LongAdder 和 AtomicLong 都是 Java 并发包中重要的原子类,但它们的设计哲学和最佳应用场景有显著区别。下面这个表格能帮你快速抓住核心差异。
| 特性维度 | AtomicLong | LongAdder |
|---|---|---|
| 核心设计 | 单变量 CAS 竞争模型 | 多单元(Cell)分散竞争模型(分而治之) |
| 高并发写性能 | 较差(竞争激烈时CAS失败重试频繁,CPU空转严重) | 极佳(竞争被分散,显著减少冲突) |
| 读(get/sum)性能 | 极佳(一次 volatile 读,直接返回精确值) | 较差(需遍历 Cell 数组求和,非原子快照,是最终一致性的) |
| 内存占用 | 小(仅一个 long 变量) | 较大(需维护基础值 base 和 Cell 数组,空间换时间) |
| 数据一致性 | 强一致性:每次读都能获得最新的、精确的值 | 最终一致性 :sum()返回的是调用时刻的近似值 |
| 功能接口 | 提供丰富的原子操作(如 compareAndSet) |
主要提供 add、increment等简单算术操作 |
💡 深入理解工作原理差异
两者性能差异的根源在于其内部实现机制。
-
AtomicLong 的单一热点竞争
AtomicLong 内部维护了一个被
volatile修饰的value变量。每次线程执行incrementAndGet()等操作时,都会通过 CAS 操作去直接修改这个value。在高并发下,大量线程同时竞争修改这一个变量,会导致大量的 CAS 失败和重试(自旋)。同时,由于value的可见性要求,频繁的修改会引发总线上的大量 缓存一致性流量 (如flush和refresh操作),消耗大量CPU资源,导致性能下降。 -
LongAdder 的分而治之策略
LongAdder 则采用了更聪明的"分段"思想。它内部有一个 base 变量和一个 Cell\[\] 数组。
-
低竞争时 :线程会尝试直接 CAS 更新
base变量。 -
高竞争时 :系统会为线程分配一个
Cell数组中的元素,让线程主要去更新自己对应的那个Cell。这样,就将对一个变量的激烈竞争,分散到了多个变量上,极大地降低了冲突概率。当需要获取最终结果(调用
sum()方法)时,LongAdder 会将base和所有Cell数组中的值累加起来。因为这个过程没有加锁,所以得到的是某个时刻的最终一致性的近似值,而非绝对精确的实时值。
-
🎯 如何做出正确选择
理解了原理,选择标准就非常清晰了。你可以根据下面的决策流程图来快速判断:
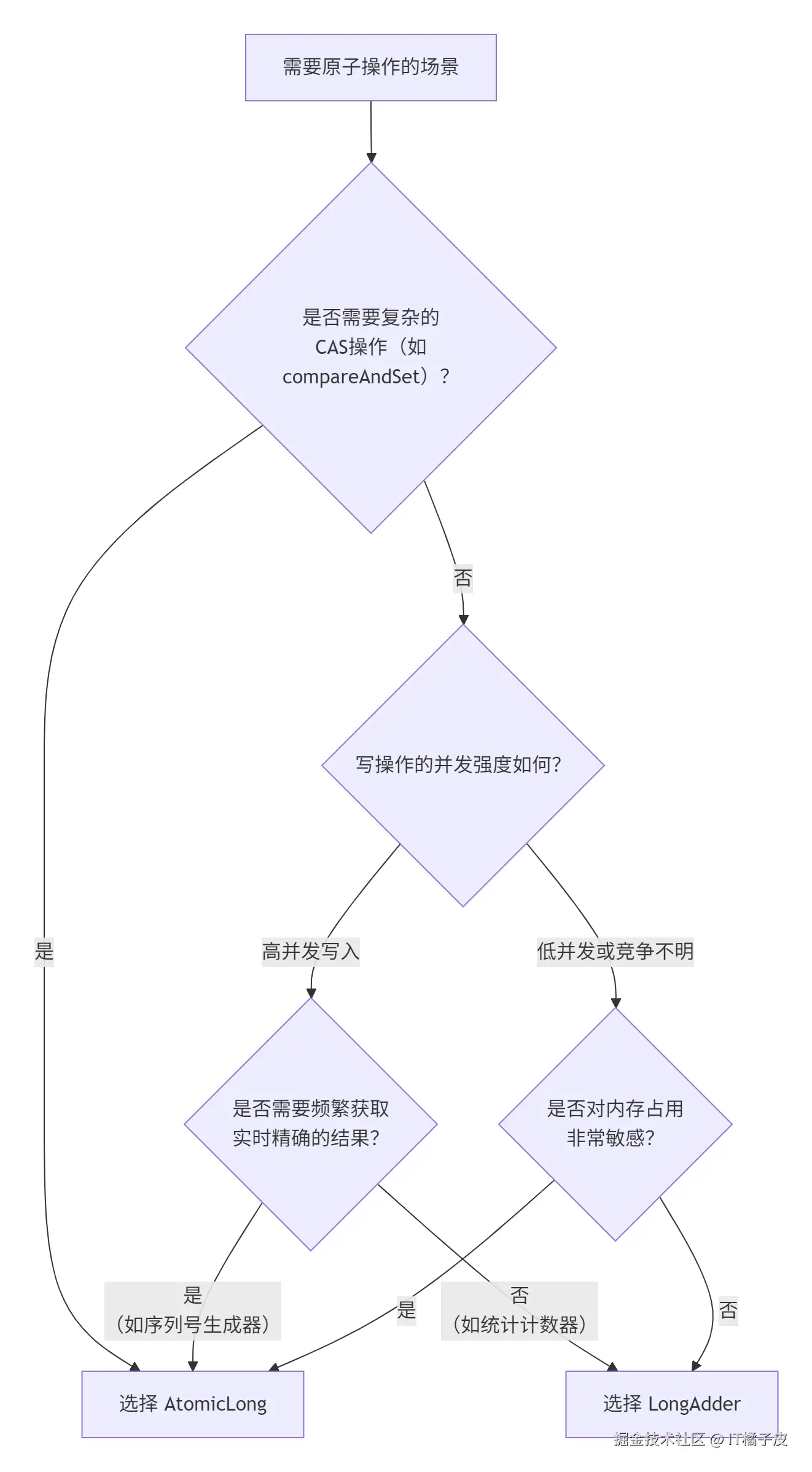 根据以上流程图,我们可以总结出更具体的选择建议:
根据以上流程图,我们可以总结出更具体的选择建议:
优先选择 AtomicLong的场景:
- 需要原子性比较和设置操作 :例如实现自旋锁、状态机等复杂逻辑,必须使用
AtomicLong的compareAndSet方法。 - 低并发环境且需要频繁、精确读取 :例如作为一个需要被频繁查询的全局序列生成器。此时
AtomicLong的简单性和读取高性能是最佳选择。 - 对内存占用非常敏感 :在资源受限的环境下,
AtomicLong的固定小内存占用更有优势。
优先选择 LongAdder的场景:
-
高并发写操作,对读的实时精确性要求不高 :这是
LongAdder的设计目标。典型场景包括:-
统计计数器:如统计接口的调用次数、成功/失败次数。
-
监控指标收集:如记录收到的消息数量、日志事件数量等。
这些场景下,写入极其频繁,但通常只需要定期(如每秒)获取一次汇总值进行展示或上报,短暂的延迟和近似精确是完全可接受的。
-
💎 总结
简单来说,这是一个典型的 权衡艺术 :LongAdder用 空间 和 实时精确性 换取了高并发写入下的 吞吐量 ;而 AtomicLong则保持了 简洁性 、实时精确性 和 更丰富的原子操作,但在极高并发写入时会成为性能瓶颈。