前端出了问题,但总是"查无此人"
之前在一家体量不算大的公司,我们团队负责维护一个面向 C 端用户的 SaaS 系统 。
产品双周迭代,每次上线后,我们也会定期从客服那边收集用户的反馈。
但很快,我们就遇到一个反复出现、却又怎么也搞不定的"无语问题"。
有客户反馈说:页面点不动了,卡死了。
还有的说:点按钮没反应,像是前端死机了。
甚至有的说:页面直接报错,看不见内容。
于是我们第一时间去翻后端接口日志,结果却显示一切正常,没有报错、没有异常,连一个 500 都没有。
这时候锅自然就甩给了前端。
但前端同学也很无语:
- 用户只说"打不开",但没有截图、没有步骤,连系统版本都不清楚;
- 再加上这类问题是个例居多,重现概率几乎为零;
- 我们能做的,只剩下"老三样":让用户清缓存、刷新页面、重新登录......
但没办法,大多数时候,这些操作也解决不了问题。
所以就变成了前端同学每天加班查代码、调兼容性、测不同浏览器,
问题有没有解决不知道,但人是越来越累了。
终于,前端同学提了建议:
"要不我们接个前端监控吧?
比如现在很流行的Sentry,能自动上报 JS 报错的那种,定位也方便很多。"
大家一听,也确实觉得挺不错的。
但现实很快泼了冷水......
前端想接监控,运维说"没必要"
虽然sentry有云系统,但是由于项目涉及一些私有化部署和用户数据,安全层面考虑,我们必须 自建 Sentry 服务。
但当前端去找运维申请服务器时,运维那边的反馈是这样的:
"公司不是已经有监控系统了吗?
用的是专门给后端接入的那套,也不是 Sentry,
前端那点问题都是个别用户的,没必要再单独整一套吧?"
再加上自建 Sentry 的门槛也不低,
至少得有一台 4 核 8G 的独立服务器 ,部署起来还得专人维护。
对我们这样的小团队来说,单纯为了前端监控去上这么大资源,确实没必要呀。
更何况前端监控也不像后端那样要"每天盯着看",很多时候就是偶尔排查用一下,
这样专门搭一整套服务常驻着,确实有点浪费资源。
所以这个提议,第一次就被驳回了。
前端同学一听,也是很无奈。
但问题依旧在那:
用户报错没头绪,前端无法复现定位全靠猜。
每次出问题复现不了就让做向下兼容......
甚至要远程帮客户操作------这效率也太低了叭。
后来前端负责人出面找运维进行了友好的交流 ,互相问候了一下,突出了前端监控的重要性和必要性。 最终这件事才得以推进,Sentry 的前端私有化监控系统正式落地。
从后端写前端,才真正理解"监控到底有多重要"
那前端到底有没有必要接入监控系统呢?
我一直是做后端的,对 Sentry 并不陌生,
接口报错、服务异常,基本都有监控能第一时间看出来。
那时候我对"前端要不要接监控"这事,其实也没啥感觉。
总觉得前端不就是报个错、页面卡一下,只要不影响数据就刷新好了。
直到后来我开始写前端,特别是做面向 C 端用户的系统之后......
这才体会到什么叫做"靠猜解决问题"。
总是有一些无语用户 拿着已经淘汰的机型 浏览器来给我提bug。
关键我还总是复现不了......
而且偏偏这些问题,总爱挑在下班时间冒出来,
刚放松一点,就又得重新打开代码,翻 log、翻源码、翻历史版本,
越查越烦躁。
也是在这种时候我我才体会到做后端的美好 有监控是真提莫好啊。
Sentry 介绍
Sentry 是一个用来监控应用错误的系统,简单来说,它能在我们代码出问题的时候第一时间记录下详细的异常信息。
Sentry主要能做哪些事
最重要的是它能帮我们做这三件事:错误上报、性能监控、自定义埋点。
第一,错误上报。这是我们最需要的功能。当前端页面报错时,比如用户打开页面出现白屏、控制台有 JS 异常、按钮点击崩溃等,Sentry 能自动把这些错误采集上来,并记录报错信息、文件名、报错堆栈、用户的操作路径、操作系统、浏览器版本等信息。更重要的是,如果我们配置了 sourcemap,还能还原成报错的源代码位置,方便我们来精准定位 bug。
第二,性能监控。Sentry 也能采集页面的关键性能指标(比如首屏加载时间、路由切换耗时、资源加载耗时等),帮助我们了解页面是否存在性能瓶颈。特别是对于 C 端项目来说,前端性能有时候影响的不只是用户体验,甚至可能直接导致功能失败。
第三,自定义埋点。除了系统自动采集的错误或性能数据,我们当然也可以手动埋点上报一些业务相关的异常,比如用户下单失败、登录异常、接口超时等场景。通过自定义事件上报,我们就可以把监控系统和我们的业务场景更紧密地结合起来,提升排查问题的效率。
Sentry部署方式
Sentry 的部署方式主要有两种:
第一种是 SaaS 模式 ,也就是使用官方提供的托管服务sentry.io 。这个最方便,注册账号后就可以用,不用自己部署服务器。不过它有免费额度限制,比如每天只支持最多5000 个事件(event),超了就得升级套餐,适合用来做功能验证或者小量使用。
第二种是 私有化部署,就是我们自己搭建一套 Sentry 服务,所有的数据都存在自己服务器里,安全性更高,也没有事件数的限制。但相应地,就需要占用自己的服务器资源,官方推荐至少 4 核心 8G 内存起步,还要配置 Redis、PostgreSQL、Cron 等配套组件,整体部署成本相对较高。
如果团队对数据隐私比较敏感,或者希望做更深入的自定义,那就适合选私有化部署;但如果只是前期简单接入体验功能,直接用 SaaS 模式就足够了哈。
接入 Sentry
我们以一个 Vue3 项目为例,来讲讲前端怎么接入 Sentry。
如果用的是其他前端框架,比如 React、Angular、小程序,或者是后端语言(Java、Python、Go 等),也都可以参考官方文档(docs.sentry.io)找到对应接入方式,这里就不展开讲了。
我们接下来的内容,以 Vue3 + Vite 项目为例,演示如何接入 Sentry,包括 SDK 配置、SourceMap 上传、前端错误定位等完整流程。
本次我们以 Sentry 官网的免费版本为例进行演示。
第一步 注册账号并设置语言
首先,访问 sentry.io 注册账号。注册完成后,点击页面左下角头像,进入 User Settings。
在这个页面里,可以根据自己习惯调整一些基础设置,比如语言、时区、界面主题(深色 / 浅色模式)等。设置好之后,后续在查看错误信息时会更清晰,也方便排查问题。
第二步 创建项目
基础信息设置好之后,我们就可以开始创建项目了。
点击左上角的头像,选择「项目」,进入项目管理页。点击「创建项目」后,会进入如下界面:

- 在平台选择里,选择
VUE; - 设置告警频率(默认即可,后面也可以再改);
- 填写项目名称、分配到对应团队,最后点击「创建项目」即可。
这一步完成后,Sentry 会为我们生成一份接入代码,包含 DSN 地址、初始化方式等内容,稍后我们会用到。
第三步 接入 Sentry 到 Vue3 项目中
我们现在已经创建好项目,接下来就是把 Sentry 接入到 Vue 应用了。
1. 安装依赖
我们以 pnpm 为例(也可以用 npm 或 yarn):
json
pnpm add @sentry/vue2. 新建 sentry.ts 文件 在 src 目录下新建一个 sentry.ts 文件,用于统一初始化配置:
javascript
// src/sentry.ts
import * as Sentry from "@sentry/vue";
import type { App } from "vue";
export function setupSentry(app: App) {
Sentry.init({
app,
// Sentry 项目的 DSN 地址(在项目创建页可以看到)
dsn: import.meta.env.VITE_SENTRY_DSN,
// 当前环境(如 dev、test、prod)
environment: import.meta.env.MODE || 'development',
// 版本号信息,用于错误定位时区分版本差异,使用统一注入的版本号
release: __RELEASE__,
// 是否开启调试(开发阶段建议为 true,线上建议关闭)
debug: true,
// 性能监控采样率(建议开发阶段设为 1.0)
tracesSampleRate: 1.0,
});
}3. 在入口文件中初始化 在 main.ts(或 main.js)中引入并调用 setupSentry:
javascript
// main.js
import { createApp } from 'vue'
import './style.css'
import App from './App.vue'
import { setupSentry } from './sentry'
const app = createApp(App)
// 初始化 Sentry
setupSentry(app)
app.mount('#app')通过上面代码可以看到我们没有直接在代码里写死 DSN 和环境,而是通过 import.meta.env 从 .env 配置中读取,原因主要有两个:
- 方便按环境区分配置 :不同的部署环境(开发、测试、生产)通常用不同的 DSN、不同的环境名,通过
.env.development、.env.production文件分别设置,就不用每次改代码。 - 提升安全性与灵活性:DSN 属于敏感信息,不建议直接写死在源码中。通过环境变量注入,只在打包阶段读一次,既安全又灵活,也符合前端项目的最佳实践。
这样配置完之后,Sentry 就已经接入成功了。只要页面上有 JS 报错,Sentry 就会自动帮我们捕获并上报。
为了确认是否真的生效,我们可以先写个小 demo 来验证一下。比如在某个页面或者组件里故意抛个错误,看看能不能在 Sentry 后台看到报错信息。
第三步:写个小 demo 测试一下
Sentry 配置好了,当然要测试一下它到底有没有生效。
我们可以随便找一个组件,比如首页的 Home.vue,在 onMounted 里手动抛个错:
javascript
<script setup lang="ts">
import { onMounted } from 'vue';
onMounted(() => {
// 故意抛出一个错误,测试 Sentry 是否能捕获
throw new Error('这是一个用于测试 Sentry 的前端错误');
});
</script>页面一加载,就会抛出错误。刷新页面后,稍等几秒,我们就可以在 Sentry 控制台看到这条报错了(如果设置了中文,会显示为"未处理的异常"等字样)。
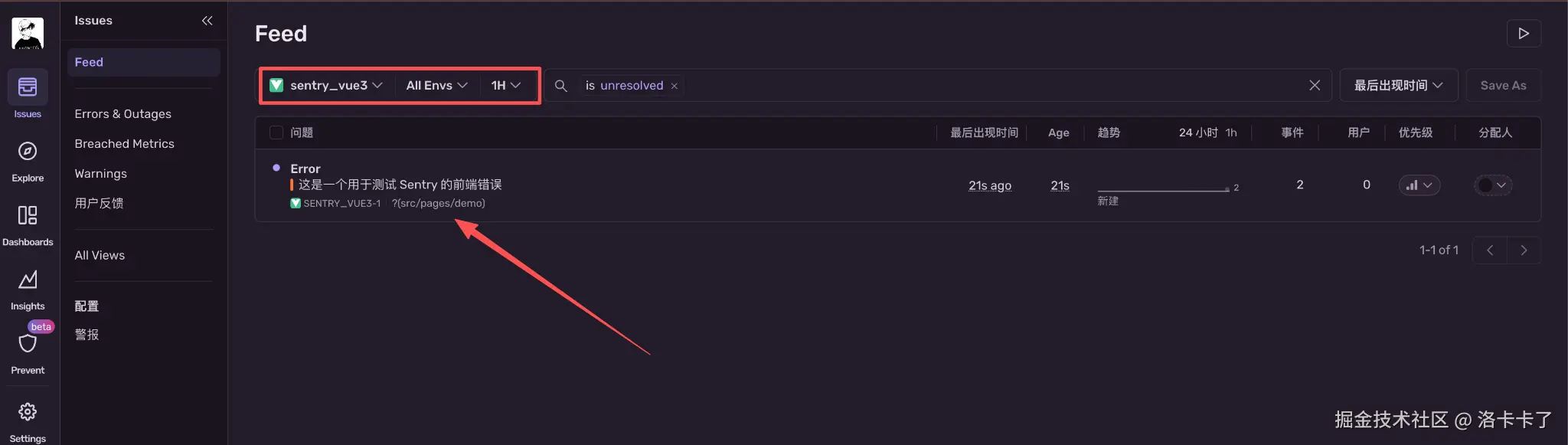
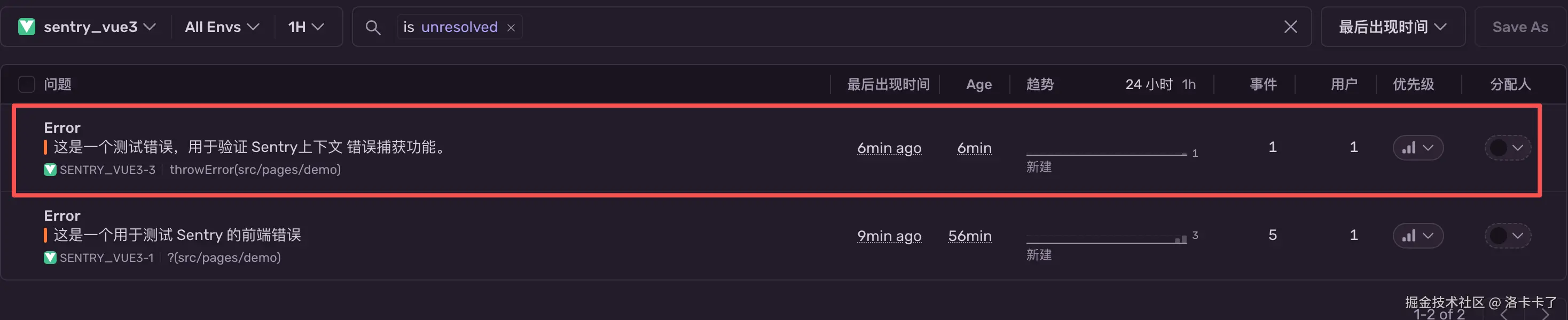
在 Sentry 控制台的 Issues 页面中,我们能看到刚刚上报的错误项:
页面左上方可以选择项目(如 sentry_vue3),中间能看到报错的标题和出现时间。
我们点击进去可以查看详细的错误信息。
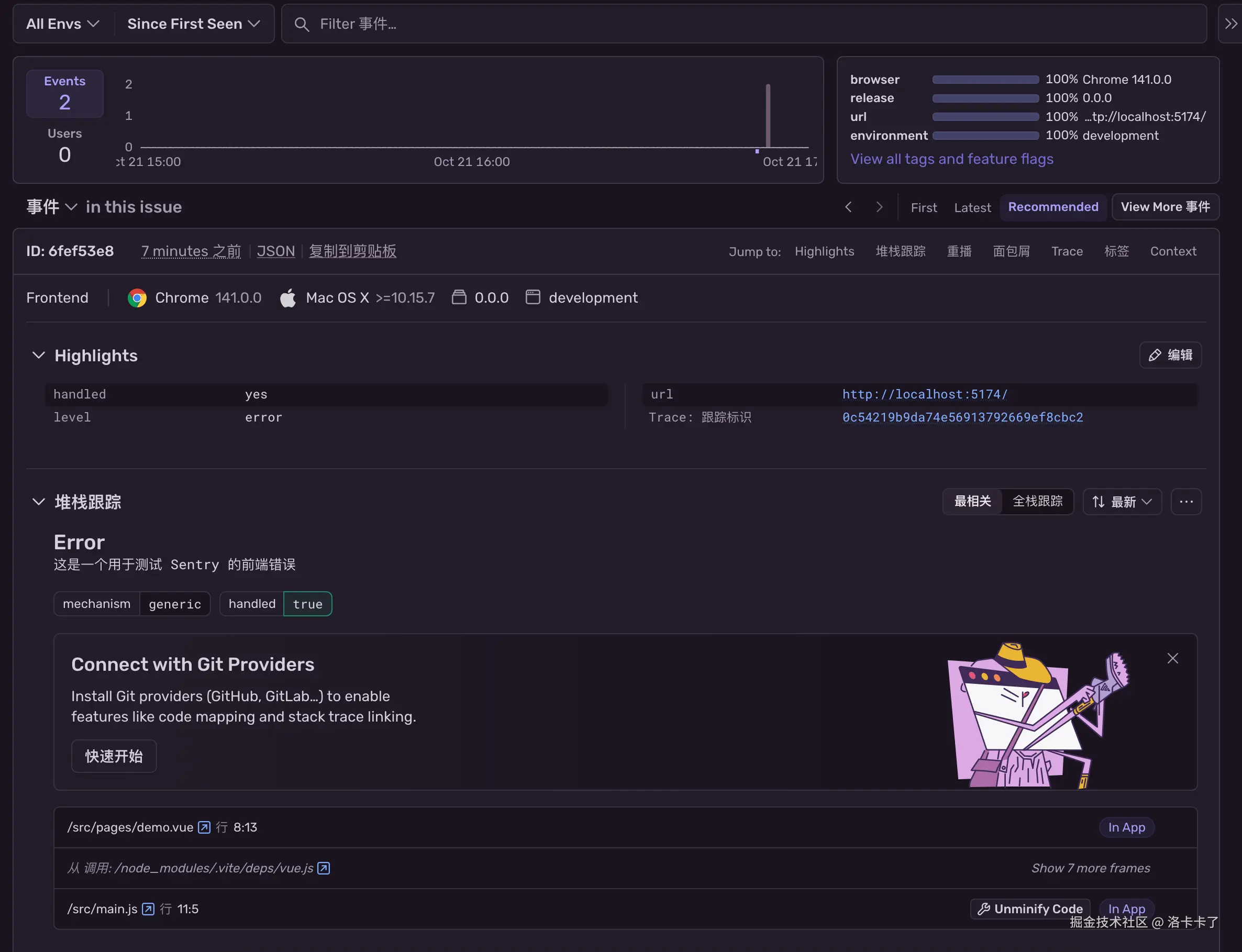
进入错误详情页后,可以看到这次异常的基本信息,例如:
- 错误类型:Error
- 报错内容:这是一个用于测试 Sentry 的前端错误
- 出错文件:src/pages/demo.vue 第 8 行
- 浏览器、系统、设备等信息
- 跟踪堆栈:包括错误抛出的具体位置及调用路径
往下滚动还能看到更多上下文信息,包括:
- 请求信息:错误发生在哪个页面(比如 localhost:5174)
- 标签信息:操作系统、浏览器、环境(我们配置的 environment 字段会显示在这里)
- 设备信息:品牌型号、地理位置、User-Agent 等
- 版本信息:我们在初始化时传入的 release 字段也会出现在这里
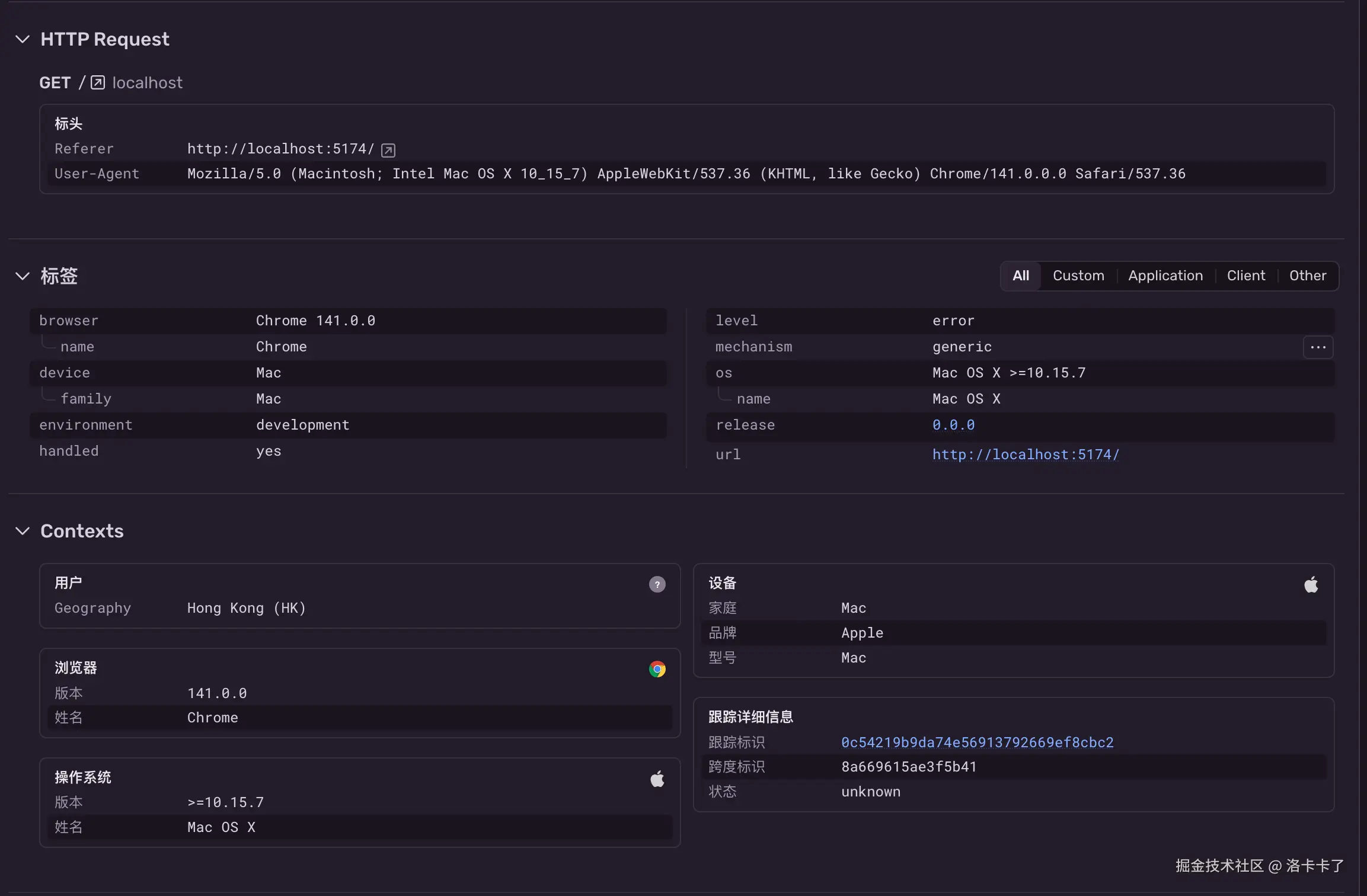
整体来看,Sentry 会自动帮我们收集并整理这次错误的上下文环境,非常方便用于问题定位,尤其是线上问题,哪怕用户无法复现,我们也能第一时间拿到关键信息。
增强 Sentry 错误捕获能力:三类常见未被默认捕获的场景补全
在前面我们已经完成了 Sentry 的接入,并通过一个简单的报错验证了它的基础功能可以正常工作。但在真实项目中,仅靠默认配置并不能捕获所有类型的前端异常。有些报错是不会自动被 Sentry 感知和上报的,如果我们不手动处理,就很容易漏掉关键错误,影响排查效率。
接下来,我们补充三种最常见的"漏网之鱼"场景,并提供对应的解决方案,让 Sentry 的异常捕获能力更完整。
场景一:Vue 组件内部报错,Sentry 没收到
常见例子:
javascript
// setup() 中写错了变量名
const a = b.c; // b 根本不存在为什么会漏掉?
这类错误发生在 Vue 组件内部(尤其是 <script setup> 语法中),有时不会触发 Sentry 的全局监听机制。Vue 会自己处理这些错误,但如果我们没有配置 app.config.errorHandler,Sentry 是无法感知的。
解决方法:
javascript
app.config.errorHandler = (err, vm, info) => {
console.error("[Vue Error]", err, info);
Sentry.captureException(err);
};这段代码放在我们的 sentry.ts 中 Sentry.init(...) 之后即可。它能确保组件中发生的报错也能正常被上报。
场景二:Promise 异常没有 catch,被悄悄吞掉
常见例子:
javascript
// 忘了写 catch
fetch('/api/data').then(res => res.json());或者:
javascript
Promise.reject("请求失败了");为什么会漏掉?
这些异步异常不会触发 window.onerror,也不会被 Vue 捕获。它们属于 Promise 的"未处理拒绝(unhandledrejection)",需要手动监听。
解决方法:
javascript
window.addEventListener("unhandledrejection", (event) => {
console.error("[Unhandled Promise Rejection]", event.reason);
Sentry.captureException(event.reason);
});加上这个监听后,任何未 catch 的 Promise 错误都会被补上报。
场景三:JS 同步错误没有被捕捉
常见例子:
javascript
// 直接抛出异常
throw new Error("代码报错了");
// 访问不存在的变量
console.log(notDefinedVar);为什么会漏掉?
这种运行期错误虽然在控制台会有报错,但默认并不会进入 Vue 的错误处理流程,也不会触发 Sentry 的内部机制。
解决方法:
javascript
window.addEventListener("error", (event) => {
console.error("[Global Error]", event.error || event.message);
Sentry.captureException(event.error || event.message);
});通过这个监听,我们就可以捕获诸如 throw new Error(...)、运行时访问空对象、空方法等同步错误。
最终效果:
把这三类监听逻辑补充进 sentry.ts,放在初始化之后,我们就可实现一个更完整、更稳定的前端异常捕获系统:
javascript
// src/sentry.ts
import * as Sentry from "@sentry/vue";
import type { App } from "vue";
export function setupSentry(app: App) {
Sentry.init({
// Vue 应用实例,用于自动捕获 Vue 组件错误(必须传)
app,
// Sentry 项目 DSN 地址,用于上报事件
dsn: import.meta.env.VITE_SENTRY_DSN,
// 当前运行环境(用于在 Sentry 中区分 dev / test / prod)
environment: import.meta.env.MODE || 'development',
// 版本号信息,用于错误定位时区分版本差异
release: __RELEASE__,
// 开启调试模式,开发阶段建议开启,生产建议关闭
debug: true,
// 性能采样率,建议开发阶段为 1.0,生产为 0.1 或更低
tracesSampleRate: 1.0,
});
/**
* Vue 组件级错误捕获(setup() / template 中的报错)
*/
app.config.errorHandler = (err, vm, info) => {
console.error("[Vue Error]", err, info);
Sentry.captureException(err);
};
/**
* 全局 Promise 异常(async/await 未 catch / new Promise 报错)
* 比如:Promise.reject("失败"),或者接口请求异常未处理
*/
window.addEventListener("unhandledrejection", (event) => {
console.error("[Unhandled Promise Rejection]", event.reason);
Sentry.captureException(event.reason);
});
/**
* 全局同步错误(JS 报错 / try-catch 漏掉的错误)
* 比如:throw new Error("xx"),或运行期 ReferenceError 等
*/
window.addEventListener("error", (event) => {
console.error("[Global Error]", event.error || event.message);
Sentry.captureException(event.error || event.message);
});
}主动上报错误:捕获那些不会自动抛出的异常
虽然我们已经通过自动监听覆盖了大多数前端异常,但实际开发中还有很多"业务逻辑错误"并不会抛异常,比如:
- 某接口返回了错误码(但没报错)
- 登录失败、权限不足等场景
- 某第三方 SDK 内部 silent fail
- 某些组件逻辑执行失败,但 catch 掉了没抛
这种情况下,程序表面看起来没问题,控制台也没报错,但我们大前端其实已经背锅了!!! 。要想让这些问题也被 Sentry 收到,就要靠主动上报。
所以我们可以在 sentry.ts 中新增两个工具函数:
javascript
/**
* 主动上报错误(可用于 catch 中或逻辑异常手动触发)
* @param error 异常对象
* @param context 可选的上下文标签(如 "登录失败")
*/
export function reportError(error: unknown, context?: string) {
console.error("[Manual Error]", error, context);
Sentry.captureException(error, {
tags: context ? { context } : undefined,
});
}
/**
* 安全执行函数:用于包装可能抛出异常的逻辑,避免中断流程
* @param fn 要执行的函数
* @param context 错误发生时附加的上下文信息
*/
export function safeExecute(fn: () => void, context?: string) {
try {
fn();
} catch (err) {
reportError(err, context);
}
}使用示例:
场景一:接口错误但没有抛异常
javascript
const res = await fetch('/api/login');
const json = await res.json();
if (json.code !== 0) {
reportError(new Error("登录失败"), "登录接口返回错误");
}场景二:包一层逻辑避免程序中断
javascript
safeExecute(() => {
// 某些不稳定逻辑
riskyFunction();
}, "支付模块逻辑异常");为什么我们推荐这样做呢?
- 业务异常不一定是技术异常,但同样需要排查
- 报错信息中带有
context标签,可以帮助我们快速定位问题来源(登录?支付?加载首页?) safeExecute可以在保底兜错的同时确保错误不会悄无声息地被吞掉- 最最最重要的是防止后端甩锅!!!
补充用户上下文信息:让错误背后的"人"和"设备"清清楚楚
前面我们讲了如何捕获错误、主动上报、加行为记录等等,但我们在实际用 Sentry 看报错详情时,很可能会发现一个问题:
"虽然报错内容我看懂了,但......这是谁的错?是在什么设备上报的?他从哪里进来的? "
默认情况下,Sentry 只会收集一些非常基础的信息,比如文件堆栈、报错文件、代码行号,但对于业务人员和开发来说,这些技术信息远远不够还原问题现场。
比如以下这些关键字段,往往都是空的:
- 当前用户 ID / 手机号
- 来源渠道(扫码进入?分享页面?哪个渠道?)
- 设备信息(iPhone 还是 Android?哪个浏览器?网络情况?)
- 用户行为路径(点了什么?进入了哪个页面?)
所以我们需要在用户登录后或页面初始化时,手动补充这些上下文信息,帮助我们更快地定位问题。
第一步:识别设备信息(device info)
我们可以在 src/utils/deviceInfo.ts 中封装一个方法,用来识别用户使用的设备、系统、浏览器等基础信息。
javascript
export function getDeviceBrand(): string {
const ua = navigator.userAgent.toLowerCase();
if (ua.includes("iphone")) return "Apple";
if (ua.includes("huawei")) return "Huawei";
if (ua.includes("xiaomi")) return "Xiaomi";
if (ua.includes("oppo")) return "OPPO";
if (ua.includes("vivo")) return "Vivo";
if (ua.includes("samsung")) return "Samsung";
return "Unknown";
}
export function getDeviceModel(): string {
return navigator.userAgent;
}
export function getOS(): string {
const platform = navigator.platform.toLowerCase();
const ua = navigator.userAgent.toLowerCase();
if (platform.includes("win")) return "Windows";
if (platform.includes("mac")) return "macOS";
if (/android/.test(ua)) return "Android";
if (/iphone|ipad|ipod/.test(ua)) return "iOS";
if (platform.includes("linux")) return "Linux";
return "Unknown";
}
export function getBrowser(): string {
const ua = navigator.userAgent;
if (ua.includes("Chrome") && !ua.includes("Edg")) return "Chrome";
if (ua.includes("Safari") && !ua.includes("Chrome")) return "Safari";
if (ua.includes("Firefox")) return "Firefox";
if (ua.includes("Edg")) return "Edge";
return "Unknown";
}
export function getNetworkType(): string {
const nav = navigator as any;
return nav.connection?.effectiveType || "unknown";
}第二步:在 sentry.ts 中设置用户、设备、行为等上文
javascript
/**
* 设置当前用户信息(在用户登录后调用)
*/
export function setSentryUserInfo(user: {
id: string;
username?: string;
email?: string;
level?: string;
channel?: string;
phone?: string; // 已脱敏,如 138****5678
}) {
Sentry.setUser({
id: user.id,
username: user.username,
email: user.email,
phone: user.phone,
});
if (user.channel) {
Sentry.setTag("channel", user.channel);
}
if (user.level) {
Sentry.setTag("user_level", user.level);
}
}
/**
* 设置设备上下文信息
*/
export function setDeviceContext() {
Sentry.setContext("device", {
brand: getDeviceBrand(),
model: getDeviceModel(),
os: getOS(),
browser: getBrowser(),
screen: `${window.screen.width}x${window.screen.height}`,
network: getNetworkType(),
});
}
/**
* 设置其他自定义标签信息
*/
export function setSentryTags(tags: Record<string, string>) {
Object.entries(tags).forEach(([key, value]) => {
Sentry.setTag(key, value);
});
}
/**
* 添加用户行为记录(Breadcrumb)
*/
export function addSentryBreadcrumb(info: {
category: string;
message: string;
level?: "info" | "warning" | "error";
data?: Record<string, any>;
}) {
Sentry.addBreadcrumb({
category: info.category,
message: info.message,
level: info.level || "info",
data: info.data,
timestamp: Date.now() / 1000,
});
}第三步:在登录成功或页面初始化时调用这些方法
javascript
// 设置模拟用户信息
setSentryUserInfo({
id: "1000000",
username: "中秋游客",
channel: "midautumn-h5",
level: "guest",
phone: "138****5678", // 已脱敏
});
// 设置页面标签(可筛选、聚合用)
setSentryTags({
page: "midautumn-event",
platform: "h5",
env: import.meta.env.MODE || "development",
});
// 设置设备上下文信息
setDeviceContext();可选:记录用户行为路径(面包屑)
面包屑的作用,就是帮我们还原"出错前用户都干了啥"。
比如用户进入了哪个页面、点了什么按钮、提交了哪个表单,这些都可以通过 addSentryBreadcrumb() 主动记录下来。
javascript
// 用户点击"进入活动页"
addSentryBreadcrumb({
category: "navigation",
message: "进入订单页",
});或者使用全局路由守卫自动记录所有页面跳转:
javascript
router.afterEach((to) => {
addSentryBreadcrumb({
category: "navigation",
message: `用户进入页面:${to.name || "unknown"}`,
data: { path: to.fullPath }, // 可在 data 里加自定义参数,比如页面路径、来源等
});
});第四步:验证上下文信息是否成功
比如我们写一段简单的函数,故意抛出一个错误,用来测试:
javascript
function throwError() {
throw new Error("这是一个测试错误,用于验证 Sentry上下文 错误捕获功能。");
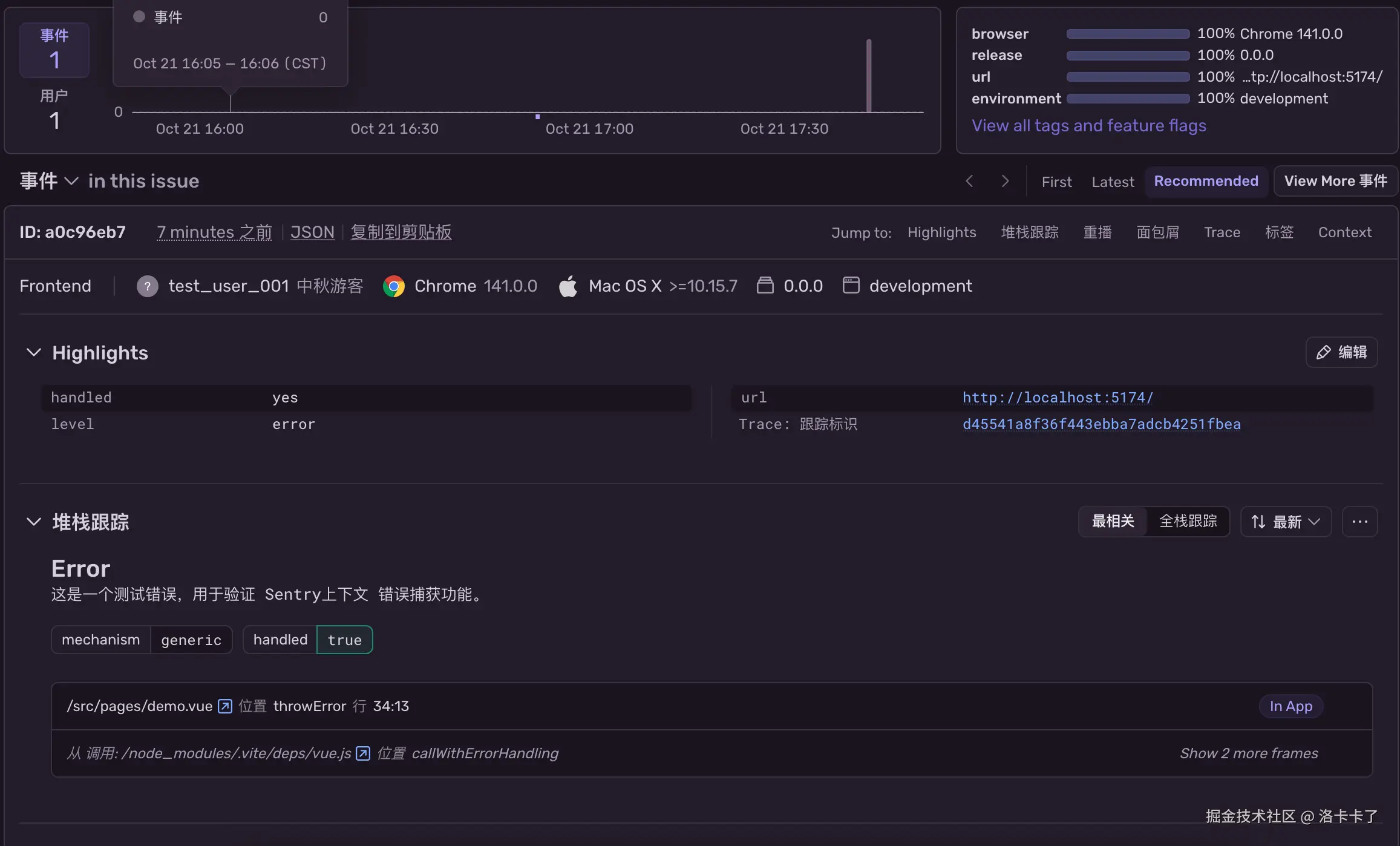
}执行完后,Sentry 控制台就会收到一条错误。
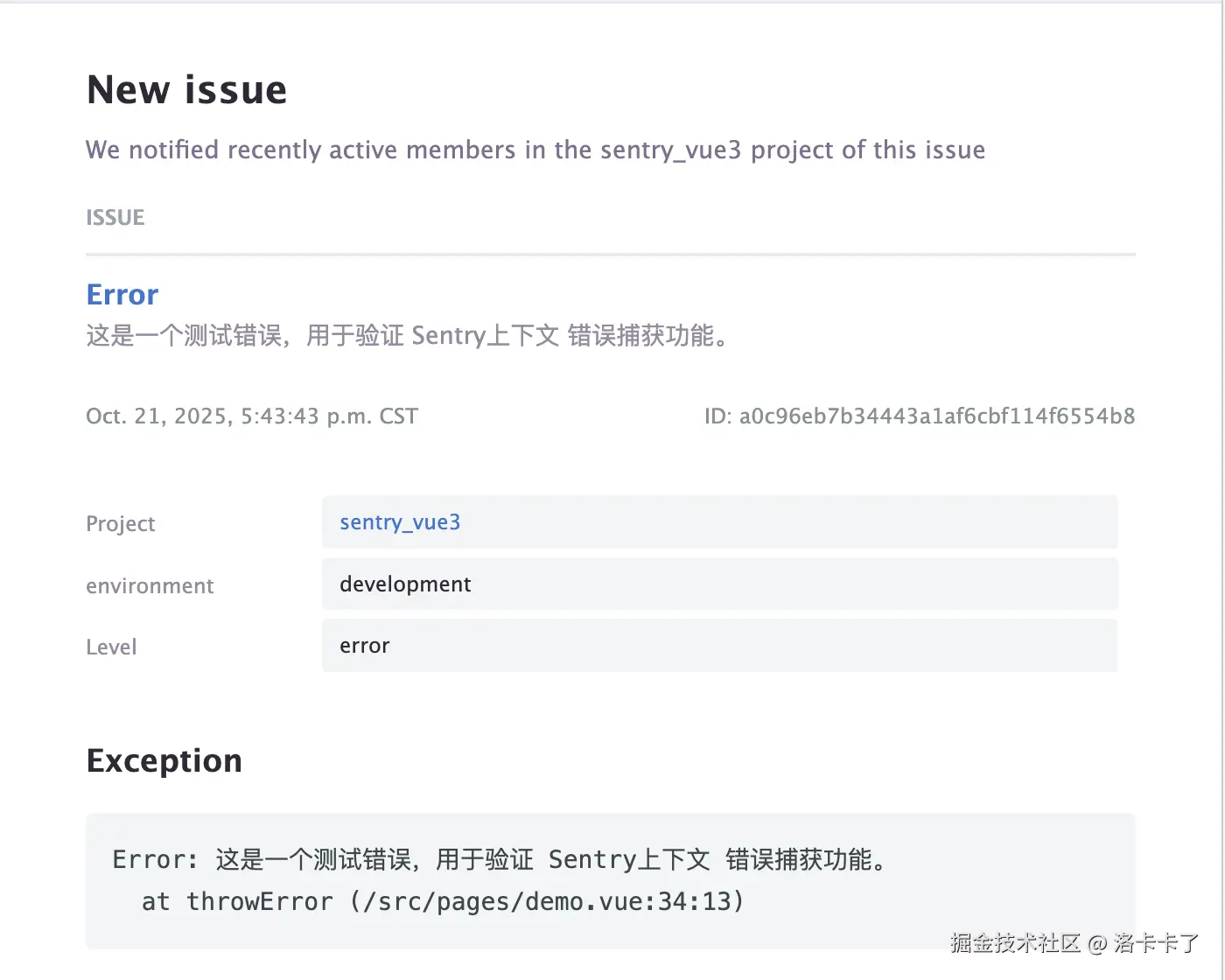
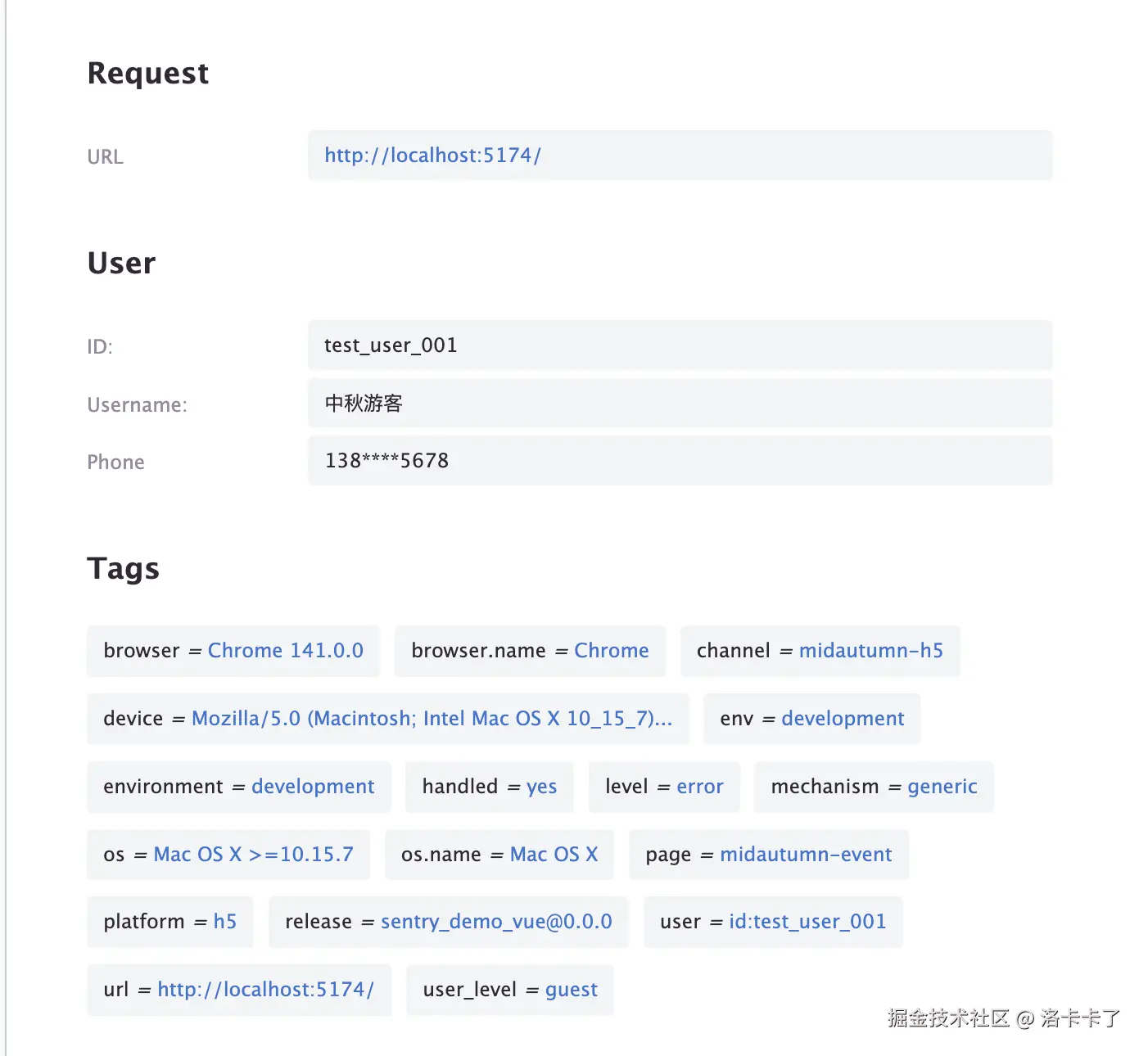
我们打开错误详情页面就可以在事件顶部清晰看到:
- 用户 ID:
test_user_001 - 浏览器、系统、环境等基础信息
再往下展开,就会看到更详细的信息
- 用户名、手机号、地域定位
- 浏览器版本、系统版本、网络类型等
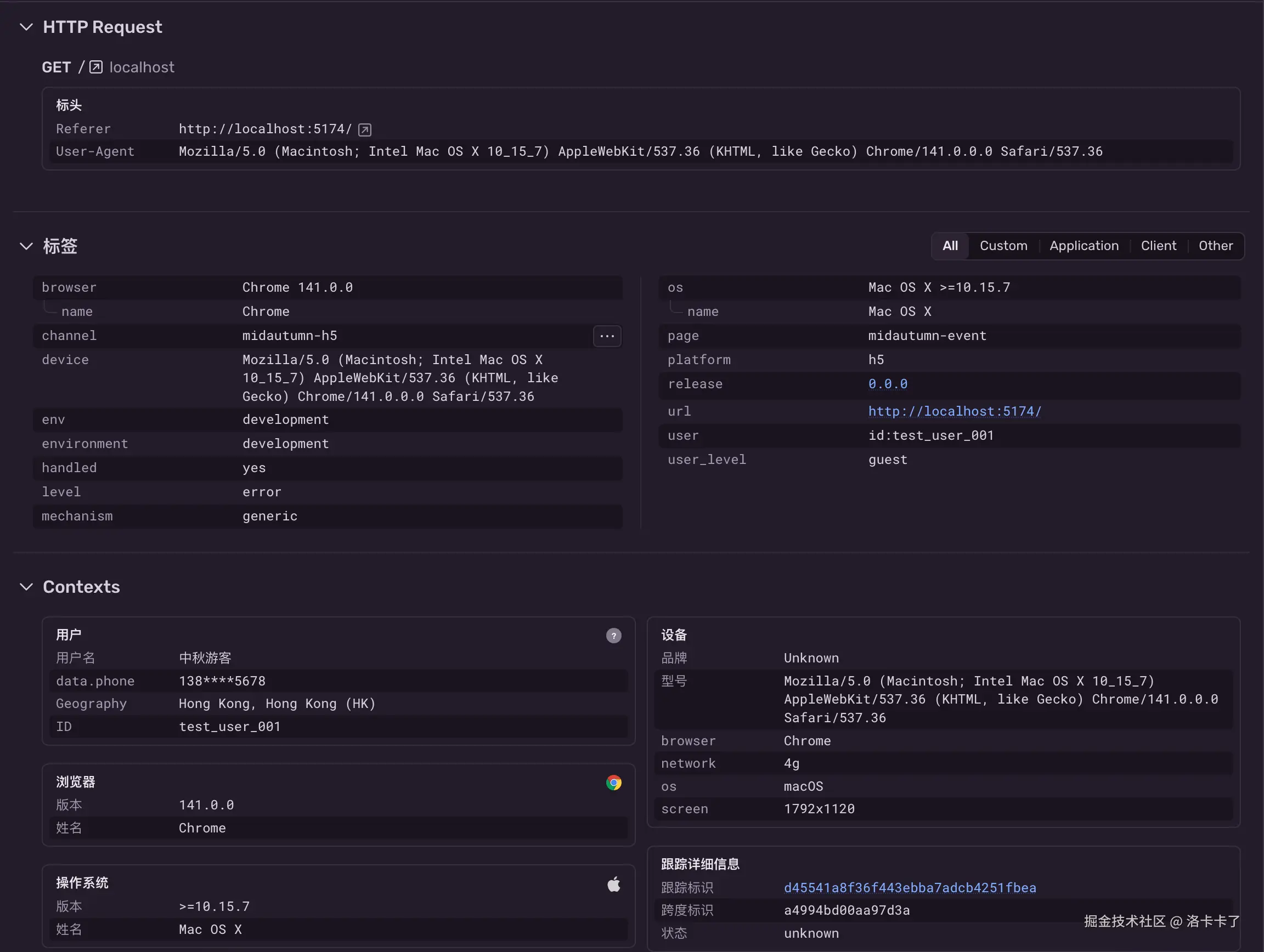
这些信息都能帮我们快速还原出问题用户的设备和环境。
加上这些后 我们这边收到的错误报警邮件有关用户信息也清晰可见:
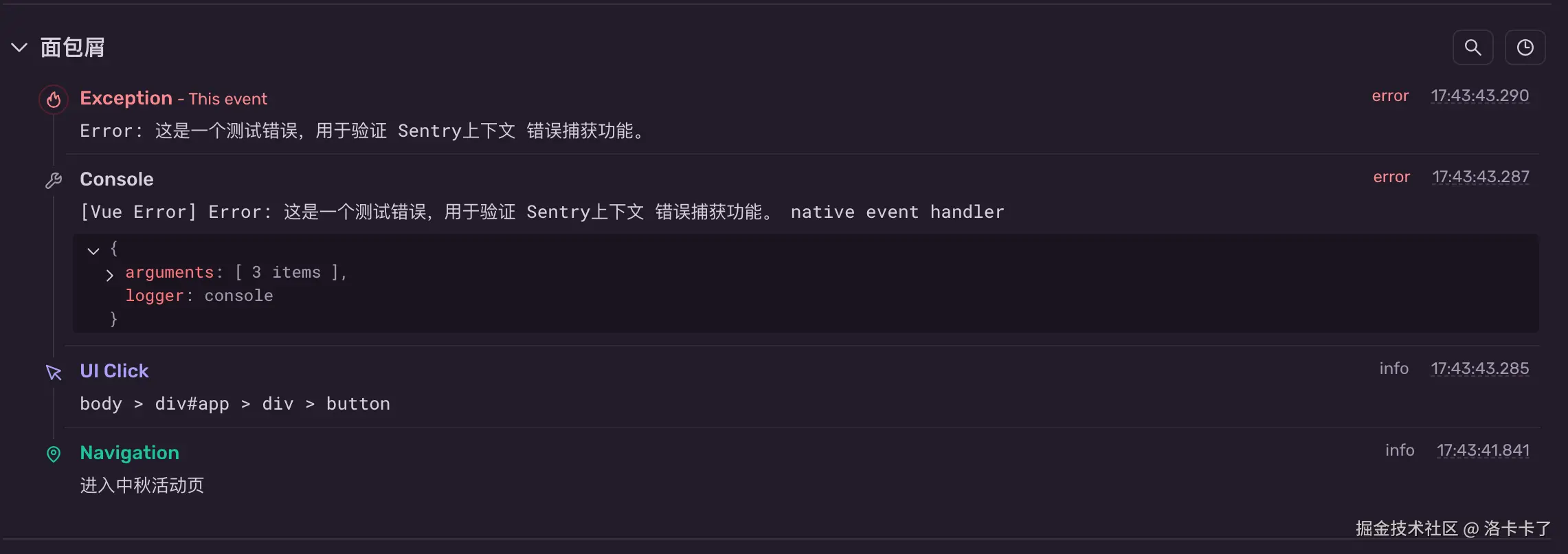
我们还可以加上一些"用户干了什么"的记录,比如:
javascript
addSentryBreadcrumb({
category: "navigation",
message: "进入中秋活动页",
});这样在 Sentry 中就能看到这条导航事件方便我们追踪用户在报错之前点了什么、跳转了哪儿。
大概总结下
虽然设置上下文信息看似繁琐,但带给我们的价值很直接:
- 报错信息中能看到哪个用户、在哪个页面、使用什么设备出了问题
- 可以根据渠道、环境、等级等进行错误聚合和筛选
- 加入用户行为记录(Breadcrumb)可以还原问题发生前的操作路径
- 日志也能跟业务人员"对得上话"了,不再只是开发自己看懂的异常栈
那什么是 SourceMap呢,为什么我们需要它?
我们先回顾下前面测试的那个例子:
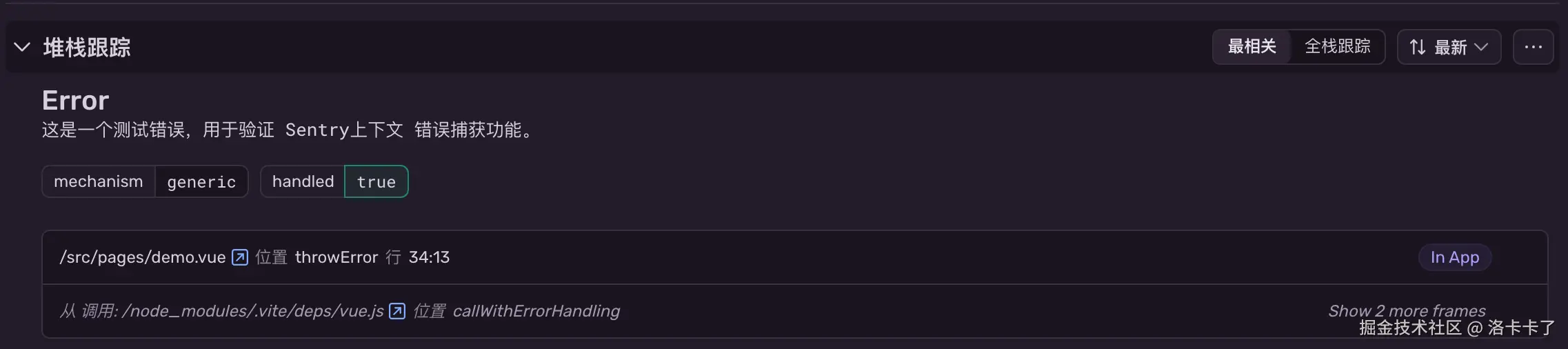
当我们在项目中手动触发一个错误,比如:
javascript
function throwError() {
throw new Error("这是一个测试错误,用于验证 Sentry 上下文捕获功能。");
}在本地运行时,我们Sentry 报错详情里能准确显示是哪一行、哪一段代码出了问题,甚至堆栈信息都非常清晰。
但是别忘了这只是因为我们还没打包,也就是在「开发模式」下运行,代码结构是完整的。
但是一旦上线,情况就变了
我们实际部署项目时,都会执行类似这样的构建命令:
js
pnpm build这一步会把所有 JS 文件压缩、混淆,删除注释、缩短变量名、合并文件,生成的代码会变成这种形式:
javascript
function a(t){try{r(t)}catch(n){console.error(n)}}这是浏览器喜欢的格式,但对人来说几乎没法看懂。
如果这时候线上用户触发了一个错误,Sentry 捕获的堆栈信息也会变成这样:
javascript
at chunk-abc123.js:1:1735我们就根本不知道这段报错到底是哪个文件、哪一行,甚至连哪个函数都不知道。
这时候就需要 SourceMap 来救场了,SourceMap 就是用来建立「压缩后代码」和「原始代码」之间映射关系的文件。
只要我们在打包之后把 .map 文件上传到 Sentry,它就能根据这些映射文件,把上面那种看不懂的堆栈信息,自动还原回我们写的源码,准确标注是哪一个文件、函数、哪一行代码出了问题。
简单来说:
打包后代码压缩了,看不懂了。
我们要想让 Sentry 继续帮我们还原出错位置,必须上传对应的
.map文件。
哪可能会问上传 SourceMap 会不会把源码暴露出去?
这个问题简单来说:
默认情况下,肯定是会暴露的。
为什么这么说呢?
因为我们每次执行 vite build 或 npm run build 时,生成的 .js 文件旁边都会有一个 .js.map 文件。如果我们把整个 dist 目录原封不动部署到线上服务器,那用户只要打开浏览器、F12 控制台一看,就能直接访问:
arduino
https://我们的域名/assets/app.js.map点开之后就是我们项目的源码结构,变量名、注释、函数逻辑一清二楚。
这就相当于:我们把项目源码白白送出去了。
那我们需要怎么做呢?
我们真正需要的,其实只是把这些 .map 文件上传给 Sentry 用于还原堆栈,而不是暴露给所有人访问。
推荐的流程是:
- 本地或 CI 构建时生成
.map文件; - 使用 Sentry CLI 或插件上传
.map到 Sentry; - 上传成功后,立刻删除本地的
.map文件; - 最终部署时,只发布
.js文件,不包含.map文件。
这样一来:
- Sentry 能还原报错堆栈;
- 用户访问不到
.map; - 项目源码就不会被轻易扒走了。
总之记住一句话:SourceMap 是给 Sentry 用的,不是给别人看的。
上传它,用完就删,不要留在线上。
接下来我们就来讲讲这个上传流程怎么做:包括怎么配置、怎么自动上传、怎么验证效果。
如何配置 SourceMap 上传到 Sentry
接下来我们就开始配置一下,把前端项目打包后的 .map 文件上传到 Sentry,用于错误堆栈还原。
1. 安装依赖
我们先安装 Sentry 提供的插件和命令行工具:
json
pnpm add -D @sentry/vite-plugin @sentry/cli2. 配置环境变量
为了让上传工具知道我们是谁、我们的项目在哪、发的是哪个版本,我们需要配置几个环境变量。
我们只需要在项目根目录下创建一个 .env.production 文件,把 Sentry 所需的配置写在里面即可:
json
# 从 Sentry 设置页面获取
VITE_SENTRY_AUTH_TOKEN=你的AuthToken
VITE_SENTRY_ORG=你的组织名
VITE_SENTRY_PROJECT=你的项目名
# 如果我们使用的是私有化部署(比如自建的 Sentry 服务器)默认就是https://sentry.io
VITE_SENTRY_URL=https://sentry.io/
# 可选:设置当前的 release 版本号,可以是 1.0.0,也可以是 git commit hash
VITE_SENTRY_RELEASE=your-project@1.0.0这些配置只会在打包构建时(vite build)被加载,开发环境下不会生效,也不需要在 .env.development 或 .env.local 中重复配置。
其实我们可以把
VITE_SENTRY_RELEASE设置为当前 Git 提交版本(git rev-parse --short HEAD),这样上传的 SourceMap 文件可以精准匹配线上版本,后面我们会演示如何自动设置。
3.修改 vite.config.ts
我们需要在 Vite 配置中引入 Sentry 插件,并做一些初始化设置:
javascript
import { defineConfig, loadEnv } from 'vite'
import vue from '@vitejs/plugin-vue'
import path from 'path'
import pkg from './package.json';
import { sentryVitePlugin } from '@sentry/vite-plugin';
import { execSync } from 'child_process';
// https://vitejs.dev/config/
export default defineConfig(({ mode }) => {
const env = loadEnv(mode, process.cwd())
const project = env.VITE_SENTRY_PROJECT || pkg.name
const version = execSync('git rev-parse --short HEAD').toString().trim()
const release = `${project}@${version}`
return {
plugins: [
vue(),
sentryVitePlugin({
url: env.VITE_SENTRY_URL, // 如果用的是官方 sentry.io,也可以省略
org: env.VITE_SENTRY_ORG,
project: env.VITE_SENTRY_PROJECT,
authToken: env.VITE_SENTRY_AUTH_TOKEN,
release: release,
include: './dist',
urlPrefix: '~/',
deleteAfterCompile: true, // 上传后删除 .map 文件
}),
],
resolve: {
alias: {
'@': path.resolve(__dirname, './src'),
},
},
define: {
__RELEASE__: JSON.stringify(release), // 注入全局常量
__APP_VERSION__: JSON.stringify(pkg.version),
},
build: {
sourcemap: true, // 必须开启才能生成 .map
},
}
})4. 修改构建命令,删除残留 .map 文件(可选)
虽然我们配置了 deleteAfterCompile: true,但有些场景下我们可能还想手动确保 .map 不被部署,可以在 package.json 的构建命令里加上:
json
{
"scripts": {
"build": "vite build && find ./dist -name '*.map' -delete"
}
}这个命令会先构建项目,再扫描 dist 目录,把所有 .map 文件都删除。
这样就能确保我们部署上线时不会把 SourceMap 文件一并带上,只上传给 Sentry,确保安全。
5.如何获取 Sentry 的 Auth Token?
为了让 sentry-cli 或插件能识别我们是谁,并授权上传 SourceMap,我们需要生成一个 Sentry 的 Token。下面是获取步骤:
第一步:进入 Sentry 设置页面
在左侧菜单栏,点击左下角的齿轮图标(Settings)进入设置界面。
第二步:创建新的 Token
在 Organization Tokens 页面:
-
点击右上角的「创建新的令牌」按钮;
-
会弹出一个创建表单:
- 姓名(Name) :填一个方便识别的名字就行,比如项目名
sentry_vue3; - 作用域(Scopes) :选择
org:ci,这个包含了我们上传 SourceMap 所需的权限(Release Creation 和 Source Map Upload);
- 姓名(Name) :填一个方便识别的名字就行,比如项目名
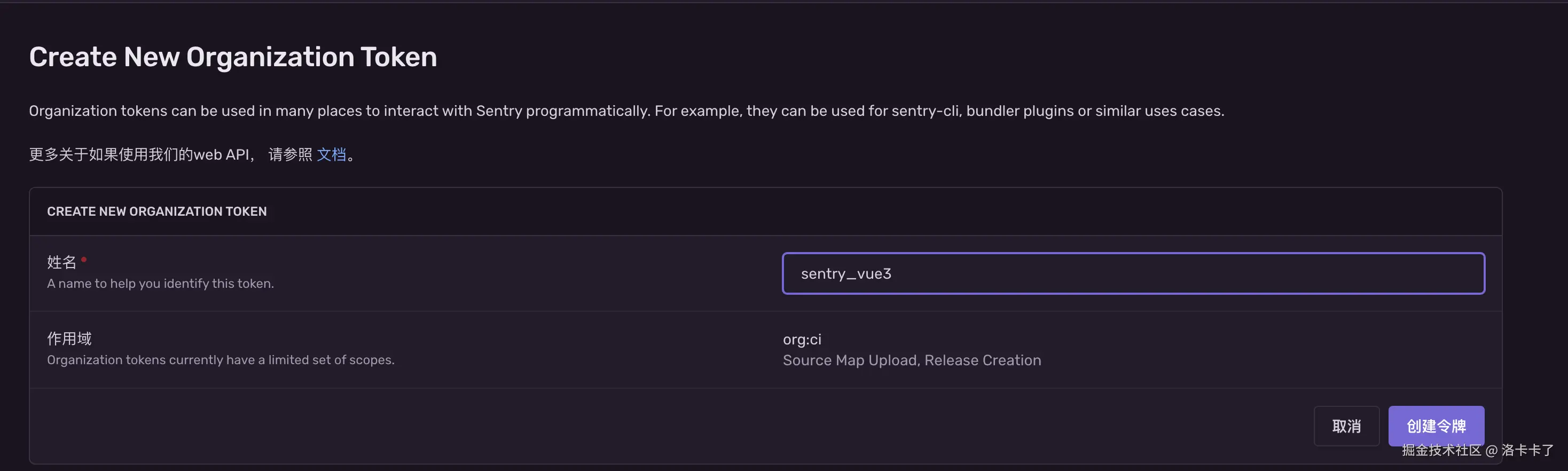
- 然后点击「创建令牌」。
创建成功后,会看到类似这样的 Token:
markdown
sntrys_************Yt8k这个 Token 就是我们要填到 .env.production 文件里的 VITE_SENTRY_AUTH_TOKEN。
一点点建议
- 这个 Token 只显示一次,请复制保存好;
- 不要提交到 Git 仓库,建议通过 CI 环境变量注入;
- 权限只勾选
org:ci就够用,不建议勾选太多;
6.执行打包并验证上传效果
前面的配置完成之后,我们就可以正式打包项目,并将 .map 文件上传到 Sentry 了。
在项目根目录执行打包命令:
pnpm build如果一切配置正确,我们会在控制台中看到类似下面的提示:
python
Source Map Upload Report
Scripts
~/67e49c15-590c-4e25-8b79-388f91742a8e-0.js (sourcemap at index-ByQNq1yw.js.map, debug id 67e49c15-590c-4e25-8b79-388f91742a8e)
Source Maps
~/67e49c15-590c-4e25-8b79-388f91742a8e-0.js.map (debug id 67e49c15-590c-4e25-8b79-388f91742a8e)
[sentry-vite-plugin] Info: Successfully uploaded source maps to Sentry这说明:SourceMap 上传成功,Sentry 已经接收了我们打包后的 .map 文件,并关联到了对应的 release。
如果我们配置了:
vbnet
deleteAfterCompile: true或者在构建命令后手动加了 .map 清理命令,那么构建完成后,.map 文件会被删除,防止误部署到线上。
我们可以执行以下命令检查:
arduino
ls dist/**/*.map如果终端提示为空(或者没有任何输出 / 提示文件找不到),说明 .map 文件已经被自动清理干净了。
这样,当我们的项目打包上线后,如果线上出现错误,再去 Sentry 查看报错详情时,堆栈信息就会像本地开发时一样清晰。我们就能直接看到具体的文件名、函数名和代码行号,而不会再只看到那些压缩后的文件路径和混淆变量。
有关release的说明,sourcemap 能不能生效就看它了
在使用 Sentry 的 SourceMap 功能时,有一个非常关键但又容易被忽略的前提:上传 SourceMap 时指定的 release,必须和我们代码里 Sentry SDK 初始化时的 release 完全一致。
我们可以把 release 理解为我们项目的版本号。每一次打包部署,都是一次 release。
而 Sentry 正是通过这个 release 来定位错误属于哪一次部署,以及匹配该版本下上传的 SourceMap。
如果我们打包时用了一个 release,结果初始化 SDK 时用了另一个,那抱歉,即使我们成功上传了 .map 文件,Sentry 也没法把错误堆栈还原成源码,只能告诉我们:
makefile
chunk-abc123.js:1:1729所以,我们必须确保这两个地方的 release 保持一致。
为了防止这类问题,我采用了构建时统一生成 release 的方式,并在代码中注入一个全局变量 __RELEASE__,确保 Sentry 插件上传 SourceMap 和 SDK 初始化用的是同一个版本号。
第一步:在 vite.config.ts 中构造 release 并注入
我们读取 VITE_SENTRY_PROJECT 作为项目名,配合当前 Git 提交的哈希值,组合成一个 release,例如:
css
sentry_demo_vue@a1b2c3d然后通过 define 注入到全局变量中:
javascript
define: {
__RELEASE__: JSON.stringify(`${project}@${version}`),
}并同时用于配置 sentryVitePlugin 插件上传:
javascript
sentryVitePlugin({
release: `${project}@${version}`,
...
})第二步:在 Sentry.init() 中使用 __RELEASE__
初始化 SDK 时,我们不再手动拼 release,而是直接使用刚才注入的变量:
arduino
Sentry.init({
release: __RELEASE__,
...
})这样无论我们在哪个环境构建,版本号都自动带上了当前的 Git 版本,既统一又不容易出错。
第三步:在 env.d.ts 中声明变量
为了让 TypeScript 识别这个全局变量,我们加了一行类型声明:
php
declare const __RELEASE__: string;构建后的项目在上传 SourceMap 时自动使用当前 git 版本,Sentry SDK 上报时也使用同样的版本号。
最终在 Sentry 后台查看错误堆栈时,源码路径、函数名、行号都能完整还原。
总结一句话:Sourcemap 能不能生效,
release一致是前提。
Sentry埋点
在实际项目中,我们做埋点往往不是为了凑功能或者"形式上有就行",而是为了更好地还原用户行为轨迹、分析问题来源、辅助产品决策、提升整体体验。
我们可以从几个常见的场景来看,哪些地方用得上埋点:
1. 用户行为异常分析
有时候我们只知道某个页面报错了,但不知道用户是怎么操作的才触发这个错误。
比如:
用户说"我点完某个按钮之后页面就出错了",但后台日志只显示某个接口 500,没有更多上下文。
这种情况下,就很难还原他是从哪里点进来的、是不是页面跳转顺序有问题、是不是某个按钮点了两次才出的问题。
如果我们在关键操作、页面跳转等地方都加了埋点,那就能清楚地知道:
- 用户先打开了哪个页面
- 之后点了哪些按钮
- 最后在什么操作后出现了异常
这在做线上问题定位、还原用户操作路径时非常重要,特别是配合 Sentry 这类错误监控工具中的「面包屑」功能,效果更明显。
2. 活动页面点击统计 / 转化分析
在活动运营中,埋点更是刚需。
比如一个节日活动页面上线了,运营可能会问:
- 有多少人打开了这个页面?
- 弹窗展示了多少次?有多少人点了"立即参与"按钮?
- 最终提交表单的人有多少?和点击的人比,转化率是多少?
这些数据平时并不会自动记录在系统里,需要我们在页面中通过埋点记录:
- 页面曝光
- 按钮点击
- 表单提交
最终才能做出转化漏斗分析,判断活动效果。如果没有埋点,就等于活动做完了,但不知道效果如何,下一次也无从优化。
3. 功能使用率评估
有一些功能上线后,看起来"做完了",但实际有没有人用、用得多不多,其实系统本身不会告诉我们的。
比如我们上线了一个"收藏"功能、一键生成配置功能等,那我们可能会好奇:
- 有多少用户点过这个功能?
- 他们点的时候是在哪个页面?
- 是不是位置太隐蔽了,大家都没发现?
这种情况下,如果我们事先加了埋点,就能清晰看到使用情况,如果发现点击量非常少,就能反过来推动:
- 改位置
- 加引导
- 甚至考虑是否下线这个功能
所以很多时候,埋点也起到了"帮助产品做决策"的作用。
4. 页面性能与路径优化
更进一步的埋点,我们还可以配合页面性能分析。
比如:
- 记录用户从首页点击"立即购买"到真正进入支付页,一共用了多久?
- 是不是在中间某个页面加载得特别慢?
通过在关键页面加载完成时打点,再记录时间差,我们就可以发现瓶颈,进行页面或接口的性能优化。
示例:用户行为异常埋点分析
在前面的内容中,我们提到了可以通过在路由中埋点的方式,记录用户的行为路径,方便后续定位问题。比如下面这段代码:
javascript
router.afterEach((to, from) => {
const toTitle = to.meta.title || to.name || to.fullPath
const fromTitle = from.meta?.title || from.name || from.fullPath || '(无来源)'
addSentryBreadcrumb({
category: 'navigation',
message: `从【${fromTitle}】进入【${toTitle}】`,
data: {
from: from.fullPath,
to: to.fullPath,
}
})
document.title = `${toTitle} - MyApp`
})这段代码的作用很简单:每当用户路由跳转时,就自动添加一条导航相关的面包屑信息,包括来源页面和目标页面。这条信息会被 Sentry 记录下来,作为用户行为轨迹的一部分。
模拟一次异常流程
我们啦做一个简单的测试:
- 用户先从首页进入"关于我们"页面;
- 然后点击跳转到"错误页面";
- 在错误页面中主动抛出一个异常。
这时候我们再打开 Sentry 后台,查看错误详情,可以看到下图中记录的错误信息:
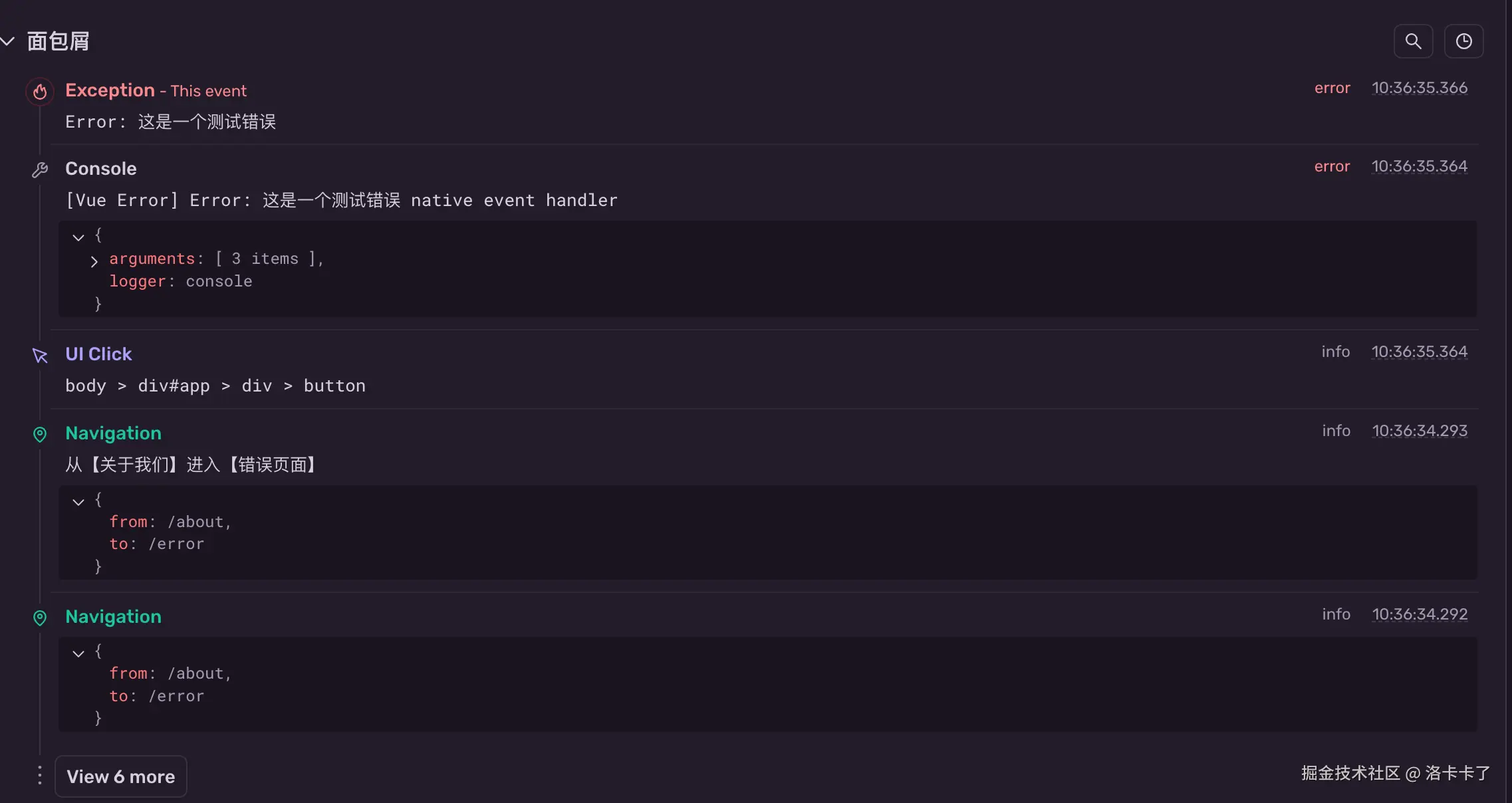
- 第一条是抛出的异常信息;
- 再往下就是用户触发异常之前的行为记录,比如从"关于我们"进入"错误页面"。
查看完整的用户行为链路
为了进一步分析问题,我们可以点击 View 6 more 展开完整的面包屑日志:
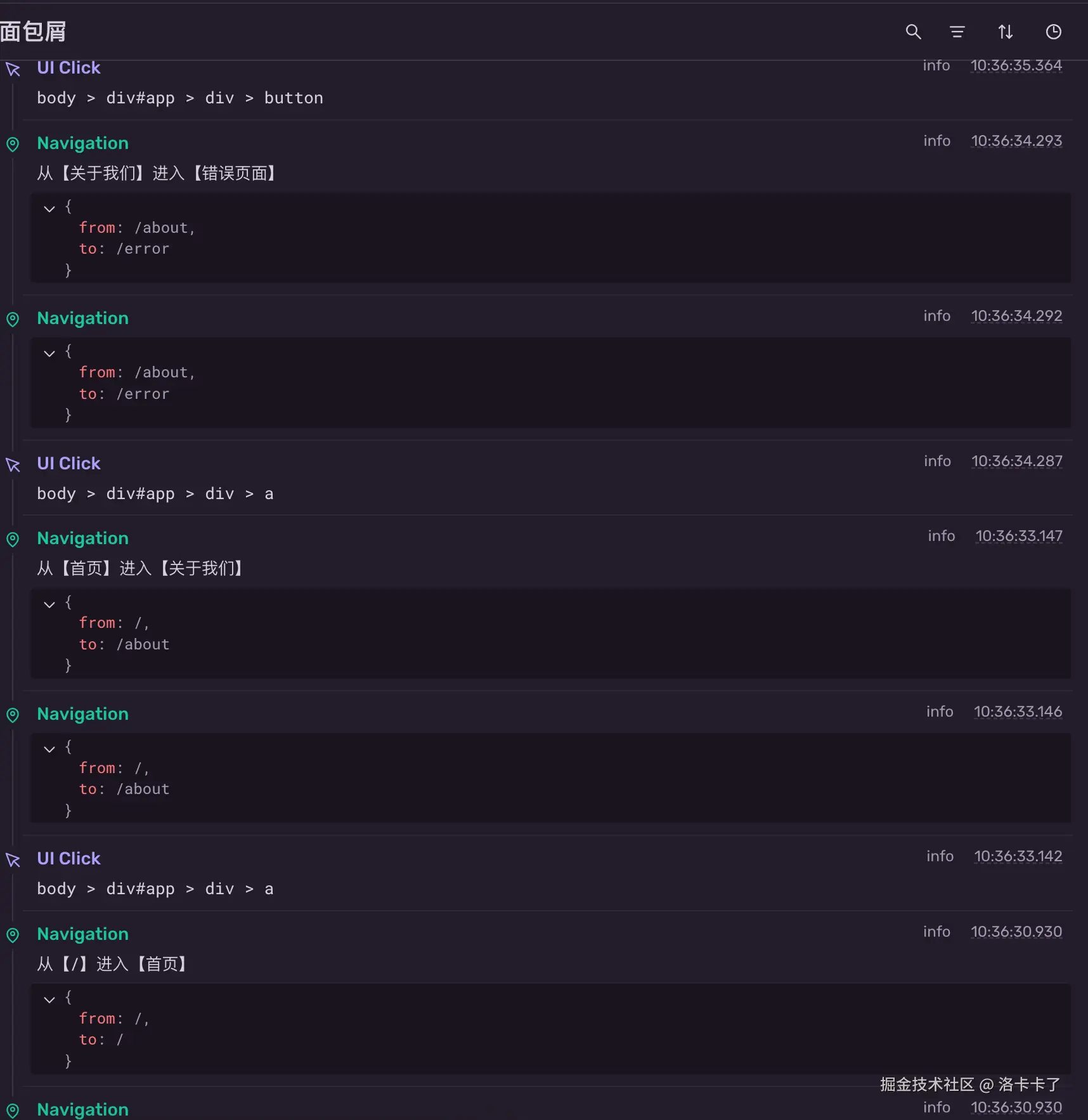
在这个面板中,我们能清晰看到整个操作链路:
- 用户从首页进入了"关于我们";
- 然后从"关于我们"跳转到了"错误页面";
- 最终触发了异常。
通过这样的导航面包屑,我们就能非常直观地还原用户的操作过程,判断异常是否与某一步操作有关,从而帮助我们快速复现并定位问题。这也是"用户行为异常埋点"的一个实际应用场景。
开启用户行为录制:还原错误发生前的真实场景
虽然我们在上一节中已经通过 addSentryBreadcrumb() 记录了用户的一些关键行为路径,比如用户点击了哪些按钮、跳转了哪些页面等等,这些信息已经可以帮助我们初步还原用户操作链路。
但在实际排查中,我们有时仍然会遇到这种情况:
用户反馈某个操作卡住了,但没有明确报错日志,甚至连 Sentry 都没捕捉到异常。
我们看到的面包屑记录是:"进入页面 -> 点击按钮",中间过程缺失,还是无法判断究竟是哪一步出了问题。
这时候,如果我们能把用户当时的页面操作录像下来,就能更精准地还原整个流程,更快速定位问题。这正是 Sentry 提供的 Replay 录屏功能 的作用。
一、安装依赖
要使用 Sentry 的屏幕录制功能(Replay),我们需要安装两个包:
sql
pnpm add @sentry/vue @sentry/replay二、如何开启 Sentry Replay 录制功能?
我们可以通过配置 @sentry/vue 提供的 replayIntegration() 模块,来快速启用该功能。核心逻辑如下:
修改 src/sentry.ts 中的初始化代码
javascript
import * as Sentry from "@sentry/vue";
import { browserTracingIntegration, replayIntegration } from "@sentry/vue";
import type { App } from "vue";
import router from "./router";
export function setupSentry(app: App) {
Sentry.init({
app,
dsn: import.meta.env.VITE_SENTRY_DSN,
environment: import.meta.env.MODE || "development",
release: __RELEASE__,
debug: true,
integrations: [
browserTracingIntegration({ router }),
replayIntegration({
maskAllText: false, // 是否对所有文本打码(false 表示原样录入)
blockAllMedia: false // 是否屏蔽图像、视频、SVG 等(false 表示保留媒体)
}),
],
// 性能采样设置
tracesSampleRate: 1.0,
// Replay 录像设置
replaysSessionSampleRate: 0.0, // 普通会话是否录像(设为 0 表示不录像)
replaysOnErrorSampleRate: 1.0, // 错误发生时是否录像(设为 1 表示100%录像)
});
// 省略:全局 errorHandler、Promise rejection、主动上报等逻辑...
}三、录制策略说明
replaysSessionSampleRate: 控制普通用户访问页面时是否录像,建议在生产环境设为0.0,避免过多无用录像。replaysOnErrorSampleRate: 控制发生 JS 报错、Promise 拒绝等错误时是否开启录制。建议设为1.0,即每次出错都能录像。
这样可以有效地将录像资源集中在真正出现问题的会话上,提高定位效率。
四、如何验证是否成功开启?
重启项目 → 打开控制台 → 手动触发一个 JS 报错,比如:
javascript
throw new Error("这是一个测试错误");然后我们会在 Sentry 控制台中看到新的报错事件,这时候:
- 页面右侧出现一个【Replay】按钮。
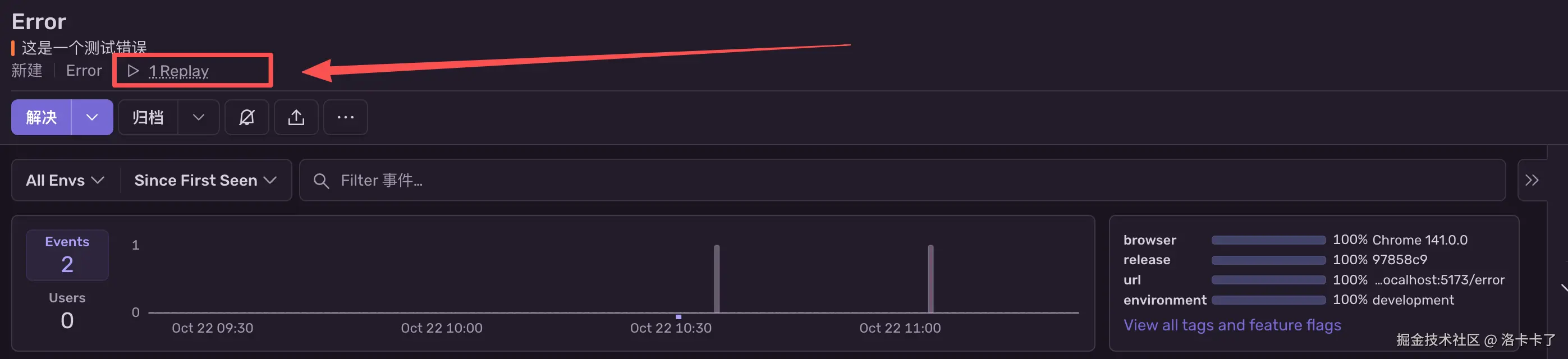 2. 点击后即可播放用户在该报错发生前后的操作录像。
2. 点击后即可播放用户在该报错发生前后的操作录像。
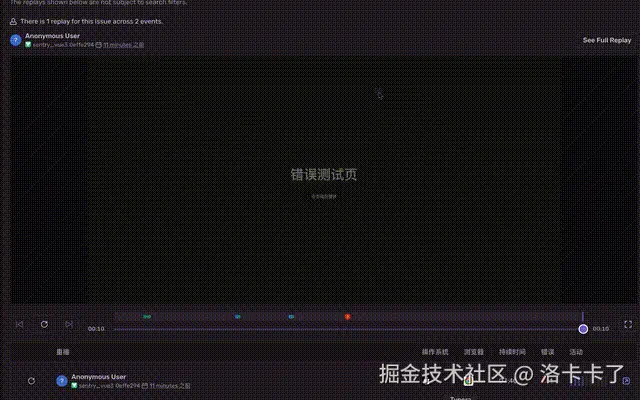
- 右下角还会有一个【See full replay】按钮,点击可以切换到完整录像页面。
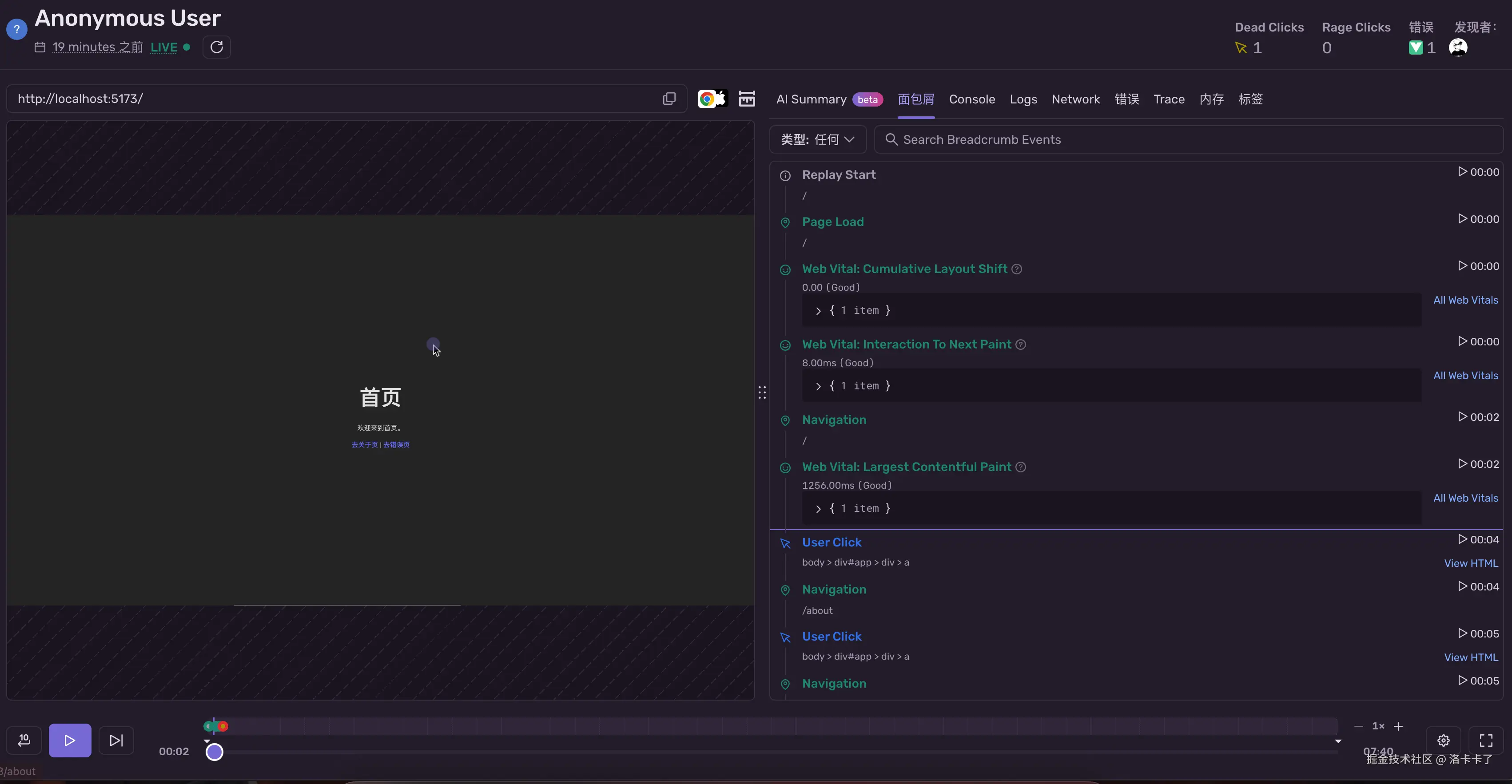 同时我们也会看到报错发生前后的【Breadcrumb】面包屑操作记录,比如页面跳转、按钮点击等行为。这样就可以帮助我们从"用户视角"真正还原问题现场。
同时我们也会看到报错发生前后的【Breadcrumb】面包屑操作记录,比如页面跳转、按钮点击等行为。这样就可以帮助我们从"用户视角"真正还原问题现场。
五、更多高级配置项(可选)
Sentry 提供了更丰富的配置能力,比如:
| 配置项 | 说明 |
|---|---|
maskAllText |
是否对页面所有文本内容打码(防止敏感数据泄露) |
blockAllMedia |
是否屏蔽页面中的图片、视频、canvas 等内容 |
networkDetailAllowUrls |
可选:采集请求详情(如 API 请求) |
identifyUser() |
推荐结合 Sentry.setUser(...) 在登录后设置用户 ID,方便后续排查是谁遇到了问题 |
Sentry.addBreadcrumb() |
可选:在关键行为处手动添加操作记录(行为日志) |
通过启用 @sentry/vue 提供的 Replay 功能,我们可以在出错时自动录制用户行为,大幅提升排查效率。结合已有的日志上报、用户 ID、标签与面包屑操作记录,我们能更完整地还原真实使用场景,做到"看得见问题"。
页面性能监控:不仅能看到错误,还能看到哪里慢了
我们前面已经实现了错误上报、面包屑埋点和屏幕录制,基本能定位大部分异常情况。
但有时候用户并不会报错,只是觉得页面加载慢、跳转卡顿或者某个页面总是半天才出来。这类"没报错但体验不好"的问题,如果我们没有性能监控,是很难发现的。
这个时候,我们可以启用 Sentry 的页面性能监控功能,来帮助我们记录:
- 页面加载时间(比如首屏渲染用了多久)
- 路由跳转耗时
- 请求接口的耗时
- 页面初始化过程中每一段逻辑的时间消耗
只要在初始化的时候加上 browserTracingIntegration 插件,就能自动采集这些信息。
安装依赖
如果还没安装性能监控相关的依赖,需要先补一下:
sql
pnpm add @sentry/vue @sentry/tracing添加性能监控配置
打开 setupSentry() 初始化方法,在 integrations 数组里加上:
javascript
import { browserTracingIntegration } from '@sentry/vue'
Sentry.init({
// ...其他配置省略
integrations: [
browserTracingIntegration({
router, // 配置 vue-router 实例,自动记录路由跳转耗时
}),
],
// 设置性能采样率(开发环境建议 1.0,生产建议 0.1)
tracesSampleRate: 1.0,
})这样配置之后,Sentry 就会自动帮我们记录每一次页面加载和跳转的耗时信息。
在哪里能看到这些数据?
配置好之后,进入 Sentry 控制台,点击左边导航的 "Performance" 或 "性能" 菜单,我们会看到每一次页面加载都被记录成了一条"事务(Transaction)"。
每条事务会显示页面加载过程中各个阶段的耗时情况,比如:
- DOM 渲染用了多久
- 路由跳转用了多久
- 图片 / 视频 / 接口加载花了多长时间
- 哪些任务是最耗时的
我们可以直接点进来查看详细的耗时分析图,定位"到底慢在哪里"。
上面实操部分我用的不多就不举例了,加上性能监控之后,我们就能做到:
- 不光知道"哪里出错了",还能知道"哪里慢了"
- 能从页面加载细节里找到性能瓶颈
- 帮助前端在没有用户投诉的情况下,提前发现体验问题
到这一步,整个前端监控体系就比较完整了。我们不仅能看到错误、知道用户做了什么、还能还原他们的操作流程,甚至还能判断性能好不好。
关于Sentry报警
除了错误上报、性能监控、用户行为录屏这些能力,我们还可以借助 Sentry 配置「报警通知」。
Sentry 支持我们设置一些规则,比如:某个错误首次出现、在短时间内重复出现多次、或影响的用户数量较多等情况时,自动触发告警。
目前默认是通过邮件来发送通知,配置起来也比较简单。如果我们想把报警信息同步到团队使用的工具,比如 Slack、飞书、Discord、企业微信等,也可以在后台的集成中心中,安装并配置对应的集成插件。
不过需要注意的是,部分通知渠道(比如 Webhook 或企业应用)可能需要更高的权限或私有化部署支持。如果我们只是用默认的云服务版本,那通常只支持部分渠道(比如邮件、Slack)直接接入。
总的来说,Sentry 的告警通知功能,适合和日常的监控流程搭配使用,帮助我们在异常发生的第一时间就收到提醒,快速定位并响应问题。
关于Sentry部署
前面我们演示的 Sentry 接入、错误上报、录屏、性能监控等功能,都是基于官方提供的云端版本(sentry.io)来进行的。
这种方式适合快速试用,不需要我们自己搭建,也省去了维护服务器、数据库的麻烦。但也有一些限制,比如:
- 有些功能(如完整的 Webhook 通知、自定义数据保留时长)只有付费套餐才支持;
- 数据存在 Sentry 的服务器上,可能不太适合对数据安全要求高的项目;
- 无法根据我们自己的业务场景做一些深度定制。
如果项目对隐私、权限或者功能控制有更高要求,Sentry 也支持"私有化部署"。我们可以自己部署一个 Sentry 服务,所有数据保存在自己的服务器上。
实际中我们最常见的部署方式有:
- Docker :官方提供了基于 Docker 的部署方案(develop.sentry.dev/self-hosted... Docker,就可以一键拉起整个服务;
- 手动部署:适用于对环境要求更细的公司,比如手动安装 PostgreSQL、Redis、Kafka、Symbolicator 等组件,然后运行 Sentry;
- 云服务商镜像:也可以从一些云平台的镜像市场上获取现成的 Sentry 部署包,比如 AWS、GCP 上可能会有官方或第三方的镜像。
不过部署 Sentry 的门槛相对还是偏高一些,对运维资源有一定要求。所以如果只是中小型项目、团队人手不多,优先使用云端版本会更加方便。
这里由于写的太多了我就不再一步一步来部署一遍了。不会部署的同学可以看下其他有关的文章跟着搞一下 其实也不难的。
其他:部署在公网时的一点小建议:加一层 Nginx + HTTPS 反向代理更稳妥
一般我们在部署 Sentry 到公网时,都会单独配置一个二级域名(比如 sentry.xxx.com),然后通过 Nginx 做一层反向代理,并加上 HTTPS 证书,确保访问安全。
如果我们只是通过 IP 地址访问,比如 http://123.123.123.123:9000,不仅会被浏览器提示"不安全连接",而且线上项目调用时也可能因为协议不一致(HTTP 和 HTTPS 混用)被浏览器拦截,甚至影响 Sentry 的上报。
所以更推荐的做法是:
- 配一个好记的二级域名,比如
sentry.mycompany.com; - 用 Nginx 做一层反向代理,把外部请求转发到 Sentry 实际运行的
localhost:9000; - 再配一个 HTTPS 证书(可以使用 Let's Encrypt 免费证书);
- 开启 80 → 443 自动跳转,确保用户始终走 HTTPS。
这样做不仅更安全,浏览器和 SDK 的请求也更顺畅,还能防止接口报 mixed content 错误。这个我也不讲具体操作了。反正也不难,我这篇写的太多了就不细讲了。ip部署有问题的可以看下其他相关文章 写的很棒的。
结语
回到开头,其实我们一开始其实就是在思考这个问题:
前端有没有必要接入 Sentry 这类监控平台?
其实很多团队对前端监控这块的投入确实不多,常见理由无非是"没什么错误"、"出了问题也能看到控制台"、"又不是后端服务挂了影响业务"......
但真到了线上环境,事情往往不是这么简单。
但是我们这篇内容通过实际接入和配置,大概也已经看到了 Sentry 的这些能力:
- 可以记录详细的 JS 报错信息,堆栈定位非常清晰;
- 通过 Source Map 还原源码,准确找到是哪一行代码报错;
- 面包屑功能可以帮我们分析用户触发错误前的操作链路;
- 录屏功能能完整还原用户操作过程,方便我们复现 bug;
- 能设置错误报警通知,第一时间知道哪里出问题了;
- 如果部署在自有服务器上,还能满足企业内部的合规需求。
这么一看,其实前端接入 Sentry 不仅"有必要",而且是非常值得做的一件事。它不仅能提升前端排查问题的效率,还能让团队整体对线上问题的掌控力大大增强。
虽然我们一直强调用技术实现"降本增效",能节省的就尽量省,但前端监控这类影响线上稳定性和用户体验的能力,是不能省的。
很多时候,一个难复现的前端 bug,可能会花掉开发、测试、运营三方大量时间。与其靠人力去定位和还原,不如一开始就接入好监控工具,把排查和追踪的成本降下来。
如果我们是个人开发者,Sentry 提供的免费额度已经够用;如果是企业团队,用 Docker 自建也不复杂。
与其被动应对报错,不如主动掌握问题的第一现场。这,就是前端接入 Sentry 的价值所在。