LLM 应用评估体系详解:从多轮对话到 RAG 与 AI Agent 的落地评估
一、引言
Agentic AI 的评估,核心是测试你的大语言模型(LLM)应用,确保其性能稳定。
这个话题或许不算最吸引人,但越来越多企业开始关注它。所以,搞清楚该跟踪哪些指标来实际衡量性能,很有必要。
另外,每次推送代码更新时,做好评估也能防止系统出问题。
因此,本文研究了多轮对话机器人、检索增强生成(RAG)和智能体(Agentic)应用的常见评估指标,还简要介绍了 DeepEval、RAGAS 和 OpenAI 的 Evals 库等框架,帮你明确不同场景下该选哪个工具。
二、传统评估方式(基础入门)
如果你熟悉自然语言处理(NLP)任务的评估方法,也了解公开基准测试的原理,可直接跳过这部分。
要是不熟悉,建议先了解准确率(Accuracy)、BLEU 等早期指标的用途和原理,以及 MMLU 这类公开基准测试的流程。
2.1 自然语言处理任务的评估
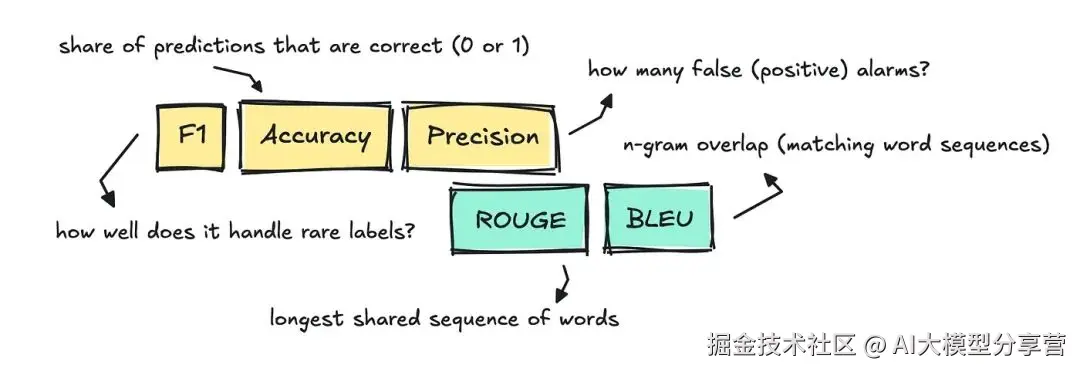
评估文本分类、翻译、摘要等传统 NLP 任务时,我们会用到准确率、精确率(Precision)、F1 分数、BLEU 和 ROUGE 等传统指标。
这些指标至今仍在使用,但主要适用于模型输出单一、易对比的 "正确答案" 的场景。
- 以文本分类为例,任务是给每个文本分配一个标签。此时可通过准确率评估 ------ 将模型分配的标签与评估数据集中的参考标签对比,判断是否正确。
- 评判标准很明确:标签错误得 0 分,正确得 1 分。
- 比如,用 1000 封邮件的垃圾邮件数据集训练分类器,若模型正确标记了 910 封,准确率就是 0.91。
- 文本分类中,我们还常使用 F1 分数、精确率和召回率(Recall)。
- 对于文本摘要、机器翻译这类 NLP 任务,人们常用 ROUGE 和 BLEU 指标,判断模型生成的译文或摘要与参考文本的吻合度。
- 这两个指标都会统计重叠的 n 元语法(n-grams),虽对比方向不同,但核心逻辑一致:共享的词语片段越多,分数越高。
- 不过这种评估方式比较简单 ------ 若模型输出用了不同措辞,分数就会偏低。
总体而言,这些传统指标在 "答案唯一" 的场景下效果最好,但对于如今我们搭建的 LLM 应用,大多不太适用。
2.2 大语言模型基准测试
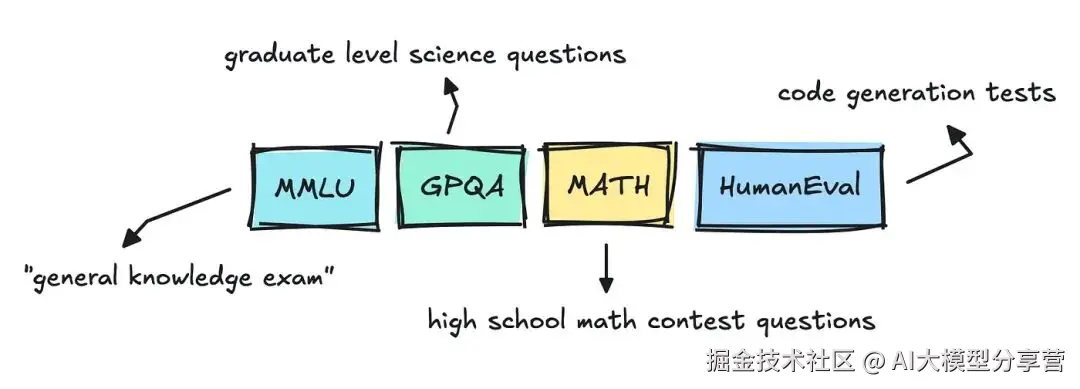
关注行业动态的话,你可能会发现:每次有新的大语言模型发布,都会进行 MMLU Pro、GPQA 或 Big-Bench 等基准测试。
这些属于通用评估,正确叫法是 "基准测试(Benchmark)",而非我们后续会讲的 "评估(Evals)"。
尽管每个模型还会接受毒性、幻觉、偏见等方面的评估,但最受关注的还是类似 "考试" 或 "排行榜" 的基准测试。
- MMLU 等数据集以选择题为主,出现已有一段时间。我曾浏览过该数据集,发现其中存在不少混乱之处。
- 有些问题和答案模糊不清,这让我猜测:LLM 提供商可能会针对这些数据集训练模型,确保模型能答对题目。
- 这也引发了公众的担忧:大多数 LLM 在基准测试中表现优异,可能只是过拟合导致;因此,我们需要更新的数据集和独立的评估方式。
2.3 大语言模型评分器(LLM-as-a-judge)
评估这些数据集时,通常可以用准确率和单元测试。但现在有个新变化 ------ 出现了 "大语言模型评分器(LLM-as-a-judge)"。
-
基准测试模型时,团队大多仍用传统方法。只要是选择题或答案唯一的场景,无需其他操作,只需将模型答案与参考答案对比,判断是否完全匹配即可。
- MMLU、GPQA 等含选择题答案的数据集,就属于这种情况。
- 对于代码测试(如 HumanEval、SWE-Bench),评分器只需运行模型生成的补丁或函数:所有测试通过,即视为问题解决;反之则未解决。
但可想而知,若问题模糊或属于开放式问题,答案就可能不稳定。这种漏洞催生了 "LLM-as-a-judge"------ 用 GPT-4 这类大语言模型对答案打分。
- MT-Bench 是采用 LLM 作为评分器的基准测试之一:它将两个竞争的多轮对话答案输入 GPT-4,让其判断哪个更好。
- 原本依赖人工评分的 "聊天机器人竞技场(Chatbot Arena)",如今似乎也通过引入 LLM-as-a-judge 来扩大规模。
为保证透明度,也可使用 BERTScore 等语义评估工具,对比语义相似度。为简洁起见,这里就不详细展开现有工具了。
综上,团队可能仍会用 BLEU、ROUGE 等重叠指标进行快速合理性检查,或在可能的情况下依赖完全匹配解析,但如今的新趋势是用另一个大语言模型来评判输出结果。
三、大语言模型应用的评估方法
现在的核心变化是:我们不再只测试 LLM 本身,而是测试整个系统。
只要条件允许,我们仍会像以前一样用程序化方法评估。
对于更细微的输出,我们可以先通过 BLEU、ROUGE 这类低成本、确定性的指标查看 n 元语法重叠情况,但如今大多数现代框架都会用 LLM 评分器进行评估。
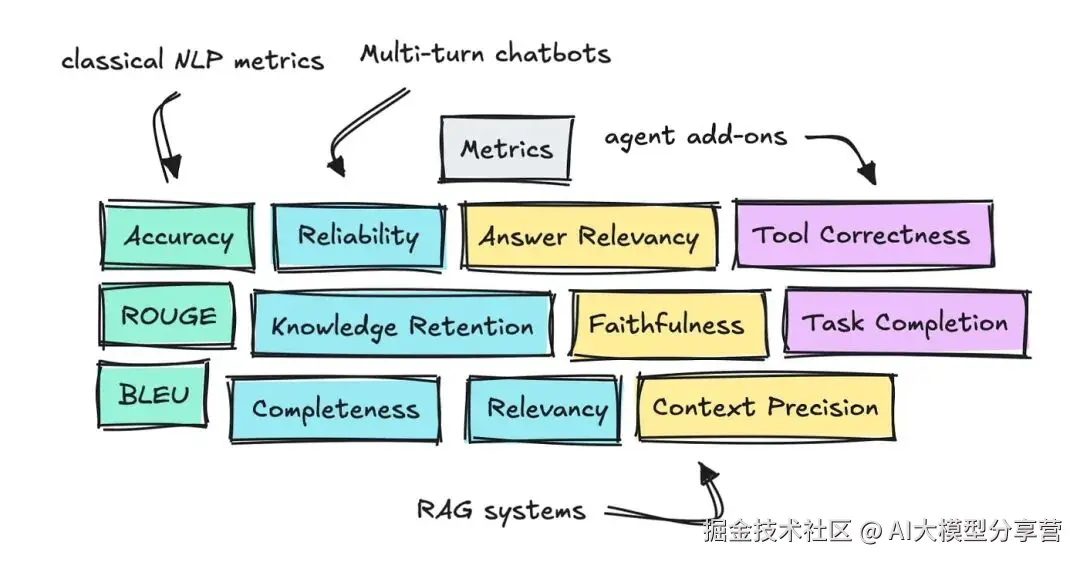
有三个领域值得探讨:多轮对话、RAG 和智能体(Agent)的评估方法及相关指标。
你可以看到,这三个领域已定义的指标数量非常多。
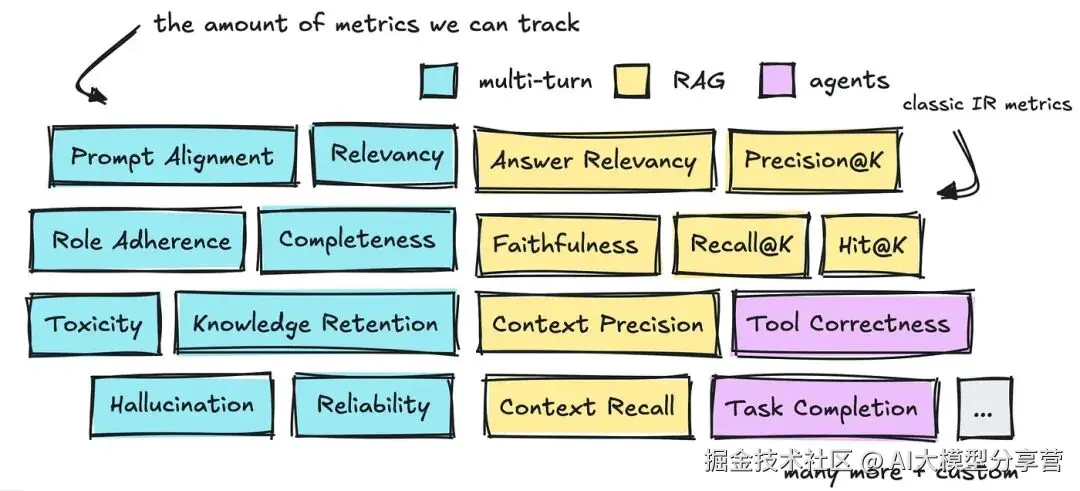
接下来,我们先简要介绍这些指标,再讲解能提供帮助的各类框架。
3.1 多轮对话评估
首先要讲的是多轮对话(常见于聊天机器人)的评估搭建方法。
我们与聊天机器人互动时,希望对话自然、专业,机器人能记住关键信息,全程不偏离主题,且能准确回答问题。
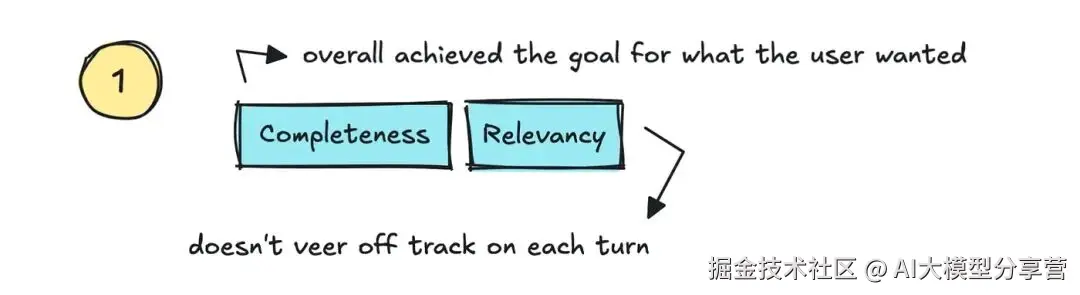
目前有不少常用指标可跟踪,首先来看 "相关性 / 连贯性(Relevancy/Coherence)" 和 "完整性(Completeness)"。
-
相关性:用于跟踪 LLM 是否恰当回应用户查询、不偏离主题;
-
完整性:若最终结果能满足用户需求,则该指标得分高。
也就是说,只要能跟踪整个对话过程中的用户满意度,我们就能进一步跟踪对话是否真的 "降低了支持成本"、"提升了信任度",以及是否 "提高了自助服务率"。
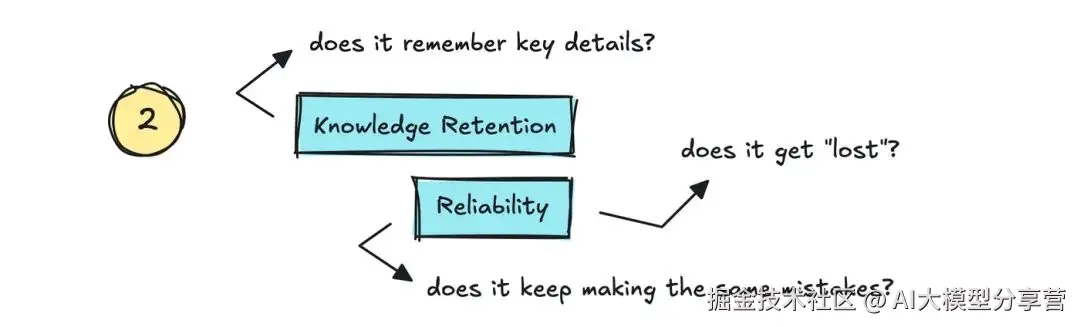
其次是 "知识留存(Knowledge Retention)" 和 "可靠性(Reliability)"。
-
知识留存:机器人是否记住对话中的关键细节;
-
可靠性:能否确保机器人不 "混乱"------ 不仅要记住细节,还要能自我修正。
在 "氛围编码工具(vibe coding tools)" 中,我们常会遇到机器人忘记之前犯的错误、反复出错的情况,这种情况就可判定为 "可靠性(或稳定性)低"。
第三是 "角色一致性(Role Adherence)" 和 "提示对齐(Prompt Alignment)"。
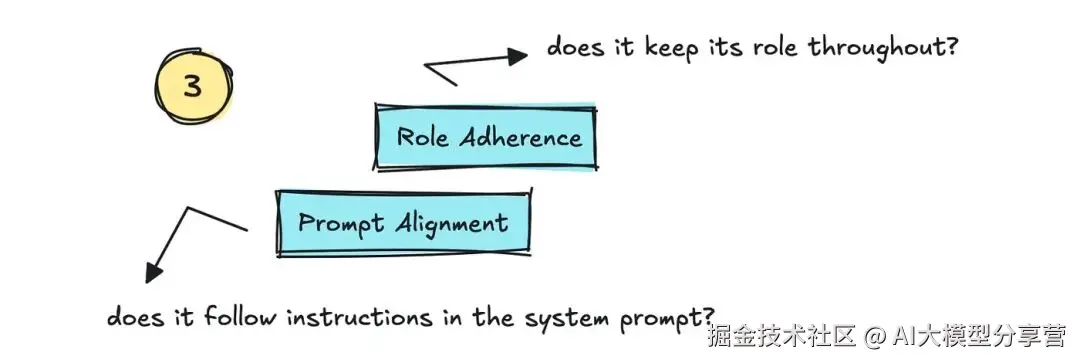
- 这两个指标用于跟踪 LLM 是否坚守给定角色,以及是否遵循系统提示中的指令。
接下来是与安全性相关的指标,如 "幻觉(Hallucination)" 和 "偏见 / 毒性(Bias/Toxicity)"。
- 幻觉:该指标很重要,但评估难度较大。有人会尝试通过网页搜索验证输出,也有人会将输出拆分为不同断言,用更大规模的模型(LLM-as-a-judge 模式)评估。
- 还有其他方法,比如 SelfCheckGPT------ 对同一提示多次调用模型,查看模型是否坚持最初答案、偏离次数多少,以此判断一致性。
- 偏见 / 毒性:可通过其他 NLP 方法评估,例如用微调后的分类器。
此外,你可能还需要跟踪一些应用定制化指标,比如代码正确性、安全漏洞、JSON 格式正确性等。
至于评估方式,并非一定要用 LLM,但多数情况下,标准解决方案都会采用 LLM。
如果能提取出正确答案(如解析 JSON),自然无需使用 LLM。正如之前所说,许多 LLM 提供商在评估代码相关指标时,也会用单元测试。
需要说明的是:用于评判的 LLM 并非总是绝对可靠,就像它们所评估的应用一样。但目前我没有相关数据支持这一点,你需要自行调研。
3.2 检索增强生成(RAG)评估
在多轮对话评估的基础上,我们再来看看 RAG 系统需要衡量哪些指标。
评估 RAG 系统时,需将流程拆分为两部分:分别衡量检索(Retrieval)和生成(Generation)的指标。
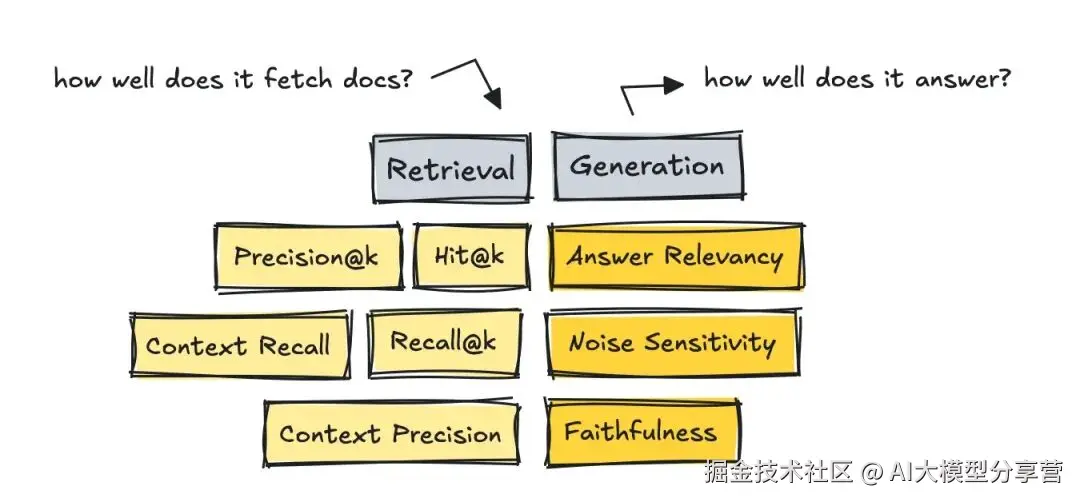
3.2.1 检索环节评估
首先要评估检索环节:获取的文档是否与查询匹配。
如果检索环节得分低,可通过以下方式优化系统:
- 制定更优的分块策略;
- 更换嵌入模型(Embedding Model);
- 加入混合搜索、重排序等技术;
- 用元数据过滤等。
评估检索效果,既可以用依赖精选数据集的传统指标,也可以用基于 LLM-as-a-judge 的无参考方法。
- 先说说经典的信息检索(IR)指标,它们是最早出现的检索评估指标。使用这些指标需要 "黄金答案(Gold Answers)"------ 即针对某个查询,对每个文档进行排序。
-
虽然可以用 LLM 构建这类数据集,但评估时无需 LLM,因为数据集中已有可对比的分数。
-
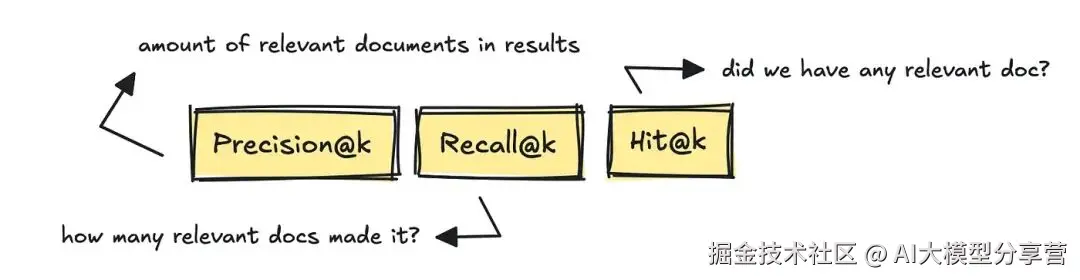
最知名的 IR 指标包括 Precision@k(前 k 个结果的精确率)、Recall@k(前 k 个结果的召回率)和 Hit@k(前 k 个结果中是否有相关文档)。
-
这些指标分别衡量:获取的相关文档数量、基于黄金参考答案检索到的相关文档数量,以及结果中是否至少包含一个相关文档。
- 而 RAGAS、DeepEval 等较新的框架,则引入了无参考、LLM 评分式的指标,如 Context Recall(上下文召回率)和 Context Precision(上下文精确率)。
- 这些指标通过 LLM 判断:基于查询,前 K 个结果中是否包含真正相关的文本块。
- 简单来说,就是判断系统是否返回了与查询相关的文档,或者是否包含过多无关文档,导致无法正确回答问题。
构建检索评估数据集的方法有两种:
- 从真实日志中挖掘问题,再由人工整理;
- 借助 LLM 使用数据集生成器 ------ 多数框架中都有这类工具,也有 YourBench 这样的独立工具。
若你想基于 LLM 搭建自己的数据集生成器,可参考以下示例:
code-snippet__js
# 生成问题的提示语
qa_generate_prompt_tmpl = """
以下是上下文信息。
---------------------
{context_str}
---------------------
根据上述上下文信息,且不依赖任何先验知识,
基于上述上下文生成{num}个问题和{num}个答案。...
"""3.2.2 生成环节评估
再来看 RAG 系统的生成环节:评估模型能否利用提供的文档准确回答问题。
如果该环节表现不佳,可通过以下方式调整:
- 优化提示词(Prompt);
- 调整模型参数(如温度系数 temperature);
- 更换模型;
- 针对特定领域知识微调模型;
- 强制模型通过思维链(CoT)模式推理;
- 检查模型的自我一致性等。
评估生成环节时,RAGAS 框架的指标很实用,包括 Answer Relevancy(答案相关性)、Faithfulness(忠诚度)和 Noise Sensitivity(噪声敏感度)。
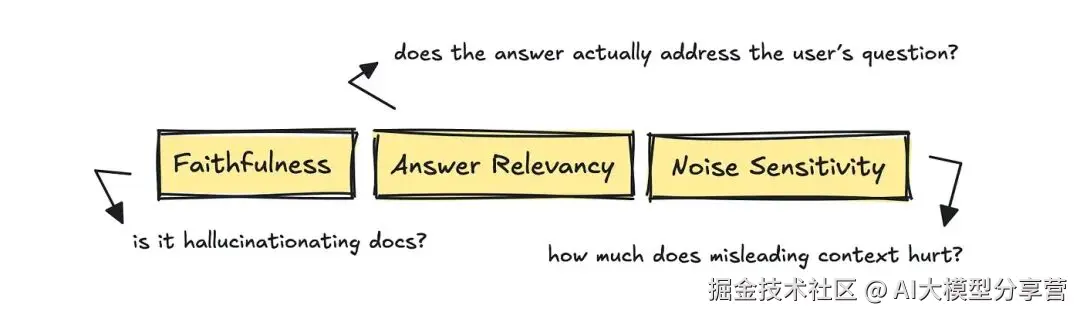
- 答案相关性:判断答案是否真正回应了用户问题;
- 忠诚度:判断答案中的每个断言是否都有检索到的文档支持;
- 噪声敏感度:判断少量无关上下文是否会导致模型输出偏离正确方向。
以 RAGAS 为例,其评估第一个指标(答案相关性)的方式可能是:将问题、答案和检索到的上下文输入 LLM,让 LLM 按 0-1 分打分,"1 分" 表示答案完全贴合问题,最终可根据原始分数计算平均值。
综上,评估 RAG 系统需将其拆分为检索和生成两个环节。既可以用基于 IR 指标的方法,也可以用基于 LLM 评分的无参考方法。
3.3 智能体(Agent)评估
最后要讲的是智能体评估 ------ 除了上述提到的输出、对话和上下文评估,智能体还扩展了新的评估指标。
评估智能体时,我们不仅关注输出、对话和上下文,还要评估它的 "行动能力":
- 能否完成任务或流程;
- 完成效率如何;
- 是否能在合适的时机调用正确的工具。
不同框架对这些指标的命名可能不同,但核心要跟踪的两个指标是 Task Completion(任务完成度)和 Tool Correctness(工具正确性)。
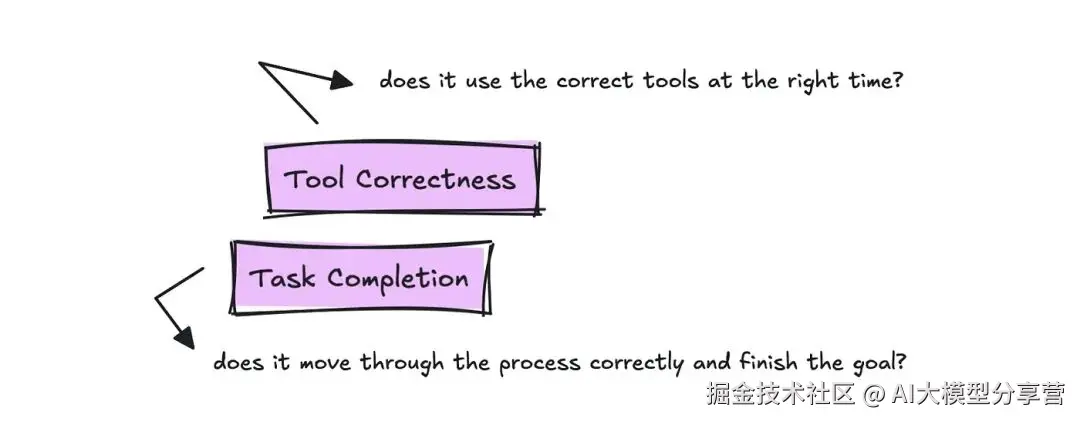
- 工具正确性:评估智能体是否为用户查询调用了正确的工具。
- 测试时需要内置包含真值的 "黄金脚本(Gold Script)",但只需编写一次,后续每次修改系统后都可复用。
- 任务完成度:评估时需查看完整的操作轨迹和目标,按 0-1 分打分并给出理由,以此衡量智能体完成任务的效果。
此外,根据智能体的具体应用场景,可能还需要测试前面提到的其他指标。
需要注意的是:尽管已有不少定义好的指标,但不同应用场景需求不同。了解常见指标很有必要,但不要默认它们就是最适合你应用的评估指标。
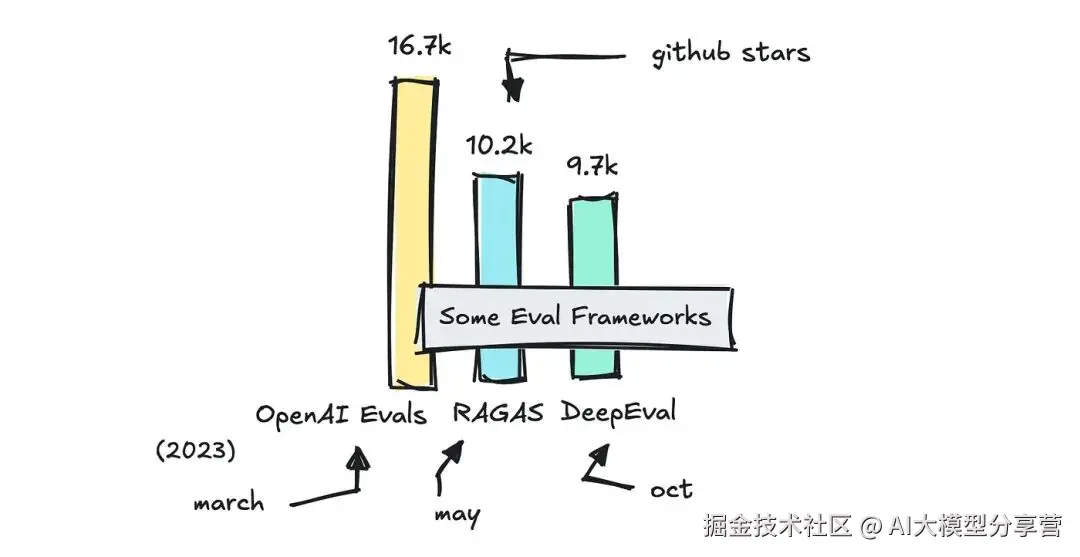
四、实用评估框架推荐
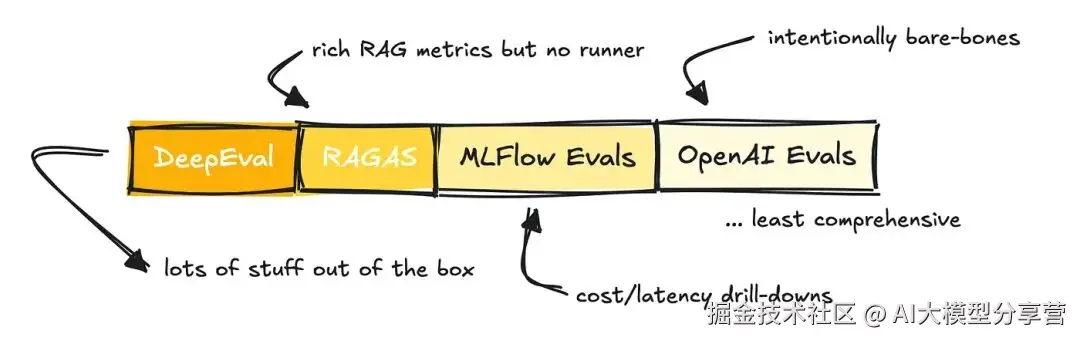
目前有很多框架可辅助评估工作,本文重点介绍几个常用框架:RAGAS、DeepEval、OpenAI 的 Evals 库和 MLFlow 的 Evals 库,分析它们的优势和适用场景。
你可以在这个代码仓库中找到我整理的所有评估框架列表。
此外,也可以使用一些框架专属的评估系统(如 LlamaIndex),尤其适合快速原型开发。
-
OpenAI 和 MLFlow 的 Evals 更偏向 "附加工具",而非独立框架;
-
RAGAS 主要定位为 RAG 应用的指标库(不过也提供其他指标);
-
DeepEval 可能是所有框架中功能最全面的评估库。
但需要说明的是,这些框架都具备以下功能:
- 支持在自定义数据集上运行评估;
- 可用于多轮对话、RAG 和智能体评估;
- 支持 LLM-as-a-judge;
- 允许设置自定义指标;
- 兼容持续集成(CI)流程。
正如前面提到的,它们的区别主要在功能全面性上:
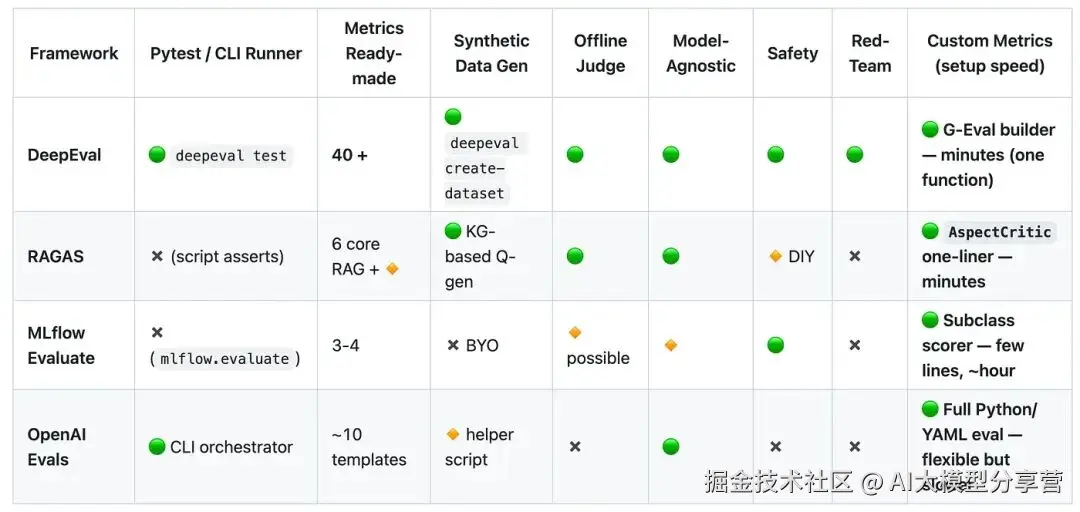
- MLFlow 最初是为评估传统机器学习管道设计的,因此针对 LLM 应用的指标数量较少;
- OpenAI 的 Evals 框架非常轻量化,需要用户自行设置指标,不过它提供了示例库帮助入门;
- RAGAS 提供了不少指标,且可与 LangChain 集成,方便运行;
- DeepEval 内置功能丰富,甚至包含了 RAGAS 的指标。
你可以在这个 GitHub 仓库中查看上述框架的指标对比表。
观察这些框架提供的指标,能大致了解它们的功能覆盖范围。
需要注意的是:提供指标的框架在命名上往往没有统一标准 ------ 不同框架中名称不同的指标,实际含义可能一致。
例如:
- 一个框架中的 "忠诚度(Faithfulness)",可能和另一个框架中的 " groundedness(扎根性)" 含义相同;
- "答案相关性(Answer Relevancy)" 可能等同于 "响应相关性(Response Relevance)"。
这种命名混乱给系统评估带来了不必要的麻烦和复杂性。
不过,DeepEval 的优势很突出:它提供了 40 多种指标,还推出了 G-Eval 框架,可帮助快速搭建自定义指标,是从 "想法" 到 "可运行指标" 最快的工具。
OpenAI 的 Evals 框架则更适合需要定制逻辑的场景,而非快速评估需求。
据 DeepEval 团队介绍,自定义指标是开发者最常搭建的功能。因此,不必纠结于 "哪个框架提供了什么指标"------ 你的应用场景是独特的,评估方式也应如此。
那么,不同场景该如何选择框架呢?
- 若需要针对 RAG 管道的专用指标,且希望最小化配置工作,选 RAGAS;
- 若需要功能全面、开箱即用的评估套件,选 DeepEval;
- 若已在使用 MLFlow,或偏好内置跟踪和 UI 功能,MLFlow 是不错的选择;
- 若依赖 OpenAI 基础设施,且需要灵活性,OpenAI 的 Evals 框架(尽管最精简)更合适。
此外,DeepEval 还通过其 DeepTeam 框架提供 "红队测试(Red Teaming)" 功能,可自动对 LLM 系统进行对抗性测试。其他框架也有类似功能,但可能不如 DeepEval 全面。
未来,我计划专门探讨 LLM 系统的对抗性测试和提示词注入问题 ------ 这是个很有意思的话题。
五、注意事项
数据集相关业务利润丰厚,因此现在我们能够用其他 LLM 标注数据或为测试打分,这是一个很好的发展阶段。
但 LLM 评分器并非 "万能工具",你搭建的评估体系可能会像其他 LLM 应用一样,存在不稳定问题。据网络信息显示,大多数团队和企业会每几周进行一次人工抽样审核,以确保评估的真实性。
你为应用搭建的指标很可能是定制化的,尽管本文介绍了不少通用指标,但最终你或许还是需要自行开发适合自己的评估指标。
不过,了解这些标准指标仍非常有必要。
希望本文能为你提供有价值的参考实现。
好了,这就是我今天想分享的内容。如果你对构建 AI 大模型应用新架构设计和落地实践感兴趣,别忘了点赞、关注噢~