Binxu Li、Minkai Xu 等来自斯坦福大学的研究团队提出了一种名为 DMPO(Divergence Minimization Preference Optimization) 的新方法,用于更好地将扩散模型与人类偏好对齐。
📖 目录
- 研究背景:为什么扩散模型需要"对齐"?
- [现有方法的"陷阱":均值 seeking 带来的模糊图像](#现有方法的“陷阱”:均值 seeking 带来的模糊图像)
- [DMPO 登场:用"反向 KL"精准捕捉偏好](#DMPO 登场:用“反向 KL”精准捕捉偏好)
- [理论保证:DMPO 与 RLHF 方向一致](#理论保证:DMPO 与 RLHF 方向一致)
- [实验结果:自动指标 + 人类评估双杀](#实验结果:自动指标 + 人类评估双杀)
- [图像编辑彩蛋:DMPO 让"宠物入口"不再消失](#图像编辑彩蛋:DMPO 让“宠物入口”不再消失)
- [消融实验:α 与 β 的的敏感性](#消融实验:α 与 β 的的敏感性)
- 总结与展望
- [快速 FAQ](#快速 FAQ)

1. 研究背景:为什么扩散模型需要"对齐"?
扩散模型(Diffusion Models, DM)自 2020 年横空出世以来,凭借「逐步去噪」的独特机制,在文本生成图像(T2I)任务上一骑绝尘。无论是 Midjourney 的插画风格,还是 Stable Diffusion 的开源生态,都展示了其惊人的「作画」能力。然而,这些模型在训练阶段往往采用单阶段、大规模图文对的方式,目标仅仅是「复现」互联网上的图文分布,而非「理解」人类对一张好图的微妙偏好。
| 模型家族 | 训练流程 | 对齐手段 | 效果 |
|---|---|---|---|
| 大语言模型(LLM) | 两阶段:预训练 + 偏好微调 | RLHF / DPO | 回答更贴心、更安全 |
| 扩散模型(DM) | 单阶段图文对训练 | ❌ 无显式对齐 | 可能"答非所图" |
一句话 :扩散模型会画"猫",但不一定画出你最想看的猫 。
目标:让模型生成"人类更pick"的图像,而不仅仅是"合理"的图像。
🎯 对齐(Alignment):让扩散模型听懂"人话"
在大语言模型(LLM)领域,研究者们早已发现「两阶段训练」的重要性:
- 预训练:让模型"博览群书",掌握通用知识;
- 偏好微调:用 RLHF 或 DPO 对齐人类价值观,让回答更贴心、更安全。
扩散模型同样需要这样的"第二阶段"------偏好对齐。
2. 现有方法的"陷阱":均值 seeking 带来的模糊图像
⚠️ 前向 KL 散度的副作用
- Diffusion-DPO 实质在优化:
D K L ( p ∗ ∥ p θ ) D_{KL}(p^*\|p_\theta) DKL(p∗∥pθ) - 问题:为了"覆盖"所有可能的好样本,模型被迫平均化 → 图像变模糊、细节丢失。
📌 什么是"均值 seeking"?
在统计学里,前向 KL 散度(也叫 I-projection)有一个著名特性:
它要求模型 q(x) 必须在 p(x) 的每一个非零区域都分配质量,否则 KL→∞。
翻译到图像生成领域:
- 如果人类偏好分布 p* 里"既喜欢卡通猫,也喜欢写实猫",
- 那么模型 pθ 就必须同时生成两种猫,哪怕训练数据里只给了"卡通猫更好"的提示。
- 结果 → 一张图里卡通+写实混搭 ,耳朵毛绒绒、身体却高清毛发,四不像!
🖼️ 视觉层面的"灾难"
| 提示词 | 人类期望 | 均值 seeking 结果 |
|---|---|---|
| "a cute corgi in a wizard hat" | 可爱短腿+帽子服帖 | 腿长忽长忽短,帽子半悬浮 |
| "cyberpunk city, neon rain" | 高对比、锐利光斑 | 全图灰蒙蒙,霓虹灯变成涂色块 |
| "a spoon with eyes and a smile" | 清晰表情、勺子光泽 | 眼睛融化在金属里,笑容成噪点 |
🧠 心理学视角:为什么人类讨厌"平均脸"
认知学研究表明,人们对"平均化"面孔的喜好度中等偏下 ------因为缺乏鲜明特征 。同理,对图像的审美也遵循"峰值偏好":我们更喜欢高饱和度、高对比、焦点清晰的片子,而非"面面俱到"的平淡图。前向 KL 恰恰把模型推向后者。
🚧 扩散家族的三种"均值 seeking"问题
- 路径级平均:Diffusion-DPO 在整条去噪轨迹上求期望,导致每步都要"兼顾"多种走向;
- 像素级平均:高维 RGB 空间下,KL 惩罚任何"零概率"区域,迫使像素值向"中庸灰"靠拢;
- 风格级平均:卡通与写实同时存在时,模型把高频纹理与低频色块混为一谈,生成"油画+照片"杂交体。
3. DMPO 登场:用"反向 KL"精准捕捉偏好
🎯 核心思想
最小化反向 KL 散度 :
D K L ( p θ ∥ p ∗ ) D_{KL}(p_\theta\|p^*) DKL(pθ∥p∗)
- 只惩罚模型在"不支持区域 "放质量 → 迫使模型聚焦高奖励模态。
- 生成结果:更清晰、更贴合提示、更符合人类偏好。
🧮 实战 loss(成对偏好)
L DMPO = E ( x w , x l ) , t σ ( u t ) log σ ( u t ) 1 − α + σ ( − u t ) log σ ( − u t ) α \mathcal{L}{\text{DMPO}}=\mathbb{E}{(x^w,x^l),t}\Big\\sigma(u_t)\\log\\frac{\\sigma(u_t)}{1-\\alpha}+\\sigma(-u_t)\\log\\frac{\\sigma(-u_t)}{\\alpha}\\Big LDMPO=E(xw,xl),tσ(ut)log1−ασ(ut)+σ(−ut)logασ(−ut)
其中
u t = − β T ∥ ε w − ε θ ( x t w ) ∥ 2 − ∥ ε w − ε ref ( x t w ) ∥ 2 − ( 同上 x l ) u_t=-\frac{\beta}{T}\Big\\\|\\varepsilon\^w-\\varepsilon_\\theta(x\^w_t)\\\|\^2-\\\|\\varepsilon\^w-\\varepsilon_{\\text{ref}}(x\^w_t)\\\|\^2-(\\text{同上 }x\^l)\\Big ut=−Tβ∥εw−εθ(xtw)∥2−∥εw−εref(xtw)∥2−(同上 xl)
4. 理论保证:DMPO 与 RLHF 方向一致
定理 (一句话版)
当 β = 1 \beta=1 β=1 时,
∇ θ L DMPO = − ∇ θ L RLHF \nabla_\theta\mathcal{L}{\text{DMPO}}=-\nabla\theta\mathcal{L}_{\text{RLHF}} ∇θLDMPO=−∇θLRLHF
→ 虽然推导路线不同,但优化方向完全一致,理论严谨无偏。
5. 实验结果:自动指标 + 人类评估
👥 人类小样本盲测(100 提示 × 3 问题)
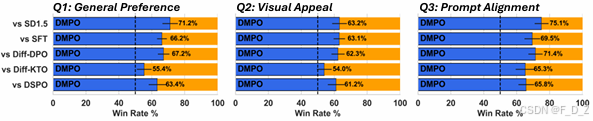
📊 自动评估(Pick-a-Pic V2)
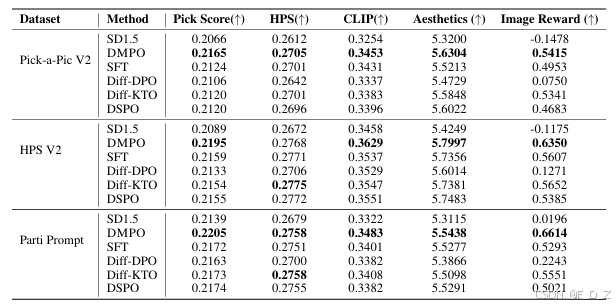
在Pick-a-Pic V2、HPS V2和Parti-Prompt数据集上,所有基准与SD1.5的奖励分数比较,最佳结果用粗体字表示。平均领先第二名 64.6%(PickScore 胜率)
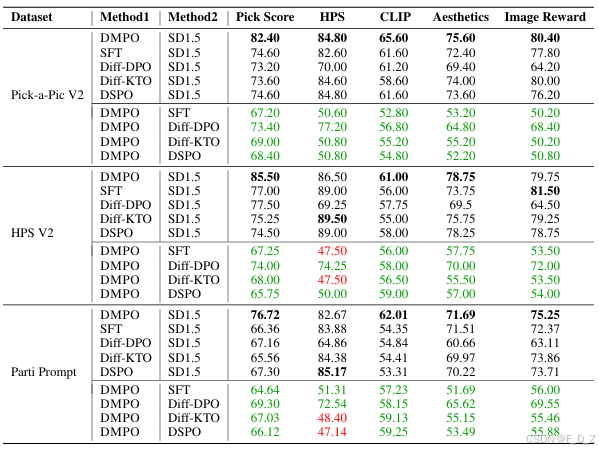
(a) Winrate (%) 在 Pick-a-Pic V2、HPS V2 和 Parti-Prompt 数据集上对比所有基线与 SD 1.5 的比较。(b) DMPO 与其他基线之间的胜率比较,胜率超过 50% 的用绿色表示,低于 50% 的用红色表示。
🌟 从"能画"到"画得好"

与其他方法相比,DMPO始终表现出更强的能力来捕捉提示的语义意图,产生的输出更加准确且质量更高。例如,在第一行中,只有DMPO成功呈现了"微笑"的概念,而在第二行中,它是唯一一个正确描绘"装扮成水手的木瓜"的模型。
6. 图像编辑彩蛋:DMPO 让"宠物入口"不再消失
除了改善图像生成任务的对齐性,DMPO还显著增强了模型在图像编辑方面的能力,尤其是在文本引导的图像编辑场景中。
任务 :真实图像 + 文本指令 → 编辑后图像
案例:
-
输入:一扇门 + "add a pet entrance"
-
DMPO :精准出现宠物小门

在第一行中,只有DMPO正确理解和呈现了内容"宠物入口"。在第二行中,输入提示为"一个半吃的披萨。",只有DMPO生成了一幅在语义上真实且视觉上高度吸引的图像。
7. 消融实验:α 与 β 的敏感性
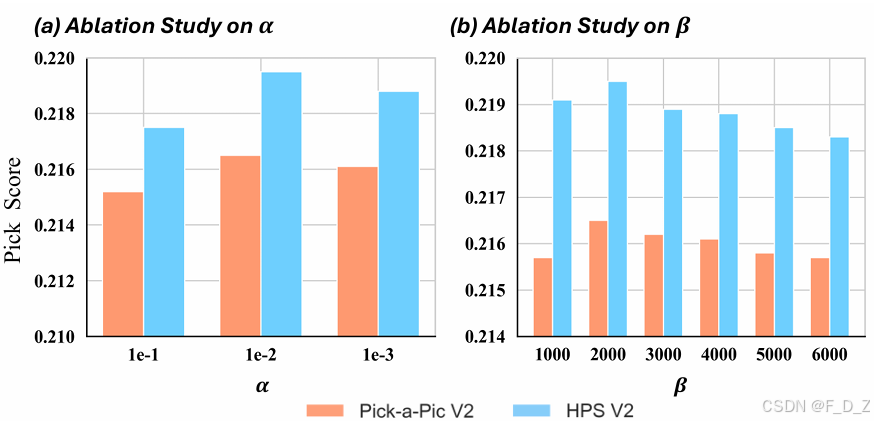
在Pick-a-Pic V2和HPS V2测试集上进行评估。(a) β的影响:当α固定为0.01时,随着β的增加,模型性能先增加后减少。(b) α的影响:当β固定为2000时,性能同样先增加后减少,随着α的增加
8. 总结与展望
✅ 一句话总结
DMPO 用"反向 KL"让扩散模型不再平均化 ,而是精准命中 人类最喜欢的模态,理论严谨 + 实验碾压。
🔮 未来方向
- 视频扩散模型对齐(VideoDM)
- 多模态条件(文本 + 图像 + 音频)
- 在线偏好收集 + 实时微调
9. 快速 FAQ
Q1:DMPO 需要额外模型或奖励网络吗?
❌ 不需要,只用成对偏好数据即可训练。
Q2:计算成本比 Diffusion-DPO 高多少?
⏱️ 几乎相同,每次迭代只多 2 次噪声预测差值。
Q3:能在 SDXL 上用吗?
✅ 已验证,SDXL 版本同样领先。
