chinese_ci),会直接报错,确保编码逻辑一致性。
2.5 校验集对查询结果的影响
不同校验集的查询规则差异,会直接导致相同查询语句返回不同结果。以下通过utf8_general_ci(不区分大小写)和utf8_bin(区分大小写)对比演示:
步骤 1:创建不同校验集的数据库并插入数据
# 1. 创建校验集为utf8_general_ci的数据库test1
mysql> create database if not exists test1 collate utf8_general_ci;
mysql> use test1;
mysql> create table t (name varchar(32));
mysql> insert into t values ('a'),('A'),('b'),('B');
# 2. 创建校验集为utf8_bin的数据库test2
mysql> create database if not exists test2 collate utf8_bin;
mysql> use test2;
mysql> create table t (name varchar(32));
mysql> insert into t values ('a'),('A'),('b'),('B');步骤 2:执行相同查询,观察结果差异
# 1. 在test1中查询name='a'
mysql> use test1;
mysql> select * from t where name='a';
# 结果:返回'a'和'A'(不区分大小写)
# 2. 在test2中查询name='a'
mysql> use test2;
mysql> select * from t where name='a';
# 结果:仅返回'a'(区分大小写)结论 :需根据业务场景选择校验集 ------ 如用户名查询需区分大小写则用utf8_bin,普通内容搜索无需区分则用utf8_general_ci(默认)。
三、数据库查看与修改:掌握当前状态与安全调整
在管理过程中,需频繁查看数据库信息或调整配置,以下是核心操作。
3.1 查看数据库相关信息
1. 查看所有数据库
mysql> show databases;也可通过 Linux 命令直接查看**/var/lib/mysql**目录下的子目录,结果与上述命令一致:
ls -l /var/lib/mysql/2. 查看当前所在数据库
通过**database()**函数可快速确认当前操作的数据库:
mysql> select database();3. 查看数据库创建详情
需了解某个数据库的创建语法(含编码配置)时,使用show create database,加\G可格式化输出,更易阅读:
# 查看test2的创建详情
mysql> show create database test2;
# 格式化输出(推荐)
mysql> show create database test2 \G输出结果中,/*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */是兼容性语法:表示若 MySQL 版本高于 4.1(当前主流版本均满足),则启用该编码配置;否则忽略,避免老版本报错。
3.2 修改数据库配置
数据库修改需谨慎,尤其是名称和编码,可能影响上层应用。
1. 不推荐的操作:修改数据库名
MySQL 5.1.23 版本后已移除RENAME DATABASE语法(安全风险高):
# 过时语法,当前版本不支持
RENAME DATABASE old_name TO new_name;若需更名:推荐 "备份旧库→创建新库→导入数据" 的流程,避免直接更名导致的应用连接失败。
2. 常用操作:修改编码配置
语法如下,可修改数据库的字符集和校验集:
ALTER DATABASE database_name [alter_specification...];示例:将test2的编码从utf8/utf8_bin改为gbk/gbk_chinese_ci:
mysql> alter database test2 charset=gbk collate gbk_chinese_ci;四、数据库删除:谨慎操作与风险规避
数据库删除是不可逆操作,需严格遵循安全流程,避免误删。
4.1 核心删除语法
DROP DATABASE [IF EXISTS] database_name;IF EXISTS:关键安全参数。若数据库不存在,不加此参数会报错;添加后转为警告。- 底层逻辑 :删除数据库时,MySQL 会级联删除
/var/lib/mysql下对应的目录及所有子文件(含表数据),且无法通过常规手段恢复。
4.2 实操示例
# 安全删除db1(带检查)
mysql> drop database if exists db1;4.3 风险提示
- 删除前必须备份 :尤其是生产环境,删除前需通过
mysqldump备份数据(下文详解)。 - 避免直接删除生产库:推荐先下线应用连接,确认无业务访问后再删除。
五、数据库备份与恢复:保障数据安全
数据备份是数据库运维的核心,MySQL 提供mysqldump工具实现灵活备份,支持全库、单表、多库备份。
5.1 备份工具:mysqldump 语法
mysqldump是 MySQL 自带的逻辑备份工具,通过生成 SQL 语句文件实现备份,语法如下(在 Linux 终端执行,非 MySQL 客户端):
mysqldump -u 用户名 -p -P 端口 [选项] 数据库名 [表名1 表名2...] > 备份文件路径- 核心参数 :
-u:指定 MySQL 用户名(如root)。-p:提示输入密码(不建议直接在命令后写密码,避免泄露)。-P:指定 MySQL 端口(默认 3306,可省略)。-B:备份数据库时,包含 "创建数据库" 语句,恢复时可直接执行。
5.2 常见备份场景示例
1. 全库备份(含创建语句)
备份test2数据库,生成test2.sql文件至/home/backup/目录:
mysqldump -u root -p -B test2 > /home/backup/test2.sql执行后输入 MySQL 密码,备份文件会包含CREATE DATABASE和CREATE TABLE语句,以及数据插入语句。
2. 单表备份(不含创建数据库语句)
备份test2中的t表,无需加-B:
mysqldump -u root -p test2 t > /home/backup/test2_t.sql3. 多库备份
同时备份test1和test2:
mysqldump -u root -p -B test1 test2 > /home/backup/test1_test2.sql5.3 数据恢复:从备份文件还原
恢复需在 MySQL 客户端中执行,核心语法为SOURCE,需注意备份文件是否包含 "创建数据库" 语句。
场景 1:备份文件含创建数据库语句(带-B备份)
直接执行备份文件即可,无需提前创建数据库:
# 登录MySQL后执行
mysql> source /home/backup/test2.sql;场景 2:备份文件不含创建数据库语句(单表备份)
需先创建数据库并切换,再恢复表数据:
# 1. 创建并切换到目标数据库
mysql> create database if not exists test2;
mysql> use test2;
# 2. 恢复表数据
mysql> source /home/backup/test2_t.sql;六、数据库连接管理:监控与控制访问
MySQL 支持多用户同时连接,需掌握连接监控与异常连接终止的方法,保障数据库性能。
6.1 查看当前连接状态
1. 精简查看:show processlist
快速查看当前所有连接的基本信息(ID、用户、数据库、执行语句):
mysql> show processlist;2. 详细查看:查询系统表
查看完整连接信息(含连接时间、状态):
mysql> select * from information_schema.processlist;3. 连接统计:查看系统状态
通过Threads_%相关变量,统计连接总数、活跃连接数:
mysql> show status like 'Threads_%';Threads_connected:当前总连接数。Threads_running:当前活跃连接数(正在执行 SQL 的连接)。
6.2 控制连接:终止异常连接
若某连接长期占用资源(如执行慢查询),可通过KILL终止:
# 1. 先通过show processlist获取连接ID(如ID=10)
# 2. 终止连接
mysql> KILL CONNECTION 10;调整最大连接数
MySQL 默认最大连接数为 151,若业务需要可动态调整(重启后失效,需在my.cnf中配置永久生效):
# 查看当前最大连接数
mysql> show variables like 'max_connections';
# 动态修改为200(重启后恢复默认)
mysql> set global max_connections = 200;总结
MySQL 数据库的基础管理围绕 "创建 - 配置 - 查看 - 备份 - 连接" 展开,核心在于:
- 编码配置 :根据业务选择字符集(如
utf8)和校验集(如区分大小写用utf8_bin),避免乱码和查询异常。 - 安全操作 :创建 / 删除时加
IF NOT EXISTS,删除前必须备份,避免不可逆损失。 - 备份恢复 :熟练使用
mysqldump实现全库 / 单表备份,通过SOURCE快速恢复,保障数据安全。 - 连接管理:监控连接状态,及时终止异常连接,调整最大连接数适配业务需求。
掌握这些基础操作,是后续学习 MySQL 索引优化、事务管理、高可用架构的前提,也是保障业务稳定运行的核心能力。