Zookeeper分布式锁:从原理到实战

【流程图】
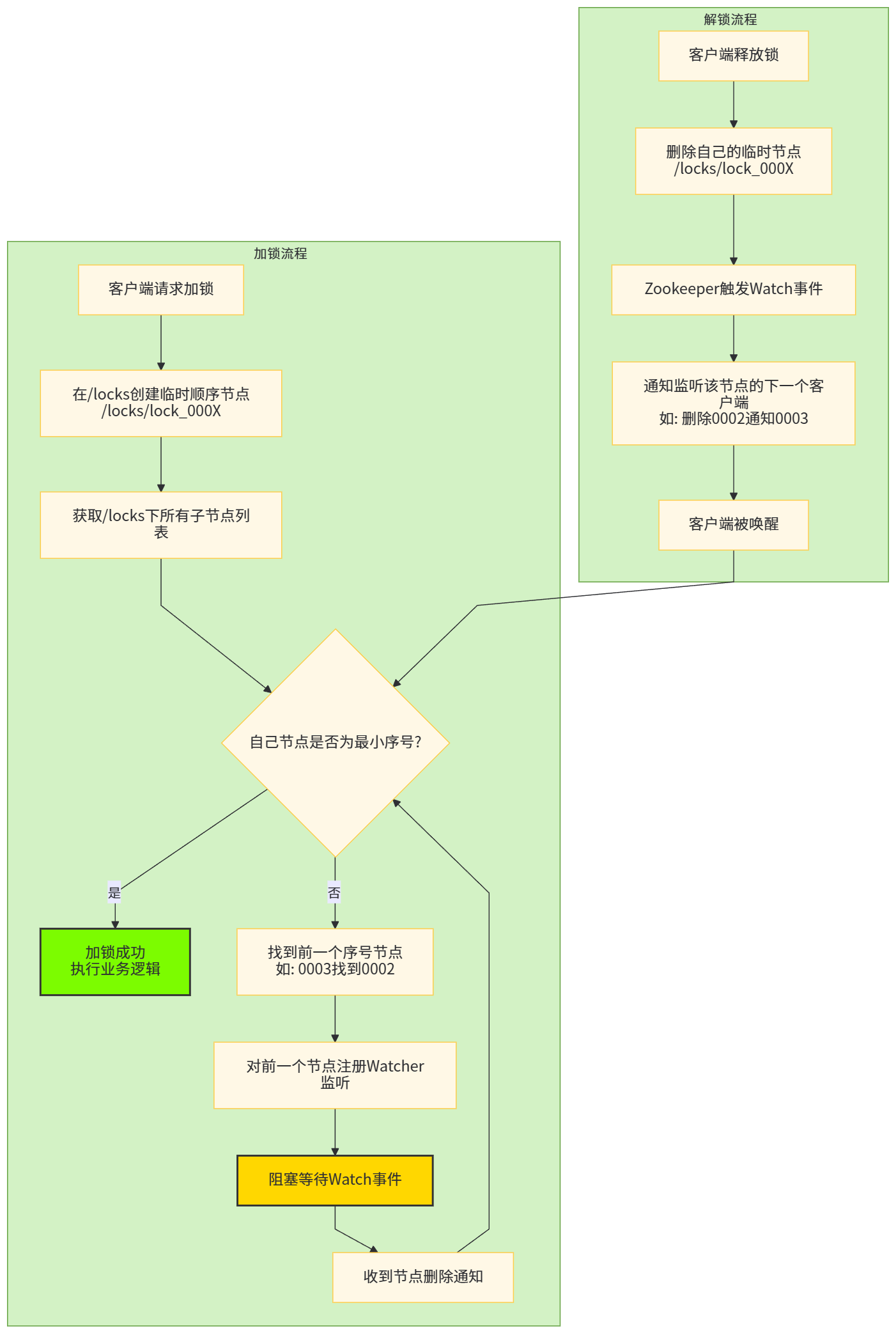
流程图关键解读
① 加锁流程(左半部分)
创建节点 :所有客户端在/locks目录下创建临时顺序节点 (如lock_0001、lock_0002)
核心判断 :获取子节点列表后,检查自己是否持有最小序号
- 是:加锁成功,直接进入临界区
- 否 :找到前一个节点 (如
0003的前一个是0002),并对其注册监听
高效等待 :利用ZK的Watch机制 阻塞,不轮询,CPU占用为0,避免"羊群效应"
② 解锁流程(右半部分)
释放锁 :客户端主动调用delete或会话超时,ZK自动删除临时节点
精准唤醒 :只通知监听该节点的下一个客户端 (如删除0002只唤醒0003)
- 性能从O(n)唤醒优化为O(1)唤醒
- 例如:1000个等待者,只唤醒1个
③ 核心设计优势
| 机制 | 作用 |
|---|---|
| 临时节点 | 客户端宕机自动释放,天然防死锁 |
| 顺序节点 | 自动排队,公平锁保证先到先得 |
| Watch监听 | 事件驱动,实时唤醒,无延迟 |
| 监听前一节点 | 避免惊群效应,性能极高 |
④ 对比Redis锁的差异
- Redis锁 :需要轮询 或Pub/Sub,延迟高(50-100ms),有惊群风险
- ZK锁 :事件通知,延迟低(<10ms),精准唤醒
一句话总结 :ZK通过临时顺序节点 + Watch监听 实现了公平、高效、自动续期 的分布式锁,是CP系统的典型代表,适用于对一致性要求极高的金融场景。
一、核心机制:临时顺序节点
Zookeeper通过四种节点类型 实现分布式协调,分布式锁依赖的是临时顺序节点(EPHEMERAL_SEQUENTIAL):
java
// 创建命令示例
create -e -s /locks/lock_ // -e:临时节点 -s:顺序节点
// 返回结果:/locks/lock_0000000001关键特性:
- 临时性 :客户端断开连接(session超时),节点自动删除 → 天然防死锁
- 顺序性:节点名后缀自动递增序号 → 实现公平锁
- 监听机制:可监听子节点变化 → 实现阻塞唤醒
二、加锁流程实战分析
假设3个客户端(A、B、C)竞争同一把锁:
Step 1:所有客户端创建临时顺序节点
/locks/
├── lock_0000000001 (客户端A创建)
├── lock_0000000002 (客户端B创建)
└── lock_0000000003 (客户端C创建)Step 2:判断自己是否持有最小序号
- 客户端A:持有
0001(最小)→ 获取锁成功 - 客户端B:持有
0002(非最小)→ 锁获取失败 - 客户端C:持有
0003(非最小)→ 锁获取失败
Step 3:未获取锁的客户端注册监听
- 客户端B监听
0001节点(前一个节点) - 客户端C监听
0002节点(前一个节点)
Step 4:阻塞等待
- B和C进入等待状态,不轮询,CPU占用为0
三、解锁流程与唤醒机制
客户端A释放锁:
- 显式删除 :调用
delete /locks/lock_0000000001 - 或会话断开 :A宕机,session超时30秒,ZK自动删除
0001
Zookeeper通知监听者:
- 节点
0001删除事件触发 - 仅通知客户端B (因为B监听了
0001) - 客户端B被唤醒,重新判断:
0002是否最小?是 → 获取锁成功 - 客户端C继续监听
0002
四、羊群效应(Herd Effect)优化
原始问题 :若所有客户端都监听同一个节点 ,删除时会唤醒所有等待者,造成性能抖动。
Zookeeper解决方案 :只监听前一个节点(如图)
未优化(错误):
所有客户端监听 /locks 目录变化
→ 0001删除时,B、C、D...全部被唤醒
优化后(正确):
B监听0001,C监听0002,D监听0003
→ 0001删除时,仅B被唤醒性能对比 :从O(n)唤醒 降为O(1)唤醒,支撑万级并发无压力。
五、Zookeeper vs Redis分布式锁对比
| 维度 | Zookeeper | Redis |
|---|---|---|
| 一致性 | CP系统(强一致,故障时不可用) | AP系统(高可用,可能丢数据) |
| 防死锁 | Session过期自动删节点 | 依赖EXPIRE过期时间 |
| 可重入 | 需额外标记ThreadID | Redisson原生支持 |
| 公平性 | 顺序节点天然公平 | 随机竞争,可能饥饿 |
| 等待机制 | Watch通知,实时唤醒 | Pub/Sub或轮询,延迟较高 |
| 性能 | 较低(写操作需过半节点同步) | 极高(内存操作) |
| 运维成本 | 高(需维护ZK集群) | 低(Redis更普及) |
| 适用场景 | 金融、支付(强一致) | 电商、社交(性能优先) |
六、Java实战代码(Curator框架)
java
// Maven依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.2.1</version>
</dependency>
// 配置ZK客户端
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.1.10:2181,192.168.1.11:2181,192.168.1.12:2181")
.sessionTimeoutMs(30000) // Session超时30秒
.connectionTimeoutMs(10000)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
// 创建分布式锁(InterProcessMutex)
InterProcessMutex lock = new InterProcessMutex(client, "/locks/order_lock");
// 使用锁
lock.acquire(); // 阻塞式获取锁
try {
// 执行业务:扣库存、下单等
// 天然支持可重入:同一线程可多次acquire()
} finally {
lock.release(); // 必须finally释放
}Curator封装的优势:
- 自动续期:内部心跳维持Session,无需WatchDog
- 可重入:记录线程ID和重入次数
- 公平锁:顺序节点保证先到先得
七、面试快刷要点
java
// ZK锁核心三要素
临时节点:宕机自动删除,防死锁
顺序节点:公平锁,排队机制
Watch机制:监听前一个节点,避免羊群效应
// 加锁流程(4步)
1. create -e -s /locks/lock_
2. getChildren /locks 获取所有子节点
3. 判断自己是否序号最小
├─ 是 → 加锁成功
└─ 否 → 监听前一节点,阻塞等待
// 解锁流程(1步)
delete /locks/lock_000X 或 断开session八、一句话总结
Zookeeper通过临时顺序节点 + Watch监听 实现分布式锁,强一致性、自动续期、公平性 是其核心优势,但性能低于Redis。适用于金融、支付 等对可靠性要求极高的场景;Redis锁性能更强,适合电商、社交等性能优先的业务。