作者:郑前祎(乾以)
在日志场景,向量索引的成本和吞吐挑战
在语义索引中,Embedding 是决定语义召回率的关键因素;在整个语义索引的处理流程中,Embedding 也是整个链路的核心成本所在 。Embedding 1GB 数据的成本可能在数百元 ,速度最大只有 100kb/s 左右,索引构建和存储成本与之相比都显得微不足道。Embedding 模型在 GPU 上的推理效率直接决定了语义索引的构建速度和整体成本。
对于知识库场景,这个成本也许可以接受,因为知识库是静态,不经常更新的。而对于 SLS 的流数据而言,数据源源不断产生,对成本和速度提出了极大的挑战。数百元的成本和 100kb 的速度,难以投入生产。
为了优化大规模应用场景下的性能和成本压力,我们针对 Embedding 服务的推理瓶颈进行了系统性优化。通过深入分析、方案选择与定制优化,最终实现了吞吐量提升 16 倍,同时显著降低了单位请求的资源成本。
技术上的挑战与优化思路
要实现 Embedding 服务的极致性价比,需要解决以下几个关键挑战:
-
推理框架:
- 市场上存在多种推理框架(vLLM, sglang, llama.cpp, TensorRT, sentence-transformers 等),各有侧重(通用/专用,CPU/GPU)。如何选择最适合 Embedding 任务、并能最大化发挥硬件(尤其 GPU)性能的框架是关键。
- 框架本身的计算效率(连续批处理、Kernel 优化等)也会是 embedding 模型推理性能瓶颈。
-
最大化 GPU 利用率:这是降低成本的核心。GPU 是如此的昂贵,如果不能把 GPU 的使用率搞上去,就是浪费,这和 CPU 时代的程序存在明显差别。
- 批量处理:Embedding 推理对批量处理极其敏感,单条请求处理效率远低于批量。需要高效的请求攒批机制。
- 并行处理:需将 CPU 预处理(如 Tokenization)、网络 I/O 与 GPU 计算充分解耦并行,避免 GPU 空闲等待。
- 多模型副本:与大参数量的 Chat 模型不同,常见 Embedding 模型参数量相对较小,单副本在单张 A10 GPU上可能仅占用 15% 的算力和 13% 的显存。如何在单张 GPU 卡上高效部署多个模型副本,以"填满" GPU 资源是降低成本和提升吞吐量的关键。
-
优先级调度:
- 语义索引包含索引构建(大批量、低优先级)和在线查询(小批量、高实时性)两个阶段。必须确保查询请求的 embedding 任务不被构建任务阻塞。简单的资源池隔离不够灵活,需要精细化的优先级队列调度机制。
-
E2E链路中的短板:
- 当 GPU 利用率提升后,其他环节(如 Tokenization)容易成为新的瓶颈点。
方案
最终我们实现了如下优化方案:

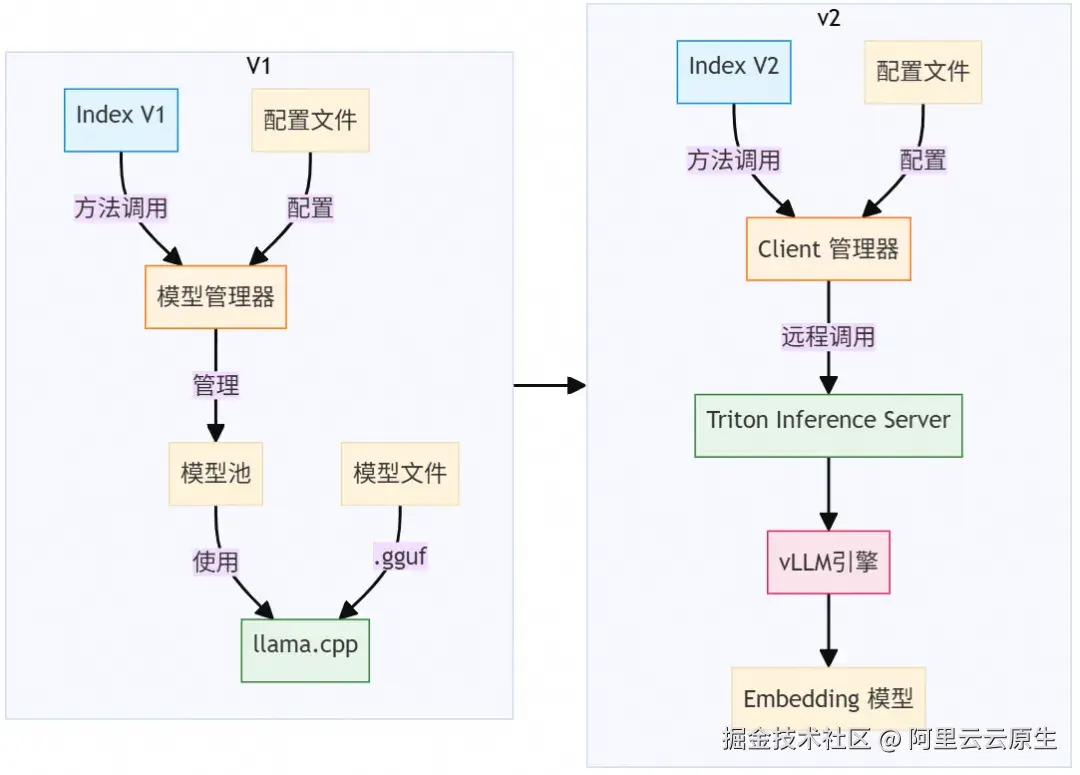
优化点 1:选定 vLLM 作为核心推理引擎 (替换 llama.cpp)
我们最初选择 llama.cpp 主要考虑其 C++ 高性能、CPU 友好性(我们部分任务在 CPU 节点运行)以及易于集成。然而,最近的测试结果表明,在相同硬件上,vLLM 和 sglang 的吞吐量是 llama.cpp 的 2 倍,同时 GPU 平均利用率低 60%。我们认为其核心差距可能源于 vLLM 的 Continuous Batching(连续批处理)和高度优化的 CUDA Kernels。
最终我们将 Embedding 作为独立服务分离出来。向量构建和查询均通过远程调用获取 Embedding。虽然引入了网络开销和额外的服务运维成本,但获得了显著的基础性能提升,为后续优化奠定了基础。
优化点 2:单卡部署多模型副本
为了提供 GPU 利用率,我们需要在单张 A10 GPU 上部署多个模型副本。经过多个方案的对比,最终选择采用 Triton Inference Server 作为服务框架。能够轻松控制单卡上的模型副本数量,并利用其 调度与动态批处理 (Dynamic Batching) 能力,将请求路由到不同副本。(同时我们绕过 vLLM HTTP Server:直接在 Triton 的 Python Backend 中调用 vllm 核心库 (LLMEngine),减少一层开销。)
优化点 3:解耦 Tokenization 与模型推理
我们发现在多副本 vLLM 下,GPU 吞吐提升后,Tokenization 阶段成为了新的性能瓶颈。同时我们的测试表明 llama.cpp 的 Tokenization 吞吐量是 vLLM 的 6 倍。所以我们的将 Tokenization 阶段和推理阶段分离。使用 llama.cpp 进行高性能 Tokenization,然后将 Token IDs 输入给 vLLM 。成功规避了 vLLM Tokenizer 的性能瓶颈,进一步提升端到端吞吐。当我们做完这个优化后,也看到 snowflake 发了一篇文章做了同样的优化,说明这是一个普遍性的问题,我们也在积极推动 vLLM 社区版能够解决这个问题。
优化点 4:优先级队列与动态批处理
Triton Inference Server 内置了优先级队列(Priority Queuing) 机制和动态批处理机制,非常契合embedding 服务的需求。查询时的 embedding 请求,使用更高的优先级,降低查询延迟。同时也使用动态批处理策略,对请求进行攒批,提升整体吞吐效率。
最终架构设计
在突破 embedding 的性能瓶颈之后,对整个语义索引框架进行改造也是非常必要的。需要转为调用远程 embedding 服务,并实现数据读取、chunking、Embedding 请求、结果处理/存储等环节的充分异步和并行。
embedding 调用
在之前的架构中,直接调用嵌入的 llama cpp 引擎进行 embedding。而在新架构中,通过发起远程调用来进行 embedding。
充分异步和并行
在旧的架构中,数据解析 -> chunking -> embedding 是完全串行的,无法将 GPU 上的 embedding 服务负载打满。我们设计了充分异步和并行的新的代码架构,将网络 IO/CPU/GPU 高效利用起来。
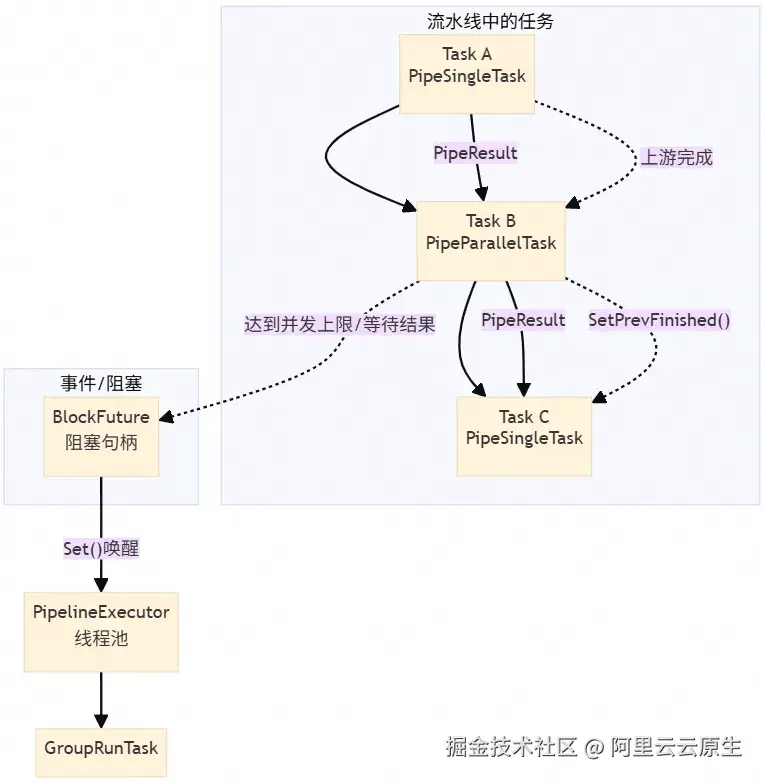
1. 流水线任务编排
我们将语义索引的构建流程切分为多个 Task,并且将这些 Task 构建为 DAG 执行。不同的 Task 之间可以异步和并行执行,一个 Task 内部也可以并行执行:
DeserializeDataTask → ChunkingTask(并行) → GenerateBatchTask → EmbeddingTask(并行)→ CollectEmbeddingResultTask → BuildIndexTask → SerializeTask → FinishTask
2. Pipeline 调度框架
为了高效执行流水线 Task,我们还实现了以数据和事件驱动的调度框架。
3. 全新的构建流程
通过全面的代码改造,我们实现了架构设计上的飞跃,实现了高性能的语义索引构建。

结语:吞吐升,成本降
在充分的流水线化改造后,经过测试:
- 吞吐从 170kb/s 提升到了 3M/s。
- 最终,SLS 提供的向量索引,定价在 0.01/百万 token,相比业界的解决方案有两个数量级的费用优势。
最后,欢迎使用 SLS 的向量索引,请参考使用文档:help.aliyun.com/zh/sls/vect...