
网络:传输层协议UDP和TCP
UDP
端口号
在传输层中(TCP/UDP)我们使用源ip,目标ip,源端口号,目标端口号,协议号这样一个五元组来标识一个通信netstat -n
1-1023 知名端口号,大多是被一些知名的协议内定了,http,https,ssh等
1024-65535 操作系统动态分配的端口号,客户端其他程序使用的端口号,由OS自动动态分配
所以在我们写自己的程序时,应该避免绑定这些知名端口
| 协议名称 | 默认端口号 | 传输层协议 | 核心用途 |
|---|---|---|---|
| HTTP | 80 | TCP | 超文本传输协议,用于普通网页访问、HTTP 接口通信 |
| HTTPS | 443 | TCP | 加密的 HTTP 协议(基于 TLS/SSL),用于安全的网页访问、电商支付、API 通信 |
| FTP | 21(控制) | TCP | 文件传输协议的控制连接,用于指令交互(如上传 / 下载命令);数据连接使用 20 端口(主动模式) |
| SSH | 22 | TCP | 安全外壳协议,用于远程服务器登录、命令执行、文件传输(如 SCP/SFTP)、Git 操作 |
| Telnet | 23 | TCP | 远程终端协议(明文传输,安全性差),多用于设备调试(逐渐被 SSH 替代) |
| SMTP | 25 | TCP | 简单邮件传输协议,用于发送电子邮件(服务器之间或客户端到邮件服务器) |
| POP3 | 110 | TCP | 邮局协议版本 3,用于从邮件服务器接收电子邮件(下载到本地,服务器可删除原邮件) |
| IMAP4 | 143 | TCP | 互联网邮件访问协议版本 4,用于接收电子邮件(支持远程管理邮件文件夹,不强制下载本地) |
| DNS | 53 | TCP/UDP | 域名系统,UDP 用于小报文解析,TCP 用于大报文(如超过 MTU 的响应)或区域传输 |
| DHCP | 67(服务器)/68(客户端) | UDP | 动态主机配置协议,用于自动分配 IP 地址、子网掩码、网关等网络配置信息 |
| TFTP | 69 | UDP | 简单文件传输协议,轻量级(无认证),用于设备固件升级、网络启动(PXE)等场景 |
| SNMP | 161(代理)/162(管理站) | UDP | 简单网络管理协议,用于监控网络设备(如路由器、交换机)的状态和性能 |
| MySQL | 3306 | TCP | MySQL 数据库的客户端 - 服务器通信端口,用于 SQL 指令交互和数据传输 |
| PostgreSQL | 5432 | TCP | PostgreSQL 数据库的默认通信端口 |
| MongoDB | 27017 | TCP | MongoDB 文档数据库的默认通信端口,用于客户端连接和数据操作 |
| Redis | 6379 | TCP(默认)/UDP | 内存数据库 Redis 的默认端口,支持键值对操作、缓存、消息队列等 |
| RabbitMQ | 5672(AMQP)/5671(AMQPS) | TCP | 消息队列 RabbitMQ 的默认端口,AMQP 协议用于消息的生产和消费 |
| Nginx/Apache | 80(HTTP)/443(HTTPS) | TCP | Web 服务器的默认端口,用于提供静态资源或反向代理到后端应用 |
| RDP | 3389 | TCP/UDP | 远程桌面协议,用于 Windows 系统的远程桌面连接 |
| LDAP | 389 | TCP/UDP | 轻量级目录访问协议,用于用户身份认证、组织目录查询(如企业内部系统集成) |
| LDAPS | 636 | TCP | 加密的 LDAP 协议(基于 TLS/SSL),用于安全的目录服务访问 |
| RTSP | 554 | TCP/UDP | 实时流传输协议,用于控制音视频流(如监控摄像头、流媒体服务器的播放 / 暂停) |
| SIP | 5060(UDP/TCP)/5061(TLS) | UDP/TCP | 会话初始协议,用于建立、修改和终止 VoIP 通话、视频会议等实时通信会话 |
| NFS | 2049 | TCP/UDP | 网络文件系统,用于客户端挂载远程服务器的文件系统,实现共享访问 |
| iSCSI | 3260 | TCP | 互联网小型计算机系统接口,用于将远程存储设备映射为本地磁盘(存储区域网络 SAN) |
-
一个端口号可以绑定多个进程吗?
No -
一个进程可以被多个端口绑定吗?
Yes
报文格式
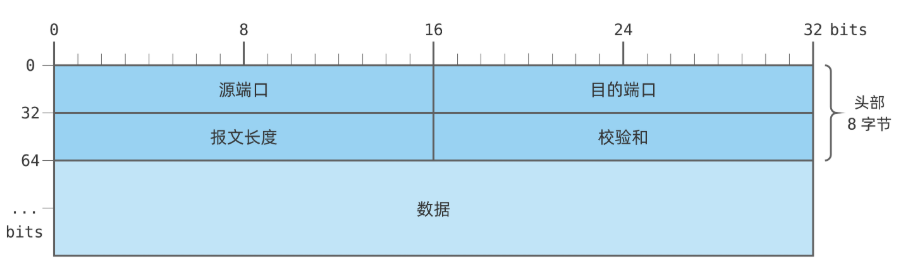
报文长度字段:记录了UDP报文包含数据内容一共的长度
校验和:通过一些算法逻辑对数据进行校验,校验不通过则直接丢弃
特点
无连接:UDP协议只需要知道对方的ip和端口就可以传输,不建立连接
不可靠:没有确认机制,没有重传机制,UDP即使传输失败也不会有任何的报错信息,因为根本不知道传输是成功还是失败
面向数据报:这一边怎么发的报文,另一边就要怎么收。不能控制读写数据次数和数量
面向数据报
也就是说应用层交给UDP一段数据,UDP既不能拆分,也不能合并,只负责保持原样发送就行
发送端调用sendto发送了100字节的数据,接收端也必须调用一个recvfrom接收100字节,不能够调用十次recvfrom每次接受10字节这样
无发送缓冲区
UDP协议在内核层面上其实是有发送缓冲区的,但是这只是为了方便和TCP公用代码,实际上UDP是不会用发送缓冲区的,应用层把数据交给UDP后,调sendto后内核添加报头后直接交给网络层进行后续的传输操作
当然UDP是有接受缓冲区的,主要是为了保证,发送和接受的数据顺序一致,当接受缓冲区满了之后再来的数据会被直接丢弃(不可靠)
UDP的socket既能读又能写,是全双工
注意事项
UDP协议报中有一个字段:最大长度,占了16位空间,所以UDP一次能够传输的最大数据量是64K,并且这还是包含了UDP报头长度的,在当今互联网中64K已经算是一个比较小的数据量了,如果我们要传输的数据量大于64K,就需要在应用层手动分包后再交给UDP多次发送,接收端收到后也需要进行手动拼装
基于UDP的一些应用层协议
NFS:网络文件系统TFTP:简单文件传输系统DHCP:动态主机配置协议BOOTP:启动协议(用于无盘设备启动)DNS:域名解析协议(需要快速响应,所以用UDP无需复杂操作)- 当然还有我们自己编写的基于
UDP的应用层协议
TCP
TCP协议全名传输控制协议 Transmission Control Protocol接下来我们就从"传输"和"控制"这两个词开始展开介绍
报文格式
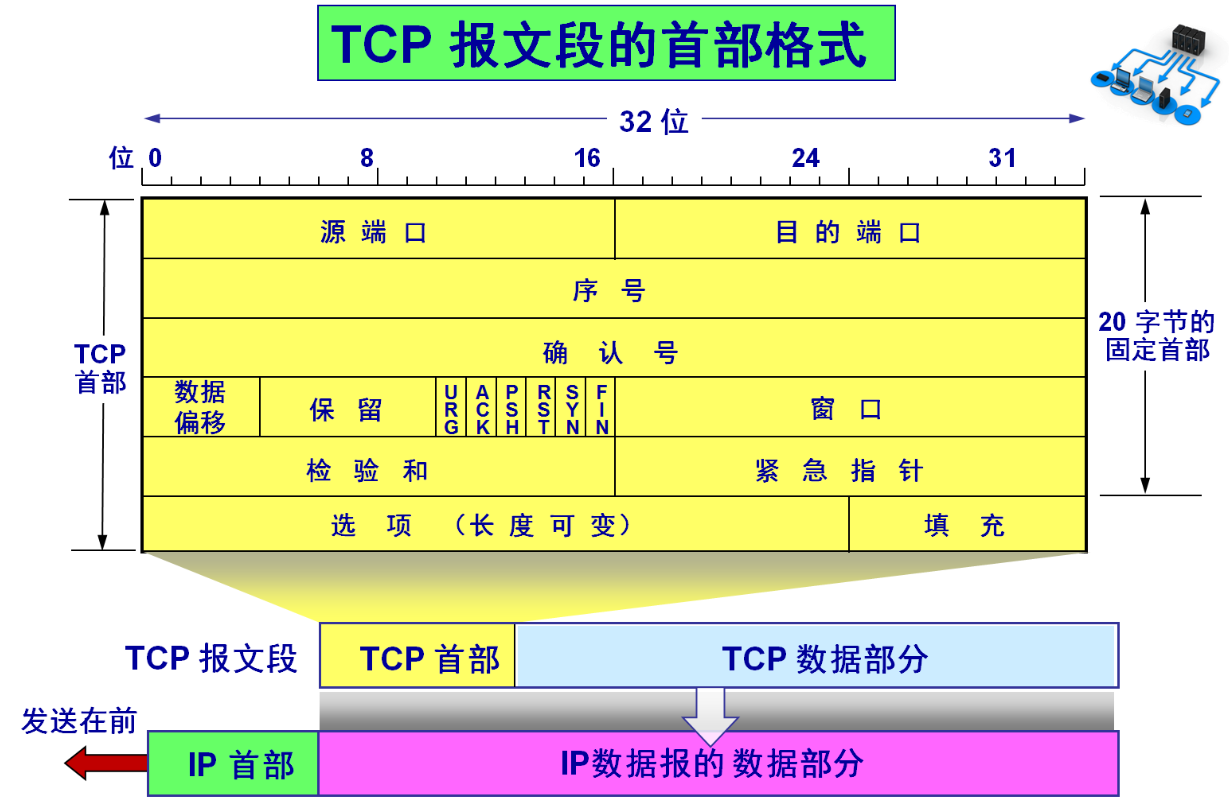
- 源端口、目的端口
- 32位序号/32位确认号:和确认应答机制有关
- 4位
TCP报头长度:表示该TCP头部有多少32bit(4字节)如果四位全是一:1111就表示有15 * 4 = 60字节(最大也就是60字节) - 六位标志位
URG:紧急指针是否有效;表示报文含紧急数据(优先处理)ACK:确认号是否有效(和确认应答机制有关)PSH:提示接收端应用程序马上从TCP缓冲区把数据读走RST:对方要求重新建立连接;携带此标识的报文叫做复位报文段SYN:请求建立连接;携带此标识的报文叫做同步报文段FIN:通知对方本端要关闭了;携带此标识的报文叫做结束报文段
- 16位窗口大小:与滑动窗口有关
- 16位校验和:发送端填充
CRC校验,接受端验证不通过,则认为数据有问题。(此处校验也包含数据部分) - 16位紧急指针:标识哪部分数据是紧急数据
- 选项:用于扩展
TCP功能如:MSS协商每个报文段能承载的最大数据长度(建立连接时确定)、窗口扩大因子、时间戳,剩余部分为填充字段补 0 使整个TCP头部的长度为4字节的整数倍即可
确认应答机制
TCP给每一个字节的数据都标了序号,就是序列号
| 字段 | 作用 | 示例 |
|---|---|---|
| 序列号(Seq) | 标识 "当前 TCP 段中第一个字节的数据在整个数据流中的位置",确保数据有序。 |
若发送方需传输 1000 字节数据(总数据流编号 1-1000),第一个段(500 字节)的 Seq=1,第二个段的 Seq=501。 |
| 确认号(ACK Num) | 标识 "接收方期望下次收到的 TCP 段的第一个字节序号",隐含 "此前所有序号的数据已成功接收"。 |
接收方成功收到Seq=1、长度 500 字节的段后,会回复 ACK Num=501(表示 "1-500 字节已收到,下次请发 501 开始的数据")。 |
超时重传机制
在发送端发送给接受端消息时,预期是会接收到ACK报文,但是如果没有接收到呢,或者是因为发送的消息根本没有到达接受端,又或者是接收端收到了消息并发送了ACK报文,但ACK报文在路上丢了。这时候发送端在经过一段时间后会重新发送报文。
这样有几个问题,接收端可能会接收到很多一样的报文,但这有序列号,相同序列号的报文即为重复报文,所以去重不是一件难事。
问题在于你如何界定发送端发送过了多少时间没有接受到ACK报文即为超时呢?
- 找到一个最小时间,确保如果没有问题,一定可以在这个时间内收到
ACK报文- 但是你如何保证网络延迟呢
- 因为网络延迟,这个时间设定得越短,那么可能发送端会频繁发送数据包
- 那么这个时间设定得越长,可能会影响重传效率
那么TCP协议为了控制无论在任何环境下都能保证到一个不错的传输效率,这个时间是根据网络环境动态计算的
Linux中超时以500ms为一个单位进行控制,每次判定超时重发的时间总是500ms的整数倍- 如果在重发一次后,仍旧得不到回答,等待
2 * 500ms后再次重传- 如果仍旧得不到应答,等待
4 * 500ms后再次重传,以指数形式递增- 累计一定重传次数,
TCP则认为网络或者对方主机异常,强制关闭连接
连接管理机制
正常情况下TCP需要进行三次握手建立连接,四次挥手断开连接
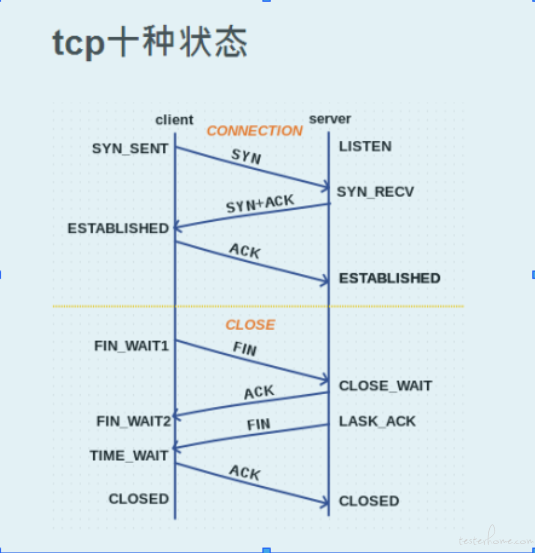
服务端状态变化
[CLOSED -> LISTEN]服务端调用listen后进入LISTEN状态,等待客户端连接[LISTEN -> SYN_RCVD]一旦监听到连接请求(同步报文段),就将该连接放入内核等待队列中,并向客户端发送SYN确认报文[SYN_RCVD -> ESTABLISHED]服务端一旦收到客户端的确认报文,就进入ESTABLISHED状态,可以进行读写数据了[ESTABLISHED -> CLOSE_WAIT]当客户端主动关闭连接(调用close),服务端会收到结束报文段,服务器返回确认报文段并进入CLOSE_WAIT[CLOSE_WAIT -> LAST_ACK]进入CLOSE_WAIT后说明服务器准备关闭连接(需要处理完之前的数据);当服务器真正调用close关闭连接时,会向客户端发送FIN,此时服务器进入LAST_ACK状态,等待最后一个ACK到来(这个ACK就是确认客户端收到了FIN)[LAST_ACK -> CLOSED]服务器收到了对FIN的ACK,彻底关闭连接
客户端状态变化
[CLOSED -> SYN_SEND]客户端调用connect,发送同步报文段[SYN_SEND -> ESTABLISHED]connect调用成功,则进入ESTABLISHED状态,开始读写数据[ESTABLISHED -> FIN_WAIT_1]客户端主动调用close时,向服务器发送结束报文段同时进入FIN_WAIT_1[FIN_WAIT_1 -> FIN_WAIT_2]客户端收到服务端对结束报文的确认,则进入FIN_WAIT_2,开始等待服务器的结束报文段[FIN_WAIT_2 -> TIME_WAIT]客户端收到服务器发来的结束报文段,进入TIME_WAIT,并发出LAST_ACK[TIME_WAIT -> CLOSED]客户端要等待一个2MSL(Max Segment Life,报文最大生存时间)的时间,才会进入CLOSED状态
理解TIME_WAIT状态
当我们在Linux上先启动一个server再启动一个client,之后Ctrl+C关掉server,马上再次运行server,这时会报一个错误:bind error:Address already in use
这是因为虽然server进程终止了,但是在TCP层的连接并没有马上断开,因此是不能再次监听同一个端口的。
TCP协议规定,主动关闭连接的一方要处于TIME_WAIT状态,等待2MSL (Max Segment Life)的时间后才能回到CLOSE状态- 我们使用
Ctrl+C终止了server进程,所以server是主动关闭连接的一方,在TIME_WAIT期间仍然不能再次监听同样的server端口 MSL在RFC1122中规定为两分钟,但各个操作系统的实现不同,在Ubuntu上默认配置的值是60s- 查看该值:
cat /proc/sys/net/ipv4/tcp_fin_timeout
bash
wq@wq-VMware-Virtual-Platform:~/Desktop$ cat /proc/sys/net/ipv4/tcp_fin_timeout
60为什么TIME_WAIT的时间是2MSL?
MSL是TCP报文的最大生存时间,所以TIME_WAIT状态持续2MSL后,在两个传输方向上的所有尚未被接受的或者迟到的报文都会消失,否则服务器立刻重启,可能还会收到上一个进程迟到的数据,但是这个数据可能是错误的。同时也是在理论上保证最后一个报文可靠到达,也就是如果最后一个ACK丢了,那么服务器会再次发送一个FIN,这时虽然客户端的进程不在了,但是TCP连接还在,仍然可以重发送LAST_ACK
解决TIME_WAIT状态引起的bind失败的方法 (服务器上大量连接处于TIME_WAIT状态是什么原因?)
如果服务器需要处理非常大量的客户端的连接,每一个客户端的连接的生存时间很短,但是每秒都有大量的客户端发来连接请求。这时如果服务器主动关闭某些客户端不活跃的连接,那么就会产生大量处于
TIME_WAIT状态的连接。但是每一个连接都会占用一个五元组(源IP、源端口、目的IP、目的端口、协议),其中服务器的IP、端口和协议是固定的,如果新来的客户端连接的端口号和正在TIME_WAIT的连接占用的端口号重复了,那么就会出现问题在
server的TCP连接没有完全断开之前理论上是不允许重新监听的。我们可以使用setsockopt()设置socket描述符的选项SO_REUSEADDR为1,即表示允许创建端口号相同但IP地址不同的多个socket描述符(前提是这些IP地址均属于本机)
cint opt = 1; setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
理解CLOSE_WAIT状态
如果我们在服务器的代码里取消new_sock.Close();这个代码,但客户端关闭后,服务器向客户端发送ACK报文,表示我收到了你的关闭连接请求,但不会向客户端发送FIN报文,所以这时候服务器就处于CLOSE_WAIT状态,四次挥手没有完成
所以服务器上出现大量的
CLOSE_WAIT状态,就是因为服务器没有正确关闭socket,四次挥手没有正确完成,只是代码上的BUG,加上close即可,表示服务端也想关闭连接
滑动窗口
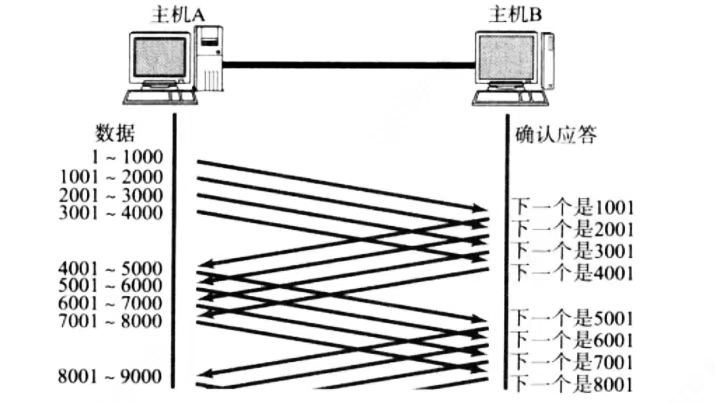
前面我们说过确认应答机制,一方对另一方发送的报文进行确认,即发送ACK报文,如果对每一条报文都进行ACK回应才能发送下一条报文的话,在通信时间上会有问题
那么我们可不可以一次性发送一个批量的数据,将这个批量的数据的等待时间重叠到一起呢?OK 这时候滑动窗口出场了
- 窗口大小就是无需等待确认应答而继续发送的最大数据量,下图的窗口大小就是
200 - 发送前
200字节的时候无需等待ACK直接法送 - 收到第一个
ACK后窗口向右(后)移动,继续发送下面的数据 - 操作系统为了维护这个窗口,需要开辟发送缓冲区来记录当前还有哪些数据没有应答,只有确认应答后的数据才能从缓冲区删掉
- 这个窗口越大,说明网络吞吐量就越高
如果出现丢包,如何解决
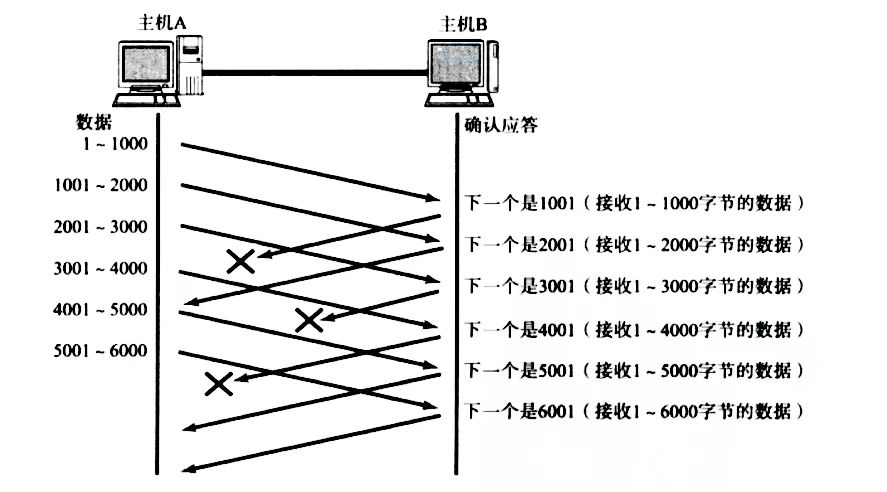
情况一:数据包已经抵达,但ACK丢了
部分ACK丢了不会影响,因为确认应答的机制是:此前所有序号的数据已成功接收 。可以通过后面的ACK确认
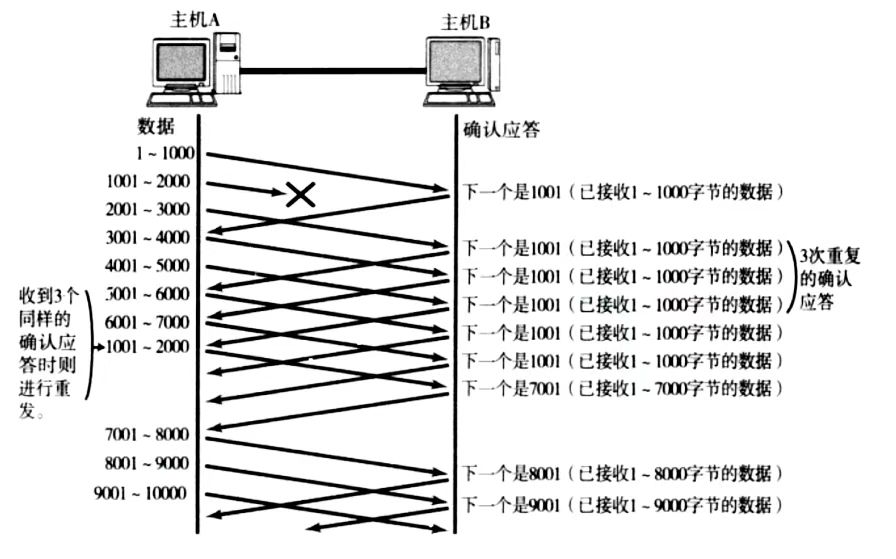
情况二:数据包直接丢了,对方根本没收到
- 当某一段报文丢失后,发送端会一直收到
1001这样的ACK,就是表明1001前面的我都收到了,你应该从1001给我开始发 - 如果发送端连续三次收到同样的
1001这样的应答,就会将对应的数据1001 - 2000重新发送 - 如果这时候收到了
1001 - 2000,对这个报文返回的ACK的确认序号就是7001,表示7001前面的数据都已经收到了,放到了操作系统的接受缓冲区中
这种机制叫做高速重发控制,也叫做快重传
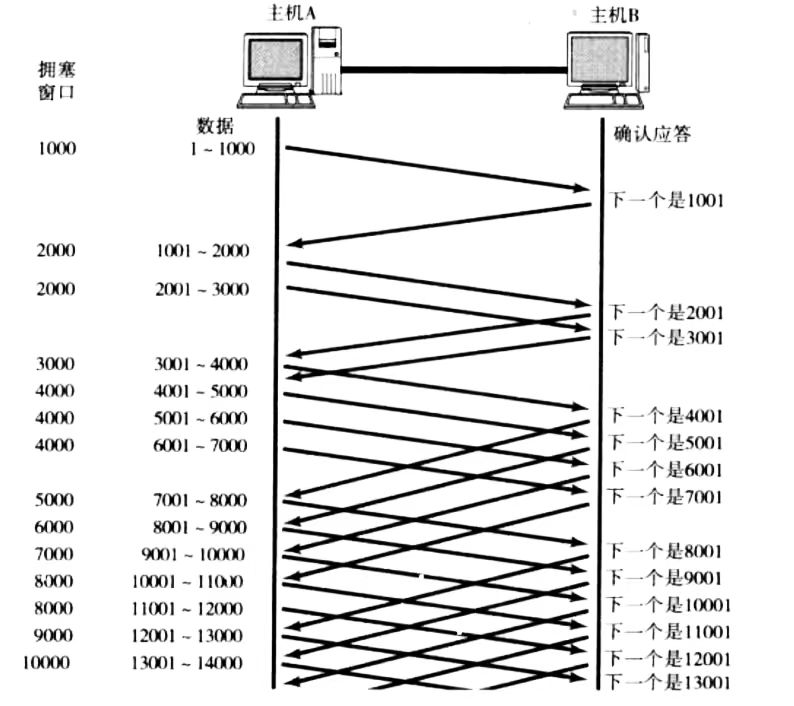
流量控制
接受端处理数据速度有限,不能让发送端一直发送,所以得想办法让发送端知道接收端的数据处理情况,也就是我可以接受多少的数据,那么"窗口大小"这个字段就是干这个的。
- 发送端根据接受端的接受能力发送数据,这个就叫流量控制机制
Flow Control - 每次接收端向发送端发送
ACK确认报文时,会在TCP首部窗口大小字段填上自己的接收缓冲区的剩余空间大小 - 窗口大小越大,说明网络吞吐量越高
- 接受端会根据自己的接受缓冲区大小实时调整发送的窗口大小字段
- 如果接受缓冲区满了,将窗口大小设置为
0,对放不再发送数据,但是还是会定期发送一个窗口探测数据段,促使接受端赶快把窗口大小告诉发送端
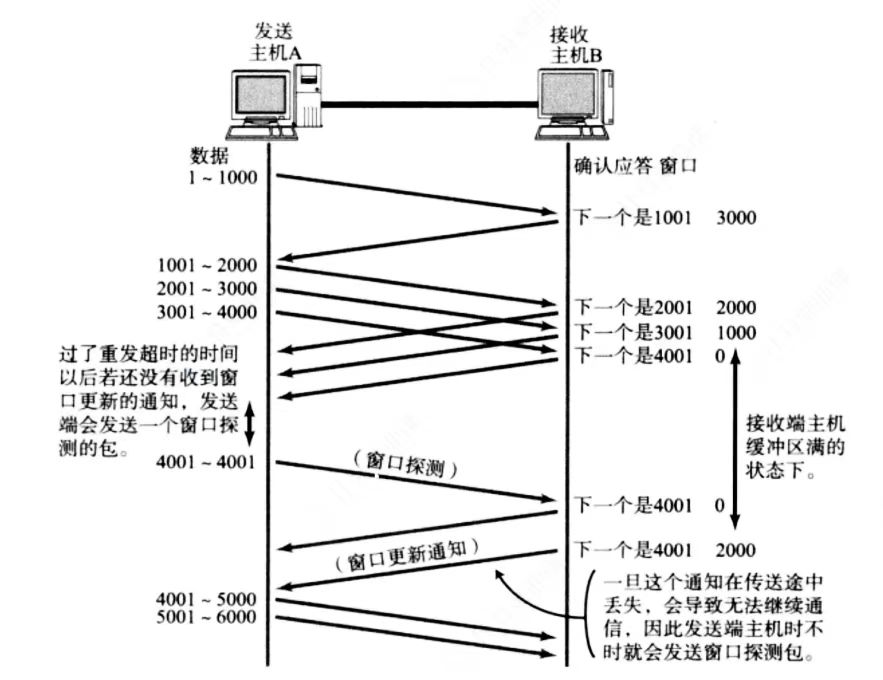
我们知道TCP首部中窗口大小字段是16位的,所以16位数组最大表示65535,所以TCP窗口最大就是65535字节?NO!``TCP首部40字节选项中包含了一个窗口扩大因子M,实际窗口大小为窗口字段左移M位
拥塞控制
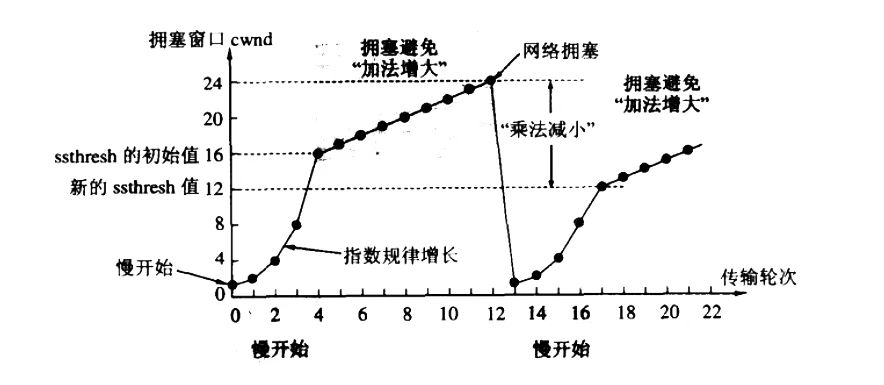
此外网络中有很多计算机,在网络通信一开始的时候我们需要先搞清楚当前的整个网络状况,所以TCP协议引入慢启动机制,先发送少量数据,搞清楚当前网路拥堵状态,慢慢加速,直到达到最大传输速度
慢启动
在TCP协议栈内存在一个拥塞窗口,发送开始时拥塞窗口为1MSS,每次收到一个ACK应答,拥塞窗口加1MSS,每一次发送数据包时,将拥塞窗口和接收端主机的窗口大小做比较,取较小值作为实际发送窗口
- 初始发送与 ACK 反馈假设初始 cwnd=1 MSS(即一次可发送 1 个报文段):
- 第 1 次发送:发送 1 个报文段(大小为 1 MSS)。
- 收到该报文段的 ACK 后,根据规则,cwnd 增加 1 MSS,变为cwnd=2 MSS。
- 第二轮发送与 ACK 累积此时 cwnd=2 MSS,意味着一次可发送 2 个报文段:
- 第 2 次发送:连续发送 2 个报文段(总大小 2 MSS)。
- 每个报文段被确认后,cwnd 分别增加 1 MSS:
- 收到第 1 个 ACK:cwnd 从 2→3 MSS;
- 收到第 2 个 ACK:cwnd 从 3→4 MSS。
- 因此,一轮发送(2 个报文段)结束后,cwnd 从 2 变为 4 MSS(翻倍)。
- 第三轮及后续
- cwnd=4 MSS 时,一次发送 4 个报文段,收到 4 个 ACK 后,cwnd 会从 4→8 MSS(每个 ACK 增加 1 MSS,4 次累积增加 4 MSS)。
- 以此类推,每经过一个 RTT(完成一轮发送和确认),cwnd 的大小就会翻倍。
拥塞避免
我们可以知道这个拥塞窗口的增长速度是指数级别的,慢启动是指启动时慢,但增长很快。
但是不能让它这么一直翻倍下去,在超过一个阈值后,为了避免发送数据过多造成网络拥堵,后面就是线性增长了(保守)。策略是:每收到一轮(即一个往返时间内)ACK后让拥塞窗口增加1MSS
拥塞发生后的调整
当检测到拥塞后(发生超时重传,3次重复ACK说明有数据丢包了)拥塞窗口会被重新设置为1,慢启动阈值会被设置为原来的一半,然后重新进入慢启动
拥塞控制就是TCP想尽快把数据传给对方,但又要避免给网络造成太大压力的一个折中方案
MSS(Maximum Segment Size,最大报文段长度)是 TCP 协议中定义的一个参数,用于指定 TCP 报文段(Segment)中应用层数据的最大长度(不包含 TCP 头部和 IP 头部)。它是 TCP 在建立连接时协商的关键参数,直接影响数据传输的效率。
下面的代码是高并发内存池项目中和拥塞窗口相似的代码:
C++
void *ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// 一次从中心缓存取多少空间 控制一个批量 小对象多给 大对象少给 慢启动 <类似拥塞窗口>
// 在每一个自由链表中维护一个 maxsize 每次取 maxsize 与 batch 中的小值 然后每一次++maxsize或者+=2
size_t batchNum = std::min(SizeClass::NumMoveSize(size), _FreeLists[index].MaxSize());
// 最开始不会向中心缓存要太多 如果需求大 maxsize 会不断增长 直到上限
if (_FreeLists[index].MaxSize() == batchNum)
_FreeLists[index].MaxSize() += 1;
// 获取单例 调用fetchrangeobj函数 但span里不一定有那么多 返回实际获取了多少
void *start = nullptr;
void *end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum > 0);
if (actualNum == 1)
{
assert(start == end); // start和end应该是相同的
return start;
}
else
{
// 插入当前线程的ThreadCache自由链表 并将第一个内存块返回
_FreeLists[index].pushRange(NextObj(start), end, actualNum - 1);
return start;
}
}延迟应答
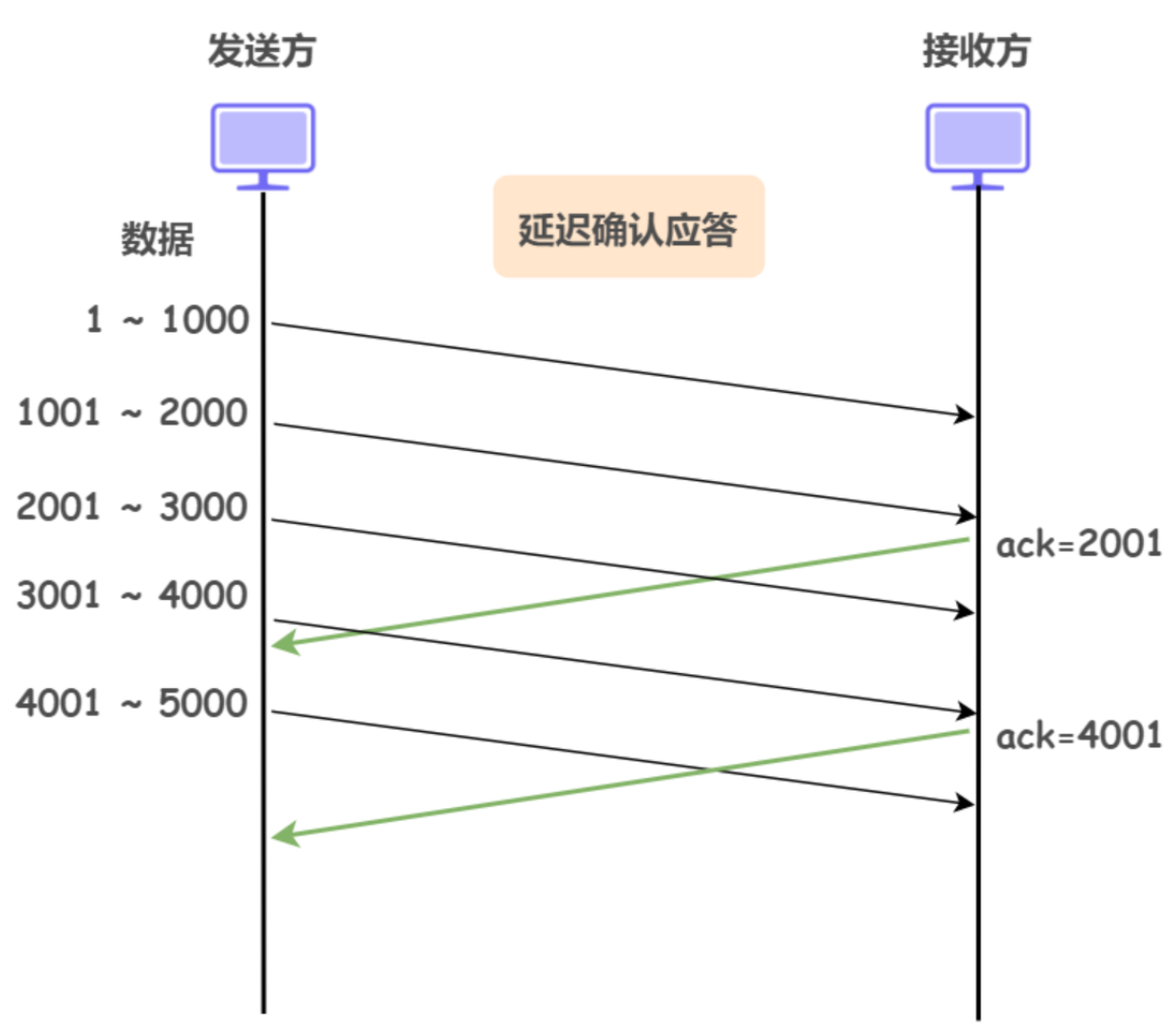
如果接受端接收到数据马上返回ACK应答的话,返回的窗口大小就会很小,如果我们等一会再发送ACK,刚刚发过来的数据我们已经处理完了,这时候发送过去的ACK携带的窗口大小就会变大一些
- 假设接收端缓冲区为
1M,这次收到了500K的数据,如果立即返回ACK窗口大小就是500K - 但是实际上接收端只需要
10ms就可以把这500K的数据处理完,所以就算把窗口扩大到1M接收端也能处理得过来 - 所以我们选择等一会(
200ms)再应答,这时候返回的窗口大小就是1M - 一般是每隔N(取2)个包应答一次,另外超过最大延迟时间(
200ms)应答一次(不同操作系统的设计方案不一样)
这样还可以减少ACK报文的数量,节省带宽,同时也减少整个网络中间设备的负载
捎带应答
其核心思想是:将ACK报文附加在要发送给对方的数据报文上,整合为一个报文,减少发送的总报文数量、网络流量和资源消耗
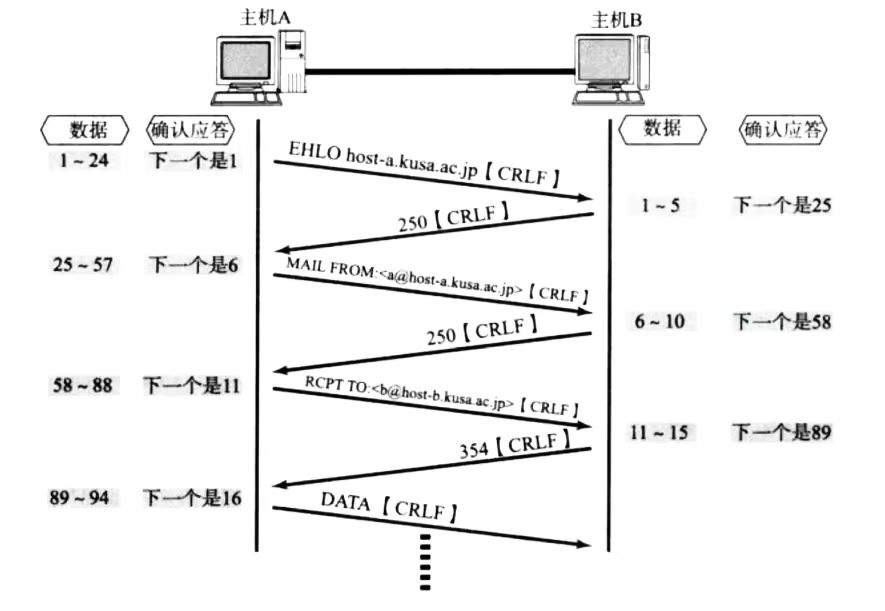
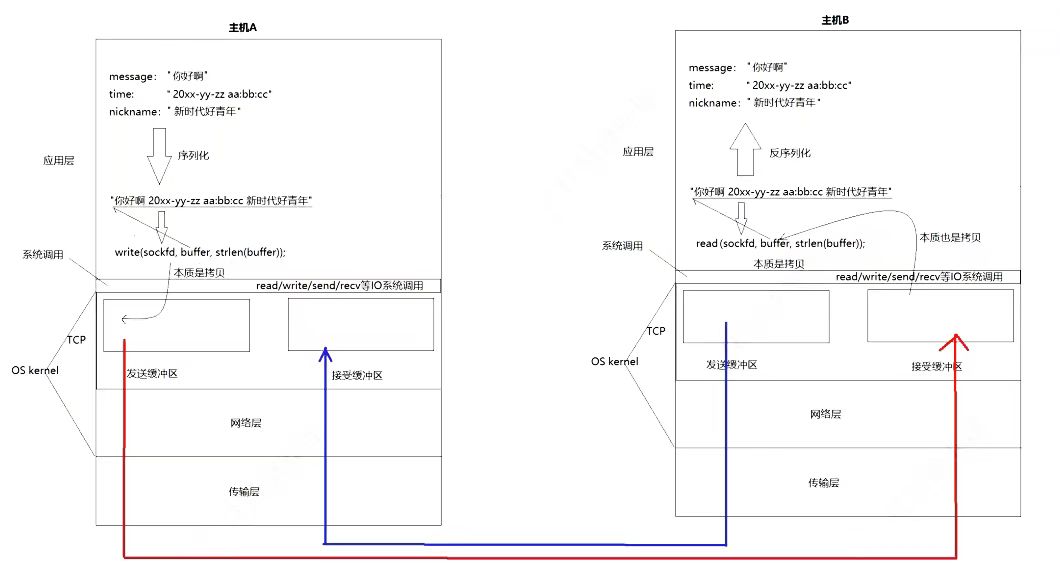
面向字节流
我们需要知道TCP不像UDP,TCP是有发送缓冲区和接收缓冲区的,当你调用wirte时,数据会先写入发送缓冲区,再由操作系统接管决定什么时候发。如果发送的字节数过长,会被拆成多个TCP包发出;如果发送的字节数过短,操作系统就会让数据在发送缓冲区等着,数据量够了再一起发出去。接受数据也是同理,先从网卡驱动搬到接收缓冲区,然后用read调用从接收缓冲区里面读取数据。此外一个TCP连接有发送接收缓冲区,既可以读也可以写,这个叫做全双工
因为有了缓冲区,TCP的读和写不需要一一匹配,写了100个字节的数据,可以调用一个read读取一百个字节,也可以调用10个read一次读取10个字节
粘包问题
面向字节流随之而来的一个问题就是粘包(应用层的数据包)问题,在传输层的角度TCP报文一个一个的排着队,存在缓冲区中,但在应用层的角度,看到的就是一串连续的数据,分不清每一个数据报文的边界。
如何明确两个包之间的边界?
- 对于定长的包,确保每次读取固定大小的字节
- 对于变长的包,可以在包的头部约定一个包总长度的字段,也就知道了包到哪里结束(这个长度字段说在报文的正文数据部分的,不是在报头)
- 此外还可以在包和包之间使用明确的分隔符(如
\r\n)也就是应用层协议了,可以由程序员自己定,并确保分隔符不与正文冲突
UDP有粘包问题吗?
没有
根本原因是UDP是面向数据报:UDP调用sendto是直接将数据封装为一个报文立即发送,没有TCP那样的合并小数据包的算法;UDP调用recvfrom每次也只会读取一个数据包,如果没有读取,数据包会在缓冲区排队(UDP是有接收缓冲区的),并且UDP的报头里面是有一个字段叫做:报文长度 ;TCP只有序号、确认号
异常情况
- 进程终止:会释放文件描述符,但仍然可以发送FIN,和正常关闭没区别
- 机器重启:重启之前会关闭所有进程,和进程终止一样
- 机器掉电 / 拔网线:当前机器无法发送报文,但对端会认为连接还在。如果对端有数据发送,会因为始终无法接收到
ACK确认,会触发超时重传,超市重传达到系统阈值(15次)后认为连接不可用,关闭连接,并返回错误ETIMEDOUT;如果对端无数据发送,空闲连接,TCP有保活机制 (默认是关闭的需手动通过socket选项开启),系统会定期(2小时)发送一个探测报文,如果连续多次发送探测报文未收到回应,判定连接失效,关闭连接
实际开发中的应对策略
-
开启
TCP保活机制:针对长连接场景,通过setsockopt配置Keepalive参数(缩短探测间隔和重试次数),快速检测无效连接,减少资源占用。cpp// C++开启TCP保活示例 int keepalive = 1; setsockopt(sockfd, SOL_SOCKET, SO_KEEPALIVE, &keepalive, sizeof(keepalive)); // 配置探测间隔(如30秒)、重试次数(如3次)等参数(系统相关) -
应用层心跳机制 :在
TCP之上设计自定义心跳协议(如定期发送小数据包),比TCP保活更灵活,可快速感知对端异常,主动关闭连接并重启重连。 -
幂等性设计:因掉电可能导致数据传输中断(如已发送但未确认的数据),应用层需保证数据处理的幂等性,避免重复处理或数据丢失。
-
资源释放兜底:服务器端需限制单个连接的超时时间,定期清理长时间未活动的连接,防止因大量半开连接耗尽端口和内存资源。
基于TCP的应用层协议
一、核心基础协议
| 协议名称 | 核心用途 | 关键特性 |
|---|---|---|
| HTTP/HTTPS | 万维网数据传输(网页、接口请求) | HTTPS 基于 TLS 加密,HTTP/1.1 支持长连接,HTTP/2 支持多路复用,均依赖 TCP 的可靠性确保报文完整传输 |
| FTP | 文件上传 / 下载 | 采用双连接模型(控制连接 + 数据连接),通过 TCP 保证大文件传输的完整性 |
| SMTP/POP3/IMAP | 电子邮件传输(发送 / 接收) | SMTP 负责发送,POP3/IMAP 负责接收,依赖 TCP 确保邮件内容无丢失 |
| SSH | 远程服务器登录与命令执行 | 加密传输,通过 TCP 保障指令和数据的可靠交互(如服务器管理、Git 操作) |
| Telnet | 远程终端访问(明文,已逐步被 SSH 替代) | 基于 TCP 实现字符流的可靠传输,因安全性问题仅用于测试场景 |
二、分布式与服务通信协议
| 协议名称 | 核心用途 | 技术要点 |
|---|---|---|
| HTTP/2 gRPC | 跨语言 RPC 通信 | 基于 HTTP/2 帧结构,使用 Protocol Buffers 序列化,依赖 TCP 实现高可靠的服务间调用 |
| JDBC/ODBC | 数据库连接(如 MySQL、PostgreSQL) | 通过 TCP 与数据库服务器建立持久连接,确保 SQL 指令和查询结果的可靠传输 |
| Redis(TCP 模式) | 内存数据库的客户端 - 服务器通信 | 虽支持 UDP,但默认使用 TCP,保证键值对操作的原子性和数据一致性 |
| MQTT(TCP 模式) | 物联网设备通信 | 轻量级发布 / 订阅协议,基于 TCP 实现低带宽场景下的可靠消息传输 |
三、文件与媒体传输协议
| 协议名称 | 核心用途 | 适用场景 |
|---|---|---|
| SFTP | 安全文件传输(SSH File Transfer Protocol) | 基于 SSH 协议,通过 TCP 提供加密的文件传输,替代 FTP 的明文缺陷 |
| FTPS | FTP 的 SSL/TLS 加密版本 | 保留 FTP 的双连接模型,通过 TCP+TLS 实现安全的大文件传输 |
| RTSP(TCP 控制通道) | 实时流媒体控制(如视频监控) | 控制通道(播放 / 暂停指令)基于 TCP,数据通道可选用 UDP,但控制指令需可靠传输 |
四、其他常用协议
| 协议名称 | 核心用途 | 备注 |
|---|---|---|
| DNS(TCP 模式) | 域名解析(大报文场景) | 默认使用 UDP,但当响应报文超过 MTU(如 1500 字节)时,自动切换为 TCP 确保完整传输 |
| NFS | 网络文件系统 | 客户端挂载远程文件系统时,通过 TCP 保障文件读写操作的可靠性 |
| LDAP | 轻量级目录访问协议 | 用于用户身份认证、目录服务查询,依赖 TCP 确保目录数据的准确传输 |
UDP和TCP的发送缓冲区
| 特性 | UDP 发送缓冲区 | TCP 发送缓冲区 |
|---|---|---|
| 核心作用 | 暂存待发送数据报,快速转发给网络层 | 暂存待发送字节流,配合流量控制、拥塞控制调整发送节奏 |
| 数据处理方式 | 不合并、不延迟,按数据报独立转发 | 可能合并小数据(Nagle 算法),按需分段(MSS 限制) |
| 可靠性关联 | 与可靠性无关,发送后不保留数据 | 需保留已发送但未确认的数据,用于超时重传 |
| 阻塞机制 | 非阻塞模式下溢出直接失败;阻塞模式下可能短暂阻塞 | 常因流量控制(窗口为 0)或拥塞控制长期阻塞 |
| 对比维度 | TCP 接收缓冲区 | UDP 接收缓冲区 |
|---|---|---|
| 存储单位 | 连续字节流(按序列号重组,确保有序的字节序列) | 独立数据报(按到达顺序存储,不保证发送顺序) |
| 核心作用 | 1. 暂存接收的字节流,按序列号重组排序2. 通过滑动窗口告知发送方可接收的字节数(流量控制) | 1. 暂存接收的数据报,等待应用层读取2. 保留数据报边界,确保应用层一次读取一个完整数据报 |
| 数据处理逻辑 | - 自动重组乱序数据,确保字节流连续- 丢弃重复数据(通过序列号判断) | - 不重组数据,按到达顺序存储- 不处理重复数据(需应用层自行判断) |
| 溢出处理 | 接收窗口满时,通知发送方暂停发送(滑动窗口机制) | 缓冲区满时,直接丢弃新到达的数据报(无通知机制) |
| 与可靠性的关联 | 强关联:通过缓冲区管理确保有序、无重复的数据交付 | 无关联:仅暂存数据,不保证数据完整或有序交付 |
| 典型配置参数 | SO_RCVBUF(接收缓冲区大小) | SO_RCVBUF(接收缓冲区大小) |
| C++ 操作函数 | setsockopt/getsockopt(设置 / 获取缓冲区大小) | setsockopt/getsockopt(设置 / 获取缓冲区大小) |
基于UDP实现可靠传输(基于UDP实现TCP)
需在应用层模拟 TCP 的可靠性设计,核心机制包括:
- 序号与确认(Seq/Ack):为每个数据包分配唯一序号,接收方收到后返回确认报文(携带期望接收的下一个序号),发送方通过确认判断数据是否送达。
- 超时重传:发送方发送数据后启动定时器,若超时未收到确认,则重传该数据包(超时时间可采用自适应算法调整)。
- 乱序重排:接收方维护接收缓冲区,按序号重组乱序到达的数据包,确保按顺序交付给应用层。
- 流量控制:接收方通过确认报文告知发送方自身缓冲区剩余容量,避免发送方发送过快导致数据溢出。
- 拥塞控制:可选机制,通过检测网络丢包情况调整发送速率(如慢启动、拥塞避免),避免网络拥塞。
- 重传去重:接收方对已确认的序号进行记录,忽略重复到达的数据包。