就在昨晚,百度正式发布并开源了自研多模态文档解析模型 PaddleOCR-VL 。
在最新的 OmniDocBench V1.5 榜单中,它以 92.6 分的综合成绩位列全球第一,是目前唯二突破 90 分的模型。
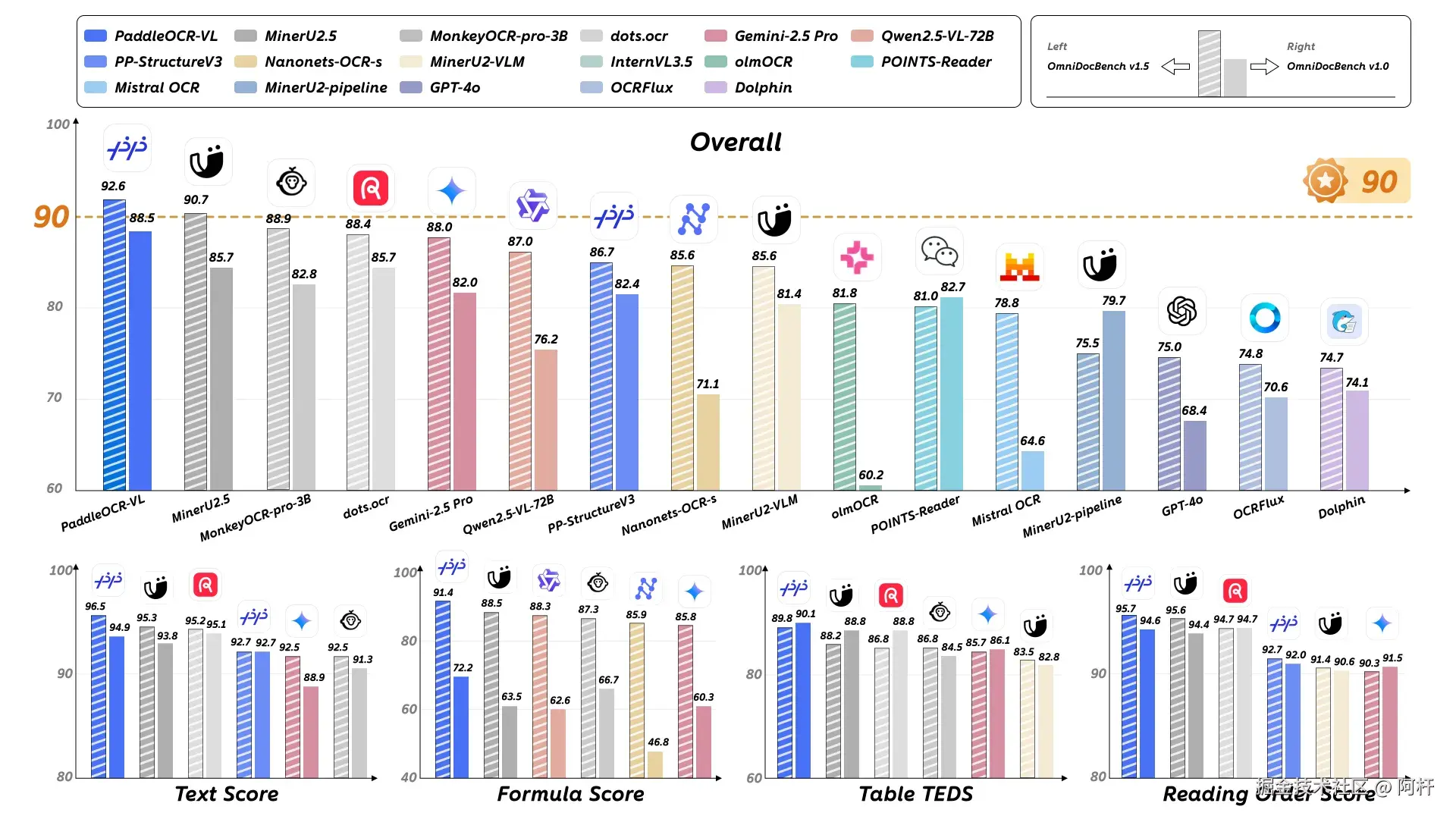
发布的几小时后,它也同时登顶了 Hugging Face 趋势榜的总榜第一。
更离谱的是,这些成绩来自一个只有 0.9B 参数的小模型 ,它实现了对赛道内所有大小模型的全面超越。包括国际主流多模态大模型 GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL-72B,以及OCR领域热门小模型 MinerU2.5、Dots.OCR、InternVL1.5、MonkeyOCR-Pro-3B、OCRFlux等。
它在四个核心维度(文本识别、公式识别、表格理解、阅读顺序)上全部 SOTA,全部都是顶尖级别!并且还支持 100 多种语言。
说它是文心4.5的最强衍生模型,我觉得一点都不为过。
所以问题来了:它的实际效果到底如何?它又是如何做到的这些成绩的?我花了点时间,把几类"折磨 OCR 的文件"全塞给了它,并简单的研究了下他的技术报告。
论文篇
我找了篇论文,挑了几张元素复杂的页面,丢给了它几张论文的截图,里面有多栏排版、数学公式、图表等。
对于这种复杂场景,以往模型的常见症状:
- 公式被识成"E=MC平方平方平方"
- 图表标题混进正文
- 阅读顺序乱到让人懵逼
让我们看看 PaddleOCR-VL 的输出结果:


PaddleOCR-VL 的输出结果简直让人惊讶,公式被准确地渲染成 LaTeX 格式,图表标题与正文自动分区,还能识别左右排版并按照阅读顺序进行了输出。
更妙的是,它可以直接输出结构化的 Markdown 和 JSON 文件,不仅人能看懂,机器也能直接拿来做二次处理。

这其实是它的核心架构在起作用,它将复杂的文档解析任务拆解为一个两阶段处理流程:
- 第一阶段 ,由 PP-DocLayoutV2 执行版面分析与阅读顺序预测;
- 第二阶段 ,由 PaddleOCR-VL-0.9B 进行细粒度识别,包括文本、表格、公式、图表等。
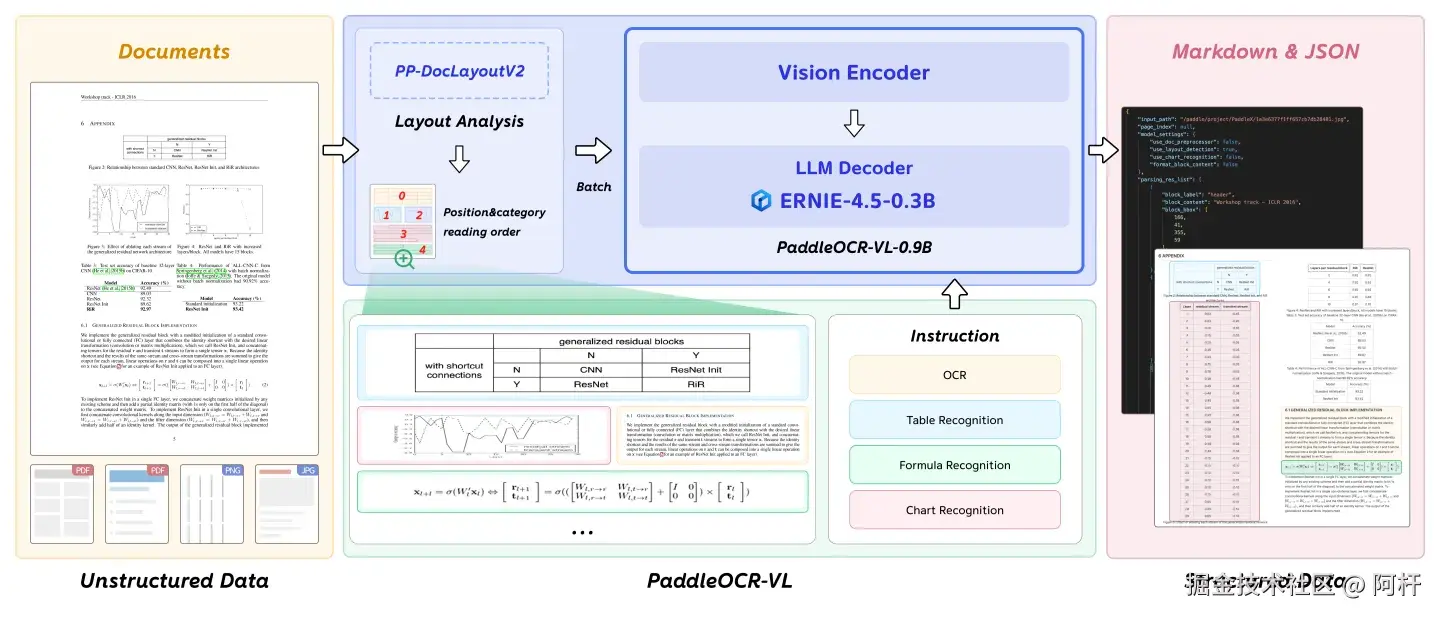
(模型架构图 - 看不懂没关系doge)
简单说,它先去"理解排版逻辑",然后再去"看图识字"。这也是它在论文类文档上能碾压许多大模型的原因:大模型懂语言,但不懂排版;而 PaddleOCR-VL 正是为版面而生的视觉语言模型。
图表篇
接下来我找了一些带有图表的文章内容,那些混合图表、复杂表格的素材。
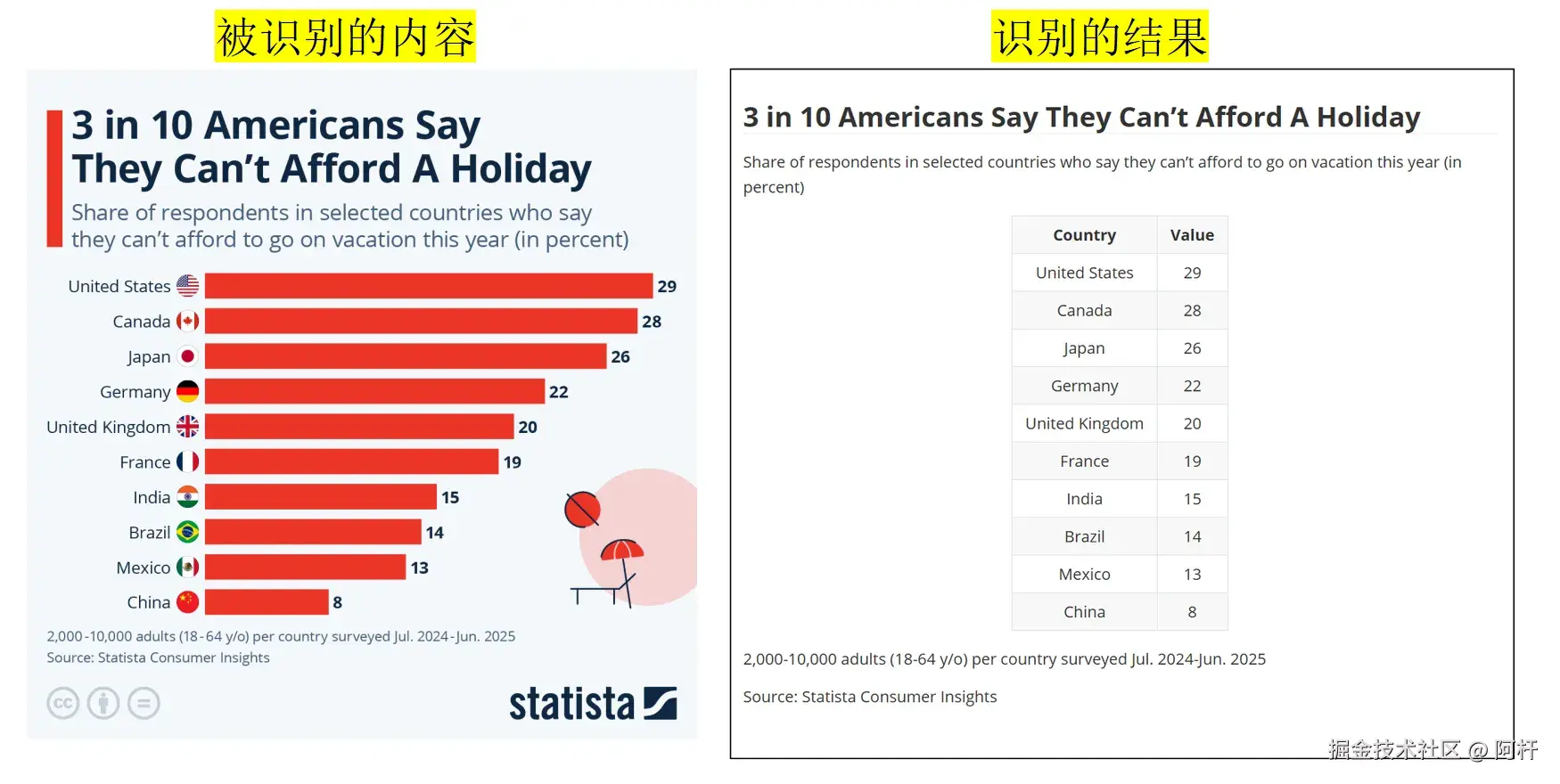
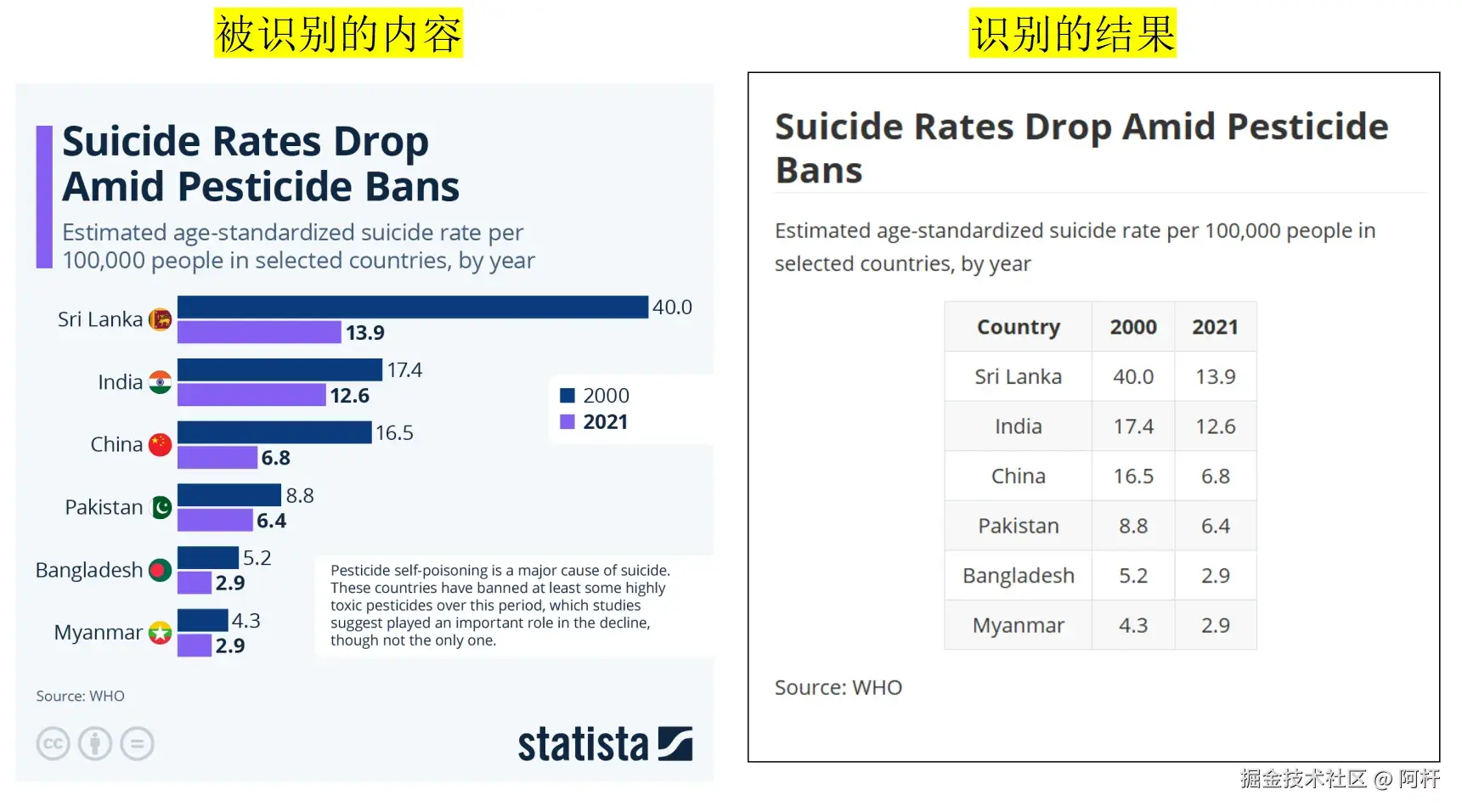
PaddleOCR-VL 输出的结果不仅识别了表格结构和内容,还把表格的内容转换为了数据表格的形式,更加利于后续的二次处理和计算。
这就不得不提到它的另一个亮点:它具备非结构化图表转结构化数据的能力。
也就是说,PaddleOCR-VL 不只是识别表格,还能把折线图、饼图这些"视觉元素"直接还原为可计算的表格。这项特性在自动财报分析、智能报表系统中是杀手级的。
手写篇
最后我拿出了一叠来自某位考公人的手写笔记,OCR 的噩梦素材:歪斜的字、不规则的图、重叠的笔迹、模糊的边角。


PaddleOCR-VL 识别出的结果居然也出奇地稳定,几乎所有的手写文字都被正确解析,手绘图片也得以保留,笔迹重叠的地方还能通过视觉编码器区分层次,非常适合在在教育行业进行开发使用。
行业价值
实测下来,我觉得"PDF 之神"这个称号并不夸张。
它不仅识别文字,更能把杂乱的页面"翻译"成规整的结构化数据。
这让它在很多场景下的价值不止是"看得懂",而是"能直接被使用"。
- 金融与商业:自动解析财报、合同、发票、审计报告;
- 教育与科研:数字化教材、论文、试卷;
- 媒体出版:复原报刊、杂志、书籍排版;
- 政府与档案管理:文档电子化、公文结构化提取;
更重要的是,它是完全开源的。PaddleOCR 自2020年开源至今,在 GitHub 上累计有 57.2k Star,被 6k+ 项目使用,累计下载量突破900万。
今年,PaddleOCR 团队陆续推出了文字识别方案 PP-OCRv5 、文档解析方案 PP-StructureV3 、关键信息抽取方案 PP-ChatOCRv4 等个项目,这次推出的 PaddleOCR-VL 亮点则是多模态文档解析。
这些数据足以说明,这是一个经过长期打磨、社区验证的产业级引擎。
尾声
以前我总觉得 OCR 只是"识别文字的工具",但这次我看到的是一个能理解排版逻辑、能恢复语义结构的全能高手。它在文档处理领域真正做到了"机器读懂人类格式化思维"的那一步。
当复杂的 PDF、扫描件、手写稿都能被 AI 自动解析并转成结构化数据时,人类与机器的信息边界被再次重写。
或许在未来,任何复杂的文档都将不再是静态的,而是可被理解、可被交流的。
这一次,OCR 不只是识字,它终于开始读懂世界。
参考链接
在线Demo:
Github:github.com/PaddlePaddl...
huggingface:huggingface.co/PaddlePaddl...