RAG解决什么问题
大模型知识的局限性。
RAG是什么:
RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。
简易流程
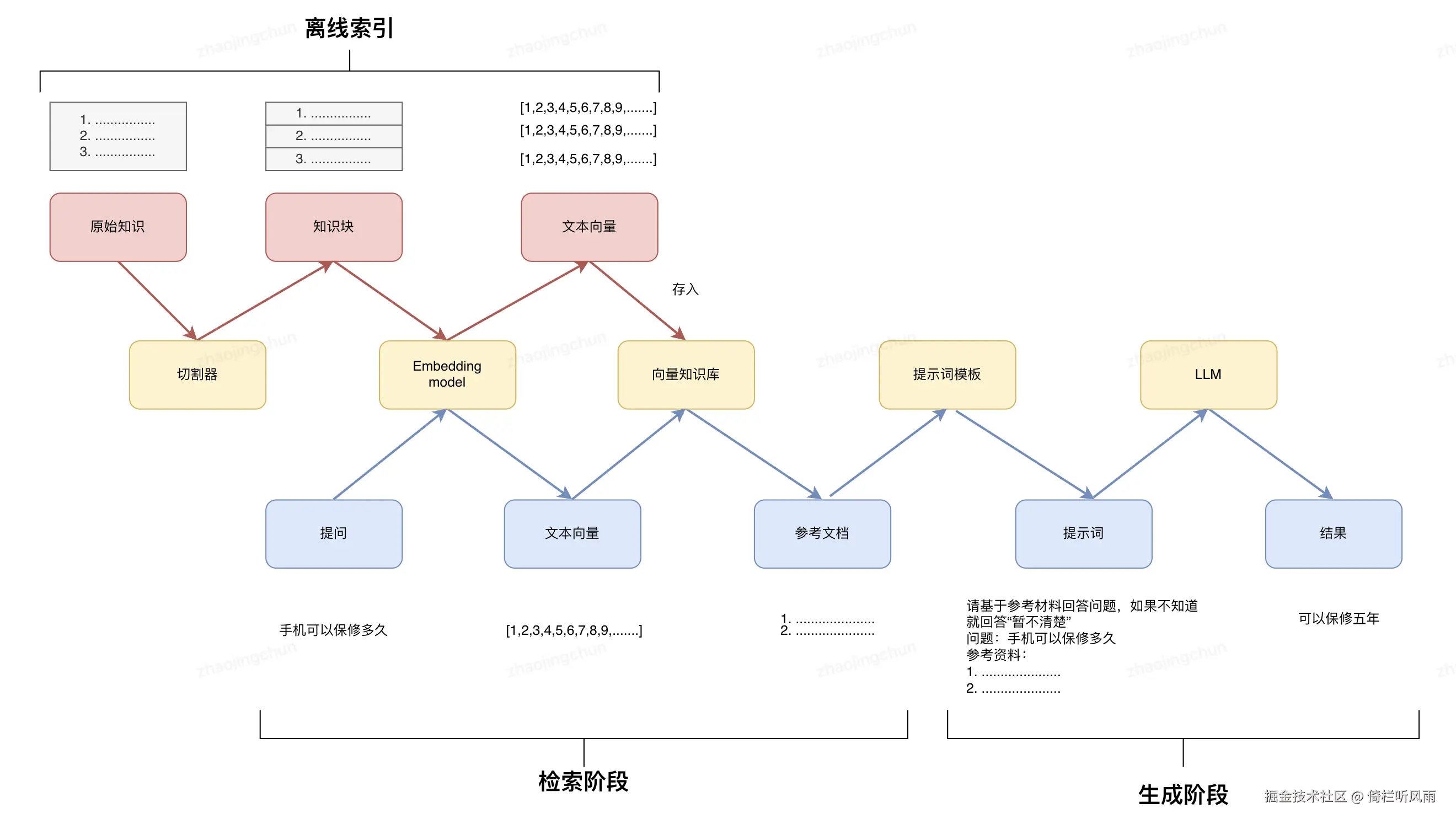
索引: 搭建一个知识库,支撑后面的文档索引 核心:怎么切割知识,怎么选择合适的模型
检索: 找到合适的参考文档 ,核心:检索方式选择
生成: 整合提问和参考文档输入大模型,得到答案 核心:提示词构建 和大模型选择
切割器的奥义:
文档切分:核心语义连贯性
- 应尽量保证划分后的同一段文本里面,语义是统一、完成的
- 太长语义不统一,影响检索效果
- 太短语义不完成,影响回答质量
切分方法:

最好的问题答案对 ,知识归
检索奥义技巧
检索用:小文本块 ,生成时:大文本块
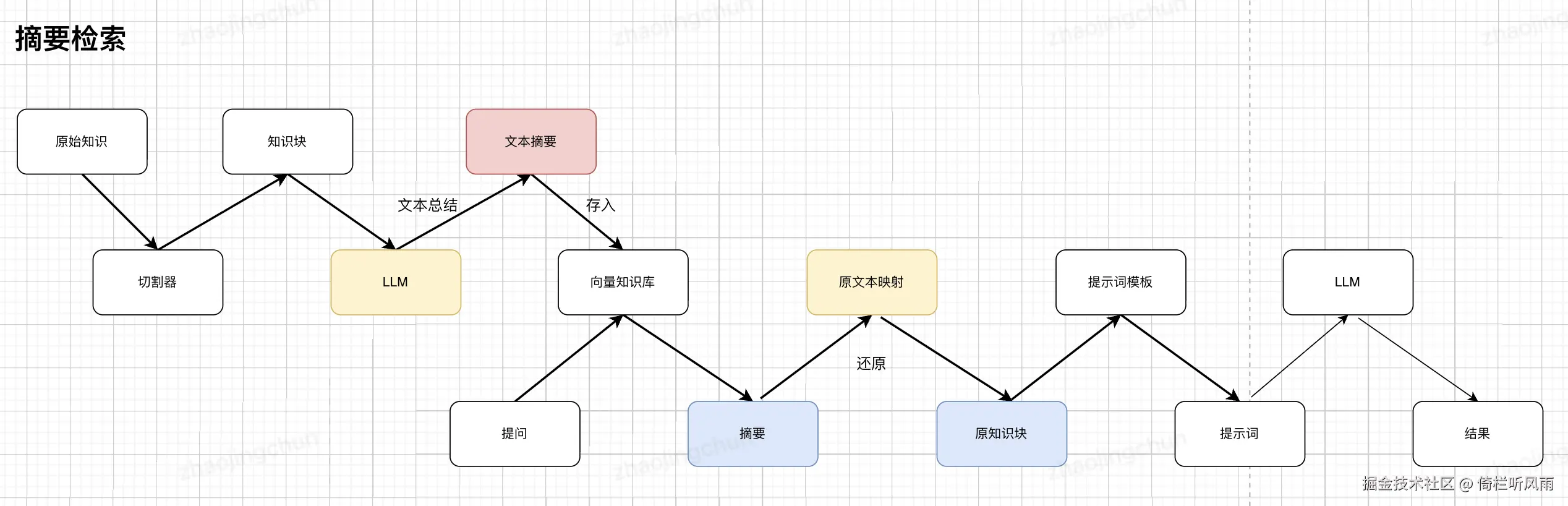
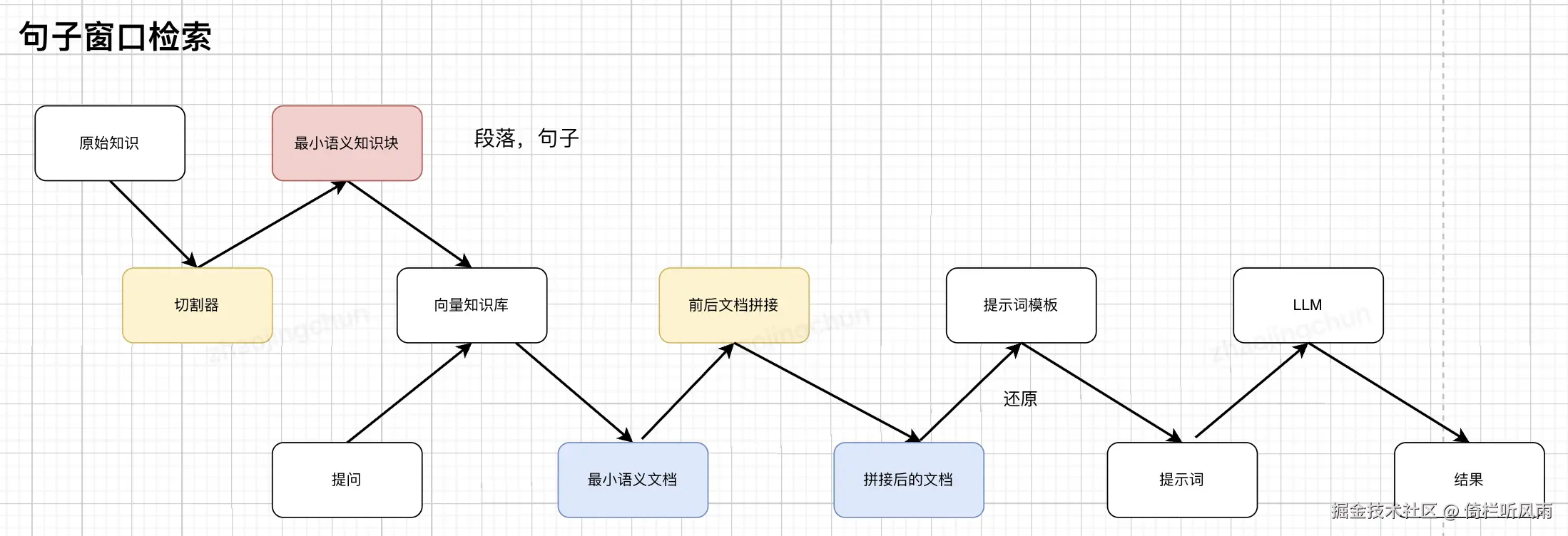 语义检索 和关键字检索关系
语义检索 和关键字检索关系
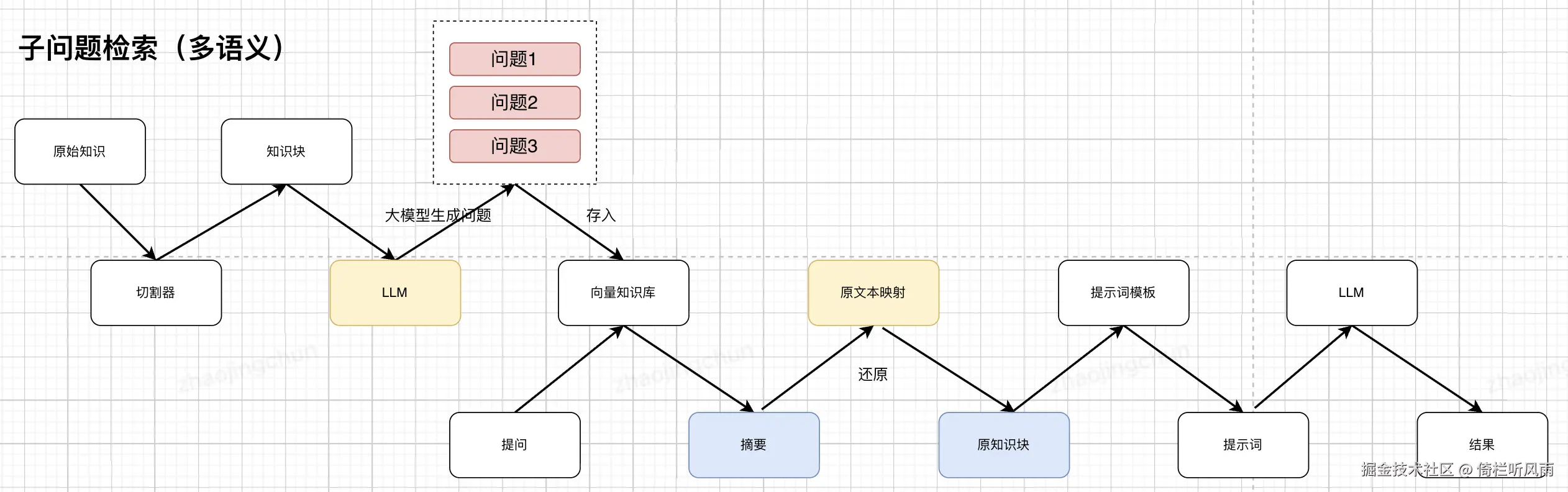
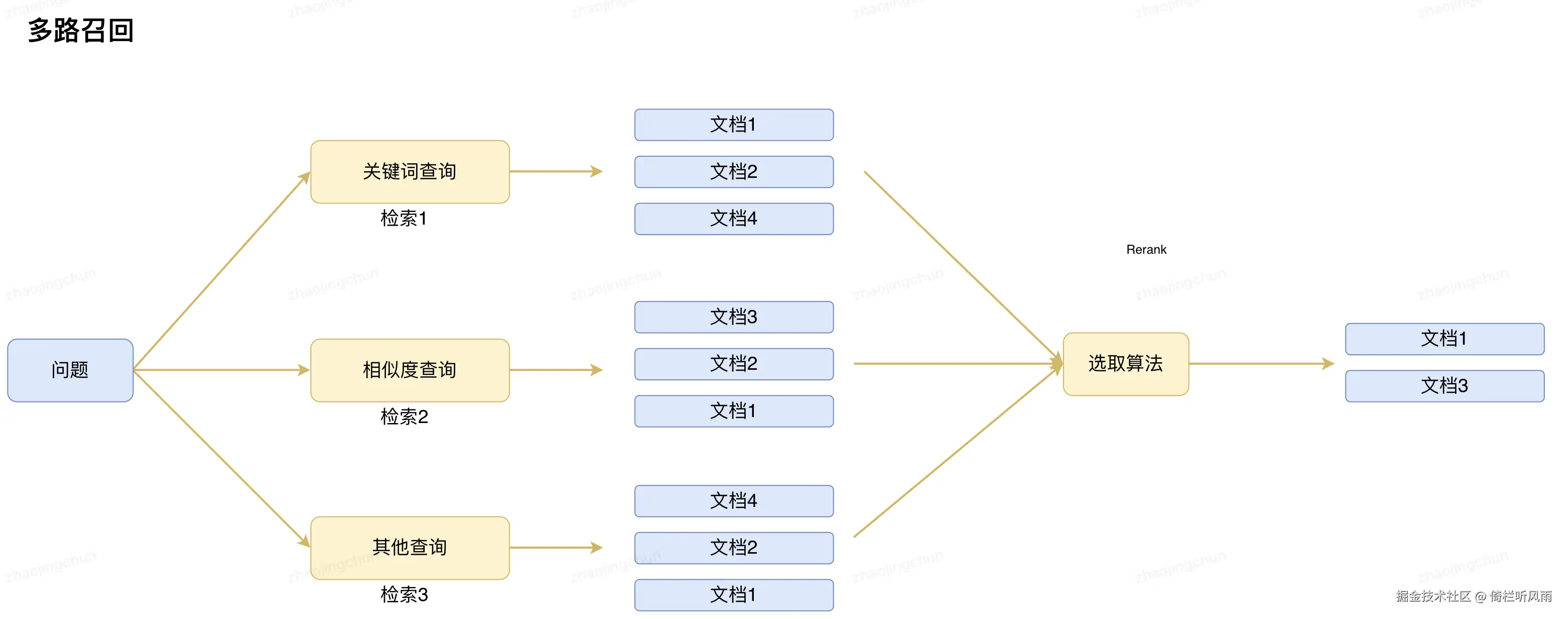
多路召回
提问的奥义
提问改写 :
- 提问不规范 ,语义模糊,歧义 语句不通顺
- 多轮对话
用户:三国里战力最高的是谁
RAG系统:是吕布
用户:他是哪一年出生的?
- 复杂提问
拆解成多个问题,分别提问RAG,然后组合成最终答案
生成奥义优化:
如何很好的利用参考文档
1、简单粗暴 ,都丢给 大模型
- 上下文溢出 (直接切除)
葫芦娃救爷爷
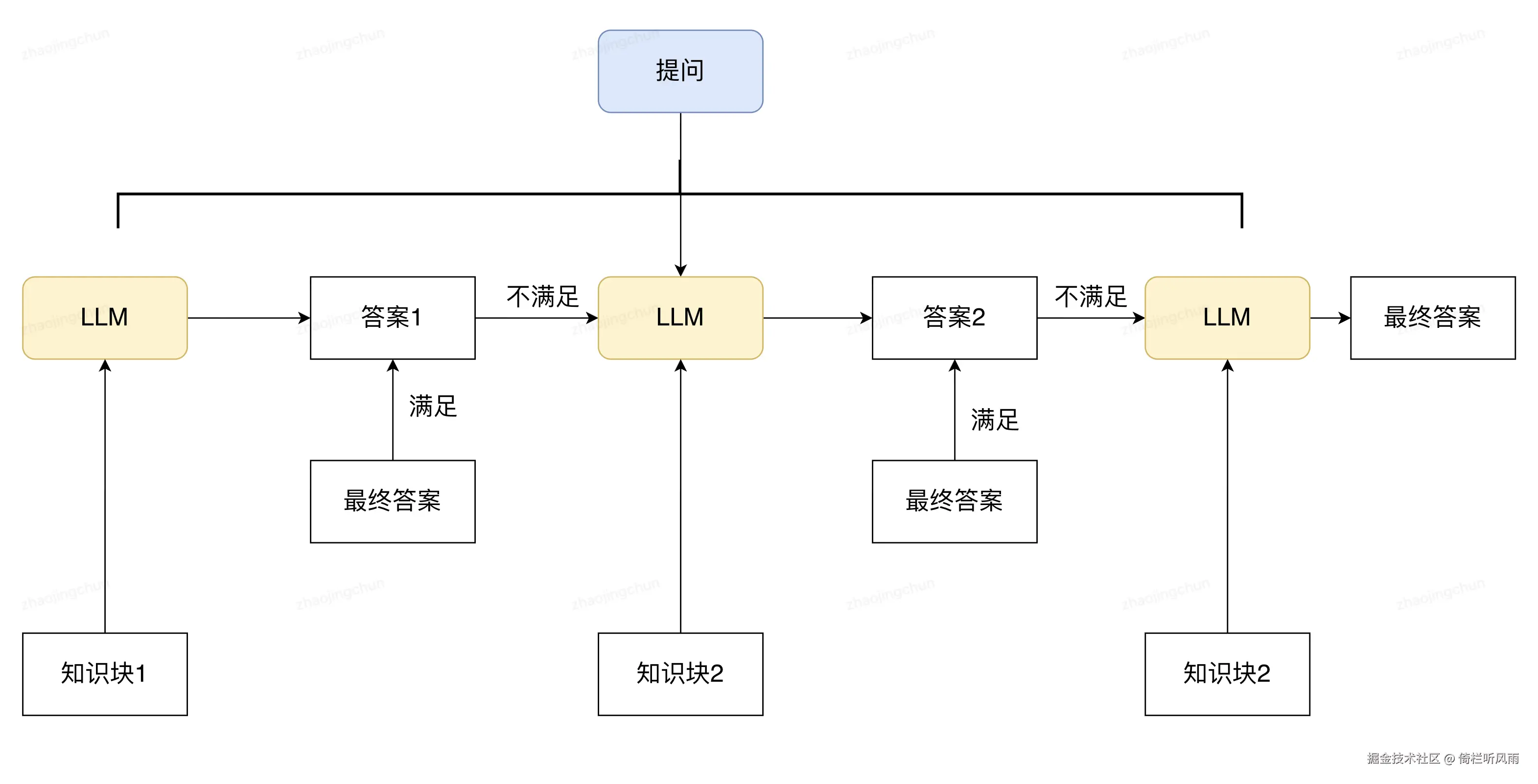
文档块的葫芦娃救爷爷
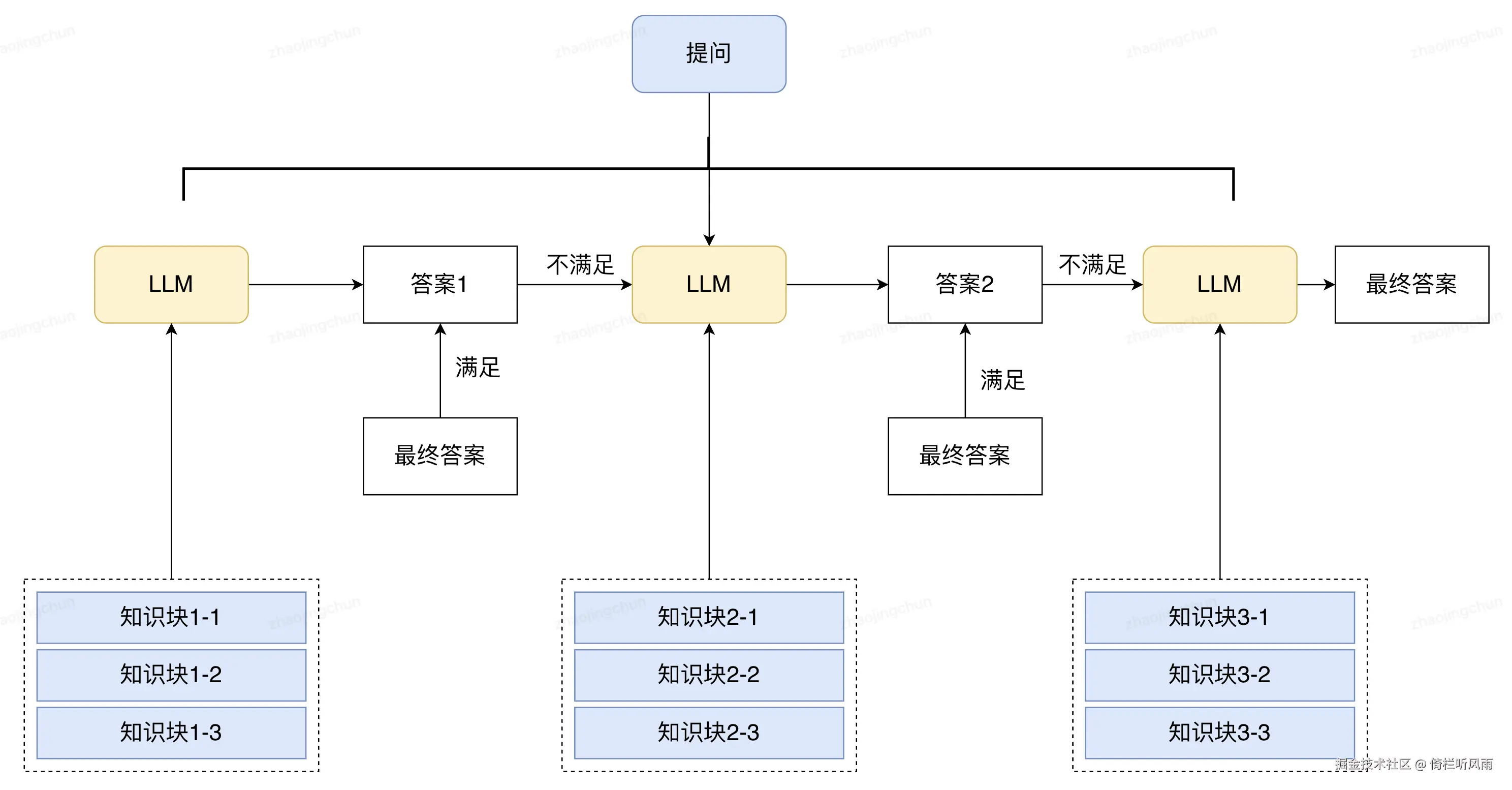
总结树模式
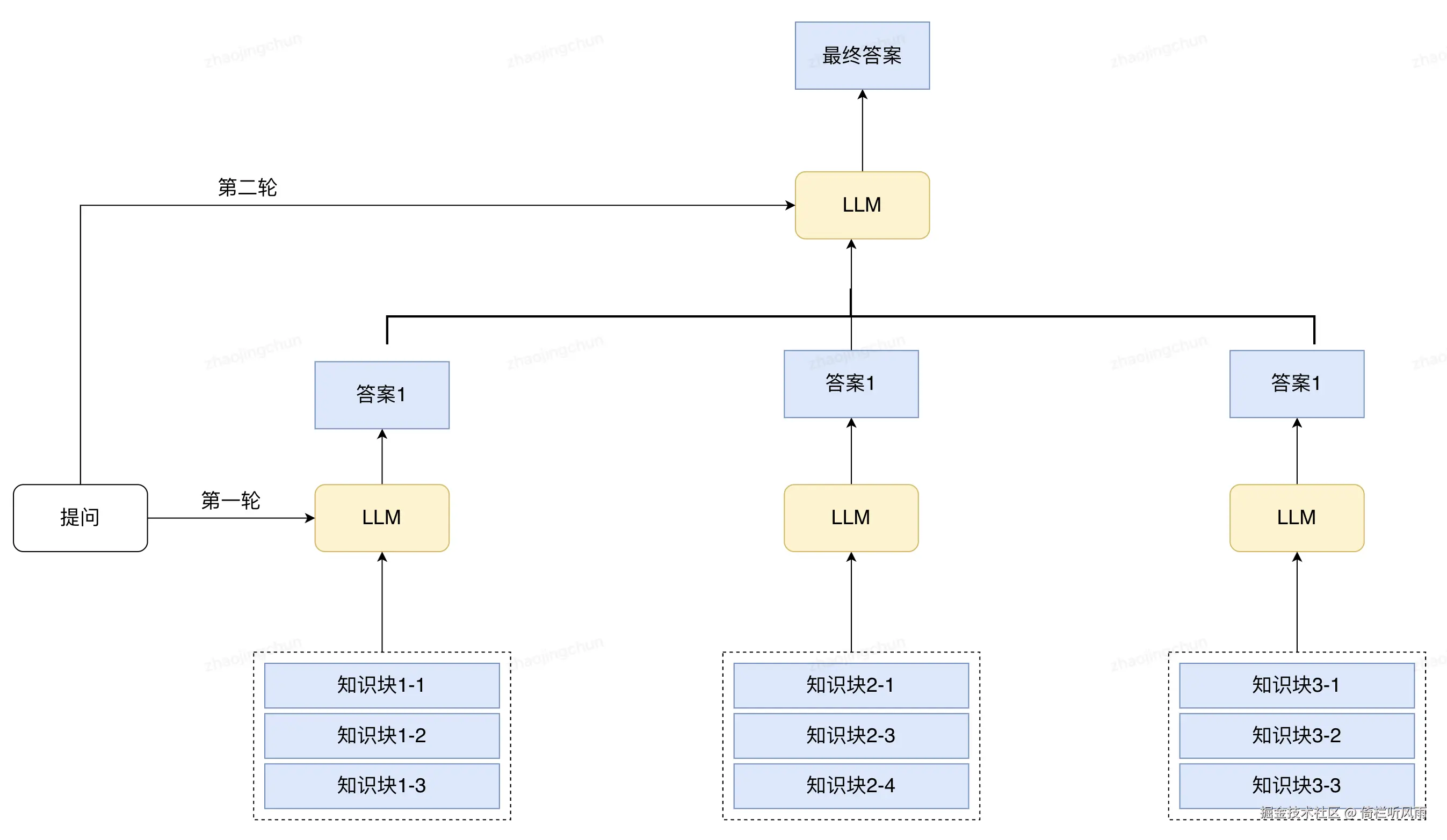
合理利用元数据
- 元数据 保鲜 。 我问房价多少 ,你说 2000年房价
- 检索中评估相关性:重要的文档给与更高的权重 ,专家权重。
- 检索后的排重复
- 提供参考链接 增加可信度
评估:
准确率 : 用户视角 ,答案是否符合预期
忠诚度:生成的内容是否忠实于提供的上下文或背景信息
召回率,精确率 ,F1:评估找的资料质量
评估手段:
- 人工
- 自动化
JAPI的文档检索
知识库建立:对JAPI文档做摘要总结 入口
问题优化:问题改写拓展
文档检索:采用多路召回的方式 关键字+向量数据库检索
结果返回:文档去重后 ,大模型算相似度排序 + 总结回答
稠密向量 ,稀疏向量
余弦相似度 语义识别好
欧氏距离 具体+关键词