pdf转md思路
rapidocr paddle版本的报错(onnxruntime解析很慢)
C++ Traceback (most recent call last): No stack trace in paddle, may be caused by external reasons. Error Message Summary: FatalError: Segmentation fault' is detected by the operating system. Timelnfo: \*\*\* Aborted at 1760348604 (unix time) try "date-d @1760348604" if you are using GNU date \*\*\* Signallnfo: \*\*\* SIGSEGV (@0x7fafe0a32000) received by PID 29461 (TID 0x7fb8bbdff700) from PID 18446744073183371264 \*\*\*
C++ 调用栈(按最近调用顺序排列): 在 paddle 中没有出现堆栈跟踪信息,这可能是由外部原因导致的。 错误信息摘要: 致命错误:操作系统检测到"分段错误"。系统信息:\*\*\* 异常终止于 1760348604(UNIX 时间) 请使用 GNU 的 date 命令执行"date -d @1760348604"来查看 \*\*\* 信号信息:\*\*\* 发生了 SIGSEGV(0x7fafe0a32000)信号,由进程 ID 29461(线程 ID 0x7fb8bbdff700)从进程 ID 18446744073183371264 发出 \*\*\*
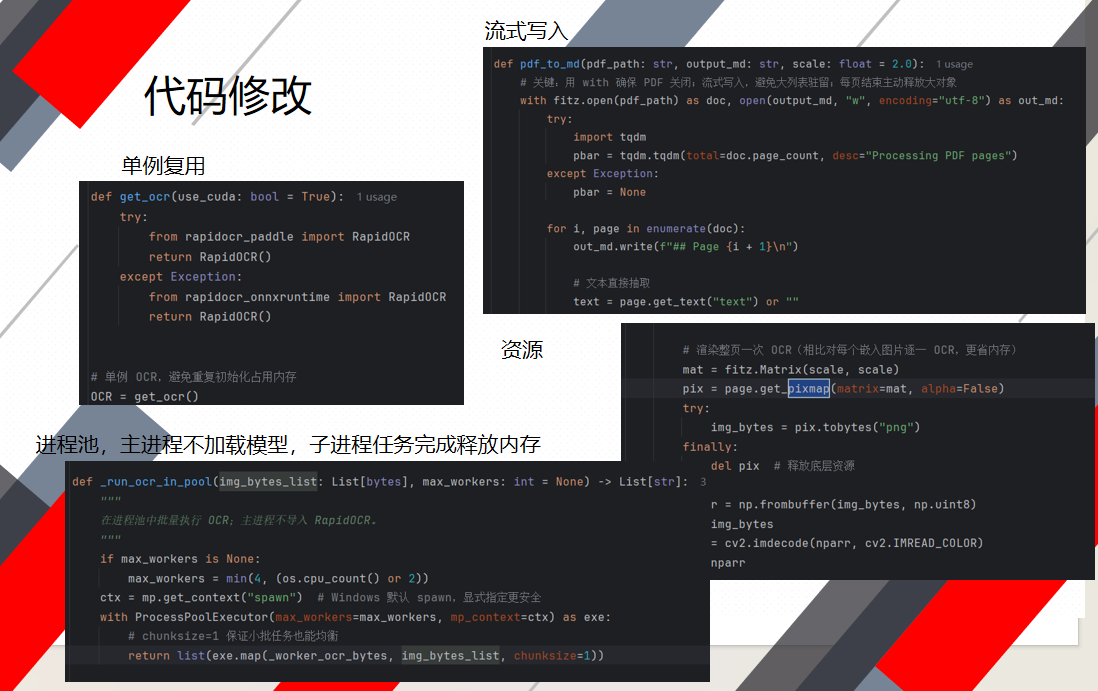
这里是我pdf写md的文件代码的问题,每次调用一页的内存就会增加50MB左右,在top指令可以看到。上升到3G,可能有OOM。
然后针对代码进行了优化。这里的单例复用,每次解析都会调到一次ocr实例,单例复用 的代码进行修改,改为进程池,主进程只负责pdf转图像流,子进程负责将图像进行解析流式写入md,然后就可以了