显卡会被运用到不同的场景,比如3D游戏、图像渲染、深度学习、AI大模型等,显卡的产品参数也在各种场景做了优化,比如有渲染核心、光追核心、AI加速等,所以显卡的性能天梯图也需要基于不同应用场景去看。
在实际场景中,特别是深度学习和AI方面的应用,各种显卡的性能表现到底如何,或者如何更有效地从深度学习等应用场景测试显卡的性能?
这里我们选择了英伟达的RTX 3090和RTX 4090两张显卡,基于实际的深度学习中训练的场景进行性能实测,来比较下被称为「上一代卡皇」的 3090 和「当前消费级主力」的 4090 的实际性能到底差多少。
RTX 3090和RTX 4090参数对比
先对比先3090和4090两张显卡的参数规格:
| RTX 3090 | RTX 4090 | |
|---|---|---|
| 架构 | Ampere | Ada Lovelace |
| CUDA核心数 | 10,496 | 16,384 |
| 显存容量 | 24 GB GDDR6X | 24 GB GDDR6X |
| 显存带宽 | 936 GB/s | 1,008 GB/s |
| TDP功耗 | 350W | 450W |
| FP32 算力 | 35.6 TFLOPS | 82.6 TFLOPS |
| Tensor FP16 算力 | 142 TFLOPS | 330 TFLOPS |
- 3090和4090在显存层面比较接近,显存容量都是24GB,显存带宽差异也不大
- 算力方面,4090无论是单精度还是Tensor FP16都是3090的2.3倍左右
- 其他方面,4090基于新的Ada Lovelace架构,并且功耗也远高于3090
基于深度学习的模型训练测试
这里选择ResNet-50进行模型训练来实测显卡性能,为什么是ResNet-50?
ResNet-50是经典的计算机视觉模型,一种深度为50 层的卷积神经网络(CNN);模型比较平衡,参数数量及显存占用适中,涵盖了深度学习训练的关键计算模式,包含大量矩阵计算,可以评估AI核心的算力。
我们基于Pytorch框架来训练ResNet-50模型,基于CIFAR-10数据集进行测试,来比较样本吞吐速度、显卡使用、GPU使用率等。
从节省成本和使用便利性考虑,可以直接从GPU算力平台租用GPU算力,我们在 晨涧云 分别租3090和4090两种机器进行模型训练的对比测试:
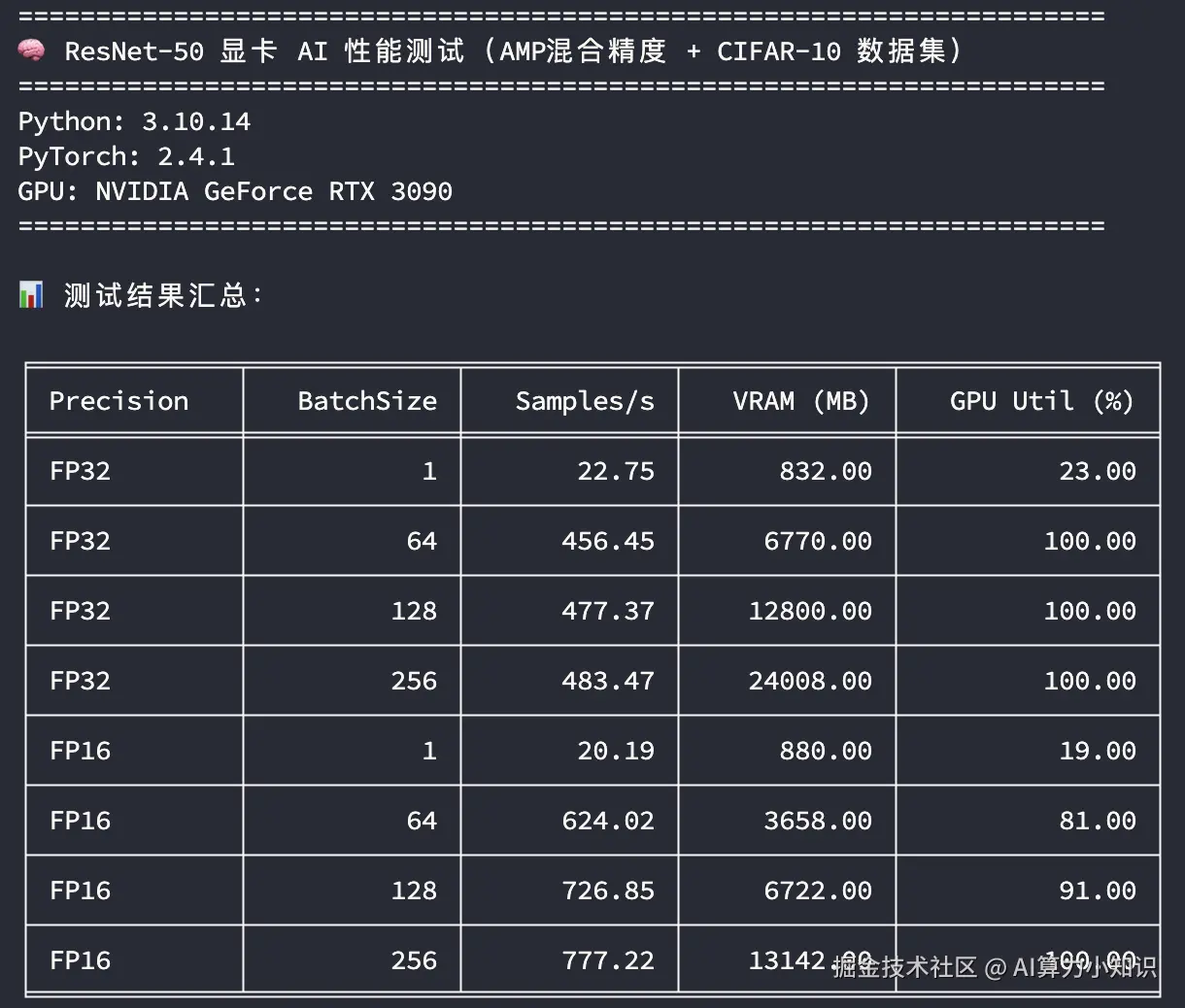
RTX 3090
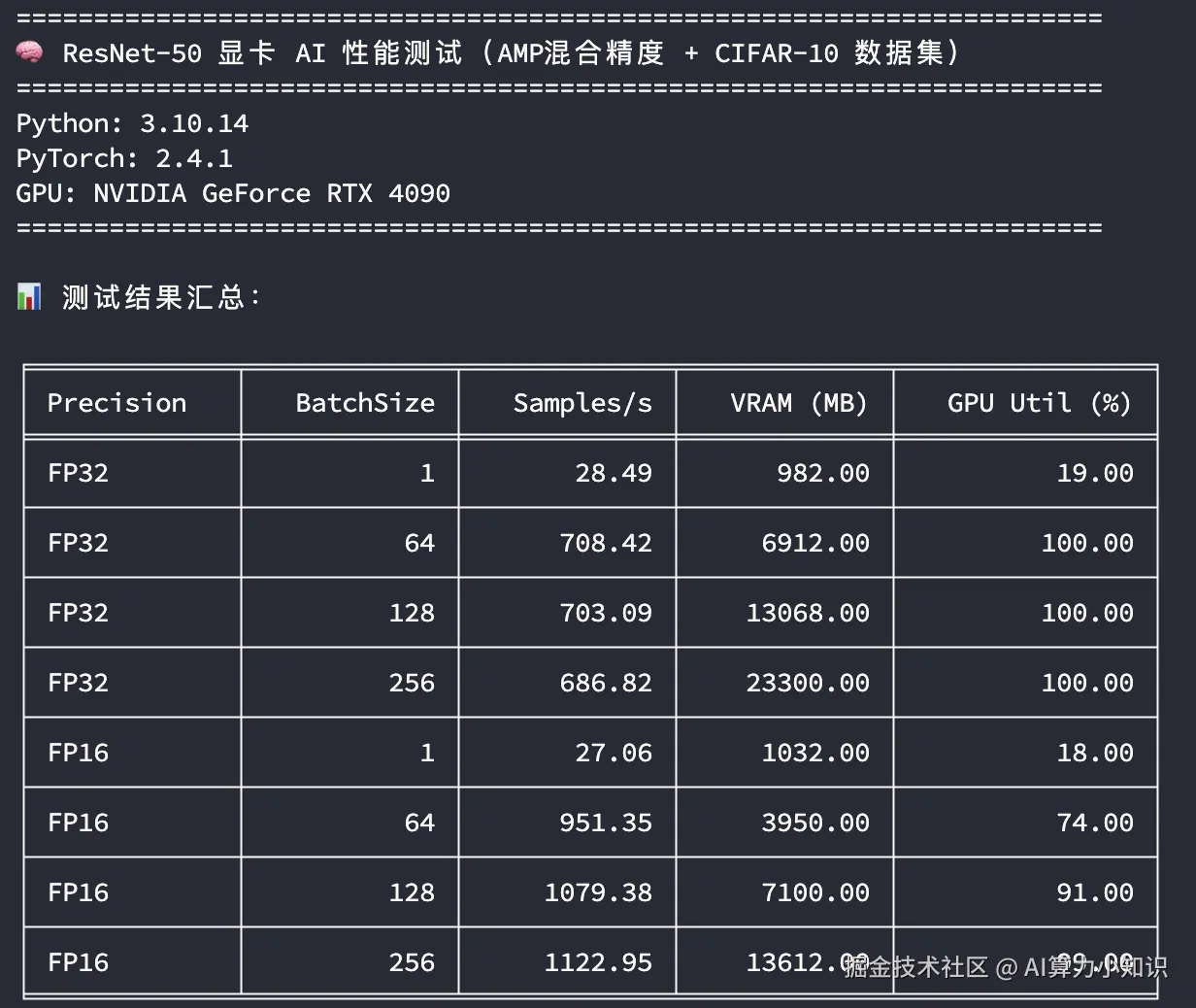
RTX 4090
测试结果解释
这里从不同的训练精度,不同的训练批次大小来比较3090和4090训练吞吐量的差异,同时关注显存和GPU的峰值使用情况:
- 精度 :FP32 表示使用单精度训练,FP16 表示使用混合精度训练
- BatchSize:训练批次大小
- Samples/s:每秒样本吞吐量
- VRAM (MB) :峰值显存使用量
- GPU Util (%) :峰值GPU利用率
从上图中主要看在GPU使用率比较高的场景下(如 BatchSize=256),模型训练样本的吞吐速度比较;无论是单精度还是混合精度,RTX 4090的样本吞吐速度都在RTX 3090的1.45倍左右。
这个结果跟显卡本身的算力(TFLOPS)值存在一定的差异,当然训练还跟其他环境配置直接相关,比如机器的CPU、显卡PCIe接口的版本等,而且这个只能说明在计算机视觉模型的训练场景的性能表现,在其他应用场景,如大模型推理、文生图、科学计算等性能基准又会有不同表现,需要分开测试评估。