
我平时做语音转录,最头疼的就是 噪声。 录音里往往有风声、电流声、键盘声、回声......这些杂音一多,转录模型就容易漏听,甚至整句识别不出。
网上的降噪方法很多,大多是基于"大模型"的 AI 降噪,比如 RNNoise、Deepfilture2 、resemble-enhance 等,
效果确实好,但问题也不小:
- 模型动辄几百 MB甚至几个G;
- 下载慢,还容易因为国内网络环境中断;
- 处理慢,不适合批量。
- 最重要的是不太适合打包分发
对我来说,目标很简单: 我只是想在转录前,把音频稍微清理干净一点 ,减少漏识别的句子。 降噪不必完美,只要足够简单、足够轻量就行。
最初的尝试:afftdn
一开始我用的是 FFmpeg 自带的频域降噪滤镜:
bash
ffmpeg -i 1.wav -af afftdn 1_denoised.wav命令确实够短,但------几乎没效果。 轻微的底噪、风声、呼吸声几乎没变。
我尝试调参数:
bash
-afftdn=nf=-30强度确实大了点,但人声也被吃掉了一部分,声音发闷、带水声。 我想,也许需要几种滤镜配合使用。
改进方案:四个滤镜组合
最后,我确定了下面这一行命令:
bash
ffmpeg -i 1.wav -af "highpass=f=80,afftdn=nf=-25,loudnorm,volume=2.0" 1_clean.wav降噪效果立刻提升不少,识别率也明显更稳定。
以下均是使用 whisper 的最小模型 tiny 测试
- 这是未进行降噪处理的语音转录效果,很明显前面漏了好几句
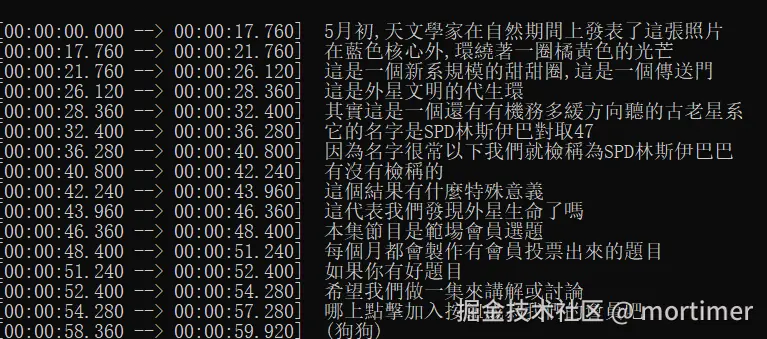
- 这是使用该降噪参数后的语音转录效果
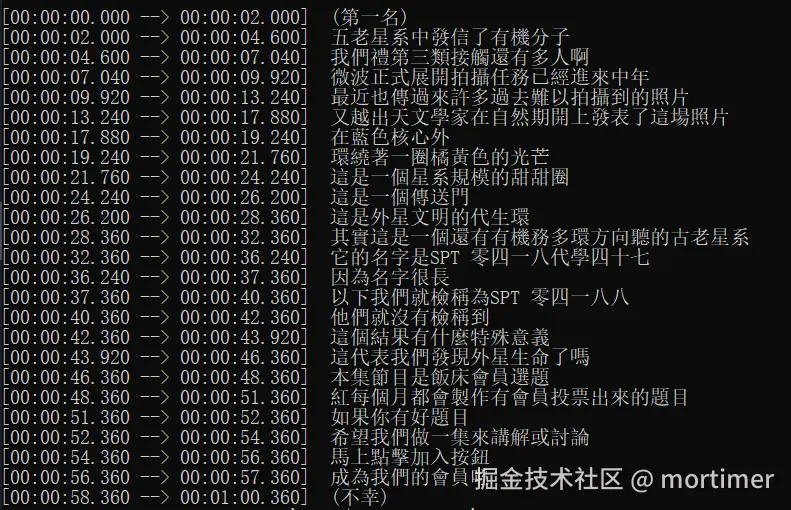
提升还是比较明显的,不仅不再漏句,断句也更合理了
来看一下它的组成部分👇
1️⃣ highpass=f=80
高通滤波器,去掉 80Hz 以下的低频杂音。 这部分通常是环境嗡嗡声或麦克风底噪,人声几乎不受影响。 加上这一条,整体立刻"干净"了不少。
2️⃣ afftdn=nf=-25
核心降噪滤镜。 nf 表示噪声底阈值(noise floor),默认是 -20。 我将它调到 -25,略强一点但不会太糊。 这个参数相当于一个"力度控制",越低降噪越强。
3️⃣ loudnorm
响度归一化。 降噪后声音有时会忽大忽小,loudnorm 能让整体听起来更自然、更平衡。
4️⃣ volume=2.0
最后把音量放大两倍,补回降噪带来的能量损失。 如果音量太高或爆音,可以调为 1.5。某些场景下,1.5比2.0效果更好
为什么不用 AI 降噪?
有人可能会问: FFmpeg 不是还有基于神经网络的 arnndn 吗?效果更好啊。
是的,它确实更强,但问题在于------麻烦。 很多 FFmpeg 版本根本没编译这个滤镜,要用它就得:
- 自己下载
.rnnn模型; - 配置路径;
- 兼容不同系统;
- 分享脚本时还得附带模型文件。
对我这种希望一条命令就能跑、还要发给其他小白用户的人来说,这不现实。
相比之下,highpass + afftdn 是纯内置方案,不依赖外部模型,速度快、兼容性好。
实战体验
我把这条命令作为语音转录前的预处理,效果非常稳定。 环境噪声明显减轻,语音识别模型的漏识率降低了不少。
更重要的是:
- 运行只需几秒;
- 无需额外文件;
- 任意系统都能用;
- 批量处理轻松搞定。
对于希望部署简单、运行快速、结果可控的需求来说,这条命令堪称"刚刚好"。

降噪这件事,没有完美方案。 AI 模型能做到极致,但门槛高; 传统滤镜效果一般,但稳定、通用。
我的目标不是做声音修复,而是让语音转录更稳一点。 而这一行命令,正好在"效果"和"简单"之间取得了平衡:
bash
ffmpeg -i 1.wav -af "highpass=f=80,afftdn=nf=-25,loudnorm,volume=1.5" 1_clean.wav