本文针对于milvus2.5.15版本的search流程进行源码分析
tips
- proxy做请求转发、结果聚合;
- 在queryNode可能会做两次rpc请求;
- queryNode和segment是一对多的关系;一个queryNode仅包含部分segment信息;
- L0 Segment是一个特殊的segment,用于专门管理删除操作,仅包含删除操作,不包含数据;
数据流
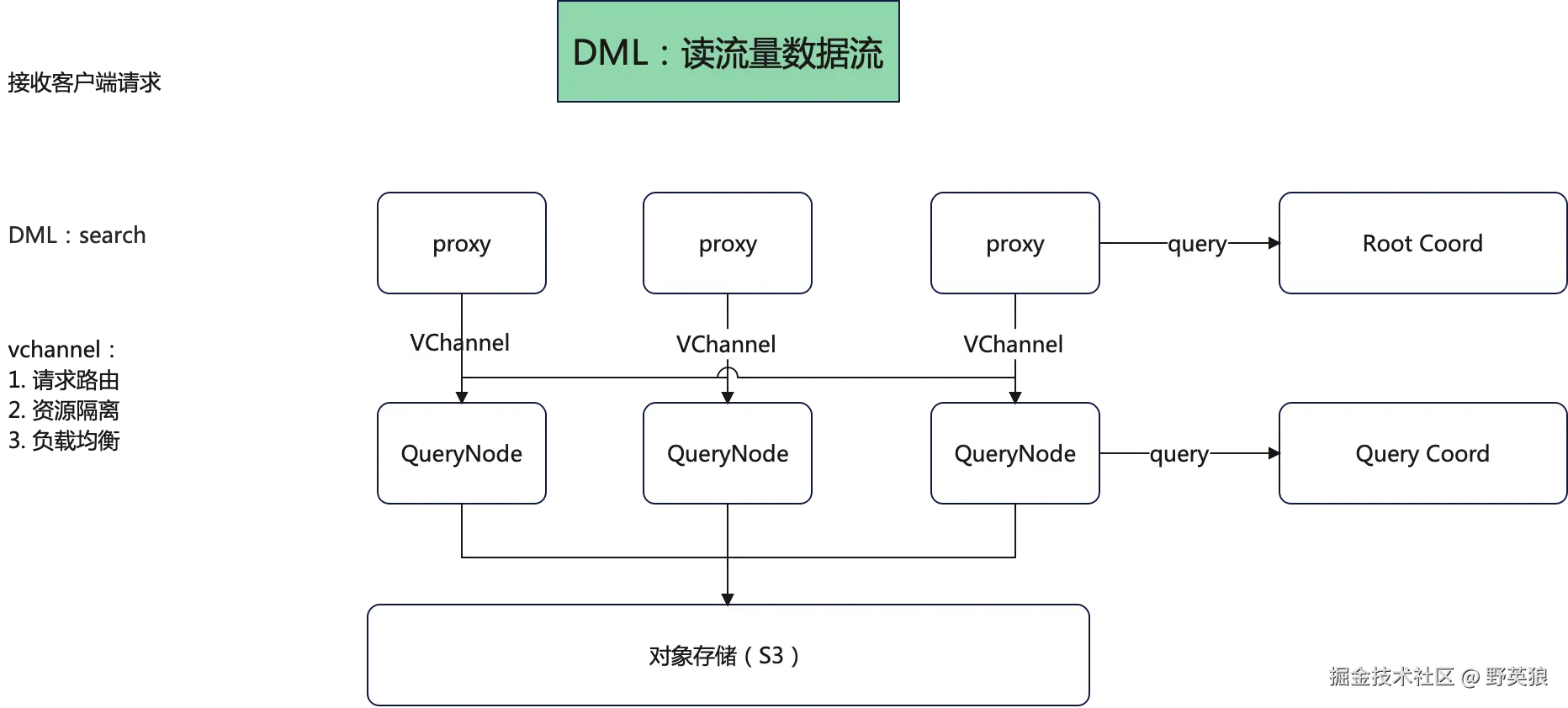
思维导图
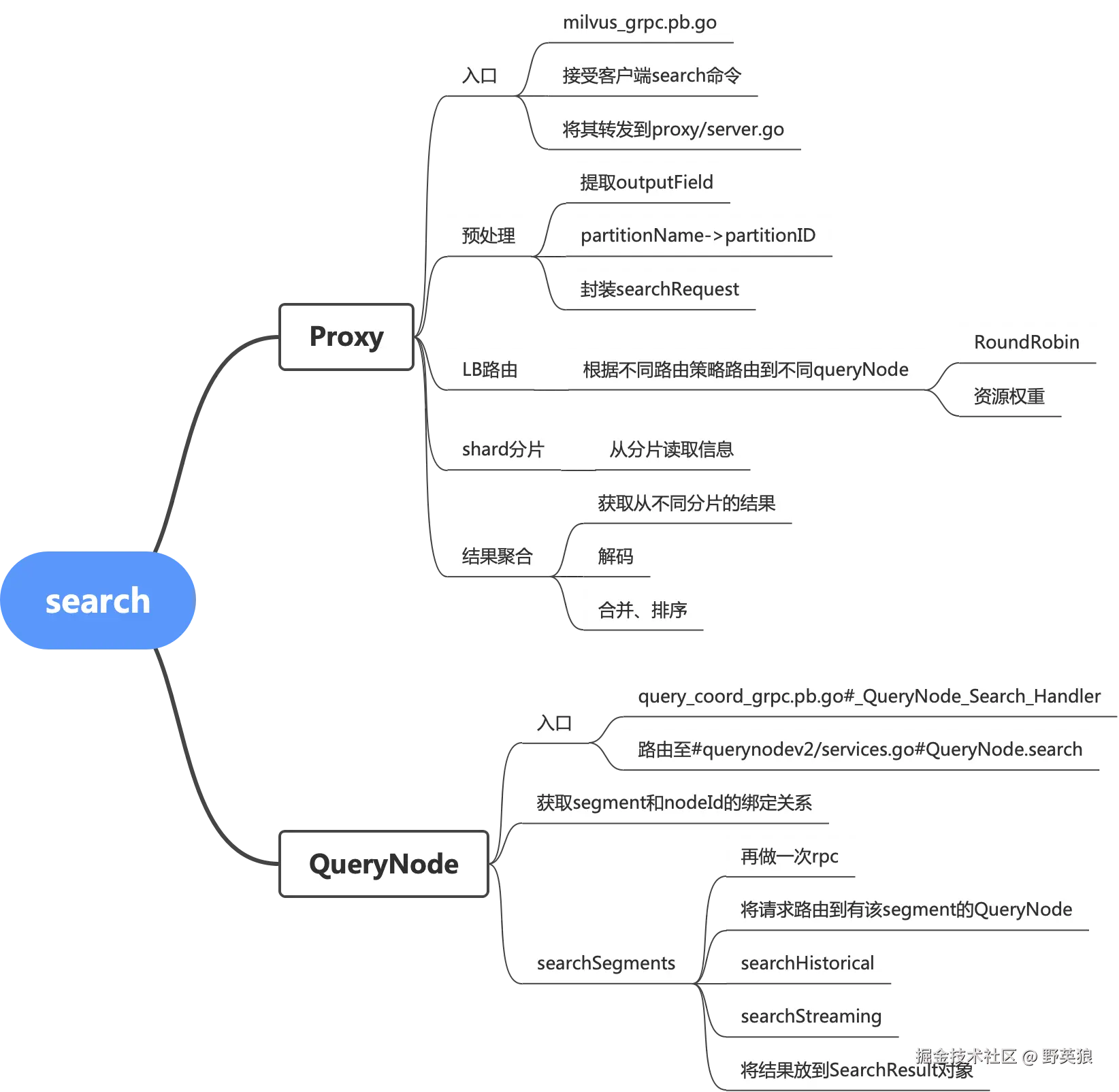
源码解析
- milvus的各个组件是通过grpc进行交互
- milvus.proto是定义行为和属性的统一入口;对应的grpc会生成一个执行类
- milvus_grpc.pb.go;milvus server的功能入口
Proxy模块
堆栈如下 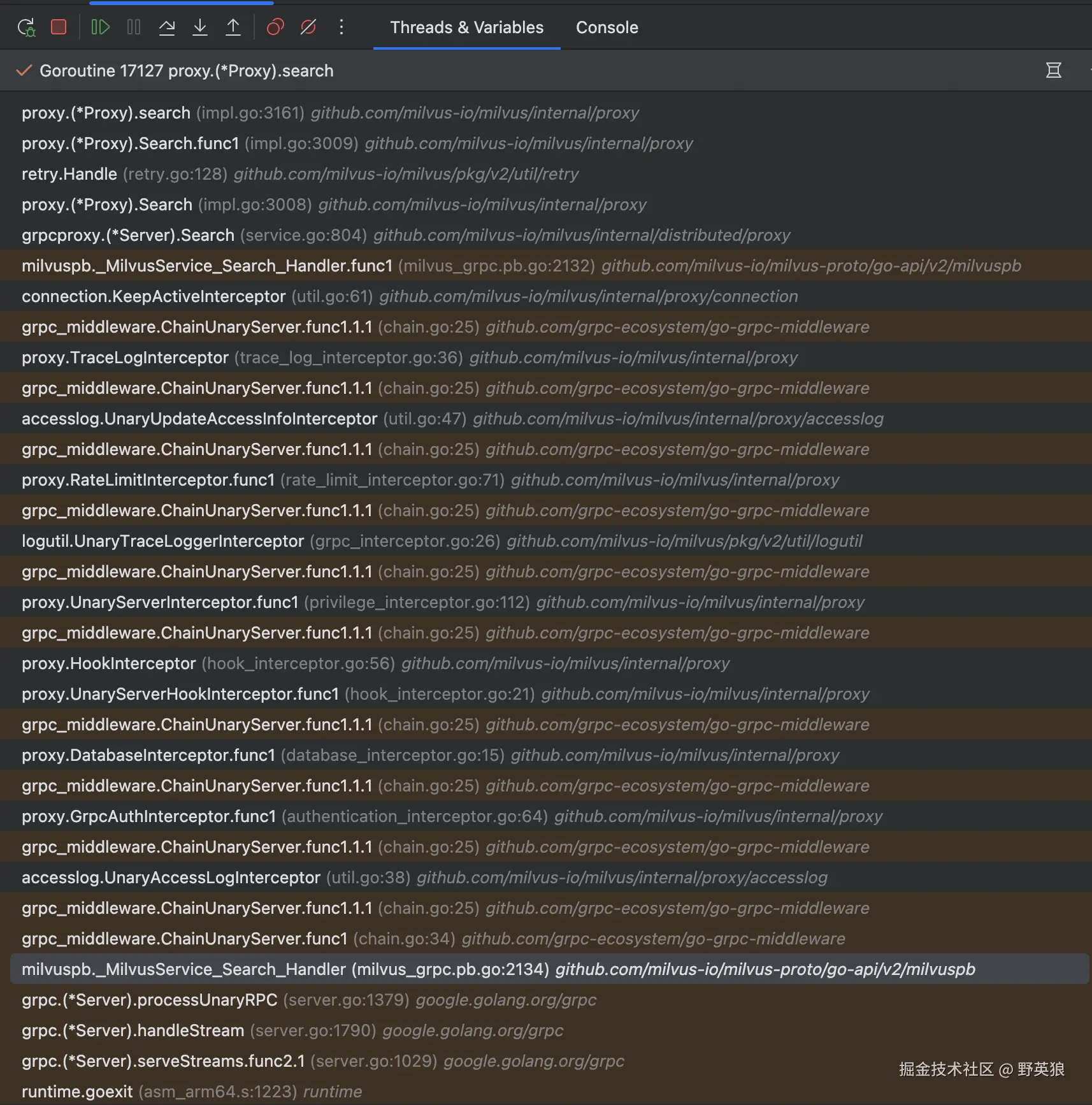
Proxy#search
经过一系列的grpc的拦截器后到internal.distributed.proxy.impl.go#search ;这相当于search方法的真正入口的地方了;
在这里面,其中最核心的一步是封装searchTask,然后将这个searchTask提交的Scheduler中,交给异步线程去执行,最后等待返回结果;
go
func (node *Proxy) search(ctx context.Context, request *milvuspb.SearchRequest, optimizedSearch bool, isRecallEvaluation bool) (*milvuspb.SearchResults, bool, bool, bool, error) {
...
qt := &searchTask{
ctx: ctx,
Condition: NewTaskCondition(ctx),
SearchRequest: &internalpb.SearchRequest{
Base: commonpbutil.NewMsgBase(
commonpbutil.WithMsgType(commonpb.MsgType_Search),
commonpbutil.WithSourceID(paramtable.GetNodeID()),
),
ReqID: paramtable.GetNodeID(),
IsTopkReduce: optimizedSearch,
IsRecallEvaluation: isRecallEvaluation,
},
request: request,
tr: timerecord.NewTimeRecorder("search"),
qc: node.queryCoord,
node: node,
lb: node.lbPolicy,
enableMaterializedView: node.enableMaterializedView,
mustUsePartitionKey: Params.ProxyCfg.MustUsePartitionKey.GetAsBool(),
}
...
// 会将这个任务提交到task_scheduler.go#taskScheduler中;
if err := node.sched.dqQueue.Enqueue(qt); err != nil {
...
}这一步会将当前的searchTask入队列;然后返回一个引用,就完成了 ;那这个searchTask在哪里执行的呢?
答案:服务启动的时候,启动的taskScheduler,
taskScheduler#queryLoop
主要的功能:创建一个pool,然后循环监听dqQueue中是否有任务需要执行,如果有,则会将放到pool中执行,如果收到done信号,就会结束任务;
go
func (sched *taskScheduler) queryLoop() {
defer sched.wg.Done()
poolSize := paramtable.Get().ProxyCfg.MaxTaskNum.GetAsInt()
// 创建一个pool
pool := conc.NewPool[struct{}](poolSize, conc.WithExpiryDuration(time.Minute))
subTaskPool := conc.NewPool[struct{}](poolSize, conc.WithExpiryDuration(time.Minute))
defer pool.Release()
defer subTaskPool.Release()
// 这里是监听执行的地方
for {
select {
case <-sched.ctx.Done():
return
case <-sched.dqQueue.utChan():
// 如果dqQueue不为空,则会弹出task,然后放到线程池中进行执行
if !sched.dqQueue.utEmpty() {
t := sched.scheduleDqTask()
p := pool
// if task is sub task spawned by another, use sub task pool in case of deadlock
if t.IsSubTask() {
p = subTaskPool
}
// 往pool中提交任务,开始执行searchTask
p.Submit(func() (struct{}, error) {
// processTask 才是执行的重点,执行完成以后,通过引用进行回传感知
sched.processTask(t, sched.dqQueue)
return struct{}{}, nil
})
} else {
log.Ctx(context.TODO()).Debug("query queue is empty ...")
}
sched.dqQueue.updateMetrics()
}
}
}taskScheduler#processTask
在这个方法开始执行
- PreExecute:参数校验、变量赋值(partitionName->partitionID)
- Execute:请求分发到不同的shard中
- PostExecute:解码、并聚合 主要是三行,pre、exec、post
go
func (sched *taskScheduler) processTask(t task, q taskQueue) {
.....
// 主要是参数校验、对象变量赋值(consistencyLevel、guaranteeTs等)、是否搜索下推(优先使用标量过滤)
err := t.PreExecute(ctx)
......
// 真正执行的地方(后续重点介绍)
// 经过LB,将请求分发到不同的shard上执行,
err = t.Execute(ctx)
......
// decode、收集结果并聚合
err = t.PostExecute(ctx)
.....
}经过searchTask.execute-> loadbalancer.Execute进行负载均衡,最终执行到searchTask.searchShard方法
scss
func (t *searchTask) Execute(ctx context.Context) error {
ctx, sp := otel.Tracer(typeutil.ProxyRole).Start(ctx, "Proxy-Search-Execute")
defer sp.End()
log := log.Ctx(ctx).WithLazy(zap.Int64("nq", t.SearchRequest.GetNq()))
tr := timerecord.NewTimeRecorder(fmt.Sprintf("proxy execute search %d", t.ID()))
defer tr.CtxElapse(ctx, "done")
err := t.lb.Execute(ctx, CollectionWorkLoad{
db: t.request.GetDbName(),
collectionID: t.SearchRequest.CollectionID,
collectionName: t.collectionName,
nq: t.Nq,
// 回调函数在这里定义的;
exec: t.searchShard,
})
if err != nil {
log.Warn("search execute failed", zap.Error(err))
return errors.Wrap(err, "failed to search")
}
log.Debug("Search Execute done.",
zap.Int64("collection", t.GetCollectionID()),
zap.Int64s("partitionIDs", t.GetPartitionIDs()))
return nil
}LBPolicyImpl#Execute
- 获取每个shard的leader
- 执行传入的searchShard函数(真正的重点)
- 将searchResult结果放到context中(decode流程在postExecute)
go
func (lb *LBPolicyImpl) Execute(ctx context.Context, workload CollectionWorkLoad) error {
// 获取每个shard的leader
dml2leaders, err := lb.GetShardLeaders(ctx, workload.db, workload.collectionName, workload.collectionID, true)
if err != nil {
log.Ctx(ctx).Warn("failed to get shards", zap.Error(err))
return err
}
// let every request could retry at least twice, which could retry after update shard leader cache
wg, ctx := errgroup.WithContext(ctx)
// 遍历所有分片的数据
for k, v := range dml2leaders {
channel := k
nodes := v
channelRetryTimes := lb.retryOnReplica
if len(nodes) > 0 {
channelRetryTimes *= len(nodes)
}
wg.Go(func() error {
// 带有重试功能的执行
return lb.ExecuteWithRetry(ctx, ChannelWorkload{
db: workload.db,
collectionName: workload.collectionName,
collectionID: workload.collectionID,
channel: channel,
shardLeaders: nodes,
nq: workload.nq,
exec: workload.exec,
retryTimes: uint(channelRetryTimes),
})
})
}
return wg.Wait()
}searchTask#searchShard
开始要执行rpc请求到queryNode;
go
func (t *searchTask) searchShard(ctx context.Context, nodeID int64, qn types.QueryNodeClient, channel string) error {
......
// 这里的qn 是qn_wrapper.go里面的qnServerWrapper
result, err = qn.Search(ctx, req)
......
}QueryNode
QueryNode模块的功能流转
经过RPC调用后,先经过querynode/service.go,流转至querynodev2/services.go进行逻辑处理
QueryNode#Search方法
internal.querynodev2.services.go 一个注意点:DmlChannels: 是从QueryCoord里面查询得到以后,逐步传过来的;是一个string字符串(比如:by-dev-rootcoord-dml_0_xxxv0)
go
func (node *QueryNode) Search(ctx context.Context, req *querypb.SearchRequest) (*internalpb.SearchResults, error) {
......
collection := node.manager.Collection.Get(req.GetReq().GetCollectionID())
......
// 获取解析结果
ret, err := node.searchChannel(ctx, channelReq, ch)
if err != nil {
resp.Status = merr.Status(err)
return resp, nil
}
......
return ret, nil
}QueryNode#searchChannel
- 在这个DmlChannel对应的shardDelegator中准备获取数据
- DmlChannel和shardDelegator是一一对应的
- 执行查询操作
- (一个DmlChanel对应多个segments时)将segments的数据进行pb解码,去重、排序后,选择topK,然后在pb编码
go
func (node *QueryNode) searchChannel(ctx context.Context, req *querypb.SearchRequest, channel string) (*internalpb.SearchResults, error) {
......
// get delegator
sd, ok := node.delegators.Get(channel)
......
// do search
results, err := sd.Search(searchCtx, req)
......
// reduce result
resp, err := segments.ReduceSearchOnQueryNode(ctx, results,
reduce.NewReduceSearchResultInfo(req.GetReq().GetNq(),
......
return resp, nil
}shardDelegator#search
- 智能剪枝
- BM25字段检索
- 分配给不同的QueryNode(该node包含segment信息)search子任务
- 真正开始调用rpc请求,并返回结果
- 结果聚合(去重、排序)
go
func (sd *shardDelegator) search(ctx context.Context, req *querypb.SearchRequest, sealed []SnapshotItem, growing []SegmentEntry) ([]*internalpb.SearchResults, error) {
......
searchAgainstBM25Field := sd.isBM25Field[req.GetReq().GetFieldId()]
......
req, err := optimizers.OptimizeSearchParams(ctx, req, sd.queryHook, sealedNum)
if err != nil {
log.Warn("failed to optimize search params", zap.Error(err))
return nil, err
}
tasks, err := organizeSubTask(ctx, req, sealed, growing, sd, sd.modifySearchRequest)
if err != nil {
log.Warn("Search organizeSubTask failed", zap.Error(err))
return nil, err
}
// 分别执行子task,
results, err := executeSubTasks(ctx, tasks, func(ctx context.Context, req *querypb.SearchRequest, worker cluster.Worker) (*internalpb.SearchResults, error) {
return worker.SearchSegments(ctx, req)
}, "Search", log)
if err != nil {
log.Warn("Delegator search failed", zap.Error(err))
return nil, err
}
log.Debug("Delegator search done")
return results, nil
}QueryNode#SearchSegments
最主要的功能就是将search任务放到了队列中,等待异步执行
scss
func (node *QueryNode) SearchSegments(ctx context.Context, req *querypb.SearchRequest) (*internalpb.SearchResults, error) {
channel := req.GetDmlChannels()[0]
......
if err := node.lifetime.Add(merr.IsHealthy); err != nil {
resp.Status = merr.Status(err)
return resp, nil
}
defer node.lifetime.Done()
......
log.Debug("start to search segments on worker",
zap.Int64s("segmentIDs", req.GetSegmentIDs()),
)
searchCtx, cancel := context.WithCancel(ctx)
defer cancel()
tr := timerecord.NewTimeRecorder("searchSegments")
log.Debug("search segments...")
if !node.manager.Collection.Ref(req.Req.GetCollectionID(), 1) {
err := merr.WrapErrCollectionNotLoaded(req.GetReq().GetCollectionID())
log.Warn("failed to search segments", zap.Error(err))
resp.Status = merr.Status(err)
return resp, nil
}
collection := node.manager.Collection.Get(req.Req.GetCollectionID())
defer func() {
node.manager.Collection.Unref(req.GetReq().GetCollectionID(), 1)
}()
var task scheduler.Task
if paramtable.Get().QueryNodeCfg.UseStreamComputing.GetAsBool() {
task = tasks.NewStreamingSearchTask(searchCtx, collection, node.manager, req, node.serverID)
} else {
task = tasks.NewSearchTask(searchCtx, collection, node.manager, req, node.serverID)
}
if err := node.scheduler.Add(task); err != nil {
log.Warn("failed to search channel", zap.Error(err))
resp.Status = merr.Status(err)
return resp, nil
}
......
}quernodev2/SearchTask#Search
- 在指定的Segment执行搜索逻辑
- 根据类型判断在Stream还是Historical Segment执行Search任务
- 最后做一次结果的聚合
scss
func (t *SearchTask) Execute() error {
log := log.Ctx(t.ctx).With(
zap.Int64("collectionID", t.collection.ID()),
zap.String("shard", t.req.GetDmlChannels()[0]),
)
if t.scheduleSpan != nil {
t.scheduleSpan.End()
}
tr := timerecord.NewTimeRecorderWithTrace(t.ctx, "SearchTask")
req := t.req
err := t.combinePlaceHolderGroups()
if err != nil {
return err
}
searchReq, err := segcore.NewSearchRequest(t.collection.GetCCollection(), req, t.placeholderGroup)
if err != nil {
return err
}
defer searchReq.Delete()
var (
results []*segments.SearchResult
searchedSegments []segments.Segment
)
if req.GetScope() == querypb.DataScope_Historical {
results, searchedSegments, err = segments.SearchHistorical(
t.ctx,
t.segmentManager,
searchReq,
req.GetReq().GetCollectionID(),
req.GetReq().GetPartitionIDs(),
req.GetSegmentIDs(),
)
} else if req.GetScope() == querypb.DataScope_Streaming {
results, searchedSegments, err = segments.SearchStreaming(
t.ctx,
t.segmentManager,
searchReq,
req.GetReq().GetCollectionID(),
req.GetReq().GetPartitionIDs(),
req.GetSegmentIDs(),
)
}
defer t.segmentManager.Segment.Unpin(searchedSegments)
if err != nil {
return err
}
defer segments.DeleteSearchResults(results)
// plan.MetricType is accurate, though req.MetricType may be empty
metricType := searchReq.Plan().GetMetricType()
if len(results) == 0 {
for i := range t.originNqs {
var task *SearchTask
if i == 0 {
task = t
} else {
task = t.others[i-1]
}
task.result = &internalpb.SearchResults{
Base: &commonpb.MsgBase{
SourceID: t.GetNodeID(),
},
Status: merr.Success(),
MetricType: metricType,
NumQueries: t.originNqs[i],
TopK: t.originTopks[i],
SlicedOffset: 1,
SlicedNumCount: 1,
CostAggregation: &internalpb.CostAggregation{
ServiceTime: tr.ElapseSpan().Milliseconds(),
},
}
}
return nil
}
relatedDataSize := lo.Reduce(searchedSegments, func(acc int64, seg segments.Segment, _ int) int64 {
return acc + segments.GetSegmentRelatedDataSize(seg)
}, 0)
tr.RecordSpan()
// 结果聚合、排序、去重、填充字段,序列化成pb格式
blobs, err := segcore.ReduceSearchResultsAndFillData(
t.ctx,
searchReq.Plan(),
results,
int64(len(results)),
t.originNqs,
t.originTopks,
)
if err != nil {
log.Warn("failed to reduce search results", zap.Error(err))
return err
}
defer segcore.DeleteSearchResultDataBlobs(blobs)
metrics.QueryNodeReduceLatency.WithLabelValues(
fmt.Sprint(t.GetNodeID()),
metrics.SearchLabel,
metrics.ReduceSegments,
metrics.BatchReduce).
Observe(float64(tr.RecordSpan().Milliseconds()))
for i := range t.originNqs {
blob, err := segcore.GetSearchResultDataBlob(t.ctx, blobs, i)
if err != nil {
return err
}
var task *SearchTask
if i == 0 {
task = t
} else {
task = t.others[i-1]
}
// Note: blob is unsafe because get from C
bs := make([]byte, len(blob))
copy(bs, blob)
task.result = &internalpb.SearchResults{
Base: &commonpb.MsgBase{
SourceID: t.GetNodeID(),
},
Status: merr.Success(),
MetricType: metricType,
NumQueries: t.originNqs[i],
TopK: t.originTopks[i],
SlicedBlob: bs,
SlicedOffset: 1,
SlicedNumCount: 1,
CostAggregation: &internalpb.CostAggregation{
ServiceTime: tr.ElapseSpan().Milliseconds(),
TotalRelatedDataSize: relatedDataSize,
},
}
}
return nil
}