随着ChatGPT、文心一言等大语言模型(LLM)的爆发,AI的能力边界被不断拓宽。然而,当企业试图将这些"通才"模型应用到垂直领域或私有业务中时,往往会遭遇"水土不服"。
如何在不进行昂贵模型训练的前提下,让大模型"懂业务"、"懂私有数据"?RAG(Retrieval Augmented Generation,检索增强生成) 应运而生,成为了当前解决这一问题的最佳实践方案。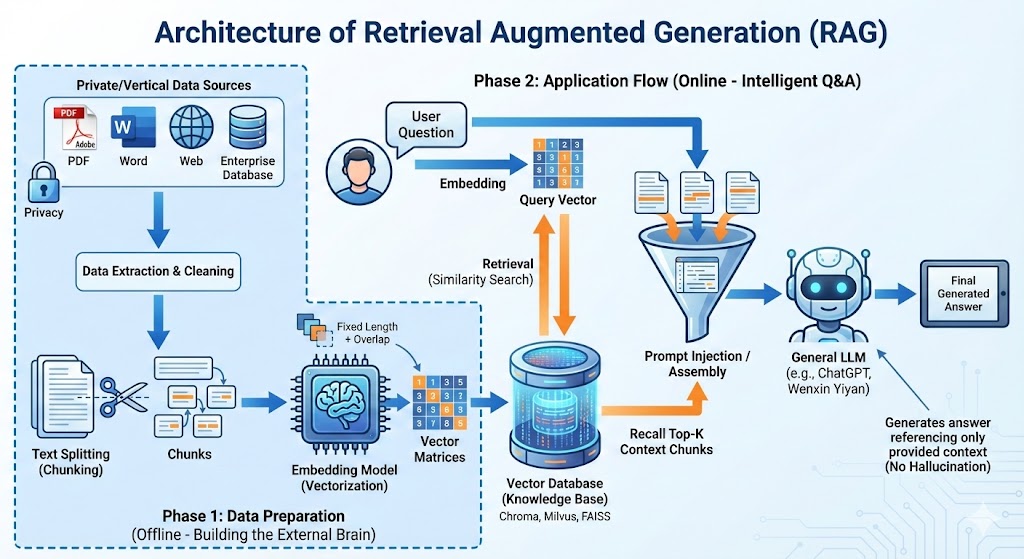
一、 为什么我们需要RAG?
通用的基础大模型虽然强大,但在实际落地时面临三大核心痛点:
-
知识的局限性(Knowledge Cutoff):
大模型的知识完全来源于其训练数据。对于实时新闻、非公开的企业内部文档或训练截止日期之后产生的数据,大模型一无所知。
-
幻觉问题(Hallucination):
大模型的本质是概率预测。当它遇到盲区或不擅长的领域时,倾向于"一本正经地胡说八道",这种不可控的错误在医疗、金融等严谨场景下是致命的。
-
数据安全性(Data Privacy):
没有企业愿意将核心的私域数据(如财务报表、技术图纸)上传到第三方平台进行模型训练,数据隐私成为了企业应用大模型的最大拦路虎。
RAG正是为了解决上述矛盾而生。它不需要让模型"重新学习",而是通过"外挂知识库"的方式,让模型在回答问题前先去查阅资料。
二、 什么是RAG?
RAG(Retrieval Augmented Generation)的核心逻辑可以简化为公式:RAG = 检索(Retrieval) + 生成(Generation)。
它的工作原理类似于一场"开卷考试":当用户提问时,系统不是直接让大模型凭空作答,而是先在本地的知识库中检索相关信息,然后将这些信息连同问题一起交给大模型,让大模型"参考"这些资料生成答案。
三、 RAG的核心架构拆解
一个标准的RAG应用流程包含两个主要阶段:数据准备阶段(离线) 和 应用阶段(在线)。
1. 数据准备阶段(构建外挂大脑)
这是RAG的地基,主要目的是将非结构化的私域数据转化为计算机可高效检索的形式。
-
数据提取(Data Extraction):
从PDF、Word、网页等不同源头获取数据,并进行清洗、过滤和格式统一。同时提取关键的元数据(如时间、文件名)。
-
文本分割(Text Splitting):
由于Embedding模型有Token限制,且过长的文本会稀释语义,需要将长文档切分为小的"知识块(Chunk)"。
-
句分割: 保证句子语义完整。
-
固定长度分割: 如每256或512个Token切分,通常会在头尾增加冗余重叠(Overlap)以保持上下文连贯。
-
-
向量化(Embedding):
这是最关键的一步。将文本"翻译"成计算机能理解的向量矩阵。常用的Embedding模型包括:
-
OpenAI/ChatGPT-Embedding: 效果好但需调用接口。
-
M3E/BGE: 强大的开源模型,支持私有化部署和微调,适合中文场景。
-
-
数据入库:
将向量化后的数据存入向量数据库(如Chroma, Milvus, FAISS, ES),建立索引以便快速检索。
2. 应用阶段(智能问答)
当用户发起提问时,系统执行以下流程:
-
用户提问: 接收自然语言问题。
-
数据检索(Retrieval):
将用户的问题也进行向量化,然后在数据库中计算它与存储的知识块的相似度(如余弦相似度),召回得分最高的Top-K个片段。
- 进阶策略: 可结合"全文检索(关键词匹配)"与"向量检索"的混合模式,提升召回率。
-
Prompt注入:
将召回的背景知识(Context)与用户问题(Question)按照特定的模板组装成Prompt。
-
LLM生成:
大模型根据Prompt中的限制条件(如"仅根据背景知识回答"),生成最终答案。
四、 实战案例:打造"藜麦"知识专家
为了更直观地理解RAG,我们以一份关于"藜麦"的百度百科数据为例,使用LangChain框架搭建一个私域知识问答助手。
核心技术栈
-
框架: LangChain
-
LLM: 文心一言(Ernie-Bot)
-
Embedding: moka-ai/m3e-base(开源模型)
-
向量数据库: Chroma
实现步骤概览
-
加载数据: 读取本地的《藜.txt》文档。
-
切分文档: 使用
CharacterTextSplitter将文档按128字符长度进行切分,确保每个切片包含独立且集中的信息。 -
向量化存储: 调用M3E模型将切片转为向量,存入Chroma数据库。
-
Prompt设计:
Plaintext
【任务描述】请根据背景知识回答,禁止使用常识。 【背景知识】{{context}} 【问题】{question} -
检索与问答:
-
用户问:"藜怎么防治虫害?"
-
系统检索出数据库中关于"辛硫磷颗粒剂"、"象甲虫"等相关段落。
-
大模型结合这些段落,输出具体的防治方案(如用药量、施用方法),而不是泛泛而谈。
-
-
多轮对话支持:
利用ConversationalRetrievalChain,系统能记录chat_history。当用户进行追问时,系统会先结合历史上下文重写问题,再进行检索,从而实现流畅的对话体验。
五、 总结
RAG技术完美地平衡了成本、效果与隐私。它让大模型从"全知全能但有时胡扯"的通用与创意工具,转型为"严谨可靠"的业务专家。
对于希望拥抱AI的企业而言,RAG不仅仅是一种技术架构,更是低成本撬动大模型业务价值的杠杆。 只要掌握了数据提取、向量化和检索这三把钥匙,任何企业都能构建出属于自己的"超级大脑"。