前言
文本主要是介绍一种在 Vue 项目中自定义 markdown 解析规则并渲染 Vue 组件的方式,这里借助一个实际的业务场景来分析如何实现这个功能
需求分析
需求是基于 Vue 写一个 AI 前端对话网页,并且实现类似于腾讯元宝的联网搜索功能,具体效果可以参考下面的页面截图:

我们知道,AI 返回的内容是 markdown 格式的,因此图中那些标注引用来源的小圆点,实际上是由 markdown 解析器对某种自定义语法进行渲染后生成的。为了确认这一点,我们可以打开开发者工具,查看 AI 流式返回的原始内容到底是什么样子:
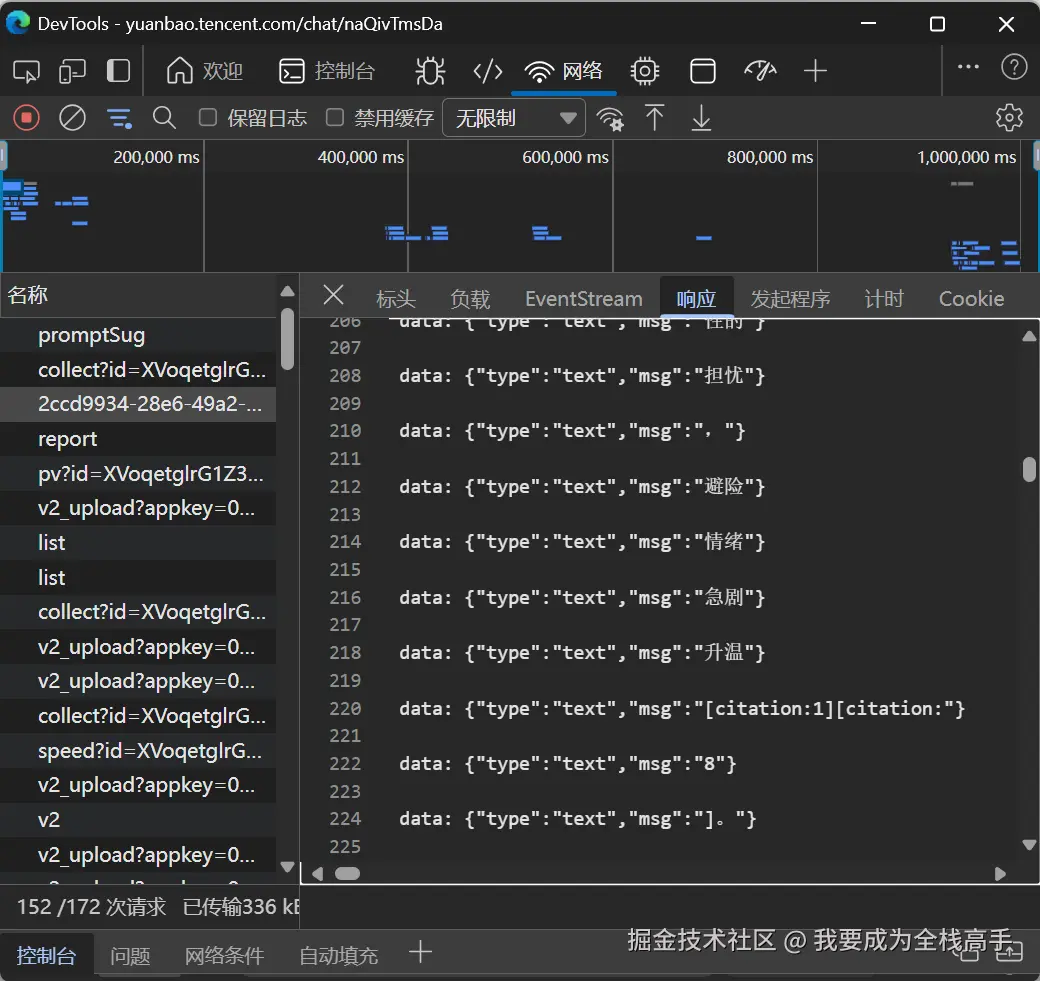
实际上,标注引用来源的小圆点,其本质是 markdown 解析器解析特定语法并进行渲染的结果。当解析器遇到 [citation:<num>] 格式的文字(<num> 为引用在搜索结果列表中的索引)时,便会将其渲染为对应的小圆点
当我们的鼠标悬停在小圆点上的时候,上方还会有一个悬浮的网页卡片,这个需求的实现方法在文章后面也会写到,先把基本的小圆点给渲染出来
项目准备
本文的示例代码的 Vue 版本是 vue3,采用的 markdown 解析器是 unified
为什么要用这个 markdown 解析器呢?因为这个解析器的插件系统允许深度定制解析流程,适合需要非标准语法扩展的场景
这里顺带附上本文示例代码中涉及到的所有和 markdown 解析器相关的依赖:
bash
# 核心依赖
npm install unified
npm install remark-parse
npm install remark-rehype
npm install rehype-stringify
# 插件依赖
npm install remark-gfm
npm install remark-math
npm install rehype-katex
npm install rehype-raw
# 工具依赖
npm install hast
npm install unist-util-visit
# 类型依赖
npm install --save-dev @types/hast基础 Markdown 渲染
先不考虑对于自定义语法的解析,先基于 unified 把最基本的 markdown 语法渲染给实现了
首先我们先创建一个 MarkdownRenderer 组件,文件结构如下:
markdown
components/
└── MarkdownRender/
├── index.vue
└── processor.tsprocessor.ts 写的是 markdown 处理器的核心逻辑:
typescript
import { unified } from 'unified'
import remarkParse from 'remark-parse'
import remarkGfm from 'remark-gfm'
import remarkMath from 'remark-math'
import remarkRehype from 'remark-rehype'
import rehypeKatex from 'rehype-katex'
import rehypeRaw from 'rehype-raw'
import rehypeStringify from 'rehype-stringify'
/**
* 将 Markdown 内容处理为 HTML 字符串的异步函数
*
* @param content - 原始 Markdown 文本内容
* @returns 处理后的 HTML 字符串
*/
export async function processMarkdown(content: string) {
// 预处理数学公式标记:
// 1. 将 \(公式\) 格式的行内数学公式转换为 $公式$ 格式,以便 remark-math 正确识别
// 2. 将 \[公式\] 格式的块级数学公式转换为 $$公式$$ 格式,以便 remark-math 正确识别
const processed = content
.replace(/\\\(([^]*?)\\\)/g, (_, math) => `$${math}$`)
.replace(/\\\[([^]*?)\\\]/g, (_, math) => `$$${math}$$`)
// 创建统一处理器实例,并配置处理流水线
const processor = unified()
// 使用 remark-parse 将 Markdown 文本解析为 MDAST
.use(remarkParse)
// 使用 remark-gfm 添加对 GFM 扩展语法的支持
.use(remarkGfm)
// 使用 remark-math 识别和解析数学公式语法
.use(remarkMath)
// 使用 remark-rehype 将 MDAST 转换为 HAST (HTML AST)
.use(remarkRehype)
// 使用 rehype-raw 允许保留原始 HTML 标签
.use(rehypeRaw)
// 使用 rehype-katex 将数学公式渲染为美观的数学符号
.use(rehypeKatex)
// 添加 rehype-stringify 将 HAST 编译为 HTML 字符串
.use(rehypeStringify)
// 执行处理流程,将预处理后的内容转换为 HTML
const file = await processor.process(processed)
// 返回处理结果中的 HTML 字符串
return file.value as string
}处理器接收原始的 markdown 文本字符串,可以返回解析之后得到的 HTML 字符串。然后我们可以直接通过 v-html 指令将解析得到的 HTML 字符串绑定到一个容器元素里面:
vue
<script setup lang="ts">
import { ref, watch, defineOptions } from 'vue'
import { processMarkdown } from './processor'
defineOptions({
name: 'MarkdownRenderer',
})
const props = defineProps<{
content: string
}>()
const htmlString = ref('')
// 监听 content 变化
watch(
() => props.content,
async (newContent) => {
htmlString.value = await processMarkdown(newContent)
},
{ immediate: true },
)
</script>
<template>
<div class="markdown-container" v-html="htmlString"></div>
</template>
<style>
@import 'katex/dist/katex.min.css';
.markdown-container {
line-height: 1.6;
}
/* 基础 Markdown 样式 */
.markdown-container h1 {
font-size: 2em;
margin: 0.67em 0;
}
.markdown-container h2 {
font-size: 1.5em;
margin: 0.75em 0;
}
.markdown-container p {
margin: 1em 0;
}
.markdown-container pre {
background-color: #f6f8fa;
padding: 16px;
border-radius: 6px;
overflow: auto;
}
.markdown-container code {
font-family: monospace;
background-color: rgba(175, 184, 193, 0.2);
padding: 0.2em 0.4em;
border-radius: 6px;
}
.markdown-container blockquote {
border-left: 4px solid #dfe2e5;
color: #6a737d;
padding: 0 1em;
margin: 0 0 1em 0;
}
.markdown-container table {
border-collapse: collapse;
width: 100%;
}
.markdown-container th,
.markdown-container td {
border: 1px solid #dfe2e5;
padding: 6px 13px;
}
.markdown-container tr {
background-color: #fff;
border-top: 1px solid #c6cbd1;
}
.markdown-container tr:nth-child(2n) {
background-color: #f6f8fa;
}
</style>然后我们在 App.vue 里面写一下测试代码:
vue
<script setup lang="ts">
import { ref } from 'vue'
import MarkdownRenderer from '@/components/MarkdownRender/index.vue'
// 基本Markdown语法测试
const basicMarkdown = ref(`
# 标题1
## 标题2
这是一个段落,包含**粗体**和*斜体*文本。
- 无序列表项1
- 无序列表项2
1. 有序列表项1
2. 有序列表项2
> 这是一个引用块
\`行内代码\`
`)
// 数学公式测试
const mathMarkdown = `
# 数学公式测试
行内公式:$E = mc^2$
块级公式:
$$
\\int_{0}^{\\infty} e^{-x^2} dx = \\frac{\\sqrt{\\pi}}{2}
$$
转义括号公式:\\(a^2 + b^2 = c^2\\) 和 \\[x = \\frac{-b \\pm \\sqrt{b^2 - 4ac}}{2a}\\]
`
// GFM扩展语法测试
const gfmMarkdown = `
# GFM扩展语法测试
## 表格
| 姓名 | 年龄 | 城市 |
| ---- | ---- | ---- |
| 张三 | 25 | 北京 |
| 李四 | 30 | 上海 |
## 删除线
~~这是删除的文本~~
## 任务列表
- [x] 已完成任务
- [ ] 未完成任务
`
</script>
<template>
<div class="container">
<!-- 测试基本Markdown语法 -->
<MarkdownRenderer :content="basicMarkdown" />
<!-- 测试数学公式 -->
<MarkdownRenderer :content="mathMarkdown" />
<!-- 测试GFM扩展语法 -->
<MarkdownRenderer :content="gfmMarkdown" />
</div>
</template>
<style scoped>
.container {
padding: 20px;
}
</style>
测试效果没有问题,至此我们已经完成了基础 markdown 语法的解析和渲染
但如果我们要实现「需求分析」中提到的引用小圆点和悬浮网页卡片的需求,思路肯定是去自定义一套解析规则,并且最好能实现直接渲染一个 Vue 组件,这样的话我们可以自由定制渲染内容和交互逻辑
至于怎么实现渲染 Vue 组件,这里先卖个关子,先来简单了解一下 unified 的工作流程
unified 工作流程简述
假设现在有如下这样一段 markdown 字符串:
markdown
# 标题
这是一个**粗体**文本。
行内公式:$E = mc^2$以我们之前编写的那个 markdown 解析器为例,讲解一下它是怎么解析上面这段 markdown 字符串的
文本字符串转 MDAST
remarkParse 插件会把 markdown 字符串文本解析为抽象语法树:
json
{
"type": "root",
"children": [
{
"type": "heading",
"depth": 1,
"children": [
{
"type": "text",
"value": "标题"
}
]
},
{
"type": "paragraph",
"children": [
{
"type": "text",
"value": "这是一个"
},
{
"type": "strong",
"children": [
{
"type": "text",
"value": "粗体"
}
]
},
{
"type": "text",
"value": "文本。"
}
]
},
{
"type": "paragraph",
"children": [
{
"type": "text",
"value": "行内公式:"
},
{
"type": "inlineMath",
"value": "E = mc^2"
}
]
}
]
}功能增强
完成了基础的转换之后,还会继续使用我们注册的一些别的插件对 markdown 解析结果再进行增强:
- GFM 扩展 (remarkGfm):增强对表格等语法的支持
- 数学公式处理 (remarkMath):专门处理数学公式节点
- 转换为 HAST (remarkRehype):将 MDAST 转换为 HTML 抽象语法树
转换后的 HAST 结构类似于:
json
{
"type": "root",
"children": [
{
"type": "element",
"tagName": "h1",
"properties": {},
"children": [
{
"type": "text",
"value": "标题"
}
]
},
{
"type": "element",
"tagName": "p",
"properties": {},
"children": [
{
"type": "text",
"value": "这是一个"
},
{
"type": "element",
"tagName": "strong",
"properties": {},
"children": [
{
"type": "text",
"value": "粗体"
}
]
},
{
"type": "text",
"value": "文本。"
}
]
},
{
"type": "element",
"tagName": "p",
"properties": {},
"children": [
{
"type": "text",
"value": "行内公式:"
},
{
"type": "element",
"tagName": "span",
"properties": {
"class": "math-inline"
},
"children": [
{
"type": "text",
"value": "E = mc^2"
}
]
}
]
}
]
}对比之前第一步解析得到的 MDAST,可以很明显地看出有如下区别:
- HAST 的节点类型是基于 HTML 标签来定义的;MDAST 的节点类型是基于 markdown 语法来定义的(比如
heading/paragraph) - HAST 具有
tagName属性,因为最终 HAST 会转化为 HTML 字符串,需要指定每个节点的标签名是什么才能进行转换;而 MDAST 没有这个属性,其节点字段定义基于 markdown 语法 - HAST 具有
properties字段,存储一些 HTML 节点的属性,比如类名、自定义属性;而 MDAST 则没有属性字段
到这一步,其实思路就已经浮现出来了,细心的你肯定可以发现,这个所谓的 HAST 和 Vue 的虚拟 DOM 有一定的相似之处,其本质都是用对象去模拟真实的 DOM 节点
那我们是不是可以不把 HAST 转化为 HTML 字符串,而是建立一个 HAST 到 VNODE 之间的映射,然后直接把映射得到的 VNODE 交给 Vue 框架自己去渲染,这样的话,我们就可以在映射的过程中,把自定义的 HAST 节点映射为 Vue 的组件来进行渲染了
原始 HTML 和数学公式处理
- 原始 HTML 支持 (rehypeRaw):允许保留原始 HTML 标签
- 数学公式渲染 (rehypeKatex):用 KaTeX 将数学公式渲染为美观的数学符号
编译为 HTML 字符串
使用 rehypeStringify 将 HAST 编译为最终的 HTML 字符串:
html
<h1>标题</h1>
<p>
这是一个
<strong>粗体</strong>
文本。
</p>
<p>
行内公式:
<span class="math-inline">E = mc^2</span>
</p>建立 HAST-VNODE 映射
获取 HAST
根据之前的思路,我们需要先去获得字符串解析得到的 HAST,要获得 HAST 得先解析得到前置产物 MDAST,我们可以通过处理器实例的 parse 方法获得 MDAST,然后再 run 方法将 MDAST 转化为 HAST:
typescript
import { unified } from 'unified'
import remarkParse from 'remark-parse'
import remarkGfm from 'remark-gfm'
import remarkMath from 'remark-math'
import remarkRehype from 'remark-rehype'
import rehypeKatex from 'rehype-katex'
import rehypeRaw from 'rehype-raw'
// 获取HAST的函数
export async function processMarkdown(content: string) {
const processed = content
.replace(/\\\(([^]*?)\\\)/g, (_, math) => `$${math}$`)
.replace(/\\\[([^]*?)\\\]/g, (_, math) => `$$${math}$$`)
console.log(processed)
// 创建处理器实例
const processor = unified()
.use(remarkParse)
.use(remarkGfm)
.use(remarkMath)
.use(remarkRehype)
.use(rehypeRaw)
.use(rehypeKatex)
// 先解析为 MDAST
const mdast = processor.parse(processed)
// 再运行转换
const hast = await processor.run(mdast)
console.log(JSON.stringify(hast, null, 2))
return hast
}
rehypeStringify这个插件可以删掉了,我们后面不需要转化为 HTML 字符串,只需要 HAST
然后这里我们用 processMarkdown 函数去获取之前例子中 markdown 文本的 HAST 结构,看看打印出了什么东西:
json
{
"type": "root",
"children": [
{
"type": "element",
"tagName": "h1",
"properties": {},
"children": [
{
"type": "text",
"value": "标题"
}
]
},
{
"type": "text",
"value": "\n" // 换行符
},
{
"type": "element",
"tagName": "p",
"properties": {},
"children": [
{
"type": "text",
"value": "这是一个"
},
{
"type": "element",
"tagName": "strong",
"properties": {},
"children": [
{
"type": "text",
"value": "粗体"
}
]
},
{
"type": "text",
"value": "文本。"
}
]
},
{
"type": "text",
"value": "\n" // 换行符
},
{
"type": "element",
"tagName": "p",
"properties": {},
"children": [
{
"type": "text",
"value": "行内公式:"
},
{
"type": "element",
"tagName": "span",
"properties": {
"className": ["katex"] // KaTeX公式样式
},
"children": [
// 以下是KaTeX公式的HTML渲染结果
{
"type": "element",
"tagName": "span",
"properties": {
"className": ["katex-html"],
"ariaHidden": "true"
},
"children": [
{
"type": "element",
"tagName": "span",
"properties": {
"className": ["base"]
},
"children": [
{
"type": "text",
"value": "E = mc²" // 最终渲染的公式文本
}
]
}
]
}
]
}
]
}
]
}这个省略版的结果再一次验证了之前的思路,HAST 的结果完全符合预期
HAST 到 VNODE 的映射
接下来就只要实现从 HAST 节点到 VNODE 的映射就行了
对于大部分 markdown 解析得到的结果都可以用 HAST 的 element 节点和 text 节点来表示(当然,节点类型不止这么点),这里我们做映射主要考虑的节点类型有:
element:表示一个 HTML 元素节点text:表示一个文本节点root:表示一个根节点
HAST 节点的 tagName 属性就是 VNODE 的 tag 属性,而 HAST 节点的 properties 属性就是 VNODE 的 props 属性,所以我们只要把 HAST 节点的 tagName 和 properties 属性分别赋给 VNODE 的 tag 和 props 属性就行了
怎么去创建 VNODE 自然不用多说,直接用 h 函数就行了。接下来我们来完成这个映射:
vue
<script setup lang="ts">
import { h, ref, watch } from 'vue'
import { processMarkdown } from './processor'
const props = defineProps<{
content: string
}>()
const rootNode = ref<any>(null)
const astToVnode = (ast: any) => {
if (ast.type === 'text') {
return ast.value
}
if (ast.type === 'element') {
return h(ast.tagName, ast.properties, ast.children?.map(astToVnode) || [])
}
return null
}
watch(
() => props.content,
async (newContent) => {
const ast = await processMarkdown(newContent)
// 直接创建包含所有子节点的根 div
rootNode.value = h(
'div',
{ class: 'markdown-container' },
ast.children?.map(astToVnode) || [],
)
},
{ immediate: true },
)
</script>
<template>
<component :is="rootNode" />
</template>
<!-- 这里不能加 scoped -->
<style>
/* 省略样式 */
</style>仍然复用之前 App.vue 的测试代码,发现渲染得到的结果是完全一样的!
阶段性总结
到这里为止,我们已经验证了之前的思路完全可行。相比于直接将 HTML 字符串插入到 DOM 中,使用 VNODE 来渲染有如下优点:
- 安全性
- v-html:存在 XSS 风险,直接插入原始 HTML
- VNode 渲染:可通过转换过程过滤危险内容,更安全
- Vue 集成度
- v-html:脱离 Vue 响应式系统,无法使用组件
- VNode 渲染:完全集成在 Vue 中,可插入自定义组件
- 自定义能力
- v-html:只能渲染固定 HTML,难以扩展
- VNode 渲染:可在转换过程中处理自定义语法和组件
- 性能
- v-html:每次全量更新,无法细粒度控制
- VNode 渲染:可实现更精细的 diff 和更新策略
实现小圆点的渲染
经过之前的一系列分析,实现小圆点渲染的方案已经呼之欲出了:
-
首先,通过某种方式去遍历解析得到的 MDAST 树,查找所有的文本节点
-
然后,使用正则表达式对文本进行匹配,检查一下文本中是否存在符合如
[citation:<num>]这种格式的文本 -
如果匹配到了,那么不要将其作为文本节点输出,而是转化为一个我们自定义的
citations类型节点,并把匹配到的数字作为节点属性存入到citations节点中 -
HAST 中也会存在我们自定义的这个节点,而后我们可以在 HAST 到 VNODE 的映射中,将这个节点直接用
h函数转化为一个 Vue 组件,最终 Vue 会把这个组件渲染成小圆点
编写自定义插件
首先我们去实现步骤 1、2、3。unist-util-visit 这个库提供了一个 visit 工具函数,它可以让我们很方便地去遍历解析得到的 MDAST 树,并且在遍历的过程中对节点进行增删改,影响最终解析输出的结果
这里直接附上笔者写的一个自定义插件,用于解析小圆点语法:
typescript
import { visit } from 'unist-util-visit'
/**
* 自定义 remark 插件来处理 citation 标记
*/
export const remarkCitation = () => {
return (tree: any) => {
visit(tree, 'text', (node: any, index: number | undefined, parent: any) => {
const citationRegex = /\[\s*citation\s*:\s*(\d+(?:\s*[,,]\s*\d+)*)\s*\]/g
const matches = [...node.value.matchAll(citationRegex)]
if (matches.length === 0) return
const newChildren = []
let lastIndex = 0
matches.forEach((match) => {
const [fullMatch, numsString] = match
const startIndex = match.index!
// 添加匹配前的文本
if (startIndex > lastIndex) {
newChildren.push({
type: 'text',
value: node.value.slice(lastIndex, startIndex),
})
}
// 处理数字部分,支持中英文逗号和空格
const nums = numsString
.split(/[,,]\s*/)
.map((num: string) => num.trim())
// 添加citations节点
newChildren.push({
type: 'citations',
data: {
hName: 'citations',
hProperties: {
dataNums: nums.join(','),
},
},
children: [{ type: 'text', value: nums.join(',') }],
})
lastIndex = startIndex + fullMatch.length
})
// 添加剩余文本
if (lastIndex < node.value.length) {
newChildren.push({
type: 'text',
value: node.value.slice(lastIndex),
})
}
// 替换原节点
parent.children.splice(index, 1, ...newChildren)
})
}
}
export default remarkCitation这个插件可以实现如下的转化效果:
- 转化前的原始 markdown 文本
markdown
这是内容[citation:1,2]这是后续内容- 转化前的 MDAST 树
json
{
"type": "paragraph",
"children": [
{
"type": "text",
"value": "这是内容[citation:1,2]这是后续内容"
}
]
}- 转化后的 MDAST 树
json
[
{ "type": "text", "value": "这是内容" },
{
"type": "citations",
"data": {
"hName": "citations",
"hProperties": { "dataNums": "1,2" }
},
"children": [{ "type": "text", "value": "1,2" }]
},
{ "type": "text", "value": "这是后续内容" }
]插件写好之后,直接导入 processor.ts 中,并且注册插件即可让自定义解析逻辑生效
扩展 HAST-VNODE 映射
现在 HAST 树中已经存在了自定义的 citations 节点,接下来我们需要将这个自定义节点映射成 Vue 组件,才能在渲染出我们想要的小圆点的效果
首先我们完成小圆点组件 CitationList.vue 的编写:
vue
<script setup lang="ts">
interface Props {
nums: string // 以逗号分隔的数字字符串,如 "1,2,3"
}
const props = defineProps<Props>()
</script>
<template>
<span class="citation-list">
<span v-for="num in props.nums.split(',')" :key="num" class="citation">
{{ num }}
</span>
</span>
</template>
<style scoped>
/* 样式省略 */
</style>然后,在 markdown 渲染组件中,将 citations 节点映射成 CitationList 组件:
vue
<script setup lang="ts">
import { h, ref, watch } from 'vue'
import { processMarkdown } from './processor'
import CitationList from './CitationList.vue'
const props = defineProps<{
content: string
}>()
const rootNode = ref<any>(null)
const astToVnode = (ast: any) => {
if (ast.type === 'text') {
return ast.value
}
if (ast.type === 'element') {
// 处理自定义的 citations 节点
if (ast.tagName === 'citations') {
console.log(ast)
return h(CitationList, {
nums: ast.properties?.dataNums || '',
})
}
// 处理普通的 HTML 节点
return h(ast.tagName, ast.properties, ast.children?.map(astToVnode) || [])
}
return null
}
watch(
() => props.content,
async (newContent) => {
const ast = await processMarkdown(newContent)
// 直接创建包含所有子节点的根 div
rootNode.value = h(
'div',
{ class: 'markdown-container' },
ast.children?.map(astToVnode) || [],
)
},
{ immediate: true },
)
</script>
<template>
<component :is="rootNode" />
</template>
<!-- 这里不能加 scoped -->
<style>
/* 样式省略 */
</style>修改 App.vue 中的测试代码,加上测试文本文本:
markdown
这是内容[citation:1]这是后续内容测试效果如下图:
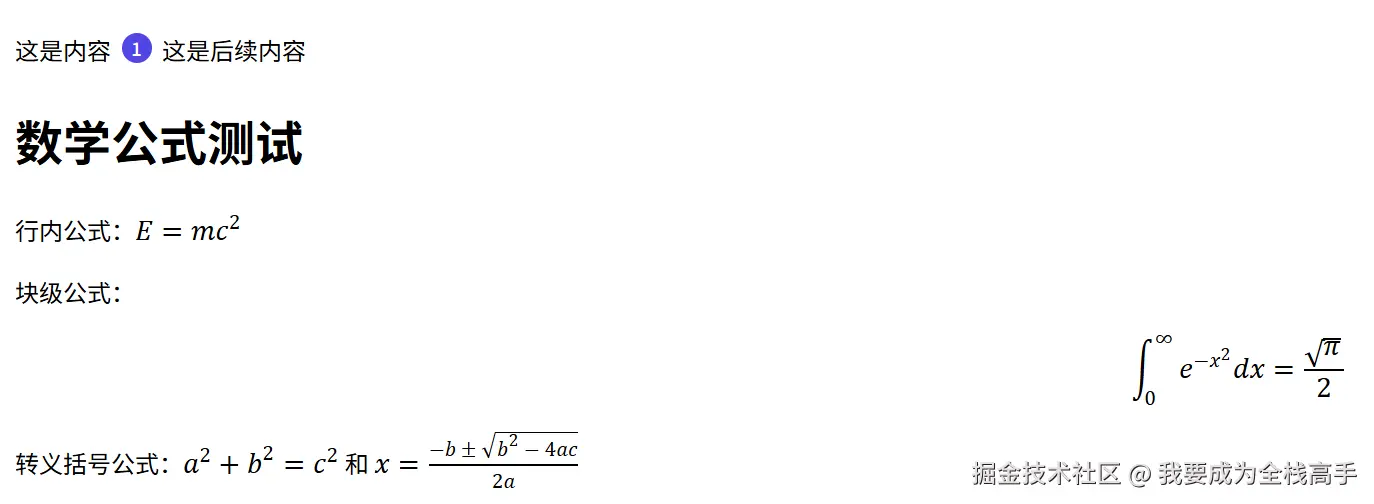
可以看到,小圆点非常完美地渲染出来了!这个小圆点就是一个正常 Vue 组件,具备所有 Vue 组件的特性,比如数据绑定、事件处理、生命周期钩子等等
拓展------实现悬浮卡片的思路
这个悬浮卡片其实就是类似于各大组件库中的 Tooltip 组件,我们只需要扩展一下 CitationList 组件,当鼠标悬浮在小圆点上的时候就显示 Tooltip 组件即可
现在最关键的问题是,悬浮卡片上展示的内容是哪里来的?
大模型的联网搜索,其实本质就是先根据用户的问题调用搜索引擎接口,然后把搜索结果在上下文中带给模型
我们可以为模型添加一个 prompt,让模型根据联网搜索的结果来生成回复,并且如果有引用联网搜索的内容的话,那么就要以 [citation:<num>] 这种格式来标注出引用的网页的编号,而搜索引擎接口返回的是一个对象数组,大致如下:
json
[
{
"name": "2024年华科专业按分排名-专业填报-高考资讯网",
"url": "http://www.gkzxw.com/major/1567890.html",
"snippet": "录取分数线 2024年华中科技大学在湖北省物理类考生中的录取分数线为635分~658分。 以上信息根据最近的数据更新整理而来,具体排名可能会根据每年的实际情况有所变动。 以上内容仅供参考,部分文章是来自自",
"siteName": "高考资讯网",
"siteIcon": "https://th.bochaai.com/favicon?domain_url=http://www.gkzxw.com/major/1567890.html",
"time": "y年M月d日"
},
{
"name": "华科录取专业线-高校招生问答平台",
"url": "http://www.zsask.com/university/2134567.html",
"snippet": "问华科录取专业线 2024-12-01 15:30:22 156次 问题描述: 华科录取专业线希望能解答下璀璨的莫过于事业 原来就是每天吃饭的筷子,每天睡觉的那张床 2024-12-01 15:30:",
"siteName": "高校招生问答平台",
"siteIcon": "https://th.bochaai.com/favicon?domain_url=http://www.zsask.com/university/2134567.html",
"time": "y年M月d日"
}
]联网搜索的结果会带给前端,小圆点里的数字其实就是上面这个数组的索引(引用了第几个搜索结果)
我们可以将上面这个搜索结果传入 MarkdownRenderer 中,再透传到 CitationList 组件中,这样就可以根据索引获取对应的搜索结果,并展示在悬浮卡片中了
具体实现代码在这里省略,感兴趣的笔者可以自行尝试实现
总结
本文详细介绍了如何在 Vue3 项目中通过自定义 markdown 解析规则来实现特殊语法(如 [citation:<num>])的解析,并将其渲染为 Vue 组件
基于 HAST-VNODE 映射的原理,我们可以自定义各种特殊语法,并且渲染成复杂的 Vue 组件,诸如 echarts 图标、mermaid 流程图等
新人第一次创作,如果本文有任何错误,欢迎各位大佬在评论区批评指正🌹