一、 OCR : 大模型 时代的"信息翻译官"
现实世界中,绝大多数信息以非结构化的形态存在,如同一座尚待挖掘的宝藏,蕴藏着巨大价值,亟待被唤醒与解读。而在检索增强生成(RAG) 等应用场景中,OCR(光学字符识别)的质量,直接决定了整个信息处理链路的"输入质量",进而影响最终生成内容的准确性与可靠性。可以说,高精度OCR是保障知识保真度的关键基石。
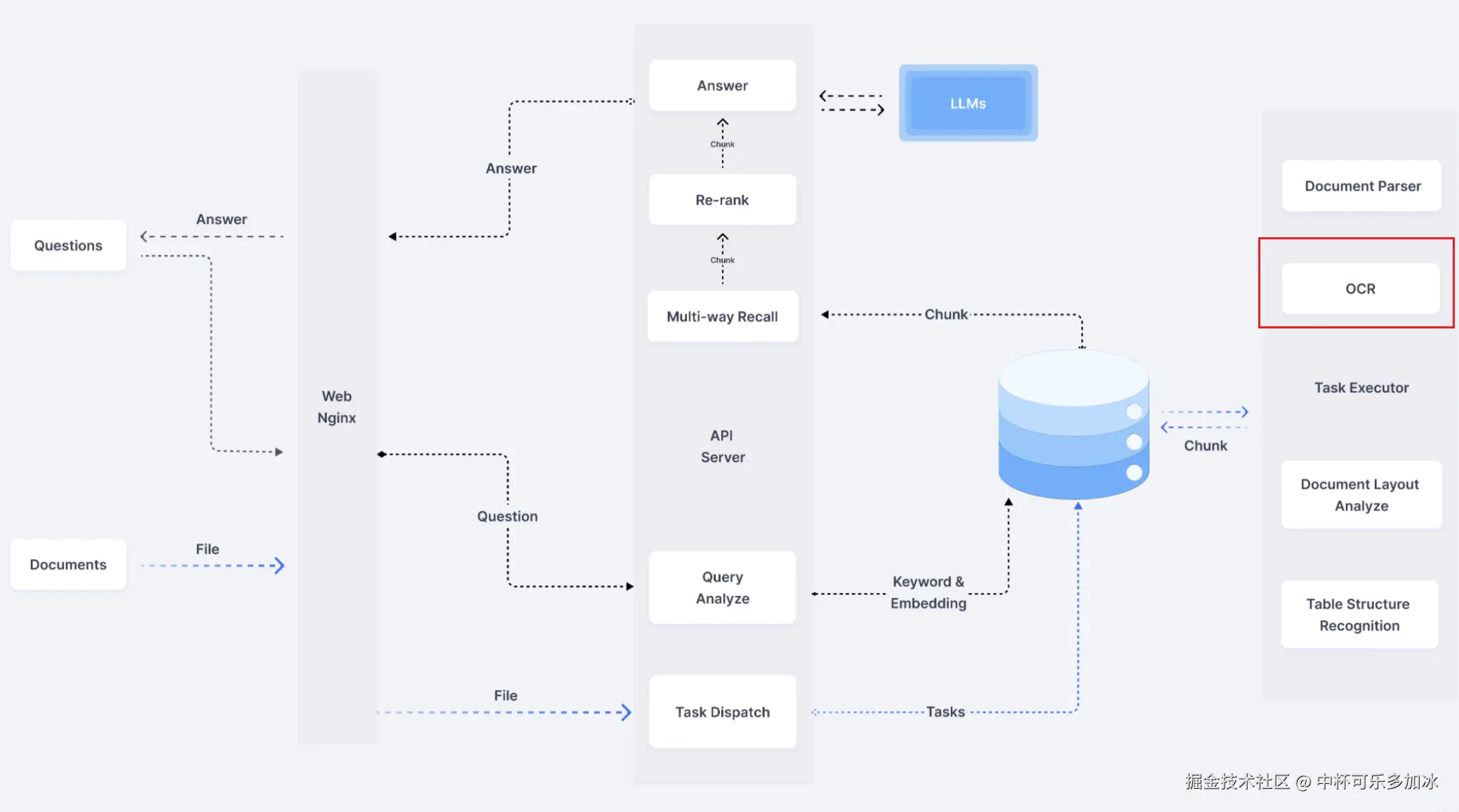
不仅如此,从大模型 进化 的角度看,人类知识的数字化是推动大模型不断进化的核心动力。历史文献、学术著作、各类档案等,都需要通过OCR技术转化为数字文本,才能成为大模型训练的养料,驱动其不断学习和演进。大模型要真正发挥其颠覆性价值,必须依赖OCR将这些数据转化为高效、精准的信息。
在这样的背景下,2025年10月16日,百度正式发布并开源了其自研多模态文档解析模型------PaddleOCR-VL。这款模型在最新OmniDocBench V1.5榜单中,以92.6的综合得分位列全球第一,在文档解析的四大核心能力维度(文本、表格、公式、阅读顺序)上,PaddleOCR-VL实现全线SOTA(State-Of-The-Art),刷新了全球OCR VL模型性能的天花板。
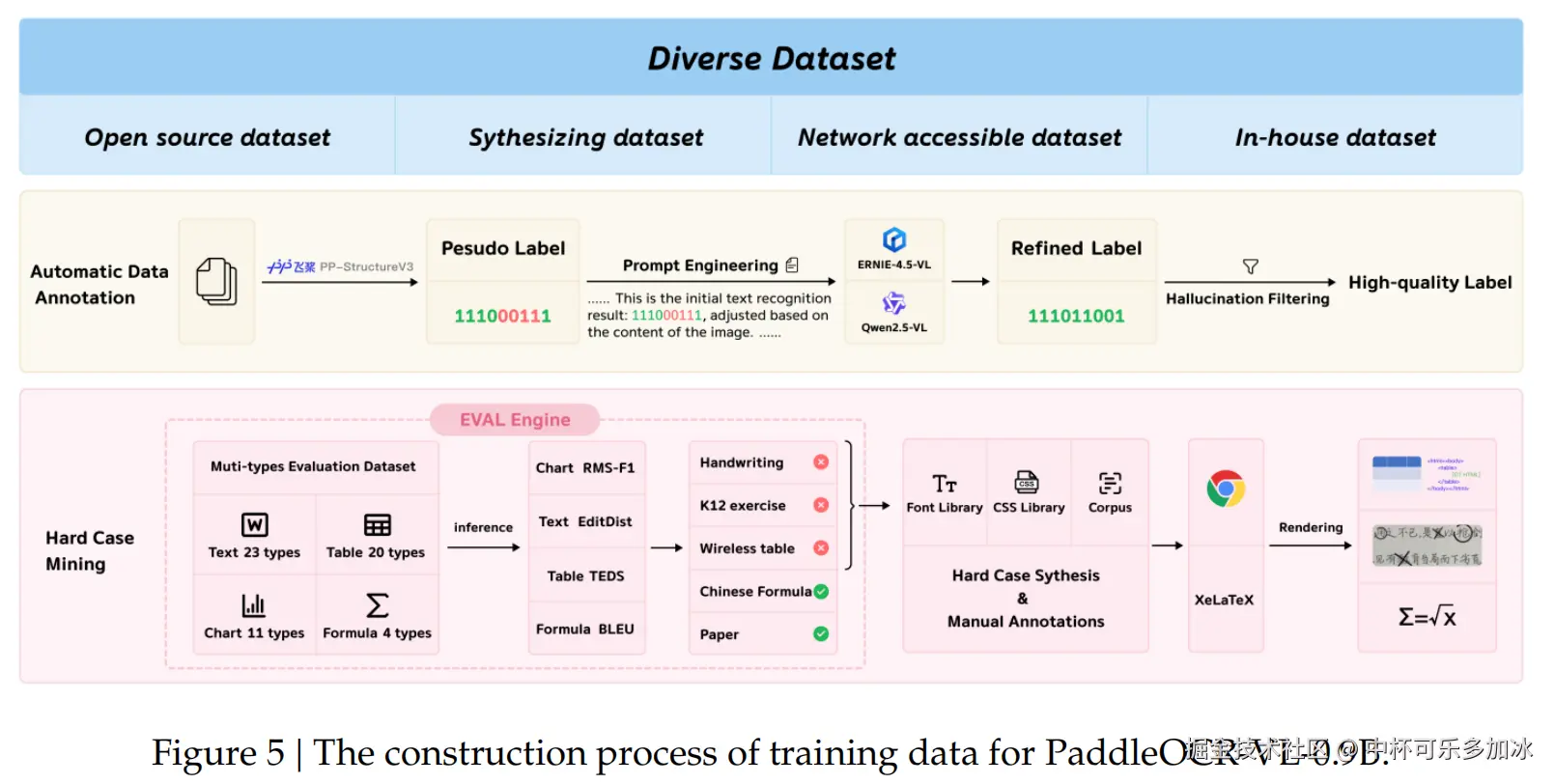
值得一提的是,PaddleOCR-VL是文心4.5最强衍生模型,它基于ERNIE-4.5-0.3B语言模型训练而来,参数量仅为0.9B,展现了轻量高效的卓越特性。它支持100+种语言文字、手写文字的识别、竖版文字识别、表格中公式识别等多种功能,堪称"PDF之神",是文档的"照相机",更是信息的"翻译官",能将杂乱的版面直接"翻译"成规整的结构化数据。
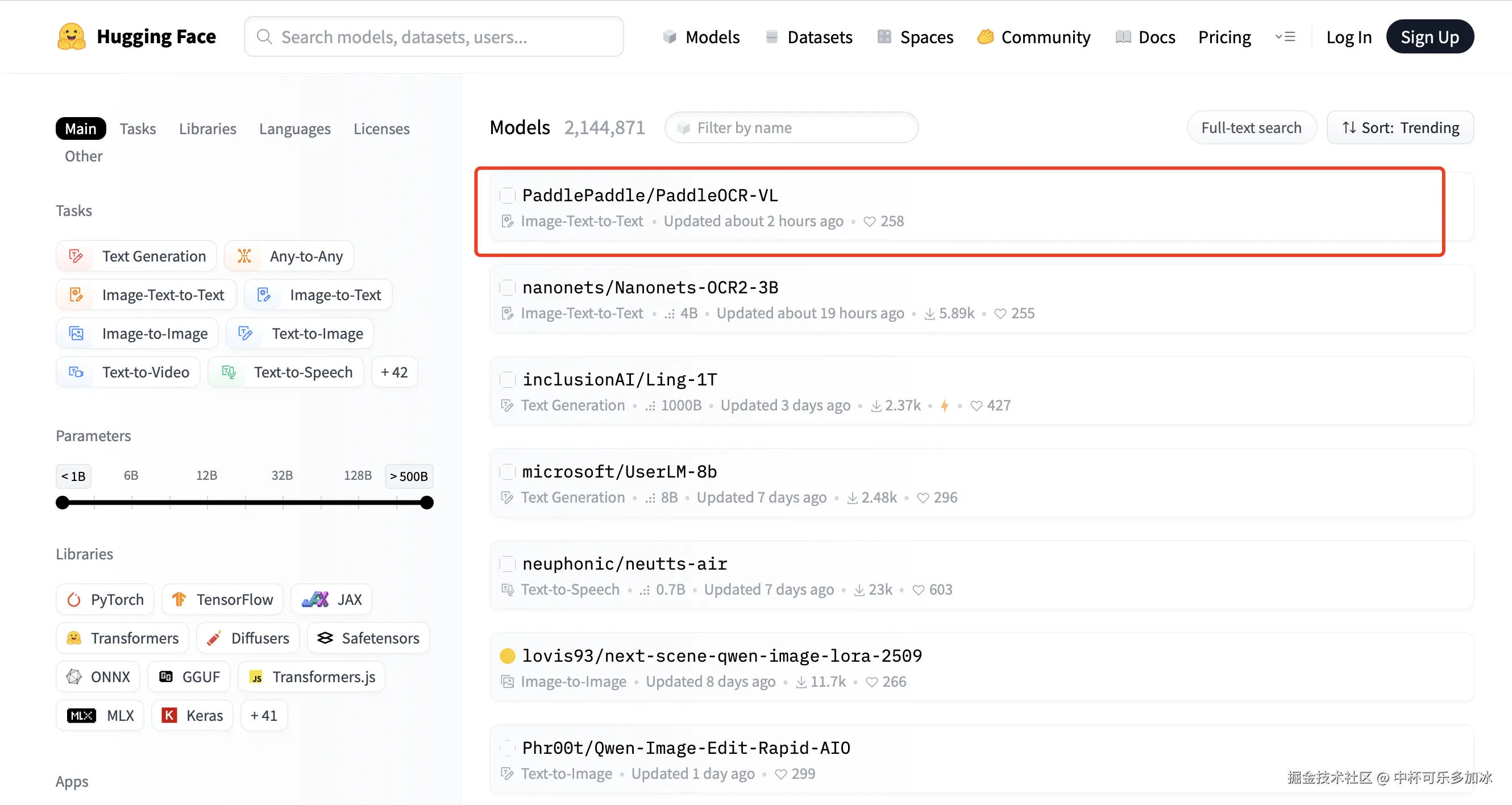
PaddleOCR-VL在开源后16h,登顶HuggingFace Trending全球第一。
二、深度解析PaddleOCR-VL
2.1、核心技术亮点与创新架构
PaddleOCR-VL的核心创新在于其独特的混合式架构,它将轻量而强大的视觉语言识别模型PaddleOCR-VL-0.9B与高精度版面分析模型PP-DocLayoutV2深度融合。
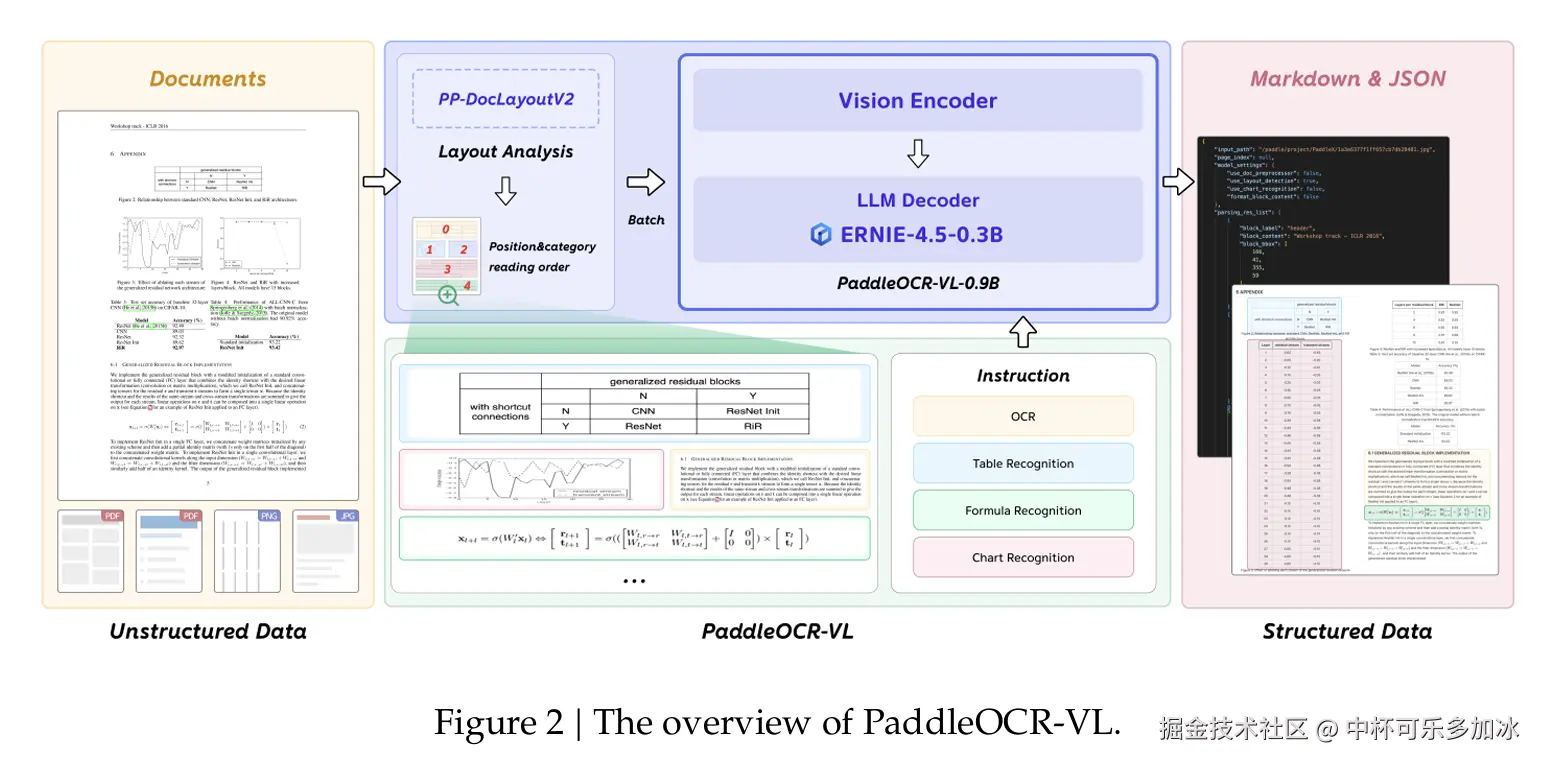
这种两阶段处理流程巧妙地解决了传统端到端VLM在处理复杂文档时面临的效率和稳定性问题,实现了性能与可扩展性的完美兼顾。
2.1.1、版面分析------PP-DocLayoutV2
在文档解析的第一阶段,PP-DocLayoutV2负责执行精细的版面分析,包括对文档中的语义区域进行定位,并预测其正确的阅读顺序。这一阶段的关键在于其解耦设计,避免了大型VLM在处理长序列时可能出现的延迟、高内存消耗和"幻觉"问题,尤其在多栏或图文混排布局中表现更稳定。
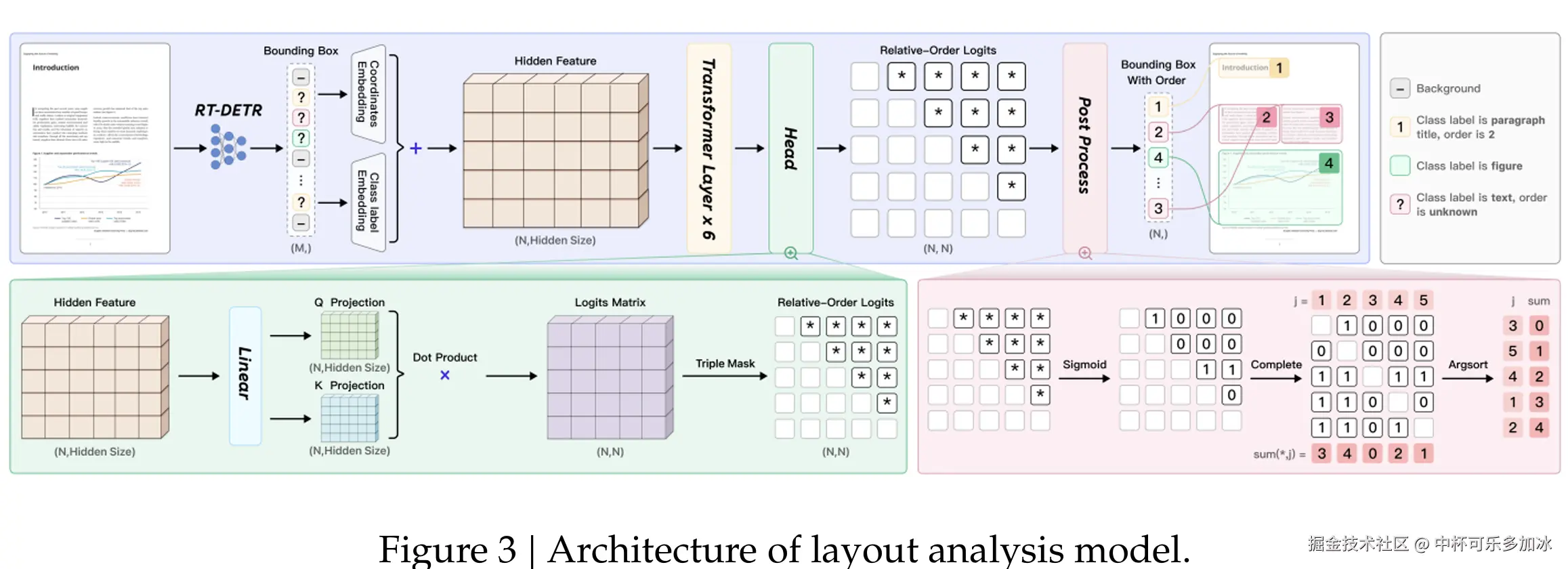
PP-DocLayoutV2主要由两部分组成:
- 基于RT-DETR的目标检测模型:该模型负责精确地检测并分类文档中的各种元素,如文本块、表格、公式、图表、图片、页眉页脚等,并输出它们的边界框位置。
- 轻量级指针网络(Pointer Network) :在检测到所有元素后,一个包含六层Transformer的指针网络会根据元素的几何位置和语义信息,预测出符合人类阅读习惯的阅读顺序。该网络还融入了几何偏置机制(Geometric Bias Mechanism),以显式建模元素间的成对几何关系,并通过确定性累积解码算法(Win-Accumulation Decoding Algorithm)恢复拓扑一致的阅读顺序。
通过这种分而治之的策略,PaddleOCR-VL在版面分析方面展现出高度的准确性和稳定性,为后续的精准内容识别奠定了坚实基础。
2.1.2、元素级识别------PaddleOCR-VL-0.9B
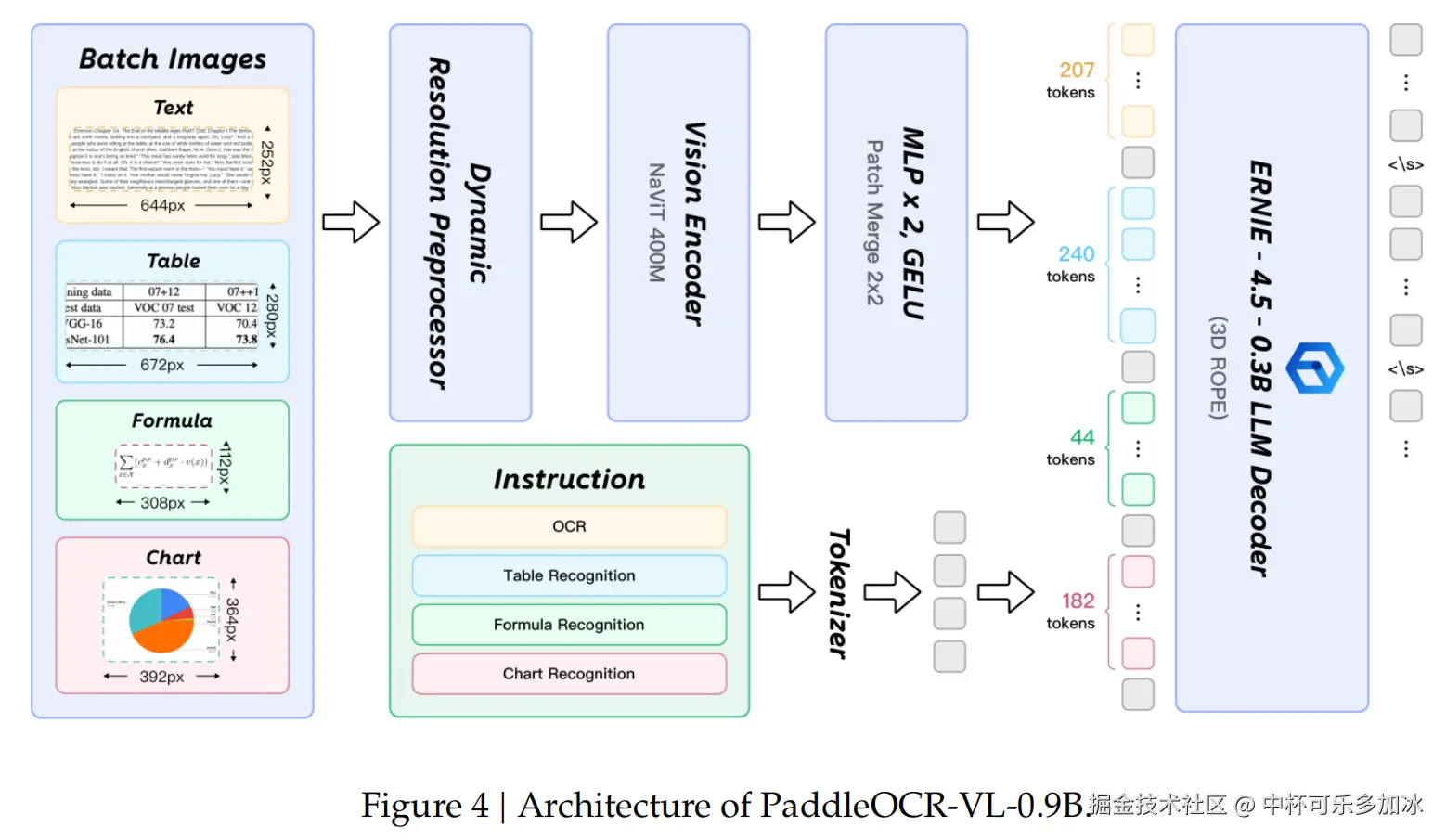
在第二阶段,PaddleOCR-VL-0.9B基于PP-DocLayoutV2生成的版面结构预测结果,进一步完成对多种内容类型的细粒度识别,涵盖文本、表格、数学公式以及图表等。该模型仅有0.9B的参数量,却展现出卓越的性能,其核心在于以下几点:
- NaViT风格的动态高分辨率视觉 编码器 :传统的VLM在处理高分辨率图像时常面临计算量大、信息失真等问题。PaddleOCR-VL-0.9B采用了NaViT(Native Vision Transformer)风格的视觉编码器,支持原生动态分辨率输入。这意味着模型可以处理任意分辨率的图像而无需进行缩放或切片,有效避免了信息损失和失真,极大地增强了对密集文本和低质量图像的识别能力。
- ERNIE-4.5-0.3B语言模型 :作为语言模型的核心,PaddleOCR-VL-0.9B集成了轻量级的ERNIE-4.5-0.3B。该模型在保持较小参数量的同时,提供了强大的语言理解能力,确保了高效的推理速度。
- 双层 MLP 投影器:负责高效地将视觉编码器提取的特征映射到语言模型的嵌入空间,实现视觉与语言信息的无缝融合。
这种视觉与语言模型的紧密结合,使得PaddleOCR-VL-0.9B不仅能"看懂"文字,更能"理解"表格、公式、图表等非文本元素的内在结构和语义,实现了从视觉信息到结构化数据的智能转换。
2.2、性能表现
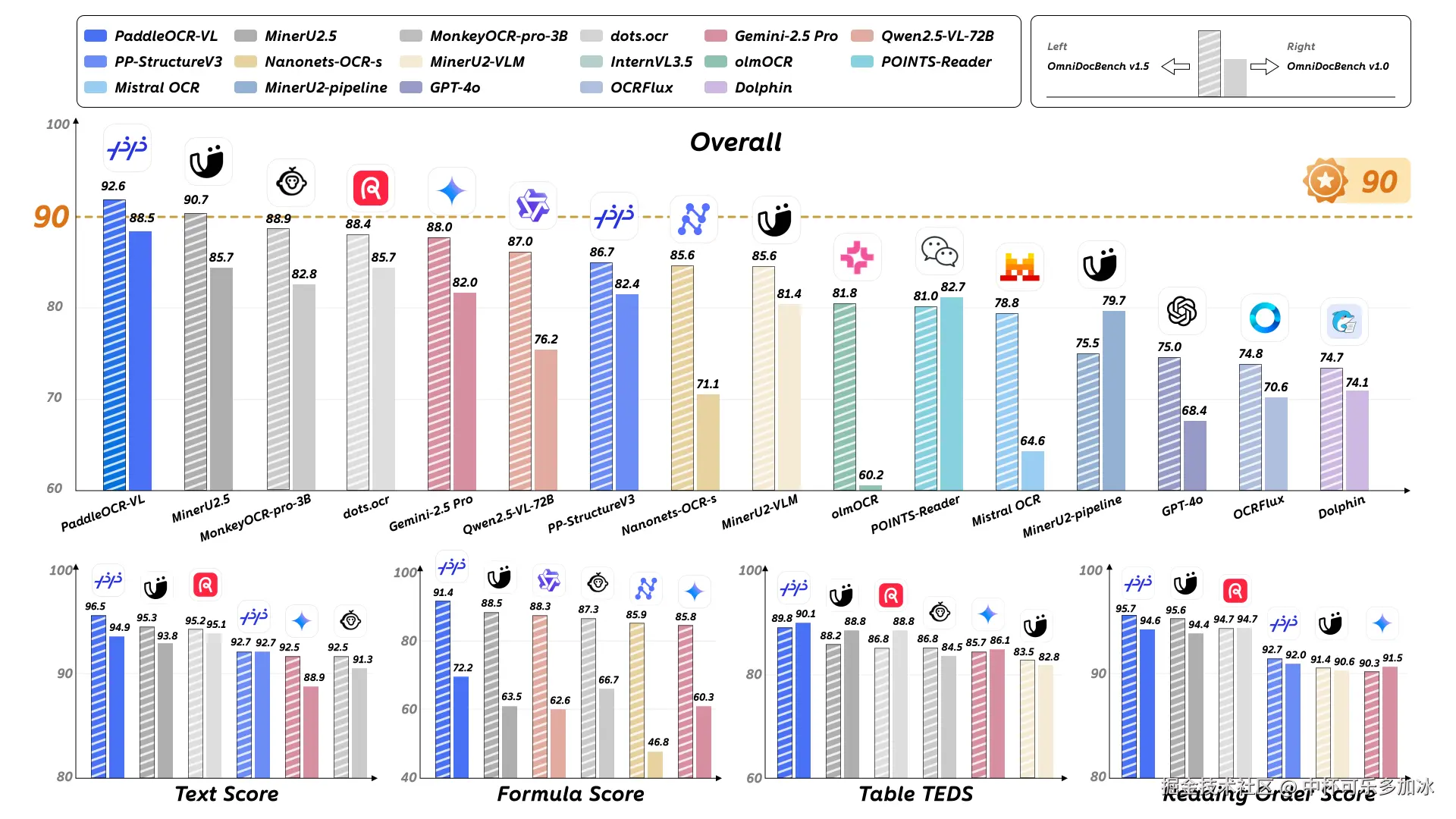
PaddleOCR-VL在OmniDocBench V1.5评测榜单中表现卓越,位列全球第一 。这一成绩不仅是数字上的领先,更是对模型综合实力的有力证明。它实现了对赛道内所有大小模型的全面超越,在文档解析的四大核心能力维度------文本识别、公式识别、表格理解、阅读顺序中,PaddleOCR-VL均位居Top1。
三、百度PaddleOCR-VL场景实测
PaddleOCR-VL 现在已经全面开源,项目地址和在线Demo如下,感兴趣的朋友可以自己去试试。
- Github:github.com/PaddlePaddl...
- HuggingFace:huggingface.co/PaddlePaddl...
- 体验Demo:aistudio.baidu.com/application...
这里,我也重点测试了几个比较常见的场景,看看它的实际表现。
- 书籍文档识别实测
在技术文档解析测试中,PaddleOCR-VL展现出了令人印象深刻的多模态理解能力。模型不仅准确提取了题目中的已知条件、待求量和选项信息,还生成了结构化的解题步骤描述。
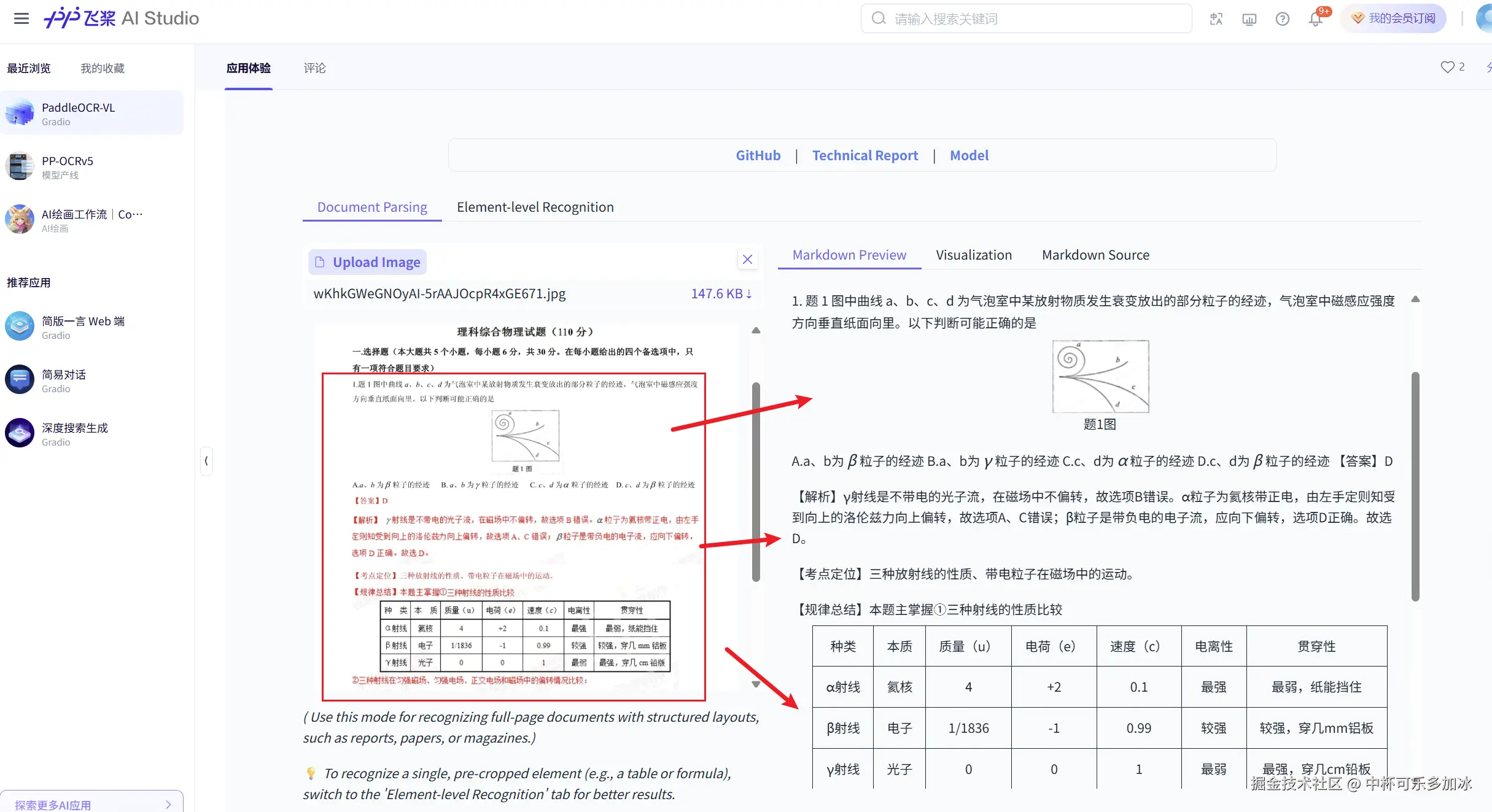
针对试题中涉及的物理图示进行了专业级的解析,模型将示意图中的关键物理要素------如物体的类别、本质属性、质量、电荷量、运动速度等参数进行了系统提取,并组织成清晰的表格形式。这种深度的内容理解能力,远超传统OCR系统的简单文字识别范畴。
- 学术论文版面分析测试
学术论文的数字化处理一直是文档理解领域的难点。评测选用了一篇采用双栏排版、包含多个复杂图表和数学公式的PDF格式学术论文。PaddleOCR-VL通过先进的视觉布局分析技术,精准地识别并划分了论文的各个内容区域,包括标题、摘要、正文、图表及参考文献等部分。
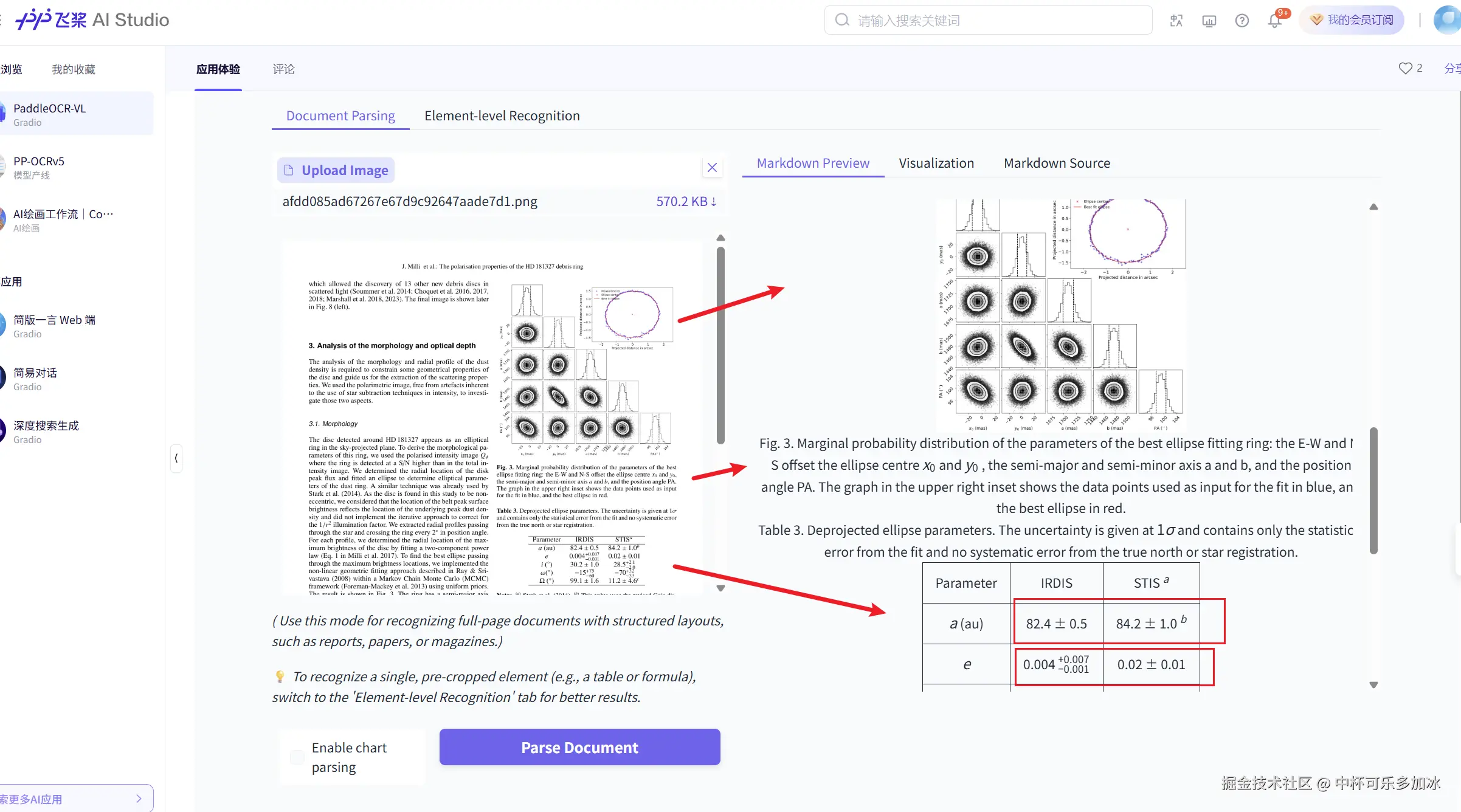
可以看到,面对双栏排版的PDF学术论文,模型也能通过视觉布局分析精准划分内容区域。在解析过程中,模型准确建立了图表与其标题的对应关系,对文中大量使用的矢量符号和上下标标注保持了极高的还原精度。这种能力对于学术文献的数字化重构和知识挖掘具有重要意义,为科研工作者提供了高效的文献处理工具。
- 手写文档适应性验证
手写文档的识别长期以来都是OCR领域的挑战性任务。测试选用了一份实验报告单,其中包含手写表格和连笔书写的内容。
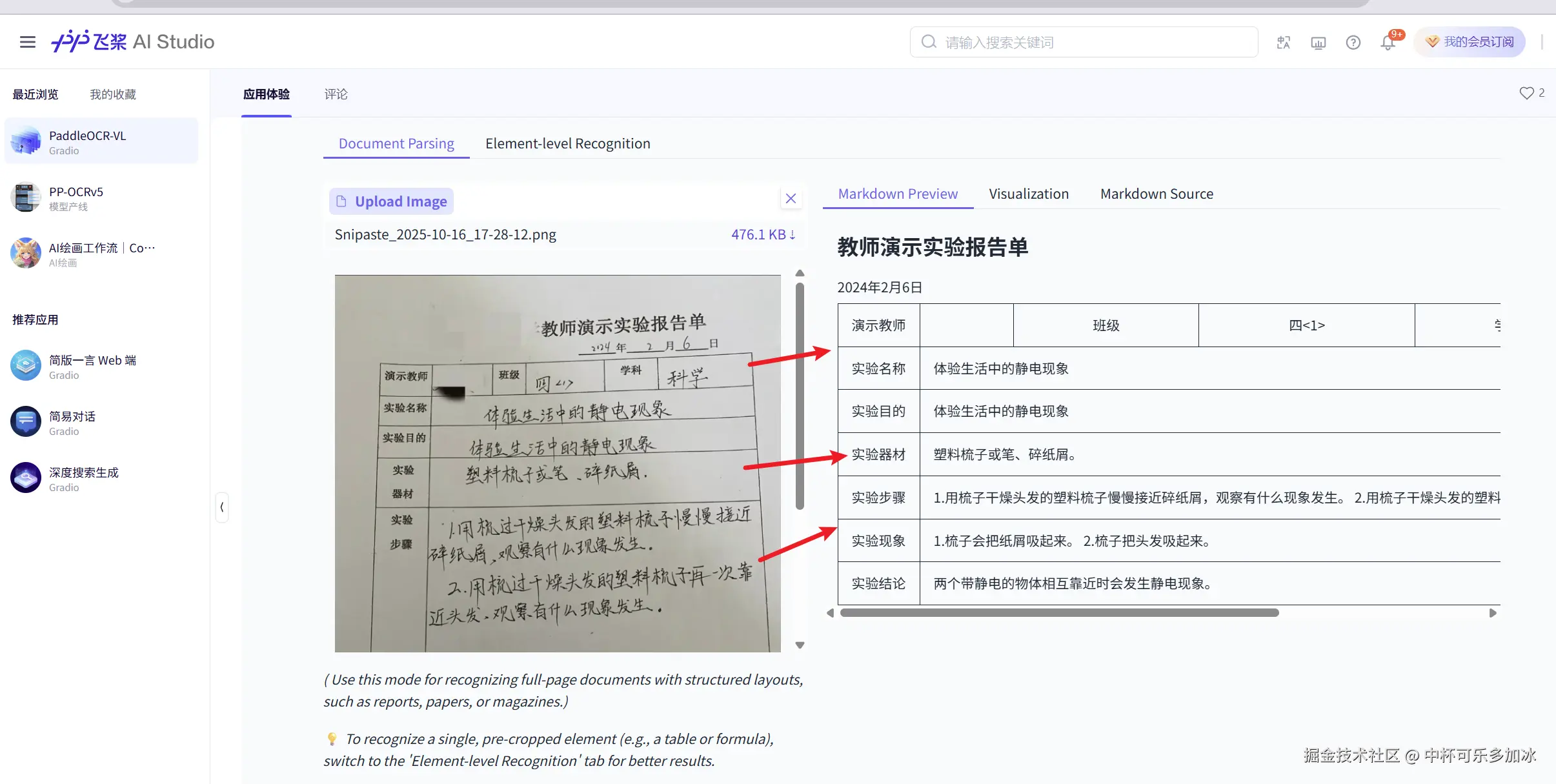
PaddleOCR-VL展现出了强大的手写体适应能力,准确识别了实验名称、目的、器材清单、操作步骤等关键信息。模型不仅将潦草的手写内容转换为可编辑的文本格式,还保持了原文的逻辑结构和语义完整性。这种能力使得手写笔记的数字化整理变得简单高效,为教育、医疗等领域的文档数字化提供了实用解决方案。
- 数学公式双向解析
数学公式的识别与处理是衡量文档智能系统技术水平的重要标尺。针对文档中的公式内容,PaddleOCR-VL展现了高度的准确性。模型能够识别包括积分、求和、分数以及各种数学运算符在内的复杂公式。
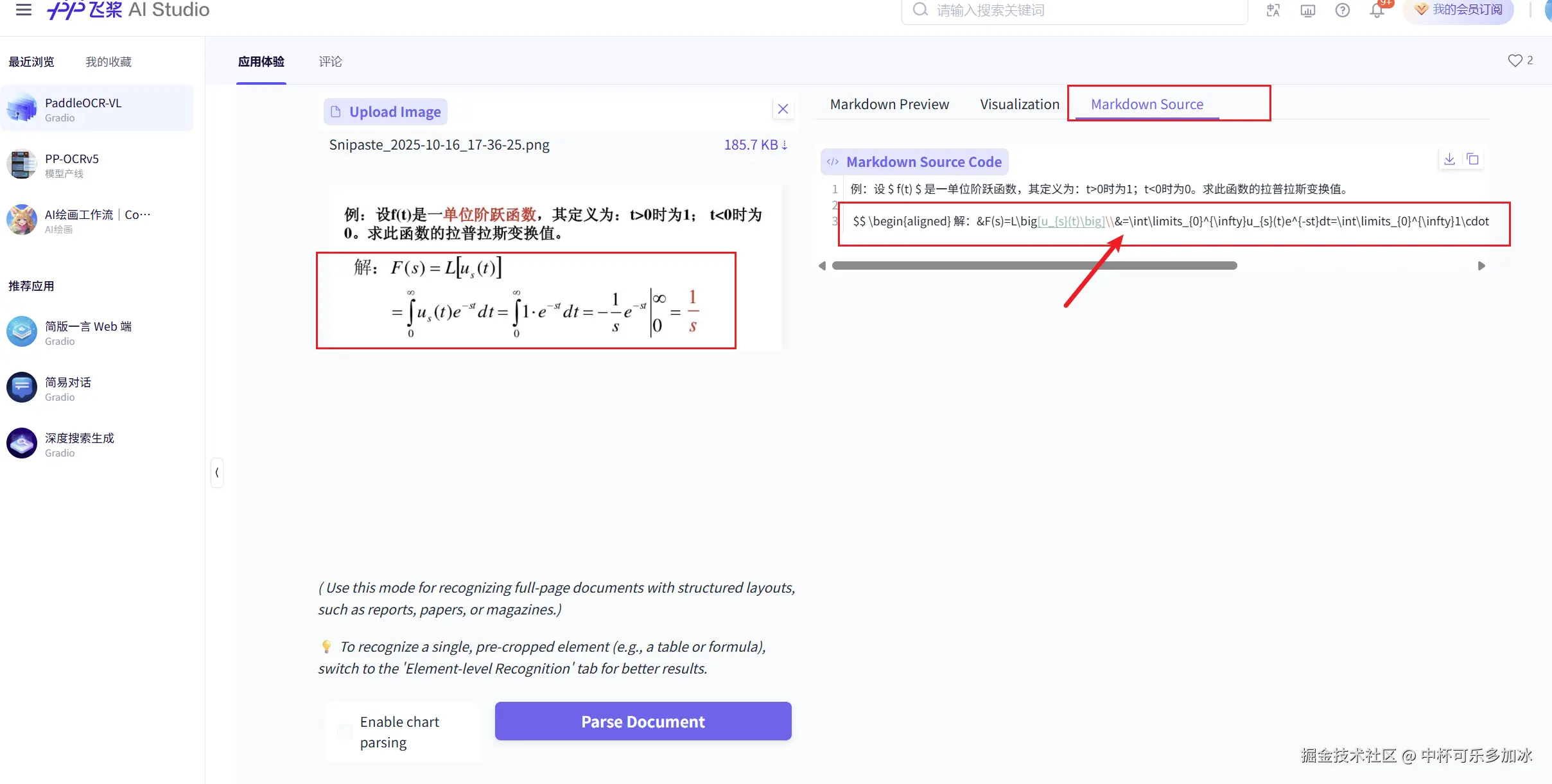
除此之外,在识别数学公式的基础上,PaddleOCR-VL还将识别结果转换为了标准LaTeX表达式,这对于学术写作、教育材料的数字化以及数学公式的进一步处理具有重要意义。
- 表格语义理解测试
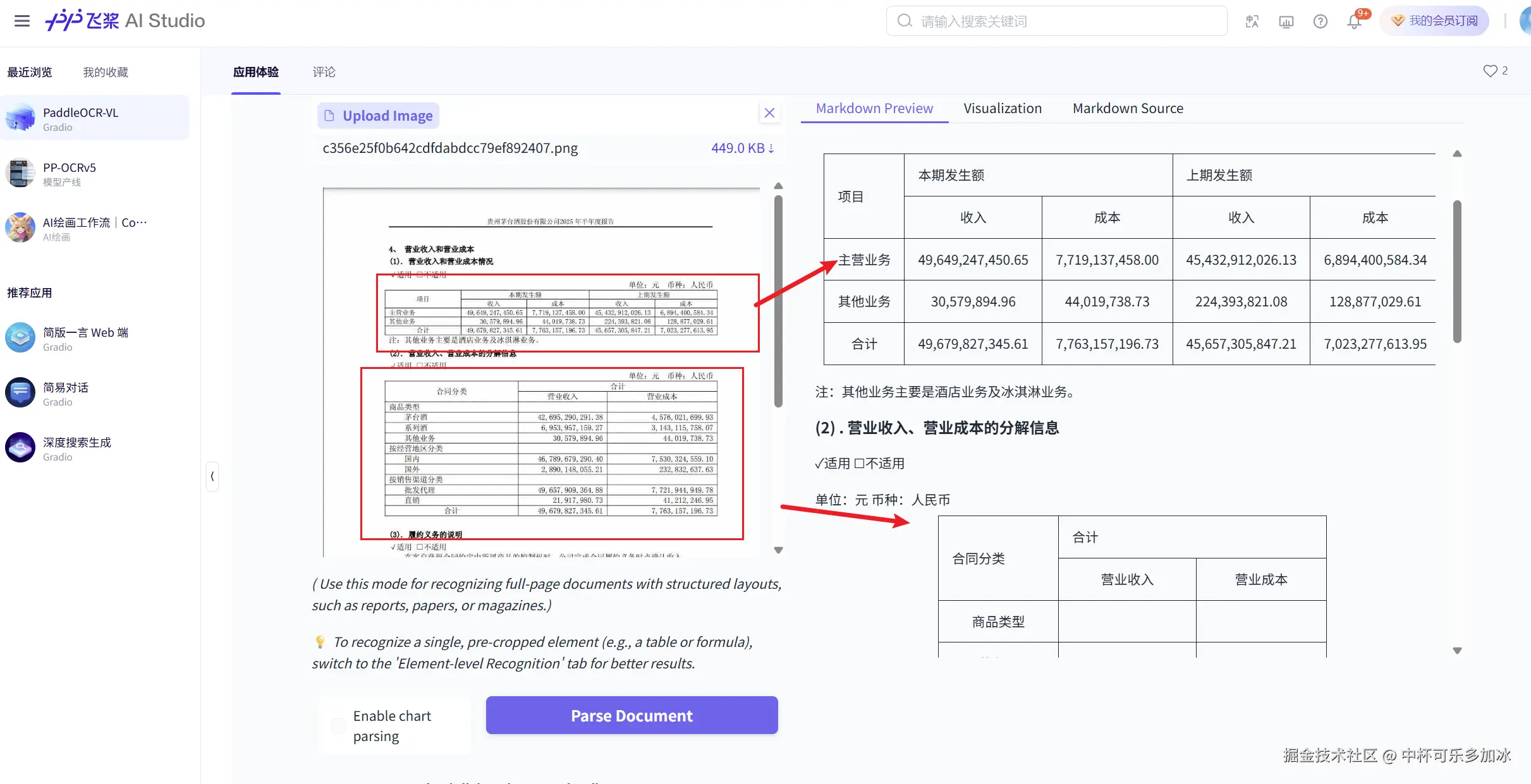
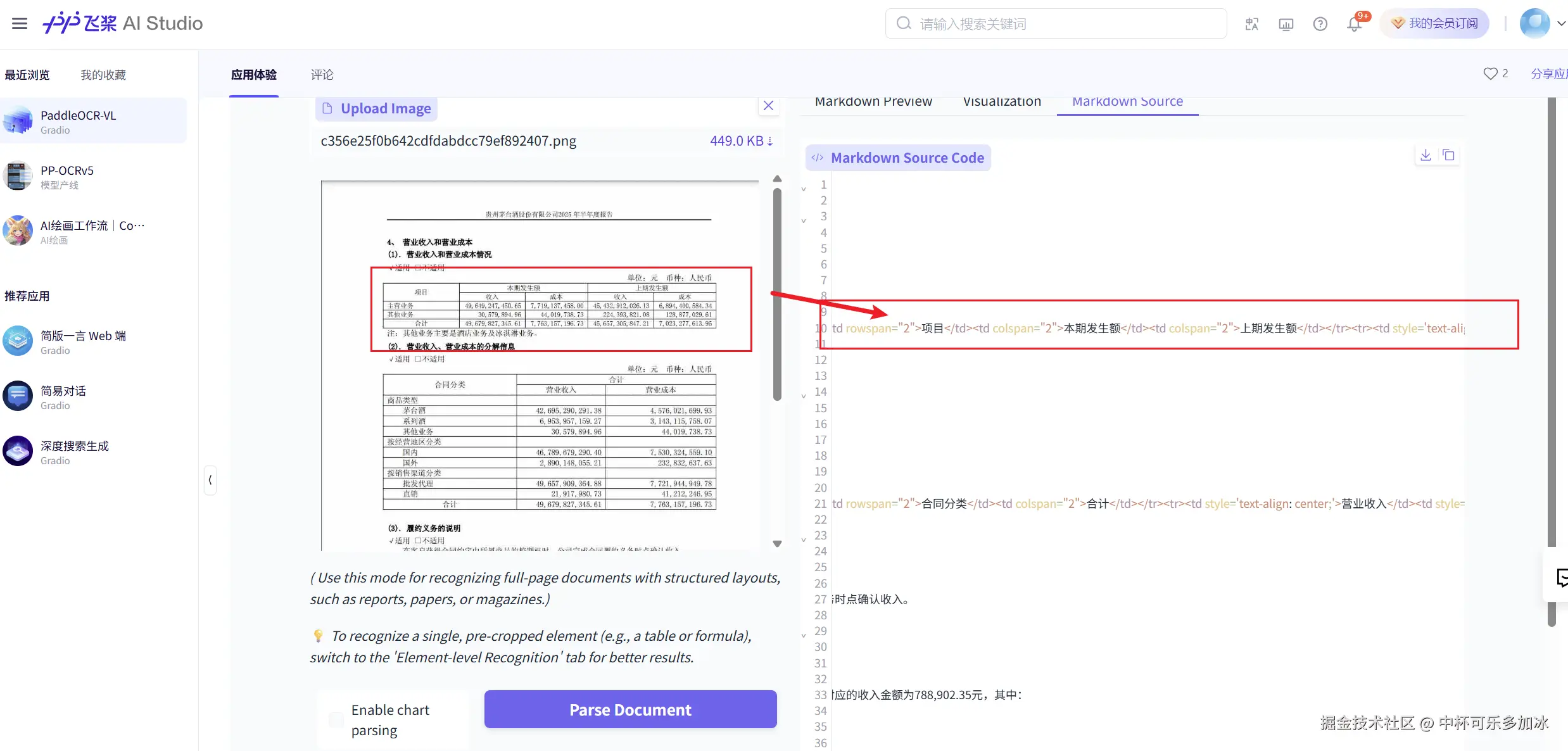
针对复杂的财务报表,PaddleOCR-VL展现出了超越传统表格识别技术的语义理解能力。模型不仅准确提取了表格中的数值数据,还深入理解了数据之间的结构和上下文关系。更为重要的是,模型将这些理解转化为结构清晰的Markdown格式输出,保持了表格的层次关系和语义关联。这种深度的表格理解能力,使得后续的数据分析和业务处理变得更加直接和高效。
通过系统的性能评估和多场景实测,可以清晰地看到PaddleOCR-VL在文档智能理解领域的技术优势,PaddleOCR-VL并非简单的文字识别与版面分析的组合,而是实现了真正的多模态深度融合,从底层的字符识别,到中层的结构分析,再到高层的语义理解,其展现全面而均衡的性能表现,能够满足实际应用的需求
四、开源力量,技术普惠
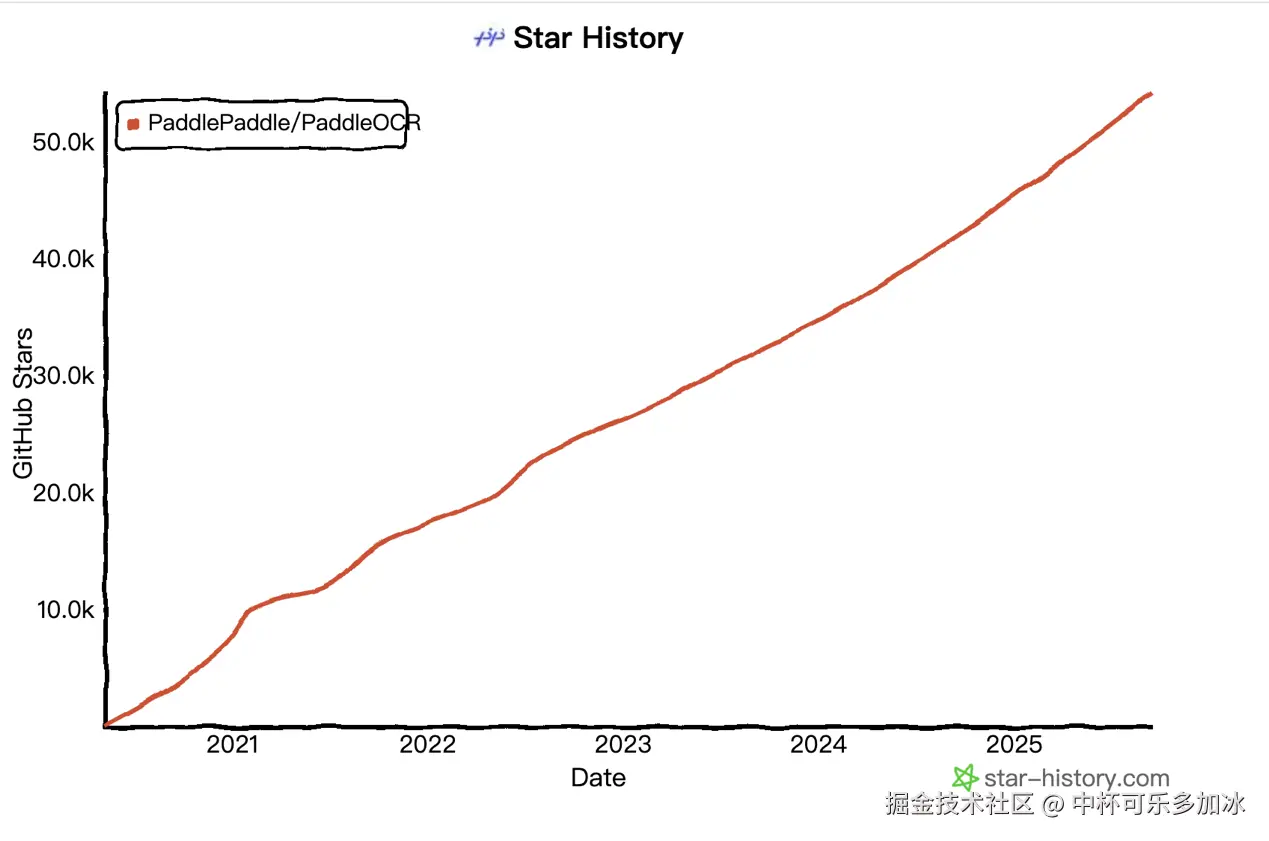
PaddleOCR项目自2020年开源以来,已成为GitHub社区中唯一一个Star数超过50k的中国OCR项目,累计下载量突破900万,被超过5.9k开源项目直接或间接使用。其技术实力和社区影响力可见一斑。
PaddleOCR项目不仅在技术上持续创新,更致力于将先进的OCR技术普惠给广大开发者。今年,PaddleOCR团队陆续推出了文字识别方案PP-OCRv5、文档解析方案PP-StructureV3、关键信息抽取方案PP-ChatOCRv4等项目,最新开源的PaddleOCR-VL则是擅长多模态文档解析领域。
在上个月,PP-OCRv5登上GitHub全球总榜Trending榜,相关技术博客连续一周登顶Hugging Face博客热度榜首,都充分展现了PaddleOCR团队在开源社区的强大号召力和技术影响力。
PaddleOCR-VL的发布,再次印证了百度在OCR及多模态领域的深厚积累和领先地位。作为文心4.5的最强衍生模型,它不仅是技术突破的里程碑,更是大模型时代赋能千行百业、推动数字化转型的重要力量。我们期待PaddleOCR-VL能在未来带来更多创新应用,共同开启智能文档处理的新篇章。